《C++多核编程》 第六章 多线程
6.1 什么是线程
第6章 多线程
在第5章中,我们查看了如何通过将程序分解为多个进程或多个线程而在C++程序中实现并发。我们讨论了进程,它是由操作系统创建的工作单元,解释了用于进程管理的POSIX API以及多个可用于创建进程的系统调用:fork( )、fork-exec( )、system( )和posix_spawn( )。还示范了如何构建C++接口组件、接口类和可用于简化一部分用于进程管理的POSIX API的声明式接口。本章将介绍:
什么是线程
用于线程管理的pthread API
线程调度及优先级
线程竞争范围
扩展thread_object以封装线程属性功能
6.1 什么是线程
线程是进程中可执行代码流的序列,它被操作系统调度,并在处理器或内核上运行。所有的进程都有一个主线程(primary thread)。主线程是进程的控制流或执行线路。具有多个线程的进程拥有和线程数目一样多的控制流。每个线程独立且并发地执行自身的指令序列。具有多个线程的进程是多线程的。线程分为用户级线程和内核级线程。与进程相比,内核级线程在创建、维护和管理方面给操作系统带来的负担都要轻很多,因为与线程关联的信息很少。内核线程被称作轻量级进程,因为它的开销要比进程少。
线程执行程序中无关的并发任务。线程可用于简化具有固有并发的应用程序的程序结构,其方式与通过函数或过程来封装功能性使得应用程序的结构更简单相同。线程可以封装并发功能。线程在一个进程的地址空间中使用最少的共享资源,相比之下,应用程序则使用多个进程。这使得操作系统得到总体更加简单的程序结构。如果正确使用,线程可以通过利用多核处理器并发来改进应用程序的吞吐率和性能。每个线程负责被分配的一个子任务,然后线程独立管理子任务的执行。可以为每个线程指定反映它执行的子任务的重要性的优先级。
6.1.1 用户级线程和内核级线程
6.1.1 用户级线程和内核级线程
线程有3种实现模型:
用户级或应用程序级线程
内核级线程
用户级和内核级混合线程
图6-1显示了3种线程实现模型。图6-1(a)显示了用户级线程,图6-1(b)显示了内核级线程,图6-1(c)则显示了用户线程和内核线程的混合。
 |
| (点击查看大图)(a) 用户级线程 |
 |
| (点击查看大图)(b) 内核级线程 图6-1 |
 |
| (点击查看大图)(c) 混合线程 图6-1(续) |
这些实现之间的较大的区别之一就是它们的模式以及要指派给处理器的线程的能力。这些线程运行在用户模式下或内核模式下。
在用户模式下,进程或线程是执行程序或链接库中的指令,它们不对操作系统内核进行任何调用。
在内核模式下,进程或线程是在进行系统调用,例如访问资源或抛出异常。同时,在内核模式下,进程或线程可以访问在内核空间中定义的对象。
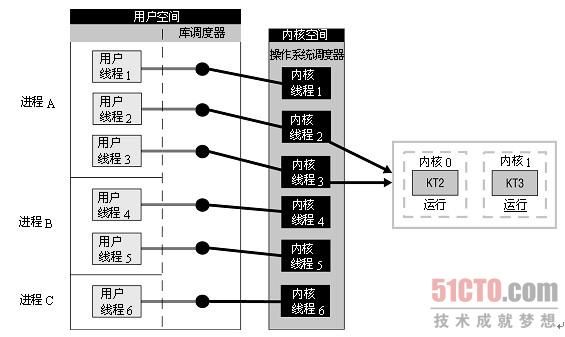
用户级线程驻留在用户空间或模式。运行时库管理这些线程,它也位于用户空间。它们对于操作系统是不可见的,因此无法被调度到处理器内核。每个线程并不具有自身的线程上下文。因此,就线程的同时执行而言,任意给定时刻每个进程只能够有一个线程在运行,而且只有一个处理器内核会被分配给该进程。对于一个进程,可能有成千上万个用户级线程,但是它们对系统资源没有影响。运行时库调度并分派这些线程。如同在图6-1(a)中看到的那样,库调度器从进程的多个线程中选择一个线程,然后该线程和该进程允许的一个内核线程关联起来。内核线程将被操作系统调度器指派到处理器内核。用户级线程是一种"多对一"的线程映射。
内核级线程驻留在内核空间,它们是内核对象。有了内核线程,每个用户线程被映射或绑定到一个内核线程。用户线程在其生命期内都会绑定到该内核线程。一旦用户线程终止,两个线程都将离开系统。这被称作"一对一"线程映射,如图6-1(b)所示。操作系统调度器管理、调度并分派这些线程。运行时库为每个用户级线程请求一个内核级线程。操作系统的内存管理和调度子系统必须要考虑到数量巨大的用户级线程。您必须了解每个进程允许的线程的最大数目是多少。操作系统为每个线程创建上下文。线程的上下文将在本章稍后部分介绍。进程的每个线程在资源可用时都可以被指派到处理器内核。
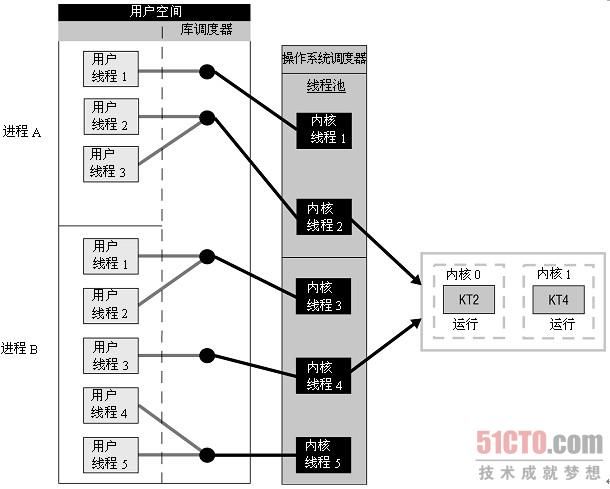
