内存管理--页表机制
内存映射过程示意图:
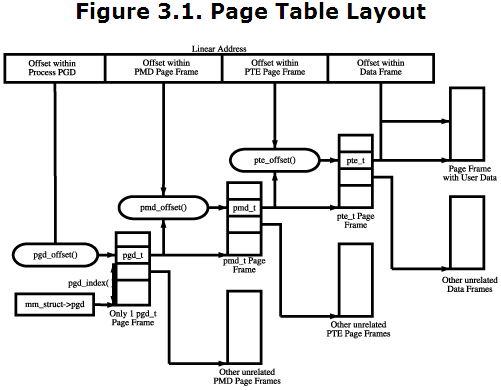
cr3寄存器指向页目录指针表pdpt
建立永久的分页机制
在前面的内存映射介绍中,init_memory_mapping()只是构建了内核页表,作为临时的分页映射。例如只对高端内存固定映射区创建了页表结构,并没有对高端内存区永久映射区进行初始化。setup_arch()在执行完init_memory_mapping()和initmem_init()后,就会调用arch/x86/mm/init_32.c:paging_init()建立虚拟内存管理要用到的完整页表和永久分页机制。如下:
/*
* paging_init() sets up the page tables - note that the first 8MB are
* already mapped by head.S.
*
* This routines also unmaps the page at virtual kernel address 0, so
* that we can trap those pesky NULL-reference errors in the kernel.
*/
void __init paging_init(void)
{
pagetable_init();
__flush_tlb_all();
kmap_init();
/*
* NOTE: at this point the bootmem allocator is fully available.
*/
olpc_dt_build_devicetree();
sparse_memory_present_with_active_regions(MAX_NUMNODES);
sparse_init();
zone_sizes_init();
}
该函数建立完整的页表,注意起始的8MB已经被head_32.S映射了。该函数会取消虚拟地址0处的页面映射,以便我们可以在内核中陷入并跟踪那些麻烦的NULL引用错误。它的主要工作包括页表初始化、内核永久映射区初始化、稀疏内存映射初始化、管理区初始化。下面重点讨论该函数。
static void __init pagetable_init(void)
{
pgd_t *pgd_base = swapper_pg_dir;
permanent_kmaps_init(pgd_base);
}
static void __init permanent_kmaps_init(pgd_t *pgd_base)
{
unsigned long vaddr;
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
vaddr = PKMAP_BASE; /* 该阶段,也就是永久内存映射区的页表初始化 */
page_table_range_init(vaddr, vaddr + PAGE_SIZE*LAST_PKMAP, pgd_base);
pgd = swapper_pg_dir + pgd_index(vaddr);
pud = pud_offset(pgd, vaddr);
pmd = pmd_offset(pud, vaddr);
pte = pte_offset_kernel(pmd, vaddr);
pkmap_page_table = pte; /* 将永久映射区间映射的第一个页表项保存到pkmap_page_table中 */
}
只有定义了使用高端内存,才会有高端永久映射区。首先用pgd_base保存页全局目录表的起始地址swapper_pg_dir。而后在函数permanent_kmaps_init()中,调用page_table_range_init()建立页表,这个函数在前面分析过,它会先根据永久映射区起始地址PKMAP_BASE,获取pgd表项索引、pmd表项索引,然后建立下一级pmd表,和最终的pte页表。第一个页表项保存到pkmap_page_table中。如果内核不划分高端内存,则permanent_kmaps_init()什么也不做。注意paging_init()初始化完页表后,要用__flush_tlb_all()刷新缓存TLB中的映射内容。
static void __init kmap_init(void)
{
unsigned long kmap_vstart;
/*
* Cache the first kmap pte:
*/得到高端固定内存映射区域的起始内存的页表,将这个页表
放到kmap_pte变量中。确切的说应该是固定内存中的临时内存映射区域 */
kmap_vstart = __fix_to_virt(FIX_KMAP_BEGIN);/*得到固定映射区的临时映射区的虚拟地址*/
kmap_pte = kmap_get_fixmap_pte(kmap_vstart);/*得到固定映射区中的临时映射区的起始页表项*/
kmap_prot = PAGE_KERNEL;
}
该函数首先把高端固定映射区(即高端临时内存映射区)的起始地址FIX_KMAP_BEGIN转换成虚拟地址,然后获取它的pte页表项,并保存到全局的kmap_pte中。
内存管理
void __init zone_sizes_init(void)
{
unsigned long max_zone_pfns[MAX_NR_ZONES];
memset(max_zone_pfns, 0, sizeof(max_zone_pfns));
#ifdef CONFIG_ZONE_DMA
max_zone_pfns[ZONE_DMA] = MAX_DMA_PFN;
#endif
#ifdef CONFIG_ZONE_DMA32
max_zone_pfns[ZONE_DMA32] = MAX_DMA32_PFN;
#endif
max_zone_pfns[ZONE_NORMAL] = max_low_pfn;
#ifdef CONFIG_HIGHMEM
max_zone_pfns[ZONE_HIGHMEM] = max_pfn;
#endif
free_area_init_nodes(max_zone_pfns);
}
