Linux高速缓存详解(一)
个人学习总结,不保证正确性。。。
在Linux高速缓存概述中介绍了Linux 0.11中的高速缓存的基础结构,这一部分将详细分析Linux高速缓存部分的相关函数。
![]()
[数据结构]
这里介绍下另外和高速缓存相关的数据结构,高速缓存散列表、空闲链表指针free_list以及等待在缓存块上的指针buffer_wait。它们定义分别如下:(代码来源buffer.c)
struct
buffer_head * hash_table[NR_HASH];
static
struct
buffer_head * free_list;
static
struct
task_struct * buffer_wait = NULL;
struct
buffer_head * start_buffer = (
struct
buffer_head *) &end;
int
NR_BUFFERS = 0;
hash_table就是之前介绍过的缓存散列表,散列函数定义如下
#define
_hashfn(dev,block) (((
unsigned
)(dev^block))%NR_HASH)
#define
hash(dev,block) hash_table[_hashfn(dev,block)]
使用两个宏,_hashfn(dev,block)计算相应的设备号和逻辑块号在散列表上的索引,使用hash(dev,block),获取计算的索引值在hash_table上的项,也就是指向双向链表的指针
free_list指向所有缓存块构成的双向链表的指针,可以将其看成是整个链表的头指针
buffer_wait是一个指向进程的指针,当进程试图获取一个缓存块时。如果所有的缓存块都不是空闲的,就会让buffer_wait指向这个进程,并且让这个进程进入不可中断的睡眠状态。当有任何进程释放一个缓存块时,就会唤醒buffer_wait指向的进程。(个人对此有个问题,当所有的缓存块都非空闲时,如果有多个进程试图获取缓存块,这几个进程都会进入不可中断的睡眠状态。但buffer_wait只是指向最后调用的那个进程,因此,当缓存块被释放,只有最后那个进程被唤醒,其它进程会一直处于不可中断的睡眠状态?)
start_buffer表示缓冲区开始地址,end是由连接程序ld生成的表明程序末端的变量(来自《Linux内核完全注释》对end的解释)
NR_BUFFERS表示缓冲块的个数,NR_BUFFERS其实是一个宏,在fs.h中定义,对应变量nr_buffers。
[缓冲区的初始化]
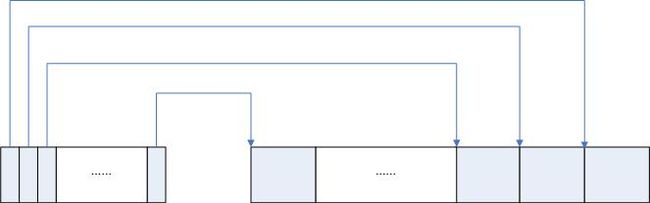
缓冲区的初始化由buffer_init完成。缓冲区的初始化过程是这样的,从缓冲区的高地址部分开始,划分出一个个大小为1KB(BLOCK_SIZE)部分作为数据缓冲部分,也就是在Linux高速缓存概述中介绍的buffer_data部分。从缓冲区的低地址部分开始,建立对应每个buffer_data部分的缓冲块头部分,也就是buffer_head部分。初始化之后的缓冲区的示意图如下
初始化代码如下所示
/*
buffer_end表示缓冲区的结束地址
*/
void
buffer_init(
long
buffer_end)
{
struct
buffer_head * h = start_buffer;
void
* b;
int
i;
/*
由于内存地址的640K~1M部分被用于显存和BIOS使用,所以这里需要对缓存的结束地址做调整
*/
if
(buffer_end == 1<<20)
//2^20=1M
b = (
void
*) (640*1024);
//640K
else
b = (
void
*) buffer_end;
/*
为了保证有足够的空间来存储缓冲块的头部和缓冲块的数据缓冲部分,需要满足b-BLOCK_SIZE>=h+1
*/
while
( (b -= BLOCK_SIZE) >= ((
void
*) (h+1)) ) {
//设置缓冲块头部的初始值,并让data指向数据缓冲部分
h->b_dev = 0;
h->b_dirt = 0;
h->b_count = 0;
h->b_lock = 0;
h->b_uptodate = 0;
h->b_wait = NULL;
//空闲的缓冲块的b_next和b_prev都为NULL
h->b_next = NULL;
h->b_prev = NULL;
h->b_data = (
char
*) b; //让data指向数据缓冲部分
h->b_prev_free = h-1;