混合线程实现是用户线程和内核线程的交叉,使得库和操作系统都可以管理线程。用户线程由运行时库调度器管理,内核线程由操作系统调度器管理。在这种实现中,进程有着自己的内核线程池。可运行的用户线程由运行时库分派并标记为准备好执行的可用线程。操作系统选择用户线程并将它映射到线程池中的可用内核线程。多个用户线程可以分配给相同的内核线程。在图6-1(c)中,进程A在它的线程池中有两个内核线程,而进程B有3个内核线程。进程A的用户线程2和3被映射到内核线程(2)。进程B有5个线程,用户线程1和2映射到同一个内核线程(3),用户线程4和5映射到内核同一个内核线程(5)。当创建新的用户线程时,只需要简单地将它映射到线程池中现有的一个内核线程即可。这种实现使用了"多对多"线程映射。该方法中尽量使用多对一映射。很多用户线程将会映射到一个内核线程,就像您在前面的示例中所看到的。因此,对内核线程的请求将会少于用户线程的数目。
内核线程池不会被销毁和重建,这些线程总是位于系统中。它们会在必要时分配给不同的用户级线程,而不是当创建新的用户级线程时就创建一个新的内核线程,而纯内核级线程被创建时,就会创建一个新的内核线程。只对池中的每个线程创建上下文。有了内核线程和混合线程,操作系统分配一组处理器内核,进程的线程可以在这些处理器内核之上运行。线程只能在为它们所属线程指派的处理器内核上运行。
在确定线程的调度模型和竞争范围时,用户级线程和内核级线程变得很重要。竞争范围决定了指定的线程与那些线程竞争处理器的使用,而且对于操作系统对大量线程的内存管理也非常重要。
6.1.2 线程上下文
6.1.2 线程上下文
操作系统管理很多进程的执行。有些进程是来自各种程序、系统和应用程序的单独进程,而某些进程来自被分解为很多进程的应用或程序。当一个进程从内核中移出,另一个进程成为活动的,这些进程之间便发生了上下文切换。操作系统必须记录重启进程和启动新进程使之活动所需要的所有信息。这些信息被称作上下文,它描述了进程的现有状态。当进程成为活动的,它可以继续从被抢占的位置开始执行。进程的上下文信息包括:
进程id
指向可执行文件的指针
栈
静态和动态分配的变量的内存
处理器寄存器
进程上下文的多数信息都与地址空间的描述有关。进程的上下文使用很多系统资源,而且会花费一些时间来从一个进程的上下文切换到另一个进程的上下文。线程也有上下文。表6-1将线程上下文和第5章讨论的进程上下文进行了对比。当线程被抢占时,就会发生线程之间的上下文切换。如果线程属于相同的进程,它们共享相同的地址空间,因为线程包含在它们所属于的进程的地址空间内。这样,进程需要恢复的多数信息对于线程而言是不需要的。尽管进程和它的线程共享了很多内容,但最为重要的是其地址空间和资源,有些信息对于线程而言是本地且唯一的,而线程的其他方面包含在进程的各个段的内部。
表6-1
| 上下文内容 |
进 程 |
线 程 |
| 指向可执行文件的指针 |
x |
|
| 栈 |
x |
x |
| 内存(数据段和堆) |
x |
|
| 状态 |
x |
x |
| 优先级 |
x |
x |
| 程序I/O的状态 |
x |
|
| 授予权限 |
x |
|
| 调度信息 |
x |
|
| 审计信息 |
x |
|
| 有关资源的信息 ● 文件描述符 ● 读/写指针 |
x |
|
| 有关事件和信号的信息 |
x |
|
| 寄存器组 ● 栈指针 ● 指令计数器 ● 诸如此类 |
x |
x |
注意:
线程间的同步将在第7章中讨论。
TSD是一种结构体,包含线程私有的数据和信息。TSD可以包含进程全局数据的私有副本,还可以包含线程的信号掩码。信号掩码用来识别特定类型的信号,这些信号在发送给进程时不会被该线程接收。否则,如果操作系统给进程发送一个信号,进程的地址空间中的所有线程也会接收到那个信号。线程会接收所有没有被掩码遮蔽的信号。
线程与它所属的进程共享代码段和栈段。它的指令指针指向进程的代码段的某个位置,是下一条可执行的线程指令,而且栈指针指向进程栈中线程的栈的顶部位置。线程还可以访问任何环境变量。进程的所有资源(例如文件描述符)都将与线程共享。
6.1.3 硬件线程和软件线程
6.1.3 硬件线程和软件线程
线程可以在硬件中实现,也可以在软件中实现。芯片生产商实现了有着多个硬件线程的内核,用作逻辑内核。有着多个硬件线程的内核被称作同时多线程(simultaneous multithreaded,SMT)内核。SMT将多线程的概念引入到硬件中,方式类似于软件线程。支持SMT的处理器在处理器内核中同时执行很多软件线程或进程。让软件线程同时在单独的处理器内核中执行,增加了内核的效率,因为类似I/O延迟等因素产生的等待时间被减到最短。操作系统将逻辑内核按照独特的处理器内核来对待。它们会要求一些冗余的硬件来存储线程的上下文信息,例如指令计数器和寄存器组。根据处理器内核的不同,其他硬件或结构将被复制或在多个线程的上下文之间共享。
Sun公司的UltraSparc T1、IBM公司的Cell Broadband Engine(CBE)以及各种Intel多核处理器利用SMT或芯片级多线程(chip-level multithreading,CMT),实现了每个内核上2个~8个线程。超线程是Intel对SMT的实现,其主要目的就是改善对多线程代码的支持。超线程或SMT技术通过在一个处理器内核上并行执行线程,在特定负载下提供了对CPU资源的有效使用。
