最短路径算法—Bellman-Ford(贝尔曼-福特)算法分析与实现(C/C++)
Dijkstra算法是处理单源最短路径的有效算法,但它局限于边的权值非负的情况,若图中出现权值为负的边,Dijkstra算法就会失效,求出的最短路径就可能是错的。这时候,就需要使用其他的算法来求解最短路径,Bellman-Ford算法就是其中最常用的一个。该算法由美国数学家理查德•贝尔曼(Richard Bellman, 动态规划的提出者)和小莱斯特•福特(Lester Ford)发明。Bellman-Ford算法的流程如下:
给定图G(V, E)(其中V、E分别为图G的顶点集与边集),源点s,
- 数组Distant[i]记录从源点s到顶点i的路径长度,初始化数组Distant[n]为, Distant[s]为0;
以下操作循环执行至多n-1次,n为顶点数:
对于每一条边e(u, v),如果Distant[u] + w(u, v) < Distant[v],则另Distant[v] = Distant[u]+w(u, v)。w(u, v)为边e(u,v)的权值;
若上述操作没有对Distant进行更新,说明最短路径已经查找完毕,或者部分点不可达,跳出循环。否则执行下次循环; - 为了检测图中是否存在负环路,即权值之和小于0的环路。对于每一条边e(u, v),如果存在Distant[u] + w(u, v) < Distant[v]的边,则图中存在负环路,即是说改图无法求出单源最短路径。否则数组Distant[n]中记录的就是源点s到各顶点的最短路径长度。
可知,Bellman-Ford算法寻找单源最短路径的时间复杂度为O(V*E).
首先介绍一下松弛计算。如下图:
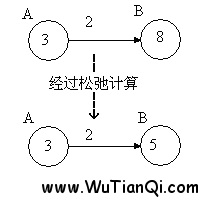
松弛计算之前,点B的值是8,但是点A的值加上边上的权重2,得到5,比点B的值(8)小,所以,点B的值减小为5。这个过程的意义是,找到了一条通向B点更短的路线,且该路线是先经过点A,然后通过权重为2的边,到达点B。
当然,如果出现一下情况
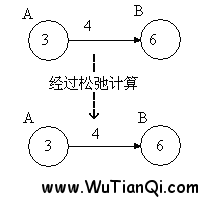
则不会修改点B的值,因为3+4>6。
Bellman-Ford算法可以大致分为三个部分
第一,初始化所有点。每一个点保存一个值,表示从原点到达这个点的距离,将原点的值设为0,其它的点的值设为无穷大(表示不可达)。
第二,进行循环,循环下标为从1到n-1(n等于图中点的个数)。在循环内部,遍历所有的边,进行松弛计算。
第三,遍历途中所有的边(edge(u,v)),判断是否存在这样情况:
d(v) > d (u) + w(u,v)
则返回false,表示途中存在从源点可达的权为负的回路。
之所以需要第三部分的原因,是因为,如果存在从源点可达的权为负的回路。则 应为无法收敛而导致不能求出最短路径。
考虑如下的图:
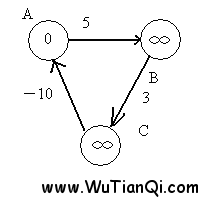
经过第一次遍历后,点B的值变为5,点C的值变为8,这时,注意权重为-10的边,这条边的存在,导致点A的值变为-2。(8+ -10=-2)
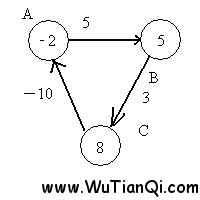
第二次遍历后,点B的值变为3,点C变为6,点A变为-4。正是因为有一条负边在回路中,导致每次遍历后,各个点的值不断变小。
在回过来看一下bellman-ford算法的第三部分,遍历所有边,检查是否存在d(v) > d (u) + w(u,v)。因为第二部分循环的次数是定长的,所以如果存在无法收敛的情况,则肯定能够在第三部分中检查出来。比如
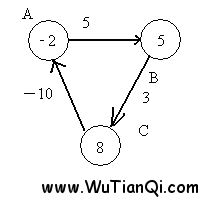
此时,点A的值为-2,点B的值为5,边AB的权重为5,5 > -2 + 5. 检查出来这条边没有收敛。
所以,Bellman-Ford算法可以解决图中有权为负数的边的单源最短路径问。
个人感觉算法导论讲解很不错,把这一章贴出来和大家分享:
24.1 The Bellman-Ford algorithm
The Bellman-Ford algorithm solves the single-source shortest-paths problem in the general case in which edge weights may be negative. Given a weighted, directed graph G = (V, E) with source s and weight function w : E → R, the Bellman-Ford algorithm returns a boolean value indicating whether or not there is a negative-weight cycle that is reachable from the source. If there is such a cycle, the algorithm indicates that no solution exists. If there is no such cycle, the algorithm produces the shortest paths and their weights.