h->b_next_free = h+1;
h++;
NR_BUFFERS++;
/*
看是否到了显存和BIOS使用的内存区域,如果是,就要调整高地址
*/
if
(b == (
void
*) 0x100000)
//16^5=2^20=1M
b = (
void
*) 0xA0000;
//0xA0000=640K
}
h--;
free_list = start_buffer; //让free_list指向链表头
free_list->b_prev_free = h; //构造循环结构
h->b_next_free = free_list;
//初始化缓冲区的散列表,所有项都设为空
for
(i=0;i<NR_HASH;i++)
hash_table[i]=NULL;
}
[高速缓存的读写操作]
[高速缓存的读操作]
高速的读操作入口函数是bread。但真正用来实现获取高速缓存数据的操作是getblk函数。与高速缓存读操作相关的函数还有get_hash_table和和find_buffer。调用这几个函数都需要指定设备号和逻辑块号。这里先对这些函数的功能做个简要介绍,后面将依次对这些函数的源代码进行说明。
bread调用getblk获取一个缓存块,然后根据获取的缓存块中的数据是否是有效的来判断是否要从底层设备读入数据。如果获取的缓存块的数据是有效的,即缓存头的b_uptodate字段为1时,就直接返回获取的缓存块。如果这个缓存块的数据是无效的,那么就需要调用底层的读取块设备函数ll_rw_block来将数据从设备读入缓存块中。
getblk实现获取一个缓存块的功能。getblk先根据设备号和逻辑块好在hash_table中查找,看是否存在相应的缓存块,如果在hash_table中能够找到相应的缓存块,就返回这个缓存块。如果在hash_table中没有相应的缓存块,那么就从空闲链表中找到一个空闲的缓存块,并将这个空闲的缓存块放返回。所以,由getblk返回的缓存块其实是有两种情况的,空闲的缓存块和在缓冲区的缓存块
get_hash_table的作用是根据设备号和逻辑块号获取在hash_table中的缓存块。如果能找到相应的缓存块,就将这个缓存块的引用数加1,等待这个缓存区解锁(如果被其它进程加锁),然后返回这个缓存块。如果在hash_table中找不到相应的缓存块,返回NULL。getblk调用get_hash_table实现从hash_table中获取缓存块的操作
find_buffer实现散列表的查找动作,根据设备号和逻辑号,计算散列值,用这个值作为索引,在散列数组hash_table中进行查找。get_hash_table调用get_buffer来实现散列表的查找过程。
下面将分别对这些函数的代码进行注释讲解。
find_buffer函数,代码来自于buffer.c
static
struct
buffer_head * find_buffer(
int
dev,
int
block)
{
struct
buffer_head * tmp;
for
(tmp = hash(dev,block) ; tmp != NULL ; tmp = tmp->b_next)
//散列值相同的缓存块之间通过b_next和b_prev构成双向链表
if
(tmp->b_dev==dev && tmp->b_blocknr==block)
return
tmp;
return
NULL;
}
hash就是前面介绍的宏。定义为
#define
hash(dev,block) hash_table[_hashfn(dev,block)],调用_hashfn宏,利用设备号和逻辑块号计算索引,并获取数组元素项。_hashfn宏的定义在前面有介绍,
#define
_hashfn(dev,block) (((
unsigned
)(dev^block))%NR_HASH),将设备号和逻辑块号进行按位或操作,然后这个结果去模NR_HASH,来计算最后的散列值。
get_hash_table函数,代码来自于buffer.c
struct
buffer_head * get_hash_table(
int
dev,
int
block)
{
struct
buffer_head * bh;
for
(;;) {
/*
如果find_buffer返回的是NULL,那么就说明对应dev和block的数据不在缓存区中,返回NULL即可
*/
if
(!(bh=find_buffer(dev,block)))
return
NULL;
/*
如果找到了相应的缓存块,就将这个缓存块的引用次数加1,即b_count的值加1.