6.1.4 线程资源
6.1.4 线程资源
一个进程能够消耗的资源是受限制的。因此,对等线程拥有的全部资源不能够超过进程的资源限制。如果一个线程试图消耗的资源数量多于定义的软件资源限制,它会收到一个信号,被告知达到了进程的资源限制。
当线程利用它们的资源时必须很小心,不能够在它们被取消时将这些资源置于不稳定的状态。如果终止的线程放任文件处于打开状态,可能导致文件受损,或者当应用程序终止时导致数据丢失。在终止之前,线程应当执行一些清理工作,防止这些不期望出现的状况发生
6.2.1 上下文切换
6.2 线程和进程的比较
线程和进程都能够提供并发程序执行。当您决定是使用多个进程还是使用多个线程时,上下文切换需要使用的系统资源、吞吐量、实体间通信、程序简化等都是需要考虑的问题。
6.2.1 上下文切换
当您创建一个进程时,可能只需要主线程这一个线程就可以实现进程的功能了。当进程有着多个并发子任务时,多个线程能够在上下文切换的开销较少的情况下提供子任务的异步执行。如果处理器可用性较低或者只有一个内核,并发执行的进程由于需要进行上下文切换而带来较大的开销。相同的情况下,如果使用线程,只有当下一个要指派到处理器的线程来自另一个进程时,才会发生进程上下文切换。较少的开销意味使用的系统资源较少,而且上下文切换的时间也更短。当然,如果有足够的处理器用于周转,那么上下文切换就不再是一个问题。
6.2.2 吞吐量
6.2.2 吞吐量
使用多个线程可以增加应用程序的吞吐量。当只有一个线程时,I/O请求将会让整个进程暂停。有了多个线程之后,当一个线程等待I/O请求时,应用程序将继续执行。当一个线程被阻塞时,另一个线程便可以执行。整个应用程序不需要等待每个I/O请求被满足,其他不依赖于被阻塞线程的任务可以继续执行。
6.2.3 实体间的通信
6.2.3 实体间的通信
线程与被称为对等线程的进程中其他线程之间,不要求特殊的通信机制。线程可以直接与其他对等线程进行数据的传递和接收。这节省了使用多个进程时,为了建立和维护特殊的通信机制所使用的系统资源。线程是通过使用进程地址空间中的共享内存来通信的。例如,如果进程声明了一个全局队列,进程中的线程A可以保存对等线程B将要处理的文件名。线程B可以从队列中读取该文件名并处理数据。
进程也可以通过共享内存进行通信,但是进程有着独立的地址空间,因此共享内存存在于进行通信的两个进程的地址空间外部。如果有一个进程希望将它处理的文件名传递给其他进程,可以使用消息队列。需要在涉及的进程的地址空间外部建立这个消息队列,而且通常需要大量的设置才能够很好地工作。这增加了用于维护和访问共享内存所使用的时间和空间。
6.2.4 破坏进程数据
6.2.4 破坏进程数据
线程可以很轻易地破坏进程的数据。如果没有同步,线程对相同数据片的写入访问可以导致数据竞争,对于进程则不会这样。每个进程有它自己的数据,而且除非设置特殊通信,否则其他进程不能够访问到它们。进程的隔离的地址空间保护数据不受其他进程无意的破坏。线程共享相同地址空间的事实使得若不使用同步,则数据便会面临被破坏的风险。例如,假定一个进程中包含3个线程:Thread A、Thread B和Thread C。Thread A和Thread B更新某个计数器,Thread C读取每个被更新的值,并将这个值用于计算中。Thread A和Thread B都试图并发地写入到内存的某个位置中,在Thread C读取之前,Thread B重写了Thread A写入的数据。应当使用同步来确保在Thread C读取数据之前,计数器不会被更新。
注意:
线程间和进程间的同步问题将会在第7章中讨论。
6.2.5 删除整个进程
6.2.5 删除整个进程
如果线程产生严重的访问违规,则可能导致整个进程的终止。访问违规不局限于线程,因为它发生在进程的地址空间。线程导致的错误往往比进程导致的错误代价更大。线程可以产生影响所有线程的整个内存空间的数据错误。线程不是隔离的,而进程是隔离的。进程可以发生导致进程终止的访问违规,但是如果违规后果不是很严重,则所有其他进程继续执行,数据错误可以限制在一个进程内。进程可以保护资源不被其他进程任意地访问。线程与进程中所有其他线程共享资源。损害资源的线程会影响整个进程或程序。
6.2.6 被其他程序重用
6.2.6 被其他程序重用
线程依赖于进程,不能够从它们所属的进程中分离开。进程比线程要独立得多。应用程序可以在多个进程之间分配任务,这些进程可以被封装为可以在其他应用程序中使用的模块。线程不能够在创建它们的进程外部生存,因此是不可重用的。
6.2.7 线程与进程的关键类似和差别
