大数据IMF传奇 java开发hadoop wodcount和hdfs文件 !
大数据IMF传奇 java开发hadoop wodcount和hdfs文件建立!
windows 32 ecliplse 连接虚拟机的hadoop集群
1、使用hadoop-eclipse-plugin-2.6.0.jar加入eclipse的插件区G:\IMFBigDataSpark2016\eclipse(java)\plugins
2、切换"Map/Reduce"工作目录,eclipse出现mapreduce视图
eclipse 选择"Window"菜单下选择"Open Perspective",弹出一个窗体,从中选择"Map/Reduce"选项进行切换。
选择"Window"菜单下的"Preference",然后弹出一个窗体,在窗体的左侧,有一列选项,里面会多出"Hadoop Map/Reduce"
选项,点击此选项,选择Hadoop的安装目录 G:\IMFBigDataSpark2016\hadoop-2.6.0
3、建立与Hadoop集群的连接,在Eclipse软件下面的"Map/Reduce Locations"进行右击,弹出一个选项,选择"New Hadoop
Location", 弹出一个窗体。
4、输入信息
Location Name:Hadoop_2.6_Location
Map/Reduce Master
Host:192.168.2.100
Port:50020
DFS Master
Use M/R Master host:192.168.2.100
Port:9000
User name:hadoop
5、开启hadoop集群
[root@master sbin]#./start-dfs.sh
6、eclipse中刷新 Hadoop_2.6_Location ,提示出错连接拒绝
7.配置hadoop
[root@master etc]#cp -R ./hadoop ./hadoop.bak.2.9
vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>The hostname of theRM.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduceapplications.</description>
</property>
</configuration>
8.配置编辑vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>The runtime framework for executing MapReduce jobs.</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>MapReduce JobHistoryServer IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description>MapReduce JobHistoryServer Web UI host:port</description>
</property>
</configuration>
9.start-yarn.sh
[root@master sbin]#./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-hadoop-resourcemanager-master.out
localhost: starting nodemanager, logging to /usr/local/hadoop-2.6.0/logs/yarn-root-nodemanager-master.out
[root@master sbin]#jps
3040 NodeManager
2948 ResourceManager
2518 DataNode
3080 Jps
2665 SecondaryNameNode
2428 NameNode
[root@master sbin]#
10.在ecliplse中刷新,显示集群的目录,ok
11.开始mapreduce的开发
1.上传文件
[root@master sbin]#hadoop dfs -mkdir -p /wordcount/input
[root@master hadoop-2.6.0]#hadoop dfs -put LICENSE.txt /wordcount/input
[root@master hadoop-2.6.0]#hadoop dfs -put README.txt /wordcount/input
2.建立代码工程,编辑代码
New-Other -MapReduce的类型 HelloMapReduce
建包:package com.dtspark.hadoop.hellomapreduce;
新建代码文件:MyFirstMapReduce
run configure:
Arguments:输入
hdfs://Master:9000/wordcount/input hdfs://Master:9000/wordcount/output
3、源代码附后
4、运行报错
4.1编译出错,无法加载主类
Description Resource Path Location Type
The container 'Maven Dependencies' references non existing library 'C:\Users\admin\.m2\repository\org\apache
\hadoop\hadoop-yarn-project\2.7.2\hadoop-yarn-project-2.7.2.jar' SparkApps Build pathBuild Path Problem
以为少了jar包,去seach.maven.org查找,修改maven的pom.xml文件
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-project</artifactId>
<version>2.7.2</version>
</dependency>
提示pom.xml文件出错了,可能依赖有问题。
另外想办法,再建了一个新的测试类,将MyFirstMapReduce的分段代码拷贝过来,结果又是好的!莫名的问题,搞了半天,终于解决了无法加载主类这个的问题。
4.2 运行仍然有问题,考虑检查虚拟机的集群问题,在虚拟机上运行
[root@master mapreduce]#hadoop jar hadoop-mapreduce-examples-2.6.0.jar w
hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount hdfs://Master:9000/wordcount/input hdfs://Master:9000/wordcount/output
发现运行以后就卡住了,去掉yarn的配置,hadoop运行正常,先保持最简配置,不用yarn。hadoop集群正常了
4.3 更改程序的传入参数,再次运行又报错:
