Hive学习笔记:四浅入
Hive 中的数据库、表、数据与HDFS 的对应关系
Hive 数据库
我们通过在hive 终端,查看数据库信息,可以看出来hive 有一个默认的数据库default,而且我们也知道,hive 数据库对应的是hdfs 上面的一个目录,那么默认的default 数据库到底是对应的哪一个目录呢? 我们可以通过hive 配置文件(hive-site.xml)中一个hive.metastore.warehouse.dir 配置项看到信息。
<!--hive在hdfs上的默认数据存储目录-->
hive数据库操作常用命令
hive操作与mysql操作大部分类似,数据库操作如:
查看库命令:show databases;
选择数据库:use dbName;
创建数据库:create database db1;
创建指定位置的数据库:create database db2 location '/user/hive/db2';(创建完可以在hdfs跟metastore中DBS查看对应关系)
删除数据库:drop database <dbName>;如drop database db1;(删除后可以查看hdfs跟metastore中变化,默认数据库无法删除)
Hive 数据类型

以下着重记录一下date、boolean 和复杂的数据类型,其余的数据类型和mysql 中的几乎一样。
hive表
hive 中的表,对应到hdfs 是文件夹。创建表语句也非常简单,举个简单例子:create table t1(id int);
查看所有表:show tables;
查看表结构:desc tableName; 如:desc t1;
查看表的创建信息:show create table tableName;
重命名表:ALTER TABLE tblName RENAME TO new_tblName;
增加表字段:alter table tblName add columns (columnName type comment 'info');如:alter table t1 add columns (name string comment '姓名');
修改表字段:ALTER TABLE table_name CHANGE
[CLOUMN] col_old_name col_new_name column_type
[CONMMENT col_conmment]
[FIRST|AFTER column_name];
修改表字段:ALTER TABLE tblName CHANGE colName new_colName new_type;如:ALTER TABLE t1 CHANGE name stu_name string comment '姓名';
修改表字段位置:
1、将列排在第一:ALTER TABLE t1 CHANGE stu_name stu_name string FIRST;
2、将列排在某列后面:ALTER TABLE t1 CHANGE stu_name stu_name string AFTER id;
替换表中的列:ALTER TABLE tblName REPLACE COLUMNS (col_spec[, col_spec ...]);如:ALTER TABLE t1 REPLACE COLUMNS (t_id int comment "t_id");
hive中没有直接删除列的方法,使用替换表中的列,达到类似效果。
删除表:drop table tableName;
创建或修改表,可以在hdfs或metastore中查看对应关系,这里不再赘述。
加载数据到表中的两种方式
1、使用命令load data,如:load data local inpath '/home/data/t1' into table t1;
2、使用hadoop fs -put 命令直接将数据放到表在hdfs 的目录下面,如:hdfs dfs -put t1 /user/hive/warehouse/t1/t1_1
简单实验,这里创建t1表只有一列,数据文件t1内容如下
1
2
3
hive客户端可以直接使用hadoop命令和linux命令,使用linux命令需要在命令前加!,如! pwd
查询表数据:select * from t1;
数据加载的两种模式
一般的,我们在加载数据到数据库有两种模式,一种是读模式,一种是写的模式。
写模式指的是在数据加载的时候,对数据合法性进行校验。表中的数据是合乎规范的,有利于快速查询和快速处理。
读模式指的是在数据读取的时候,对数据合法性进行校验,在写入的时候不校验。优点是加载数据非常快,适合于大量数据的一次性加载。
Hive 是读模式。当上传文件到表中,hive 不会对表中的数据进行校验,对于错误的数据格式查询的时候也不会报错,只是显示为NULL。
列分隔符
hive是有默认的分隔符的,默认的行分隔符比较清楚,是'\n',而默认的列分隔符呢,是\001,复杂数据类型的分隔符稍后再说。\001 这个是ASCII 码中一些特殊不常使用不可见字符,在文本中我们可以通过ctrl+v 然后ctrl+a 来输入\001。编辑文本t2如下:
1 zhangshan 2014-01-13 true 2 李四 2015-11-11 false 3 王五 2014-23-23 0
那么问题来了,为了我们能够在上传数据之后就能看到相应的数据,那我们改如何设置hive 表的默认分隔符呢?
其实也是非常的简单,只要我们自创建表的时候指定一下分隔符就可以了,加一些约束分割信息就可以了。如:
create table t2_2( id int commet 'ID', stu_name string comment 'name', stu_birthday date comment 'birthday', online boolean comment 'is online' ) row format delimited fields terminated by '\t' lines terminated by '\n';
指定列分隔符为‘\t’,行分隔符为‘\n’。注意fields terminated by要写在前面。
将数据加载到表中:load data local inpath '/home/data/t2' into table t2_2;

复杂数据类型
hive提供了复合数据类型:
Structs: structs内部的数据可以通过DOT(.)来存取,例如,表中一列c的类型为STRUCT{a INT; b INT},我们可以通过c.a来访问域a
Maps(K-V对):默认分隔符分隔符为\003,怎么敲呢,ctrl+v 和ctrl+c。访问指定域可以通过["指定域名称"]进行,例如,一个Map M包含了一个group-》gid的kv对,gid的值可以通过M['group']来获取
Arrays:分隔符为\002,怎么敲呢,ctrl+v 和ctrl+b,array中的数据为相同类型,例如,假如array A中元素['a','b','c'],则A[1]的值为'b'
1、array使用
create table t3_stu_hobby( id int commet 'ID', stu_name string comment 'stu name', stu_hobby array<string> comment "stu's hobby" ) row format delimited fields terminated by '\t' collection items termianted by ',';
准备t3数据如下:
1 zhangsan sing,coding,swing 2 lisi music,football
加载load data local inpath '/home/data/t3' into table t3_stu_hobby;查询数据:

2、map使用
create table t4_stu_scores( id int commet 'ID', stu_name string comment 'stu name', stu_scores map<string, int> comment "stu's scores" ) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':';准备t4数据如下:
1 zhangsan chinese:60,math:61,englist:62 2 lisi chinese:90,math:60,englist:32加载load data local inpath '/home/data/t4' into table t4_stu_scores;查询数据:

3、struct使用
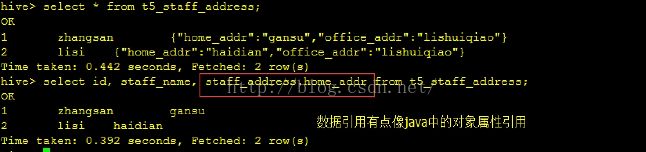
create table t5_staff_address ( id int commet 'ID', staff_name string comment 'staff name', staff_address struct<home_addr:string, office_addr:string> comment "staff's address" ) row format delimited fields terminated by '\t' collection items terminated by ',';准备t5数据如下:
1 zhangsan home_addr:gansu,office_addr:lishuiqiao 2 lisi home_addr:haidian,office_addr:lishuiqiao
加载load data local inpath '/home/data/t4' into table t4_stu_scores;查询数据: