大数据计算优化:Java 反射为什么慢?
起因
最近在看Flink中一个新feature:使用CodeGen来优化序列化器。
Flink中会根据用户定义的输入输出信息,生成相应的序列化器,这种定制化的序列化器比起Kryo性能要高很多,因为不用写类型信息等等。但是对于用户的POJO,序列化仍然是有些场景的瓶颈所在,因为不管这么定制,序列化器仍然需要通过反射来拿到对应字段。
那反射比起getXXX方法来说究竟慢在哪里呢?(这里特别说明对比的是反射中的Field/get)
测试
第一个例子:
public class Test {
public static void main(String[] args) throws Exception {
doGet();
doReflectGet();
}
public static void doGet() throws Exception {
long start = System.currentTimeMillis();
A a = new A();
for (int i = 0; i < 100000000; i++) {
a.getI();
}
System.out.println(System.currentTimeMillis() - start);
}
public static void doReflectGet() throws Exception {
long start = System.currentTimeMillis();
A a = new A();
Class<A> cls = A.class;
Field field = cls.getField("i");
for (int i = 0; i < 100000000; i++) {
field.get(a);
}
System.out.println(System.currentTimeMillis() - start);
}
}
结果:5ms 923ms
难道反射和普通get相差200倍的性能吗?!!
其实并不是,反射是慢,但慢多少这个例子并不能测试出来,这个例子第二个方法由于反射的存在,导致JVM无法优化。
第一个例子不管循环多少次,结果都是5ms左右,因为JVM直接把这段代码优化了,JVM直接判定循环中的代码没有对外界造成影响,所以直接忽略调用了。
第二个例子:
public class Test {
public static void main(String[] args) throws Exception {
doGet();
doReflectGet();
}
public static void doGet() throws Exception {
long start = System.currentTimeMillis();
Integer[] arr = new Integer[100000000];
A a = new A();
for (int i = 0; i < 100000000; i++) {
arr[i] = a.getI();
}
System.out.println(System.currentTimeMillis() - start);
}
public static void doReflectGet() throws Exception {
long start = System.currentTimeMillis();
Integer[] arr = new Integer[100000000];
A a = new A();
Class<A> cls = A.class;
Field field = cls.getField("i");
for (int i = 0; i < 100000000; i++) {
arr[i] = (Integer) field.get(a);
}
System.out.println(System.currentTimeMillis() - start);
}
}
结果:513ms 2805ms
这才是真正的差距(修改循环次数性能差距变化不大),前面那个例子证明反射干扰了JVM的优化,这个例子说明在去除干扰优化后(只能说去除了干扰的循环优化)还差了5倍的性能!!为什么呢?
反射Field/get
跟着源码看下,最后是使用FieldAccessor来获取的:
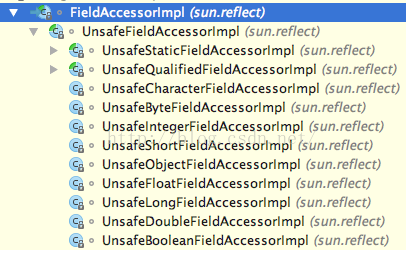
都是写使用Unsafe类来访问的,Unsafe类是Java中可以像C语言中那样使用指针偏移来操作Java对象(还有并发CAS等)的一个工具类,这个类的实现是JNI的C++代码:
jlong
sun::misc::Unsafe::getLong (jobject obj, jlong offset)
{
jlong *addr = (jlong *) ((char *) obj + offset);
spinlock lock;
return *addr;
}C++中其实就是简单的通过基地址和偏移来指针运算拿到内存值,感觉上没有什么劣势,只有JNI,但Unsafe可是JVM自带的JNI(Intrinsic function?),性能应该不会差。
但是JNI毕竟是JNI,这让JVM无法预知它的行为带来的影响,本来可以有的很多优化被此JNI调用给隔绝了,而Java本来就是靠动态优化吃饭的(Java是门半编译型半解释型语言,不像C++靠编译优化),所以性能影响还是蛮大的。
总结
反射缺点:
1.由于是本地方法调用,让JVM无法优化(还有JIT?)。
2.反射方法调用还有验证过程和参数问题,参数需要装箱拆箱、需要组装成Object[]形式、异常的包装等等问题,篇幅问题这里不加以叙述。
解决方法就是前面提到的CodeGen(这边特指Run time code generation),既然没有getXXX方法,那就通过动态生成代码来生成getXXX方法(Javassist等技术)。
类似的反射其它用法:方法调用、newInstance类都要慢很多,这在业务系统中可以忽略不计(和Http网络延时、数据库访问等等比起来反射消耗的太小了),但是在大数据计算的场景中,往往性能瓶颈就在这些地方。
CodeGen在Spark中已经运用起来,主要用于消除方法的多态调用。
Flink和Spark在其它方面还克服了JVM的其它一些“缺点”(与其说是缺点,其实是妥协):内存管理来避免Full GC、对象序列化到字节内存中减小对象的内存开销、直接在字节内存上计算以减少不必要序列化同时缓存友好 等等。