6.2.7 线程与进程的关键类似和差别
线程和进程有很多相似之处,也存在巨大的差别。线程和进程都有id、寄存器组、状态和优先级,而且都支持某种调度策略。与进程类似,线程也有一个环境来向操作系统描述实体,即进程上下文或线程上下文。上下文用来重新构建被抢占的进程或线程。尽管进程所需要的信息远多于线程所需要的信息,但它们的目的是相同的。
线程和子进程不需要额外的初始化或准备就能够共享父进程的资源。进程打开的资源对线程或子进程是立即可访问的。与内核实体类似,线程和子进程会竞争对处理器的使用。父进程对子进程或线程有一定的控制。父进程可以对子进程或线程进行如下操作:
取消
挂起
重新开始
改变优先级
线程或进程可以改变自身的属性和创建新的资源,但是它不能够访问属于其他进程的资源。
如同我们已经指出的那样,线程和进程之间最大的差别在于每个进程有自己的进程空间,而线程则包含在所属进程的地址空间内。这就是为何线程可以非常容易地共享资源,而且线程间通信如此简单的原因。子进程有自己的地址空间以及它的父进程的数据段的副本,所以当子进程改动它的数据时,不会影响父进程的数据。如果父进程同子进程期望共享数据,则需要创建一块共享内存区域。共享内存是进程间通信机制的一种类型,其中包含了管道以及先进先出(FIFO)调度策略。进程间通信机制用于在进程之间传递数据。
注意:
进程间通信将在第7章讨论。
尽管进程可以对它的子进程进行控制,对等线程却是处于相同的级别,无论是谁创建了它们。任意线程只要有权使用另一个对等线程的线程id,就能够对该线程进行取消、挂起、重新开始或改变优先级的操作。实际上,进程中的任意线程都可以通过取消主线程来删除进程,从而终止进程中的所有线程。对主线程的任何更改可能会影响进程中的所有线程。如果主线程的优先级发生了变化,则进程中继承该优先级的所有线程也都会发生变化。
表6-2汇总了线程与进程的关键类似和差别。
表6-2
| 线程与进程的类似 |
线程与进程的差别 |
| 都有id、寄存器组、状态、 优先级和调度策略 |
线程共享创建它的进程的地址空间, 进程有自己的地址空间 |
| 都有用于为操作系统 描述实体的属性 |
线程能够对所属进程的数据段进行 直接访问;进程有着父进程的数 据段的自己的副本 |
| 都包含一个信息块 |
线程可以同所属进程的其他线程直 接通信;进程必须使用进程间通 信才能够和兄弟进程进行通信 |
| 都与父进程共享资源 |
线程几乎没有开销, 进程则有相当大的开销 |
| 都可作为与父进程独立的实体 |
创建新的线程很容易,创建新的 进程则需要复制父进程 |
| 创建者可以对线程或进程 进行一些控制 |
线程可以对相同进程的其他线程 进行相当大的控制,进程只能 够对子进程进行控制 |
| 线程与进程的类似 |
线程与进程的差别 |
| 都可以改变它们的属性 |
对主线程的改动(取消、优先级改动等) 可能会影响到进程中其他线程的行为; 对父进程的改动不会影响到子进程 |
| 都可以创建新的资源 |
|
| 都不能够访问另一 个进程的资源 |
|
6.3 设置线程属性
6.3 设置线程属性
存在一些可用来确定线程上下文的关于线程的信息。这些信息用于重建线程的环境。令对等线程相互之间产生区别的是id、定义线程状态的寄存器组、优先级和它的栈。这些属性使得线程有了自己的身份。
POSIX线程库定义了线程属性对象(attribute object),它封装了线程属性的一个子集。这些属性可以被线程的创建者访问和更改。下面是可以被更改的线程属性:
竞争范围
栈大小
栈地址
分离的状态
优先级
调度策略和参数
线程属性对象可以同一个或多个线程关联。属性对象是定义了一个或一组线程的行为的概要(profile)。一旦对象被创建并初始化,可以在对线程创建函数的调用中重复引用它。如果重复使用,便会创建一组有着相同属性的线程。所有使用该属性对象的线程继承所有的属性值。一旦使用线程属性对象创建了线程,多数属性就不能够在线程使用中被改动。
范围属性描述了哪些线程同特定线程竞争资源。线程在两个竞争范围内争夺资源:
进程范围
系统范围
线程依照竞争范围和分配域(它被指派到的处理器集)来同其他线程竞争处理器的使用。有着进程竞争范围的线程同进程中其他线程竞争,而有着系统竞争范围的线程同系统分配的其他进程的线程竞争资源。有着系统范围的线程和系统中所有线程一起被排序和调度。
线程的栈大小和位置是在线程被创建时设置的。如果线程栈的大小和位置没有在创建期间指定,则系统会赋给它默认的大小和位置。默认大小同系统相关,是由进程所允许的线程最大数目、进程地址空间的指定大小、系统资源使用的空间等决定的。线程的栈大小必须足够大,以满足任何函数调用、线程调用的进程外部代码(如库代码)、局部变量存储的需要。有着多个线程的进程应当有足以满足其所有线程栈的栈段。分配给进程的地址空间限制了栈的大小,从而限制了每个线程栈的大小。线程栈地址对于访问有着不同属性的内存区域的应用程序,可能会很重要。当您指定栈的位置时,需要注意的是,线程要求多少空间以及确保该位置不会同其他对等线程的栈发生重叠。