在“内存描述”一节中对各种管理区类型做了详细介绍,这里首先用数组max_zone_pfns保存各种类型管理区的最大页面数,宏MAX_DMA_ADDRESS在arch/x86/include/asm/dma.h中定义,表示能执行DMA传输的最大地址,其中x86-32非PAE模式下MAX_DMA_ADDRESS为PAGE_OFFSET + 0x1000000,即从内核空间开始处的16MB为DMA区的地址范围,因此DMA区的地址范围为3G~3G+16M这一段空间。把这个最大地址转换成页帧号保存到max_zone_pfns数组,接着保存NORMAL区和HIGHMEM区的最大页面号。最后调用核心函数mm/page_alloc.c:free_area_init_nodes()初始化所有pg_data_t内存节点的各种管理区数据,传入参数为由各管理区最大PFN构成的数组
void __init free_area_init_nodes(unsigned long *max_zone_pfn)
{
unsigned long nid;
int i;
/* Sort early_node_map as initialisation assumes it is sorted */
sort_node_map(); /* 将活动区域进行排序 */
/* 记录管理区的界限 */
memset(arch_zone_lowest_possible_pfn, 0,
sizeof(arch_zone_lowest_possible_pfn));
memset(arch_zone_highest_possible_pfn, 0,
sizeof(arch_zone_highest_possible_pfn));
/* 找出活动内存中最小的页面 */
arch_zone_lowest_possible_pfn[0] = find_min_pfn_with_active_regions();
arch_zone_highest_possible_pfn[0] = max_zone_pfn[0];
for (i = 1; i < MAX_NR_ZONES; i++) {
if (i == ZONE_MOVABLE)
continue;
/* 假定区域连续,下一个区域的最小页面为上一个区的最大页面 */
arch_zone_lowest_possible_pfn[i] =
arch_zone_highest_possible_pfn[i-1];
arch_zone_highest_possible_pfn[i] =
max(max_zone_pfn[i], arch_zone_lowest_possible_pfn[i]);
}
/* 对ZONE_MOVABLE区域设置为0 */
arch_zone_lowest_possible_pfn[ZONE_MOVABLE] = 0;
arch_zone_highest_possible_pfn[ZONE_MOVABLE] = 0;
/* 找出每个节点上ZONE_MOVABLE区的开始页面号 */
memset(zone_movable_pfn, 0, sizeof(zone_movable_pfn));
find_zone_movable_pfns_for_nodes(zone_movable_pfn);
/* 打印管理区的范围 */
printk("Zone PFN ranges:\n");
for (i = 0; i < MAX_NR_ZONES; i++) {
if (i == ZONE_MOVABLE)
continue;
printk(" %-8s %0#10lx -> %0#10lx\n",
zone_names[i],
arch_zone_lowest_possible_pfn[i],
arch_zone_highest_possible_pfn[i]);
}
/* 打印每个节点上ZONE_MOVABLE区开始的页面号 */
printk("Movable zone start PFN for each node\n");
for (i = 0; i < MAX_NUMNODES; i++) {
if (zone_movable_pfn[i])
printk(" Node %d: %lu\n", i, zone_movable_pfn[i]);
}
/* 打印early_node_map[] */
printk("early_node_map[%d] active PFN ranges\n", nr_nodemap_entries);
for (i = 0; i < nr_nodemap_entries; i++)
printk(" %3d: %0#10lx -> %0#10lx\n", early_node_map[i].nid,
early_node_map[i].start_pfn,
early_node_map[i].end_pfn);
/* 初始化每个节点 */
mminit_verify_pageflags_layout(); /* 调试用 */
setup_nr_node_ids();
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
/* zone中数据的初始化,伙伴系统建立,但是没有页面
和数据,页面在后面的mem_init中得到 */
free_area_init_node(nid, NULL,
find_min_pfn_for_node(nid), NULL);
/* 对该节点上的任何内存区 */
if (pgdat->node_present_pages)
node_set_state(nid, N_HIGH_MEMORY);
/* 内存的相关检查 */
check_for_regular_memory(pgdat);
}
}
void __paginginit free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn, unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid);
pgdat->node_id = nid;
/* 这个已在前面调用一个函数得到 */
pgdat->node_start_pfn = node_start_pfn;
/* 计算系统中节点nid的所有物理页面并保存在数据结构中 */
calculate_node_totalpages(pgdat, zones_size, zholes_size);
/* 当节点只有一个时,将节点的map保存到全局变量中 */
alloc_node_mem_map(pgdat);
#ifdef CONFIG_FLAT_NODE_MEM_MAP
printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