hdfs://Master:9000/wordcount/input/README.txt hdfs://Master:9000/My1
运行结果生成,改成IP地址
hdfs://192.168.2.100:9000/wordcount/input hdfs://192.168.2.100:9000/wordcount/output
出错:
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory
hdfs://192.168.2.100:9000/wordcount/output already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:562)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:432)
改成
hdfs://192.168.2.100:9000/wordcount/input hdfs://192.168.2.100:9000/wordcount/output2
[root@master hadoop]#hadoop dfs -chmod 777 /wordcount
4.4再次运行,再次出错:
Exception in thread "main" java.lang.NullPointerException
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1012)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
上网查资料:缺了 winutils.exe ,下载 winutils.exe 把此文件放到hadoop/bin下,在环境变量中配置 HADOOP_HOME Caused by: java.io.IOException: CreateProcess error=216, 该版本的 %1 与您运行的 Windows 版本不兼容。请查看计算机的系统信息,了解是否需要 x86 (32 位)或 x64 (64 位)版本的程序,然后联系软件发布者。
再次下载32位的 winutils.exe,问题解决
4.5运行仍出错,缺了 hadoop.dll问题解决
缺少hadoop.dll,把这个文件拷贝到C:\Windows\System32下面
程序运行ok!
第二个例子:HDFS文件测试
1、源代码附后
2、运行报错
Exception in thread "main" org.apache.hadoop.net.ConnectTimeoutException: Call From pc/192.168.3.6 to master:9000 failed on socket timeout exception: org.apache.hadoop.net.ConnectTimeoutException: 20000 millis timeout while waiting for channel to be ready for connect. ch : java.nio.channels.SocketChannel[connection-pending remote=master/180.168.41.175:9000]; For more details see: http://wiki.apache.org/hadoop/SocketTimeout
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
2、改成ip地址解决:
String uri = "hdfs://master:9000/";
改成
String uri = "hdfs://192.168.2.100:9000/";
3、运行又出错,新的问题:
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=admin, access=WRITE, inode="/":root:supergroup:drwxr-xr-x
[root@master hadoop]#hadoop dfs -ls /
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.16/02/09 04:35:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-rw-r--r-- 1 root supergroup 1366 2016-01-24 05:03 /README.txt
drwxr-xr-x - root supergroup 0 2016-02-08 18:10 /data
-rw-r--r-- 1 root supergroup 24 2016-01-24 07:37 /helloSpark.txt
drwxr-xr-x - root supergroup 0 2016-01-31 22:29 /historyserverforSpark
drwxr-xr-x - root supergroup 0 2016-01-31 08:45 /library
drwx-wx-wx - root supergroup 0 2016-02-08 23:17 /tmp
drwxr-xr-x - root supergroup 0 2016-02-08 21:09 /wordcount
drwxr-xr-x - root supergroup 0 2016-01-24 05:15 /wordcountoutput
drwxr-xr-x - root supergroup 0 2016-02-09 00:11 /wordcountoutput1
4/修改权限,解决方法
hadoop dfs -chmod 777 /
[root@master hadoop]#hadoop dfs -chmod 777 /
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
16/02/09 04:39:23 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using
builtin-java classes where applicable
[root@master hadoop]#
5/运行正常了,
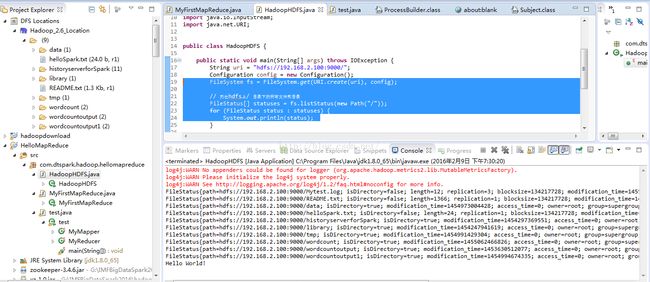
运行结果:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
FileStatus{path=hdfs://192.168.2.100:9000/README.txt; isDirectory=false; length=1366; replication=1;
blocksize=134217728; modification_time=1453629801771; access_time=1454991822379; owner=root; group=supergroup;
permission=rw-r--r--; isSymlink=false}