同时等待此缓存区解锁
*/
bh->b_count++;
wait_on_buffer(bh);
/*
如果bh指向的缓存块被其它进程所使用并加锁,那么当前进程就会进入不可中断的睡眠状态。
在进程睡眠期间,缓存区中的数据可能被修改,因此,这里需要再次进行设备号和逻辑块号的确认
*/
if
(bh->b_dev == dev && bh->b_blocknr == block)
return
bh; //确认成功,就将这个缓存块返回
bh->b_count--; //如果确认失败,就将引用次数加1,抵消之前的加1的操作。继续寻找
}
}
wait_on_buffer函数的作用是检查由参数传递的缓存块是否被加锁,如果加锁就让当前进程进入睡眠状态,并且让缓存块的b_wait指向当前的进程。然后进行进程调度。wait_on_buffer的代码如下(来自buffer.c)
static
inline
void
wait_on_buffer(
struct
buffer_head * bh)
{
cli();
while
(bh->b_lock)
sleep_on(&bh->b_wait);
sti();
}
cli和sti分别是关中断和开中断操作。调用sleep_on时会传递一个指针的地址,调用sleep_on之后,会让这个指针指向当前进程,同时让当前进程进入不可中断的睡眠状态。sleep_on的代码如下(来自sched.c)
void
sleep_on(
struct
task_struct **p)
{
struct
task_struct *tmp;
if
(!p)
return
;
if
(current == &(init_task.task)) //task[0]是不能进入睡眠的
panic(
"task[0] trying to sleep"
);
tmp = *p;
*p = current; //让指针指向当前进程
current->state = TASK_UNINTERRUPTIBLE; //将当前进程设为不可中断的睡眠状态
schedule(); //由于当前进程已经不适合运行,所以需要重新进行进程调度
if
(tmp) //能到这里,说明当前进程已经可以运行,因此修改state的值,使之恢复正常
tmp->state=0;
}
下面是getblk函数的代码,来自于buffer.c
struct
buffer_head * getblk(
int
dev,
int
block)
{
struct
buffer_head * tmp, * bh;
repeat:
/*
如果get_hash_table找到了相应的缓存块,那么就说明对应的数据在缓冲区存在,直接返回这个缓存块。这样做同时也保证了同一个设备的同一个逻辑块在缓冲区上只存在一份缓存数据
*/
if
(bh = get_hash_table(dev,block))
return
bh;
/*
如果在缓存区中没有找到,那就需要通过free_list来寻找
*/
tmp = free_list;
do
{
if
(tmp->b_count) //在free_list上查询的时候,只是寻找空闲的缓存块
continue
;
/*BADNESS值越小的缓存块,越适宜使用。BADNESS的具体意义见下面说明。找到空闲的缓存块后计算可用性值*/
if
(!bh || BADNESS(tmp)<BADNESS(bh)) {
bh = tmp;
if
(!BADNESS(tmp)) //如果BADNESS值为0,是最好的情况,便不用再寻找了
break
;
}
/* and repeat until we find something good */
}
while
((tmp = tmp->b_next_free) != free_list);
/*
如果bh为NULL,说明没有空闲的缓存块了,这个时候就需要让进程进入睡眠。注意这里和wait_on_buffer中调用
sleep_on之间的区别
*/
if
(!bh) {
sleep_on(&buffer_wait);
goto
repeat;
}
//可能找到的空闲的缓存块被其它进程加锁(使用完还没来得及释放锁,或者刚加锁还没来得及设置b_count),就需要等待缓存块解锁
wait_on_buffer(bh);