nid, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
#endif
/* zone中相关数据的初始化,包括伙伴系统,等待队列,相关变量,
数据结构、链表等 */
free_area_init_core(pgdat, zones_size, zholes_size);
}
static void __paginginit free_area_init_core(struct pglist_data *pgdat,
unsigned long *zones_size, unsigned long *zholes_size)
{
enum zone_type j;
int nid = pgdat->node_id;
unsigned long zone_start_pfn = pgdat->node_start_pfn;
int ret;
pgdat_resize_init(pgdat);
pgdat->nr_zones = 0;
init_waitqueue_head(&pgdat->kswapd_wait);
pgdat->kswapd_max_order = 0;
pgdat_page_cgroup_init(pgdat);
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, realsize, memmap_pages;
enum lru_list l;
/* 下面的两个函数会获得指定节点的真实内存大小 */
size = zone_spanned_pages_in_node(nid, j, zones_size);
realsize = size - zone_absent_pages_in_node(nid, j,
zholes_size);
/*
* Adjust realsize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = /* 存放页面所需要的内存大小 */
PAGE_ALIGN(size * sizeof(struct page)) >> PAGE_SHIFT;
if (realsize >= memmap_pages) {
realsize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
printk(KERN_WARNING
" %s zone: %lu pages exceeds realsize %lu\n",
zone_names[j], memmap_pages, realsize);
/* Account for reserved pages */
if (j == 0 && realsize > dma_reserve) {
realsize -= dma_reserve; /* 减去为DMA保留的页面 */
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
/* 如果不是高端内存区 */
if (!is_highmem_idx(j))
nr_kernel_pages += realsize;
nr_all_pages += realsize;
/* 下面为初始化zone结构的相关变量 */
zone->spanned_pages = size;
zone->present_pages = realsize;
#ifdef CONFIG_NUMA
zone->node = nid;
zone->min_unmapped_pages = (realsize*sysctl_min_unmapped_ratio)
/ 100;
zone->min_slab_pages = (realsize * sysctl_min_slab_ratio) / 100;
#endif
zone->name = zone_names[j];
spin_lock_init(&zone->lock);
spin_lock_init(&zone->lru_lock);
zone_seqlock_init(zone);
zone->zone_pgdat = pgdat;
zone->prev_priority = DEF_PRIORITY;
zone_pcp_init(zone);
for_each_lru(l) { /* 初始化链表 */
INIT_LIST_HEAD(&zone->lru[l].list);
zone->reclaim_stat.nr_saved_scan[l] = 0;
}
zone->reclaim_stat.recent_rotated[0] = 0;
zone->reclaim_stat.recent_rotated[1] = 0;
zone->reclaim_stat.recent_scanned[0] = 0;
zone->reclaim_stat.recent_scanned[1] = 0;
zap_zone_vm_stats(zone);
zone->flags = 0;
if (!size)
continue;
/* 需要定义相关宏 */
set_pageblock_order(pageblock_default_order());
/* zone中变量pageblock_flags,表示从启动分配器中进行内存申请 */
setup_usemap(pgdat, zone, size);
/* zone中的任务等待队列和zone的伙伴系统(MAX_ORDER个链表)的初始化 */
ret = init_currently_empty_zone(zone, zone_start_pfn,
size, MEMMAP_EARLY);
BUG_ON(ret);
/* zone中page相关属性的初始化工作 */
memmap_init(size, nid, j, zone_start_pfn);
zone_start_pfn += size;
}
}
void __paginginit free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn, unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid);
pgdat->node_id = nid;
pgdat->node_start_pfn = node_start_pfn;
