PCA原理及人脸识别应用
本文详细介绍PCA原理,主要参考PRML一书。
PCA也叫Karhunen-Loève transform(KL变换),或Hotelling transform(霍特林变换),是一种无监督学习方法,常用于高维数据的降维,通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量。
PCA的原理有两种等价解释:最大方差和最小投影误差,两种解释都通过一组正交投影,将原始数据投影到低维线性子空间,即主元子空间,最大方差讲求数据投影之后,在投影方向上保持最大方差,最小投影误差需要投影数据重构后和原始数据之间的均方差最小,前者由Hotelling于1933年提出,后者由Pearson于1901年提出。
1. 最大方差法
最大方差的直观理解可以从一个简单的实例解释,如我们的手掌在灯光下的投影,手掌是立体结构,属于三维空间,形成的影子在一个平面内,属于二维空间,首先达到了降维的目的,当手垂直于灯光时,完整的手的影子可以照射在地面上,该方向可保留手的最大特征,如果将手掌直立,平行于灯光,在地面上的影子就是一段很粗的线,无法判断是什么物体。再如图1,两个数据集由两个高斯分布生成,由图可以看出,数据在line B上的投影保持了两类数据的聚类结构,在line B的投影方差也更大,而方差是数据分散程度的度量,所以方差大的投影方向有利于保持数据的聚类特征。数据投影后的低维子空间叫做主元子空间,主元子空间相对于原始空间的补空间为残差子空间,主元子空间要求能保持数据的主要特征,方差作为数据分散程度的度量,是决定投影方向的重要统计量,下面通过推导公式加深对最大方差法的理解。

给定一组D维数据 {xn}Nn=1 , xn∈RD ,我们的目标是把数据投影到 M 维空间 (M<D) ,使投影后的数据方差最大。首先考虑一个维度,假设 u1∈RD 为投影方向,不失一般性,令 u1 为单位向量,即 uT1u1=1 ,任一点 xn 投影后的数据为一个标量 uT1xn ,原始数据均值为 x¯=∑n=1Nxn ,则投影数据的均值为 uT1x¯ ,投影数据协方差为
下面从数据矩阵整体的角度进一步说明PCA的一些原理,记数据矩阵为 X=[x1,x2,...,xN]T∈RN×D ,方便起见,假设 X 是已经中心化处理之后的数据,即 X=X−X¯ ,则协方差矩阵 S=1NXTX , S 的特征值按照从大到小的顺序排列依次为 λ1,λ2,⋯,λM,⋯,λD ,对应的特征向量为 u1,u2,⋯,uM,⋯,uD ,记 W=[u1,u2,⋯,uM] , P=[uM+1,⋯,uD] , Q=[W,P] ,且 QT=Q−1 ,根据特征值分解的原理可知
记投影后的低维矩阵为 Z=[z1,z2,...,zN]T∈RN×M ,则 Z=XW ,且 Z¯=X¯W=0 ,那么投影后矩阵的协方差 S~=1NZTZ=1NWTXTXW=WTSW=diag{λ1,⋯,λM} ,也就是说,投影后矩阵各个维度之间不相关,所以,PCA不仅实现了降维的目的,还将数据变换到维度之间相互独立的主元子空间,同时最大程度保持数据的分布特征。
2. 最小投影误差法
最小投影误差比较容易理解,其原理是最小化数据重构误差。首先,假设 {ui} 是一组相互正交的单位向量,其中, i=1,...,D ,即 uTiuj=δij ,( δij 为Kronecker函数),因此, {ui} 是 RD 空间的一组基,该空间中的任意一点都可以表示为这组基的线性组合,如
至此,所有的表达都基于一组基 {ui} ,下面我们将重构误差写为这组基的函数
记数据矩阵为 X=[x1,x2,...,xN]T∈RN×D ,投影后的低维矩阵为 Z=[z1,z2,...,zN]T∈RN×M ,投影矩阵为 W=[u1,u2,⋯,uM] ,由于 zni=xTnui=uTixn ,那么, zn=[zn1,...,znM]T=[uT1xn,...,uTMxn]T=WTxn ,所以, Z=[z1,...,zN]T=[WTx1,...,WTxN]T=XW 。
由以上分析可知,PCA的最大方差法和最小重构误差法是等价的,最大方差法从主元子空间的角度分析,最小重构误差法从残差子空间的角度分析,最终目标都是保留数据的主要特征。
3. 基于PCA的人脸识别
PCA是人脸识别领域的经典算法,其优点是运算速度快,因为PCA通过选取主元,将人脸图像降维,降维后的数据仍能保持人脸的主要特征,对降维后的数据进行识别,可大大降低计算量。基于PCA的人脸识别算法的主要步骤如下:
(1) 读取训练集图像的像素值,将每个图像的像素值转化为一个行向量,将所有的数据保存为一个二维矩阵,每一行为一个图像的数据;
(2) 数据中心化处理,将第一步得到的矩阵,每一列减去其所在列的均值,使整个数据集的均值为0;
(3) 计算协方差矩阵,协方差矩阵表示不同随机变量之间的相互关系,两个随机变量的协方差越大,表示其相关性越大;
(4) 选择主元子空间,将协方差矩阵的特征值按照从大到小的顺序排列,按照精度要求选择合适数量的前k个特征向量构成投影矩阵;
(5) 将训练集和测试集均进行降维,即投影到主元子空间;
(6) 人脸识别,将降维后的测试集的每一个图像与降维后的训练集的每一个图像进行匹配,将其分类到距离最小的训练集类别中。基于PCA人脸识别的前提是测试集的图像必须包含在训练集中,否则不能从训练集中识别测试集所对应的图像。
以下两组图为采用PCA进行人脸识别的两组结果,每组图的左侧为要识别的图像,即测试集,右侧为从训练集中识别出的图像,第一行为原始图像,第二行为重构后的图像,可以看出,重构后的图像仍能保持原始人脸图像的主要特征。


4. PCA方法的缺点
PCA作为经典方法在模式识别领域已经有了广泛的应用,但是也存在不可避免的缺点,总结如下:
(1) PCA是一个线性降维方法,对于非线性问题,PCA则无法发挥其作用;
(2) PCA需要选择主元个数,但是没有一个很好的界定准则来确定最佳主元个数;
(3) 多数情况下,难以解释PCA所保持的主元分量的意义;
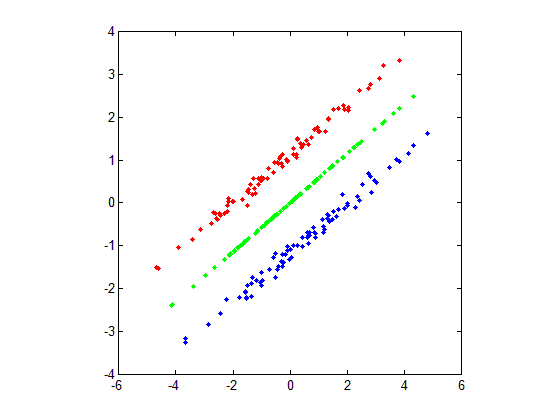
(4) PCA将所有的样本作为一个整体对待,去寻找一个均方误差最小意义下的最优线性映射,而忽略了类别属性,而它所忽略的投影方向有可能刚好包含了重要的可分类信息,如下图所示,红色和蓝色的点为原数据,中间绿色的点为重构后的数据,由此可看出,这种情形下,主元方向不能保持数据的聚类信息。