if
(bh->b_count) //如果在进程睡眠期间,缓存块变为非空闲,那就重新寻找
goto
repeat;
/*b_dirt表示某个进程使用缓存块的时候往缓存块中写入了数据。见下面说明*/
while
(bh->b_dirt) {
sync_dev(bh->b_dev);
wait_on_buffer(bh);
if
(bh->b_count)
goto
repeat;
}
/*这里再次调用find_buffer来寻找缓存块,是为了保证在缓存中只有某个逻辑块的一份缓存数据。可能进程在睡眠过程中,其它进程也要读取dev和block指定的逻辑块,那么这个其它进程就会把数据读到缓存块中。所以当前进程要再次查找,保证缓存区中没有另一份缓存数据*/
if
(find_buffer(dev,block))
goto
repeat;
/*
运行到这里,便找到一个可用的缓存块。空闲的、干净的、没有加锁的缓存块。
设置这个缓存块的相关数据
*/
bh->b_count=1;
bh->b_dirt=0;
bh->b_uptodate=0;
remove_from_queues(bh);
//将缓存块从空闲链表和散列数组的某个链表中删除
bh->b_dev=dev;
bh->b_blocknr=block;
insert_into_queues(bh); //将缓存块插入空闲链表和散列数组的某个链表中。插入空闲链表时是插入在链表的尾部
return
bh;
}
BADNESS是在buffer.c中定义的一个宏,用缓存块头部的b_dirt和b_lock来衡量缓存块的可用情况。BADNESS的定义如下
#define
BADNESS(bh) (((bh)->b_dirt<<1)+(bh)->b_lock),计算结果是两个二进制标识位组成的值, 口口,分别表示缓存内容是否已脏(使用前要将数据写到设备)和缓存块是否被加锁(使用前需要等待解锁)。共有4种情况(二进制表示结果) 11 10 01 00
11表示缓存块内容已脏并且被加锁,说明这个缓存块最不适宜使用,因为在使用这个缓存块之前需要先将数据同步到设备,并且等待缓存块解锁。00表示缓存块内容是干净的,并且没有被加锁。BADNESS的值越小,表示这个缓存块越适宜使用。
注意,在getblk中调用sleep_on和在wait_on_buffer中调用的sleep_on之间的区别。前者调用的时候,传递的参数是&buffer_wait,这是在buffer.c中定义的一个全局变量。是表示等待在整个缓存区上的进程,只要缓存区中的某一个缓存块被释放,就会去唤醒buffer_wait指向的进程。而后者传递的参数是缓存块的头部的&b_wait。只有在这个缓存块被释放的时候,才会去唤醒b_wait指向的进程。
关于b_dirt的用法,
某进程获取缓存块,往缓存中写入数据然后释放缓存块后,数据
不是马上就将数据同步到设备中,而是设置缓存块头部的b_dirt标志。当其它进程用这个缓存块时,它发现b_dirt标志为1,在真正使用之前,就必须要先把缓存块中的数据同步到设备中。
要说明的最后一个高速缓存读函数是bread,这个函数其实是使用高速缓存的入口,进程使用bread来获取缓存块。在buffer.c中,代码如下
struct
buffer_head * bread(
int
dev,
int
block)
{
struct
buffer_head * bh;
if
(!(bh=getblk(dev,block)))
panic(
"bread: getblk returned NULL\n"
);
/*
b_uptodate表示数据是否是有效的,如果数据无效就需要从底层设备重新读入数据
*/
if
(bh->b_uptodate)
return
bh;
ll_rw_block(READ,bh);
wait_on_buffer(bh);
/*
从底层设备读取数据了,等待缓存区解锁了。
如果b_uptodate为0,那就说明读取底层设备数据出错了。
那就可以返回NULL了,在返回之前首先得释放缓存块
*/
if
(bh->b_uptodate)
return
bh;
brelse(bh);
return
NULL;
}
ll_rw_block是底层块设备的读写操作入口。brelse函数是释放一个缓存块