/*计算节点占用的总页面数和除去洞的实际总页面数*/
calculate_node_totalpages(pgdat, zones_size, zholes_size);
/*分配节点的mem_map*/
alloc_node_mem_map(pgdat);
#ifdef CONFIG_FLAT_NODE_MEM_MAP
printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
nid, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
#endif
/*初始化节点中的关键数据*/
free_area_init_core(pgdat, zones_size, zholes_size);
}
static void __meminit calculate_node_totalpages(struct pglist_data *pgdat,
unsigned long *zones_size, unsigned long *zholes_size)
{
unsigned long realtotalpages, totalpages = 0;
enum zone_type i;
/*遍历节点的所有管理区*/
for (i = 0; i < MAX_NR_ZONES; i++)
totalpages += zone_spanned_pages_in_node(pgdat->node_id, i,
zones_size);/*计算第i个管理区的页面数*/
pgdat->node_spanned_pages = totalpages;/*保存总页面数*/
realtotalpages = totalpages;
for (i = 0; i < MAX_NR_ZONES; i++)/*计算实际的总页面数(不包括洞)*/
realtotalpages -=
zone_absent_pages_in_node(pgdat->node_id, i,
zholes_size);
pgdat->node_present_pages = realtotalpages;/*保存可用页面数*/
printk(KERN_DEBUG "On node %d totalpages: %lu\n", pgdat->node_id,
realtotalpages);
}
/*
* Set up the zone data structures:
* - mark all pages reserved
* - mark all memory queues empty
* - clear the memory bitmaps
*/
static void __paginginit free_area_init_core(struct pglist_data *pgdat,
unsigned long *zones_size, unsigned long *zholes_size)
{
enum zone_type j;
int nid = pgdat->node_id;
unsigned long zone_start_pfn = pgdat->node_start_pfn;
int ret;
pgdat_resize_init(pgdat);/*初始化node_size_lock*/
pgdat->nr_zones = 0;
init_waitqueue_head(&pgdat->kswapd_wait);/*初始化页换出进程的等待队列*/
pgdat->kswapd_max_order = 0;
pgdat_page_cgroup_init(pgdat);
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, realsize, memmap_pages;
enum lru_list l;
/*计算该管理区的总页面数和实际可用页面数*/
size = zone_spanned_pages_in_node(nid, j, zones_size);
realsize = size - zone_absent_pages_in_node(nid, j,
zholes_size);
/*
* Adjust realsize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = /*计算该管理区中要使用多少页面来完成映射*/
PAGE_ALIGN(size * sizeof(struct page)) >> PAGE_SHIFT;
/*如果实际可用页面大于或等于需要用来映射的页面,则用前者减去后者再保存*/
if (realsize >= memmap_pages) {
realsize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else/*否则的话说明需要映射的页面太多超过了管理区可用内存的范围*/
printk(KERN_WARNING
" %s zone: %lu pages exceeds realsize %lu\n",
zone_names[j], memmap_pages, realsize);
/* Account for reserved pages */
if (j == 0 && realsize > dma_reserve) {
realsize -= dma_reserve;
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))/*如果不是高端内存管理区*/
nr_kernel_pages += realsize;
nr_all_pages += realsize;
zone->spanned_pages = size; /*保存总页面数*/
zone->present_pages = realsize; /*保存剩余的可用页面数*/
#ifdef CONFIG_NUMA
zone->node = nid;
zone->min_unmapped_pages = (realsize*sysctl_min_unmapped_ratio)
/ 100;
zone->min_slab_pages = (realsize * sysctl_min_slab_ratio) / 100;
#endif
zone->name = zone_names[j];
spin_lock_init(&zone->lock);
