Lucene的分析过程
Lucene的分析过程
分析(Analysis)是指将域文本(Field)转换成项(Term)的过程,“项”是索引的最基本表示单元。分析器通过一系列操作(可能包括:提取单词,去除标点符号,字段转换成小写<称之为规范化>,词干还原等),这个处理的过程称之为语汇单元化过程(tokenization),从文本流(Reader)中提取的文本块成为语汇单元(token),语汇单元与域名结合后,就形成了项(Term)。
何时使用分析器
任何需要将文本转换成项的过程都将使用到分析器,对Lucene来说,建立索引和搜索这两个过程都将用到分析器。例如:对于文本”use an implementation provided Flow library”生成的语汇单元序列可能是:
[use] [implementation] [provide] [flow] [library]
索引过程分析
索引期间,文档域值包含的文本信息需要被转换成语汇单元,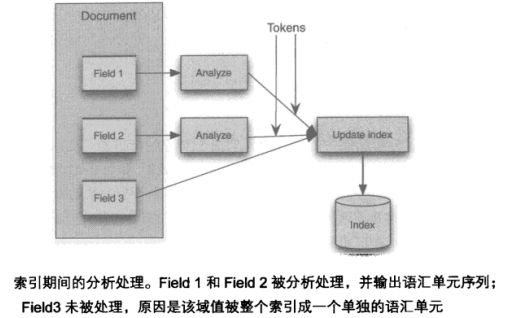
语汇单元的构成
以“the quick brown fox”为例,该文本每个语汇单元都表示一个独立了的单词,一个语汇单元包含了一个文本值(单次本身)和其他的元数据,比如:原是文本从起点到终点的偏移量,语汇单元的类型,位置增量。
词汇单元转换成项
在索引过程中进行分析后,每个语汇单元都作为一个项被传递给索引,、
TokenStream
TokenStream称之为语汇单元流,能在被调用后产生语汇单元序列的类,TokenStream有两个子类Tokenizer和TokenFilter。TokenFilter使用了组合模式,它封装了另外一个TokenStream类。
- Tokenizer负责从java.io.Reader读取字符并创建语汇单元
- TokenFilter负责处理输入的语汇单元,通过新增、删除或修改词汇单元来产生新的语汇单元。

public abstract class TokenFilter extends TokenStream {
/** The source of tokens for this filter. */
protected final TokenStream input;
/** Construct a token stream filtering the given input. */
protected TokenFilter(TokenStream input) {
super(input);
this.input = input;
}
Analyzer与Tokenizer
Analyzer有个抽象的createComponents方法,返回的TokenStreamComponents对象会递归的处理词汇单元(token),因为TokenStreamComponents就是对Tokenizer的封装,也就是说在分析过程中,Analyzer最终是通过Tokenzier来产生词汇单元(token)的。也就是说,Analyzer和Tokenizer是配对使用的。比如:
public final class WhitespaceAnalyzer extends Analyzer {
private final Version matchVersion;
/**
* Creates a new {@link WhitespaceAnalyzer}
* @param matchVersion Lucene version to match See {@link <a href="#version">above</a>}
*/
public WhitespaceAnalyzer(Version matchVersion) {
this.matchVersion = matchVersion;
}
@Override
protected TokenStreamComponents createComponents(final String fieldName,
final Reader reader) {
//whitespaceAnalyzer会调用WithespaceTokenizer生成TokenStreamComponent
return new TokenStreamComponents(new WhitespaceTokenizer(matchVersion, reader));
}
}
实例:
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.LowerCaseTokenizer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.util.Version;
import java.io.Reader;
/**
* Created by liuzhijun on 2014/8/6.
*/
public class SimpleAnalyzer extends Analyzer {
@Override
protected TokenStreamComponents createComponents(String fieldName, Reader reader) {
return new TokenStreamComponents(new LowerCaseTokenizer(Version.LUCENE_4_9, reader));
}
public static void main(String[] args) throws Exception{
SimpleAnalyzer simpleAnalyzer = new SimpleAnalyzer();
TokenStream ts = simpleAnalyzer.tokenStream("title", "this is AN title");
ts.reset();
CharTermAttribute term = ts.getAttribute(CharTermAttribute.class);
while(ts.incrementToken()){
System.out.println("["+term+"]");
}
}
}
在solr schema.xml文件中即可以仅指定Analyzer:
<fieldtype name="nametext" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.WhitespaceAnalyzer"/>
</fieldtype>
也可以直接指定TokenizerFactory来产生词汇单元(token),这种方式处理文本的时候更加精细:
<fieldtype name="text" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldtype>
参考:https://wiki.apache.org/solr/AnalyzersTokenizersTokenFilters