分离的线程是那些已经从它们的创建者中分离出来的线程。它们在终止或退出时,不需要同其他对等线程或主线程进行同步。它们仍共享所属进程的地址空间,但是由于它们是分离的,创建它们的进程或线程不能够对它们进行控制。当线程终止时,线程的id和状态由系统保存。在默认情况下,一旦线程终止,该情况会通知给创建者,线程的id和状态会返回给创建者。如果线程是分离的,则不会使用资源来保存状态或线程id。这些资源立即可以被系统重用。如果线程的创建者不需要在继续处理之前等待线程终止,或者如果线程不要求在终止时同其他对等线程进行任何类型的同步,那么该线程可以成为一个分离的线程。
线程从进程继承调度策略。线程有优先级,而且优先级最高的线程会在较低优先级的线程之前执行。通过对线程区分优先次序,系统中需要立即执行或响应的任务会被指定到处理器上并得到时间片。如果有着更高优先级的线程可以运行,则正在执行的线程会被抢占。线程的优先级可以被降低或提高。调度策略也决定了哪个线程会被指派到处理器上。可使用的策略有先进先出(FIFO)、轮询(RR)等。通常,没有必要在进程执行期间改变线程的调度属性。如果进程环境发生变动,改变了时间约束,使得您需要改进进程的性能,则可能需要对调度进行改动。但是要考虑到改动应用程序中指定进程的调度属性,可能会对应用程序的总体性能产生负面影响。
6.4 线程的结构
6.4 线程的结构
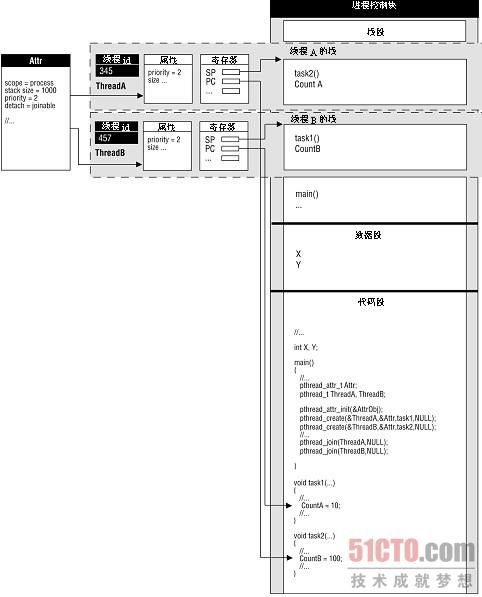
我们已经讨论了进程以及线程同它所属进程的关系。图6-2显示了包含多个线程的进程结构。进程通过上下文和属性区别于系统中其他进程,线程也可以通过上下文和属性区别于其他对等线程。进程有代码段、数据段和栈段。线程同进程共享代码段和栈段。进程的栈通常从内存的高地址开始,向下增长。线程栈以下一个线程栈的开始位置为边界。可以看到,线程栈包含其局部变量。进程的全局变量位于数据段中。Thread A和Thread B的上下文包括线程id、状态、优先级、处理器寄存器等。程序计数器(PC)指向代码段中函数task1()和task2()中下一条可执行指令。栈指针(SP)指向它们各自的栈的顶部。线程属性对象同一个线程或一组线程相关联。在本例中,两个线程使用相同的线程属性。
 |
| (点击查看大图)图6-2 |
6.4.1 线程状态
6.4.1 线程状态
线程是当进程被调度执行时的执行单元。如果进程中只有一个线程,该线程是指派到处理器内核的主线程。如果进程有着多个线程,而且对于该进程有多个处理器可用,那么所有的线程都会被指派到处理器上。
当线程被调度到处理器内核上执行时,它会改变自身的状态。线程状态是指在任意指定时间所处的模式或情形。线程有着同第5章为进程介绍的状态和转换相同的状态和转换。有4种常见的状态:
可运行
运行(活动)
停止
休眠(阻塞)
存在如下的转换:
抢占
接到信号
分派
时间片用完
主线程可以决定整个进程的状态。如果主线程是唯一的线程,则主线程的状态同进程的状态相同。如果主线程在休眠,进程也在休眠。如果主线程在运行,进程也在运行。对于有着多个线程的进程,只有进程中所有线程都处于休眠或停止状态时,我们才能够认为整个进程休眠或停止。另一方面,如果一个线程是活动的(可运行或运行),那么进程会被认为是活动的。
6.4.2 调度和线程竞争范围
6.4.2 调度和线程竞争范围
线程有两种竞争范围:
进程竞争
系统竞争
有着进程竞争范围的线程与相同进程的其他线程进行竞争。这些是混合线程(用户级和内核级线程),系统将创建内核级线程池,用户级线程将映射到它们。这些内核级线程是非绑定(unbound)的,可以映射到一个线程或多个线程。然后内核根据调度属性将内核线程调度到处理器上。
有着系统竞争范围的线程同系统范围内进程的线程进行竞争。这个模型由每个内核级线程对应一个用户级线程组成。用户线程在线程的生命期内都绑定到内核级线程上。内核线程单独负责在一个或多个处理器上调度线程执行。这个模型使用线程的调度属性,根据系统中所有线程来进行线程调度。线程的默认竞争范围根据实现定义。例如,对于Solaris 10,默认竞争范围是进程,但是对于SuSe Linux 2.6.13,默认竞争范围是系统范围。事实上,对于SuSe Linux 2.6.13,根本不支持进程竞争范围。
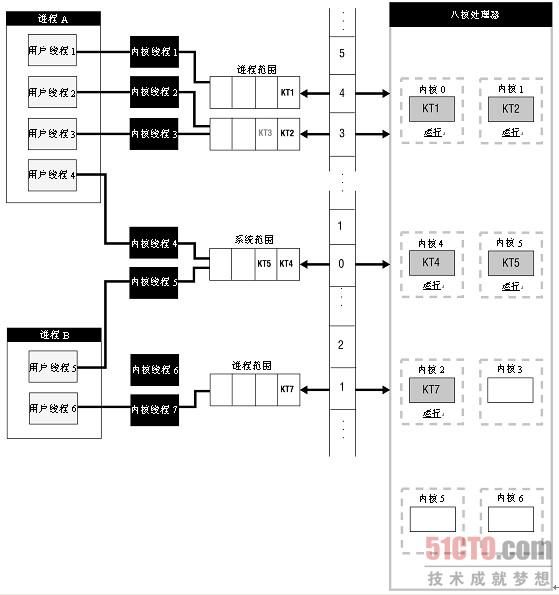