spin_lock_init(&zone->lru_lock);
zone_seqlock_init(zone);
zone->zone_pgdat = pgdat; /*指向管理区所属节点*/
zone->prev_priority = DEF_PRIORITY;
zone_pcp_init(zone);
for_each_lru(l) {
INIT_LIST_HEAD(&zone->lru[l].list);
zone->reclaim_stat.nr_saved_scan[l] = 0;
}
/*回收状态中的各项都初始化为0*/
zone->reclaim_stat.recent_rotated[0] = 0;
zone->reclaim_stat.recent_rotated[1] = 0;
zone->reclaim_stat.recent_scanned[0] = 0;
zone->reclaim_stat.recent_scanned[1] = 0;
zap_zone_vm_stats(zone);
zone->flags = 0;
if (!size)
continue;
set_pageblock_order(pageblock_default_order());
setup_usemap(pgdat, zone, size);/*为pageblock_flags分配空间*/
/*初始化管理区的等待队列(wait table)和标识空闲块的结构(free_area)*/
ret = init_currently_empty_zone(zone, zone_start_pfn,
size, MEMMAP_EARLY);
BUG_ON(ret);
/*设定管理区页面的相关信息*/
memmap_init(size, nid, j, zone_start_pfn);
zone_start_pfn += size;
}
}
(1)free_area_init_nodes()函数用于初始化所有的节点和它们的管理区数据。它会对系统中每个活动节点(即内存簇)调用free_area_init_node(),使用add_active_range()提供的页面范围来计算各节点上每种管理区和洞的大小。如果两个相邻管理区的最大PFN相同,则表明后面这个管理区是空的。例如,如果arch_max_dma_pfn == arch_max_dma32_pfn,则表明arch_max_dma32_pfn没有页面。我们假定管理区是连续的,即后一种管理区的开始位置紧接着前一种管理区的结束位置。例如ZONE_DMA32开始于at arch_max_dma_pfn。函数先计算各种管理区的下限页面号和上限页面号,保存在两个数组中,对于连续的相邻管理区(只有ZONE_MOVABLE管理区的内存是不连续的),后一个管理区的下限页面号为前一个管理区的上限页面号。而ZONE_MOVABLE的上下限页面号均设为0。然后调用find_zone_movable_pfns_for_nodes()找出每个节点上ZONE_MOVABLE的开始PFN。
(2)对每个节点,调用free_area_init_node(),传入参数为节点ID,各个管理区的大小,节点的开始页面号,各洞的大小。该函数先调用calculate_node_totalpages()计算节点上的所有物理页面,并保存在节点的pgdat数据结构中,从“内存描述”一节中可知,节点pg_data_t结构中保存了该节点的所有管理区数据。然后调用free_area_init_core()初始化各个zone中相关数据,包括伙伴系统、等待队列、相关变量、数据结构、链表等。
(3)free_area_init_core()用于设置管理区的各个数据结构,包括标记管理区的所有页面,标记所有内存空队列,清除内存位图。该函数对节点上的每个管理区,计算它需要映射的真实页面数realsize(即真实内存大小),注意对DMA区这需要减去为DMA保留的页面。然后初始化该管理区的zone数据结构中的相关变量,包括总页面数、真实页面数即realsize、未映射页面数的下限(低于此值时将进行页面回收)、用于slab分配器的页面数下限、保护伙伴系统和页面回收的LRU链表的自旋锁、LRU队列初始化、页面回收状态域、用于管理区使用情况统计的vm_stats置0,等等。最后调用init_currently_empty_zone()初始化zone中的任务等待队列和伙伴系统,调用memmap_init()初始化zone中所有page的相关属性。
节点和管理区的关键数据已完成初始化,内核在后面为内存管理做得一个准备工作就是将所有节点的管理区都链入到zonelist中,便于后面内存分配工作的进行
管理区分配机制
start_kernel()在执行完setup_arch()后即建立起永久分页机制,然后就会调用mm/page_alloc.c:build_all_zonelists()来初始化管理区分配机制,它通过对每种管理区维护一个管理区队列来实现分配和回收,因此整个初始化工作的核心就是构建所有的管理区队列。一个分配请求在zonelist数据结构上进行操作,该结构在include/linux/mmzone.h中,如下:
#ifdef CONFIG_NUMA
#define MAX_ZONELISTS 2
struct zonelist_cache {
unsigned short z_to_n[MAX_ZONES_PER_ZONELIST]; /* zone->nid */
DECLARE_BITMAP(fullzones, MAX_ZONES_PER_ZONELIST); /* zone full? */
unsigned long last_full_zap; /* when last zap'd (jiffies) */
};
#else
#define MAX_ZONELISTS 1
struct zonelist_cache;
#endif
struct zoneref {
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
};
/*
* One allocation request operates on a zonelist. A zonelist
* is a list of zones, the first one is the 'goal' of the
* allocation, the other zones are fallback zones, in decreasing
* priority.