FileStatus{path=hdfs://192.168.2.100:9000/data; isDirectory=true; modification_time=1454973004428;
access_time=0; owner=root; group=supergroup; permission=rwxr-xr-x; isSymlink=false}
FileStatus{path=hdfs://192.168.2.100:9000/helloSpark.txt; isDirectory=false; length=24; replication=1;
blocksize=134217728; modification_time=1453639061697; access_time=1454970923317; owner=root; group=supergroup;
permission=rw-r--r--; isSymlink=false}
FileStatus{path=hdfs://192.168.2.100:9000/historyserverforSpark; isDirectory=true;
modification_time=1454297369551; access_time=0; owner=root; group=supergroup; permission=rwxr-xr-x;
isSymlink=false}
FileStatus{path=hdfs://192.168.2.100:9000/library; isDirectory=true; modification_time=1454247941619;
access_time=0; owner=root; group=supergroup; permission=rwxr-xr-x; isSymlink=false}
FileStatus{path=hdfs://192.168.2.100:9000/tmp; isDirectory=true; modification_time=1454991429304;
access_time=0; owner=root; group=supergroup; permission=rwx-wx-wx; isSymlink=false}
FileStatus{path=hdfs://192.168.2.100:9000/wordcount; isDirectory=true; modification_time=1454983779042;
access_time=0; owner=root; group=supergroup; permission=rwxr-xr-x; isSymlink=false}
FileStatus{path=hdfs://192.168.2.100:9000/wordcountoutput; isDirectory=true; modification_time=1453630512077;
access_time=0; owner=root; group=supergroup; permission=rwxr-xr-x; isSymlink=false}
FileStatus{path=hdfs://192.168.2.100:9000/wordcountoutput1; isDirectory=true; modification_time=1454994674335;
access_time=0; owner=root; group=supergroup; permission=rwxr-xr-x; isSymlink=false}
Hello World!
两个例子的源代码
第一个例子wodcount的例子源代码如下:
package com.dtspark.hadoop.hellomapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
public class MyFirstMapReduce {
public static class MyMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text event = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
int idx = value.toString().indexOf(" ");
if (idx > 0) {
String e = value.toString().substring(0, idx);
event.set(e);
context.write(event, one);
}
}
}
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException,
InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: EventCount <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "event count");
job.setJarByClass(MyFirstMapReduce.class);
job.setMapperClass(MyMapper.class);
job.setCombinerClass(MyReducer.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
第二个例子创建HDFS文件HelloHDFS的源代码:
package com.dtspark.hadoop.hellomapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
public class HadoopHDFS {
public static void main(String[] args) throws IOException {
String uri = "hdfs://192.168.2.100:9000/";
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), config);
// 列出hdfs上/ 目录下的所有文件和目录
FileStatus[] statuses = fs.listStatus(new Path("/"));
for (FileStatus status : statuses) {
System.out.println(status);
}
// 在hdfs的/Mytest.log,并写入一行文本
FSDataOutputStream os = fs.create(new Path("/Mytest.log"));
os.write("Hello World!".getBytes());
os.flush();
os.close();
// 显示在hdfs的/Mytest.log下指定文件的内容
InputStream is = fs.open(new Path("/Mytest.log"));
IOUtils.copyBytes(is, System.out, 1024, true);
}
}
第一个例子运行结果

第二个例子运行结果