图6-3显示了进程和系统两种线程竞争范围的区别。在有8个内核的多核环境中,有两个进程。进程A有4个线程,进程B有两个线程。进程A的4个线程中的3个线程竞争范围为进程范围,一个线程的竞争范围为系统范围。进程B的两个线程中,一个线程竞争范围为进程范围,一个线程的竞争范围为系统范围。进程A中有着进程范围的线程竞争内核0和1,进程B中有着进程范围的线程将使用内核2。进程A和B中系统范围的线程竞争内核4和5。有着进程范围的线程映射到线程池。进程A的线程池中有3个内核级线程,进程B的线程池中有两个内核级线程。
 |
| (点击查看大图)图6-3 |
6.4.3 调度策略和优先级
6.4.3 调度策略和优先级
进程的调度策略和优先级属于主线程。每个线程可以有着与主线程不同的调度策略和优先级。优先级是拥有最大值和最小值的整数。当区分线程优先次序时,系统中要求立即执行或响应的任务会优先。在一个抢占式的操作系统中,如果有更高优先级(数字越小,优先级越高)而且竞争范围相同的线程可运行,则正在执行的线程会被抢占。
例如,在图6-3中,进程A有两个优先级为3的线程(2和3),还有一个优先级为4的线程(1)。它们被分配到处理器内核0和1上。优先级为4和3的线程是可运行的,每个线程被分配到一个处理器上。一旦优先级为3的线程3变为活动的,则线程1会被抢占,线程3被分配到处理器。在进程B中,有一个线程有着进程竞争范围,而且它的优先级为1。进程B只有一个可用处理器。有着系统竞争范围的线程不会被进程A或B中任何有着进程竞争范围的线程抢占。它们只和其他有着系统竞争范围的线程争夺处理器的使用。
就绪队列被组织为有序列表,其中每个元素是一个优先级。这在第5章中也讨论过。在第5章中,图5-6显示了就绪队列。列表中每个优先级是有着相同优先级的线程的队列。所有有着相同优先级的线程使用调度策略被分配到处理器上,调度策略为FIFO、RR或其他策略。
轮询(RR)调度策略认为所有线程有着相等的优先权,而且只让每个线程在一个时间片内使用处理器。任务的执行是交错的。例如,一个从文本文件中筛选字符的程序被分成3个线程。主线程为线程1,它从文件中读入每一行,然后将读入的内容作为字符串写入到向量中。然后主线程创建3个线程并等待这些线程返回。每个线程有着自己的字符集,它们要将属于该字符集的字符从字符串中删除掉。每个线程利用两个队列,一个队列包含之前已经被另一个线程筛选过的字符串。一旦线程已经筛选了一个字符串,就会将结果写入到第二个队列。队列是全局数据。主线程位于就绪队列中,它可抢占地运行,直到创建了其他线程,然后会休眠,直到所有线程返回。其他的线程有着相等的优先级,而且使用轮询调度策略。线程不能够筛选尚未写到队列中的字符串,因此需要对源队列的访问进行同步。线程测试互斥量,如果互斥量被加锁,那么没有可用的字符串,或者源队列正在被使用。线程必须等待,直到互斥量被解锁。如果互斥量可用,则源队列中有字符串,而且源队列没有被使用。从队列中读取一个字符串,然后线程对字符串进行筛选,并将它写入到输出队列。输出队列作为另一个线程的源队列。在将来某个时刻,线程2被分配到处理器。它的源是包含所有将要被筛选的字符串的向量。线程1必须筛选字符串,然后将筛选过的字符串写入到它的输出队列,这样线程2才有要处理的内容,然后是线程3,等等。RR调度影响有着两个处理器内核的线程的执行。这种调度策略抑制了这个程序的适当执行。我们将在本章后面讨论使用正确的并发模型。
如果使用的是FIFO调度策略,而且优先权较高,则这些任务的执行不会发生交错。分配到处理器上的线程会一直占有处理器,直到它的执行结束。这种调度策略可用于有一组线程需要尽可能快地完成的应用程序。
"其他"调度策略可以是一种定制的调度策略。例如,FIFO调度策略可以被定制为允许线程随机解除阻塞,或者您可以使用能够加速线程执行的适当调度的策略。
6.4.4 调度分配域
6.4.4 调度分配域
FIFO和RR调度策略在多个处理器上具有不同的特性。调度分配域决定了进程或应用程序的线程能够运行在哪些处理器集合上。调度策略会受到处理器内核数目以及进程中线程数目的影响。在从字符串中筛选字符的线程实例中,如果线程的数目同内核的数目相同,则使用RR调度策略会产生较好的吞吐量。但是线程的数目并不总是会同内核数目相同,有可能线程的数目多于内核数目。通常,依赖于内核的数目来大幅度影响应用程序的性能往往不是最好的方法。
6.5 简单的线程程序
6.5 简单的线程程序
下面是一个简单的线程程序示例。这个简单的多线程程序有一个主线程以及线程将要执行的函数。并发模型决定了线程创建和管理的方式。我们将在下一章中讨论并发模型。线程可以一次性创建,或者在特定条件下创建。在示例6-1中,使用了委托模型来说明简单的多线程程序。
示例6-1
- // Example 6-1 Using the delegation model in a simple threaded program.