*
* If zlcache_ptr is not NULL, then it is just the address of zlcache,
* as explained above. If zlcache_ptr is NULL, there is no zlcache.
* *
* To speed the reading of the zonelist, the zonerefs contain the zone index
* of the entry being read. Helper functions to access information given
* a struct zoneref are
*
* zonelist_zone()<span style="white-space:pre"> </span>- Return the struct zone * for an entry in _zonerefs
* zonelist_zone_idx()<span style="white-space:pre"> </span>- Return the index of the zone for an entry
* zonelist_node_idx()<span style="white-space:pre"> </span>- Return the index of the node for an entry
*/
struct zonelist {
struct zonelist_cache *zlcache_ptr; // NULL or &zlcache
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
#ifdef CONFIG_NUMA
struct zonelist_cache zlcache; // optional ...
#endif
};
zonelist在节点的pg_data_t结构中维护,以作为节点的备用内存区,当节点没有可用内存时,就从队列中分配内存。一个zonelist表示一个管理区的一个队列,队列中的第一个管理区是分配的目标,其他则为备用管理区,以优先级递减的方式存放在队列中。zonelist_cache结构缓存了每个zonelist中的一些关键信息,以便在get_page_from_freelist()中扫描可用页面时,有更小的开销。其中位图fullzones用来跟踪当前zonelist中哪些管理区开始内存不足了;数组z_to_n[]把zonelist中的每个管理区映射到它的节点id,以便我们能估计在当前进程允许的内存范围内节点是否被设置。zoneref则包含了zonelist中实际的zone信息,封装成一个结构是为了避免解引用时进入一个大的结构体内并且搜索表格。
在zonelist中,zlcache_ptr指针用来标识是否有zlcache。如果非空,则就是zlcache的地址;如果为空,则表示没有zlcache。为了加快zonelist的读取速度,zoneref保存了要读取条目的管理区索引。include/linux/mmzone.h中定义了一些访问zoneref的函数。zonelist_zone()函数返回zoneref中的zone,zonelist_zone_idx()为一个条目返回管理区索引,zonelist_node_idx()为一个条目返回zone中的节点索引。
mm/page_alloc.c:build_all_zonelists()函数如下,这里介绍非NUMA的情况:
static void zoneref_set_zone(struct zone *zone, struct zoneref *zoneref)
{
zoneref->zone = zone;
zoneref->zone_idx = zone_idx(zone);
}
/*
* 构建管理区环形分配队列,把节点上的所有管理区添加到队列中
*/
static int build_zonelists_node(pg_data_t *pgdat, struct zonelist *zonelist,
int nr_zones, enum zone_type zone_type)
{
struct zone *zone;
BUG_ON(zone_type >= MAX_NR_ZONES);
zone_type++;
do {
zone_type--;
zone = pgdat->node_zones + zone_type;
if (populated_zone(zone)) { /* 如果以页面为单位的管理区的总大小不为0 */
zoneref_set_zone(zone, /* 将管理区添加到链表中 */
&zonelist->_zonerefs[nr_zones++]);
check_highest_zone(zone_type);
}
} while (zone_type);
return nr_zones;
}
#ifdef CONFIG_NUMA
/* ...... */
static void build_zonelists(pg_data_t *pgdat)
{
/* ...... */
}
static void build_zonelist_cache(pg_data_t *pgdat)
{
/* ...... */
}
#else /* non CONFIG_NUMA */
/* ...... */
static void build_zonelists(pg_data_t *pgdat)
{
int node, local_node;
enum zone_type j;
struct zonelist *zonelist;
local_node = pgdat->node_id;
zonelist = &pgdat->node_zonelists[0];
/* 将zone添加到zone链表中,这样,zone中page的
分配等操作将依靠这个环形的链表 */
j = build_zonelists_node(pgdat, zonelist, 0, MAX_NR_ZONES - 1);
/*
* Now we build the zonelist so that it contains the zones
* of all the other nodes.