The algorithm uses relaxation, progressively decreasing an estimate d[v] on the weight of a shortest path from the source s to each vertex v ∈ V until it achieves the actual shortest-path weight δ(s, v). The algorithm returns TRUE if and only if the graph contains no negative-weight cycles that are reachable from the source.
BELLMAN-FORD(G, w, s)
INITIALIZE-SINGLE-SOURCE(G, s)
for i ← 1 to |V[G]| - 1
do for each edge (u, v) ∈ E[G]
do RELAX(u, v, w)
for each edge (u, v) ∈ E[G]
do if d[v] > d[u] + w(u, v)
then return FALSE
return TRUEFigure 24.4 shows the execution of the Bellman-Ford algorithm on a graph with 5 vertices. After initializing the d and π values of all vertices in line 1, the algorithm makes |V| – 1 passes over the edges of the graph. Each pass is one iteration of the for loop of lines 2-4 and consists of relaxing each edge of the graph once. Figures 24.4(b)-(e) show the state of the algorithm after each of the four passes over the edges. After making |V|- 1 passes, lines 5-8 check for a negative-weight cycle and return the appropriate boolean value. (We’ll see a little later why this check works.)
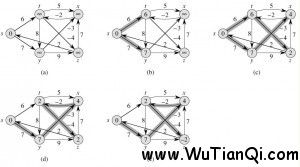
Figure 24.4: The execution of the Bellman-Ford algorithm. The source is vertex s. The d values are shown within the vertices, and shaded edges indicate predecessor values: if edge (u, v) is shaded, then π[v] = u. In this particular example, each pass relaxes the edges in the order (t, x), (t, y), (t, z), (x, t), (y, x), (y, z), (z, x), (z, s), (s, t), (s, y). (a) The situation just before the first pass over the edges. (b)-(e) The situation after each successive pass over the edges. The d and π values in part (e) are the final values. The Bellman-Ford algorithm returns TRUE in this example.
The Bellman-Ford algorithm runs in time O(V E), since the initialization in line 1 takes Θ(V) time, each of the |V| – 1 passes over the edges in lines 2-4 takes Θ(E) time, and the for loop of lines 5-7 takes O(E) time.
以下是Bellman-Ford代码:
#include <iostream>
using namespace std;
const int maxnum = 100;
const int maxint = 99999;
// 边,
typedef struct Edge{
int u, v; // 起点,重点
int weight; // 边的权值
}Edge;
Edge edge[maxnum]; // 保存边的值
int dist[maxnum]; // 结点到源点最小距离
int nodenum, edgenum, source; // 结点数,边数,源点
// 初始化图
void init()
{
// 输入结点数,边数,源点
cin >> nodenum >> edgenum >> source;
for(int i=1; i<=nodenum; ++i)
dist[i] = maxint;
dist[source] = 0;
for(int i=1; i<=edgenum; ++i)
{
cin >> edge[i].u >> edge[i].v >> edge[i].weight;
if(edge[i].u == source) //注意这里设置初始情况
dist[edge[i].v] = edge[i].weight;
}
}
// 松弛计算
void relax(int u, int v, int weight)
{
if(dist[v] > dist[u] + weight)
dist[v] = dist[u] + weight;
}
bool Bellman_Ford()
{
for(int i=1; i<=nodenum-1; ++i)
for(int j=1; j<=edgenum; ++j)
relax(edge[j].u, edge[j].v, edge[j].weight);
bool flag = 1;
// 判断是否有负环路
for(int i=1; i<=edgenum; ++i)
if(dist[edge[i].v] > dist[edge[i].u] + edge[i].weight)
{
flag = 0;
break;
}
return flag;
}
int main()
{
//freopen("input3.txt", "r", stdin);
init();
if(Bellman_Ford())
for(int i = 1 ;i <= nodenum; i++)
cout << dist[i] << endl;
return 0;
}考虑:为什么要循环V-1次?
答:因为最短路径肯定是个简单路径,不可能包含回路的,
如果包含回路,且回路的权值和为正的,那么去掉这个回路,可以得到更短的路径
如果回路的权值是负的,那么肯定没有解了
图有n个点,又不能有回路
所以最短路径最多n-1边
又因为每次循环,至少relax一边
所以最多n-1次就行了
以上内容转自http://www.wutianqi.com/?p=1912