-
- using namspace std;
- #include <iostream>
- #include <pthread.h>
-
- void *task1(void *X) //define task to be executed by ThreadA
- {
- cout << "Thread A complete" << endl;
- return (NULL);
- }
-
- void *task2(void *X) //define task to be executed by ThreadB
-
- {
- cout << "Thread B complete" << endl;
- return (NULL);
- }
-
- int main(int argc, char *argv[])
- {
- pthread_t ThreadA,ThreadB; // declare threads
-
- pthread_create(&ThreadA,NULL,task1,NULL); // create threads
- pthread_create(&ThreadB,NULL,task2,NULL);
- // additional processing
- pthread_join(ThreadA,NULL); // wait for threads
- pthread_join(ThreadB,NULL);
- return (0);
- }
在示例6-1中,主线程是boss线程。boss线程声明两个线程,即ThreadA和ThreadB。pthread_create( )创建线程并将它们同将要执行的任务关联起来。task1和task2这两个任务被分别发送消息到标准输出。pthread_create( )使得线程立即执行它们分配到的任务。函数pthread_join的工作方式同wait( )对进程的工作方式相同。主线程等待,直到两个线程都返回。图6-4包含了显示示例 6-1的控制流的顺序图。在图6-4中,pthread_create( )使得在主线程的控制流中产生了分支。增加了两个并发执行的控制流,分别是ThreadA和ThreadB。pthread_create( )在创建完线程之后立即返回,因为它是一个异步函数。当每个线程执行自己的指令集合时,pthread_join( )使得主线程等待,直到线程终止并重新加入到主控制流。
 |
| (点击查看大图)图6-4 |
编译和链接线程程序
所有使用POSIX线程库的多线程程序必须包含这个头文件:
- <pthread.h>
为了在Unix或Linux环境中使用g++或gcc命令行编译器来编译和链接多线程程序,需要确保通过使用-l编译器开关将pthread库链接到您的应用程序。这个开关之后紧接的就是库的名称:
- -lpthread
这样将导致您的应用程序链接到同POSIX 1003.1c标准定义的多线程接口兼容的库。名为libpthread.so的pthread库应当位于系统保存标准库的目录下,通常为/usr/lib。如果它位于该标准目录下,则编译行应当类似于:
- g++ -o a.out test_thread.cpp -lpthread
如果它没有位于标准位置,则使用-L选项来让编译器在搜索标准位置之前,首先在特定目录下进行查看:
- g++ -o a.out -L /src/local/lib test_thread.cpp -lpthread
这样就会告知编译器在搜索标准位置之前,首先在/src/local/lib目录下查找pthread库。
注意:
如同您将在本章稍后部分看到的那样,本书中的完整程序都伴随有程序概要。程序概要包含实现细节,例如必需的头文件和库以及编译器和链接指令。概要还包含注释部分,其中包含了在执行程序时需要遵从的任何特殊考虑。对于示例,则没有概要。
6.6 创建线程
6.6 创建线程
pthread库可用于创建、维护和管理多线程程序和应用中的线程。当您创建一个多线程程序时,您可以在进程的执行期间的任何时候创建线程,因为它们是动态的。pthread_create( )在进程的地址空间中创建一个新的线程。
调用形式
- #include <pthread.h>
-
-
int pthread_create(pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
- void *(*start_routine)(void*), void *restrict arg);
参数thread指向将要创建的线程的线程句柄或线程id。新的线程有着由属性对象attr所指定的属性。参数thread立即以arg指定的参数执行start_routine中的指令。如果函数成功地创建了线程,它返回线程id并将这个值保存在thread中。关键字restrict也被加了进来,目的是为了同之前的IEEE标准一致。下面是示例6-1中的对pthread_create( )的调用:
- pthread_create(&ThreadA,NULL,task1,NULL);
如果成功,函数返回0。如果函数没有成功,则不会创建新的线程,而且函数返回一个错误号。如果系统没有资源来创建线程,或者达到了进程能够拥有的线程数目限制,那么函数会失败。如果线程属性无效,或者调用线程没有权限来设置必要的线程属性,函数也会失败。
6.6.1 向线程传递参数
6.6.1 向线程传递参数
程序清单6-1显示了主线程从命令行给线程执行的函数传递一个参数。命令行参数还用于确定要创建的线程的数目。
程序清单6-1
- //Listing 6-1 Passing arguments to a thread from the command line.
