RGBD-SLAM
首先,致谢半闲居士(http://www.tuicool.com/articles/QZVjuu)。
RGBD-SLAM用的传感器是kinect,可以得到深度信息与图像信息。我在实验中使用的是激光扫描仪,只能得到深度信息,不过原理是一致的。
1. 得到三维点云图;
2. 对三维点云图进行两两匹配;
3. 进行图形优化;
4. 纹理贴图。
本文重点讲述第三点:图形优化问题(g2o)。
要了解g2o,可以参考以下一些文章:
Hierarchical Optimization on Manifolds for Online 2D and 3D Mapping;(2010)
g2o: A General Framework for Graph Optimization;(2011)
Experimental Analysis of Dynamic Covariance Scaling for Robust Map Optimization Under Bad Initial Estimates;(2014)
以上3篇文章,第二篇是基础(为什么第二篇文章比第一篇文章发表的晚,这个我也弄不明白,这是个bug!!),第二篇文章主要就是讲了如何建模,从而引入优化问题,之后呢,作者对该非线性问题进行了线性化,从而可以解;但是,以上是基于欧式空间的假设。进而,作者对其进行了扩展,扩展到了普遍意义上的优化问题。第一篇文章讲了g2o的一种应用方法,即将整个图形进行了分层处理。第三篇文章讲到:如果初始位置估计误差很大,则用原始g2o可能得不到自己想要的结果,于是,在优化问题中引入了一个变量参数。
g2o的基础是:顶点(vertex)和边(edge)。顶点即为机器人的位置估计,边即为两个位置之间的约束,简而言之,就是两个位置的关系(比如,在我的实验中,就是机器人两个位置之间的旋转平移矩阵)。理解g2o的应用,最好的例子就是g2o目录下的例子:tutorial_slam2d。
g2o最好在检测到闭环之后再用,这样全局优化的效果最好,比如:一个闭环有20个poses,我们可以得到相邻poses的约束20个,此时,我们可以在g2o对象中加入20个顶点,以及20个边,之后,我们可以得到优化之后的poses,它会将第一个pose和最后一个pose大概捏到一块,这个的决定因素是第一帧和最后一帧的约束,这个矩阵的模越小,它们将会挨得更近。当然了,如果优化效果并不是很好的情况下,我们可以加入更多的边,更多的约束。注意:加入的约束尽量要正确,不要引入误差,否则,效果将适得其反。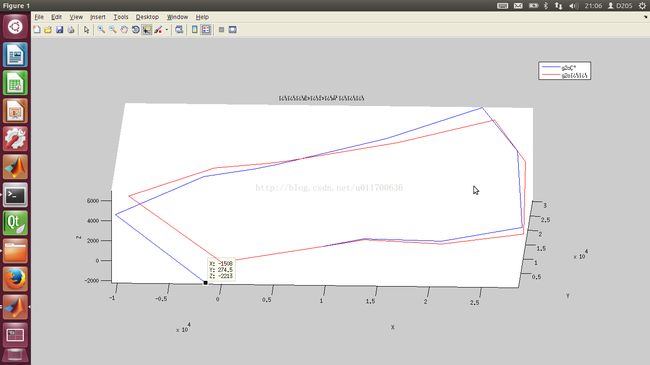
这是我用matlab画出的poses图,蓝色线是g2o前的,红的是g2o之后的,起点是[1,1,1]。从图中可以看出,最后一个pose是[-1508,274.5,-2213],和第一个pose差别很大,但是经过g2o优化之后,他们两个几乎到一块儿去了,并且对其他poses进行了修正。