文本建模系列之一:LSA
俗话说“庙小妖风大,水浅王八多”,作为一名自然语言处理的水货研究生,通常只是对论文有着一知半解的了解,然而因为毕竟人老了年纪大容易忘事,有时候还是想把这一知半解的想法用文字写出来,以便之后回顾,看官勿喷,水货要开始动笔了。
文本建模是自然语言处理领域中很基础的内容,而且也已经被研究了千万遍,这个系列我主要的思路是从LSA->pLSA->unigram model ->LDA,其中pLSA和LDA都是主题模型。我研究主题模型的初衷是为了在文本分类中提取出文本特征,而通过主题模型的建模过程,可以很好的了将文档的向量表示的维度压缩到K维,然后这K维的向量就可以丢到SVM、朴素贝叶斯、最大熵、神经网络、CNN等多个分类器中去了。文本表示的去稀疏和降维无疑对文本分类是个好事。
开始LSA,LSA论文是Deerwester等人在90年代早期发表的,其主要的方法是利用了奇异值分解(SVD)方法,这个方法在后来的pLSA论文中被指出没有真正的统计依据,也就是说缺乏合理的统计概率方法支撑,然而这个方法还是起到不错的效果,这也是神奇的地方。我并不想去探讨SVD的实际含义,只是把作者的做法表达出来一下
LSA(Latent Semantic Analysis)或者LSI(Latent Semantic Index),作者提出来主要是为了信息检索,也就是给定一个字符串,查找语料库中所有和这个字符串有关系的文档。
首先,我们将语料库的文档按照如下格式转换成矩阵:

如上图所示,横向表示文档编号,纵向表示文档中的单词,表中数字表示文档的词频统计。把这个矩阵计做是X
对于X我们可以分解成如下的形式:
![]()
其中T0和D0是正交矩阵,S0是对角矩阵,而且S0的对角是递减的正数,分解过程如下:
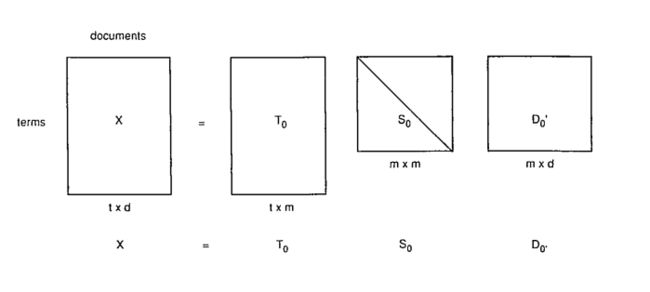
这并不神奇,神奇的是后面过程,
为了降维,我们可以在S0中取前k个数产生一个新的对角矩阵S,对应的在T0中取前两列,在D0'中取前两列,构成新的X^
其中:
![]()
示例如下:

那么上面的初始矩阵可以按照下面的分解:

假设我们取K=2,那么新产生的矩阵是:

然后就得到了新的矩阵X^:
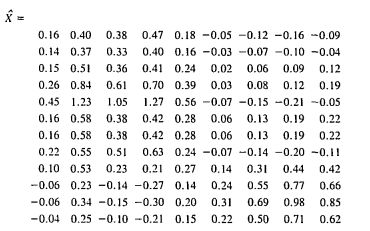
到这里,我们就可以进行下一,也就是比较文档和文档、文档和词语、词语和词语、查询语句与词语之间的相似度了。具体的计算过程如下:
- 计算词语之间的相似度(相关性)
计算词语与词语之间的相关性,
![]()
上面的矩阵,X^和X^的转置的点乘是所有的词语之间的相似度关系,而根据右边的式子,可以看出,其实是TS与TS的转置,因此第i个词语和第j个词语之间的相似性就可以使用TS中第 i 行和第 j 列的相似性,当然这里可以使用欧式距离或者余弦函数cos来计算。
- 计算文档与文档之间的相似度
计算文档与文章之间的相似度,可以用下面的矩阵来表示:
![]()
和计算词语与词语之间的一样,第 i 篇 文档 和第 j 篇文档之间的相似度就是 DS矩阵第 i 行 和 第 j 行的向量距离。
- 计算文档与词语之间的相似度(相关性)
计算文档与单词相似性的矩阵就是X^:
![]()
我们可以把第 i 个词语 和第 j 个文档的相似性比较为: TS(1/2) 矩阵的第 i 行 和 DS(1/2)矩阵的第 j 行的向量距离
- 计算查询语句q与语料中文档的相似性
这个计算过程,稍显麻烦,首先将查询语句转换成一维列向量,也就是和文最初的形式一样。然后就算:
![]()
然后将Dq和D的每一行计算向量距离即可
参考文献:
[1]Scott Deerwester. Indexing by Latent Semantic Analysis. Journal of the American Society for Information Science(1986-1998);sep 1990;41,6; ABI?INFORM Global
[2]Edel Garcia,Latent Semantic Indexing (LSI) A Fast Track Tutorial