* We don't want to pressure a particular node, so when
* building the zones for node N, we make sure that the
* zones coming right after the local ones are those from
* node N+1 (modulo N)
*/
/* 对其他在线的节点创建zonelist */
for (node = local_node + 1; node < MAX_NUMNODES; node++) {
if (!node_online(node))
continue;
j = build_zonelists_node(NODE_DATA(node), zonelist, j,
MAX_NR_ZONES - 1);
}
for (node = 0; node < local_node; node++) {
if (!node_online(node))
continue;
j = build_zonelists_node(NODE_DATA(node), zonelist, j,
MAX_NR_ZONES - 1);
}
zonelist->_zonerefs[j].zone = NULL;
zonelist->_zonerefs[j].zone_idx = 0;
}
/* 构建zonelist缓存:对非NUMA的zonelist信息,只是把zlcache_ptr设成NULL */
static void build_zonelist_cache(pg_data_t *pgdat)
{
pgdat->node_zonelists[0].zlcache_ptr = NULL;
}
#endif /* CONFIG_NUMA */
/* 返回int值,因为可能通过stop_machine()调用本函数 */
static int __build_all_zonelists(void *dummy)
{
int nid;
#ifdef CONFIG_NUMA
memset(node_load, 0, sizeof(node_load));
#endif
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
/* 创建zonelists,这个队列用来在分配内存时回绕,循环访问 */
build_zonelists(pgdat);
/* 创建zonelist缓存信息:在非NUMA中,仅仅是把相关缓存变量设成NULL */
build_zonelist_cache(pgdat);
}
return 0;
}
void build_all_zonelists(void)
{
/* 设置全局变量current_zonelist_order */
set_zonelist_order();
/* 对所有节点创建zonelists */
if (system_state == SYSTEM_BOOTING) { /* 系统正在引导时 */
__build_all_zonelists(NULL);
mminit_verify_zonelist(); /* 调试用 */
cpuset_init_current_mems_allowed();
} else {
/* 非引导时要停止所有cpu以确保没有使用zonelist */
stop_machine(__build_all_zonelists, NULL, NULL);
/* cpuset refresh routine should be here */
}
/* 计算所有zone中可分配的页面数之和 */
vm_total_pages = nr_free_pagecache_pages();
/*
* Disable grouping by mobility if the number of pages in the
* system is too low to allow the mechanism to work. It would be
* more accurate, but expensive to check per-zone. This check is
* made on memory-hotadd so a system can start with mobility
* disabled and enable it later
*/
if (vm_total_pages < (pageblock_nr_pages * MIGRATE_TYPES))
page_group_by_mobility_disabled = 1;
else
page_group_by_mobility_disabled = 0;
printk("Built %i zonelists in %s order, mobility grouping %s. "
"Total pages: %ld\n",
nr_online_nodes,
zonelist_order_name[current_zonelist_order],
page_group_by_mobility_disabled ? "off" : "on",
vm_total_pages);
#ifdef CONFIG_NUMA
printk("Policy zone: %s\n", zone_names[policy_zone]);
#endif
}
(1)build_all_zonelists()调用__build_all_zonelists()来构建所有管理区队列。如果是系统引导时,则直接调用__build_all_zonelists()对所有节点创建zonelist;如果不是引导时,则要通过stop_machine()来调用__build_all_zonelists(),先停止所有CPU以确保没有使用zonelist。然后用nr_free_pagecache_pages()计算所有zone中可分配的页面总数,如果页面总数太小,则禁用页面分组移动功能(因为这个性能开销比较大)。
(2)在__build_all_zonelists()中,对每个在线节点,调用build_zonelists()创建管理区分配的环形队列,调用build_zonelist_cache()创建队列的缓存信息。这两个函数有NUMA版本和非NUMA版本,这里略去NUMA版本,只介绍非NUMA版本。在build_zonelists()中,对每个在线节点,调用build_zonelists_node()构建环形分配队列,把节点上的所有管理区添加到队列中。在build_zonelist_cache()中,对非NUMA的zonelist信息,只是把zlcache_ptr设成NULL。
(3)在build_zonelists_node()中,通过zoneref_set_zone()将每个产生的管理区添加到队列中。