-
- 1 using namespace std;
- 2
- 3 #include <iostream>
- 4 #include <pthread.h>
- 5
- 6
- 7 void *task1(void *X)
- 8 {
- 9 int *Temp;
- 10 Temp = static_cast<int *>(X);
- 11
- 12 for(int Count = 0;Count < *Temp;Count++)
- 13 {
- 14 cout << "work from thread: " << Count << endl;
- 15 }
- 16 cout << "Thread complete" << endl;
- 17 return (NULL);
- 18 }
- 19
- 20
- 21
- 22 int main(int argc, char *argv[])
- 23 {
- 24 int N;
- 25
- 26 pthread_t MyThreads[10];
- 27
- 28 if(argc != 2){
- 29 cout << "error" << endl;
- 30 exit (1);
- 31 }
- 32
- 33 N = atoi(argv[1]);
- 34
- 35 if(N > 10){
- 36 N = 10;
- 37 }
- 38
- 39 for(int Count = 0;Count < N;Count++)
- 40 {
- 41 pthread_create(&MyThreads[Count],NULL,task1,&N);
- 42
- 43 }
- 44
- 45
- 46 for(int Count = 0;Count < N;Count++)
- 47 {
- 48 pthread_join(MyThreads[Count],NULL);
- 49
- 50 }
- 51 return(0);
- 52
- 53
- 54 }
- 55
- 56
第26行声明了MyThreads,它是规模为10的数组,数组中的每一项类型为pthread_t。N持有命令行参数。在第41行,创建了MyThreads数组中的N个线程。N作为类型为void *的参数传递给每个线程。在函数task1中,该参数从void *强制类型转换为int *,如下所示:
- 10 Temp = static_cast < int * > (X);
函数执行一个循环,其迭代次数为传递给函数的值。函数将它的消息发送到标准输出。创建的每个线程执行这个函数。程序清单6-1的编译和执行指示包含在稍后位置的程序概要6-1中。
这个例子向线程函数传递一个命令行参数,并且使用该命令行参数来决定要创建的线程的数目。如果有必要向线程函数传递多个参数,您可以创建一个包含所有需要的参数的结构体(struct)或容器,然后将指向该数据结构的指针传递给线程函数。我们将在本章稍后部分介绍一种更容易的方式来完成这个目的,即创建线程对象。
程序概要6-1
程序名:
- program6-1.cc (程序清单6-1)
描述:
从命令行接收一个整数,并将该值传递给线程函数。线程函数执行一个循环,该循环向标准输出发送消息。参数用作循环变量的结束条件。参数还决定了要创建的线程数目,每个线程执行相同的函数。
必需的库:
- libpthread
必需的头文件:
- <pthread.h> <iostream>
编译和链接指令:
- c++ -o program6-1 program 6-1.cc -lpthread
测试环境:
- Solaris 10、gcc 3.4.3和gcc 3.4.6
处理器:
- Opteron和UltraSparc T1
执行指令:
- ./program6-1 5
注释:
这个程序要求一个命令行参数。
6.6.2 结合线程
6.6.2 结合线程
pthread_join( )用于结合或再次结合进程中的控制流。pthread_join( )导致调用线程将它的执行挂起,直到目标进程终止。它类似于进程所使用的wait( )函数。这个函数由线程的创建者调用,该调用线程等待新的线程终止并返回,然后再次结合到调用线程的控制流中。如果线程句柄是全局的,则pthread_join( )也可以被对等线程调用。这样使得任何线程可以将控制流同进程中任何其他线程结合。如果调用线程在目标线程返回之前被取消,这会导致目标线程成为僵死线程。本章稍后将会讨论分离的线程。如果不同的对等线程同时对同一个线程调用pthread_join( )函数,产生的行为未被定义。
调用形式
- #include <pthread.h>
-
- int pthread_join(pthread_t thread, void **value_ptr);
参数thread是调用线程正在等待的目标线程。如果目标线程成功返回,则它的退出状态保存在value_ptr中。如果目标线程不是一个可结合的线程,换句话说,如果它是作为分离的线程创建的,则函数失败。如果指定的thread线程不存在,则函数也会失败。
应当为所有可结合的线程调用pthread_join( )函数。一旦线程被结合,则操作系统可以收回线程所使用的存储空间。如果可结合的线程没有同任何线程结合,或者如果调用join函数的线程被取消,则目标线程继续利用存储空间。这是一种类似于父进程尚未接受子进程的退出状态而产生的僵死进程的状态。子进程继续在进程表中占据一个表项。
6.6.3 获得线程id
6.6.3 获得线程id
如本章前面所提到的,进程和它的地址空间内的线程共享资源。线程自身拥有的资源很少,但是线程id是线程的独特资源中的一种。函数pthread_self( )返回调用线程的线程id。
调用形式
- #include <pthread.h>
-
- pthread_t pthread_self(void);
当一个线程被创建之后,会将线程id返回到调用线程。一旦线程有了自己的id之后,可以将id传递给进程中的其他线程。这个函数返回线程id,且未定义错误。
下面是调用这个函数的实例:
- pthread_t ThreadId;
- ThreadId = pthread_self();
线程调用这个函数,函数将线程id返回并赋给pthread_t类型的变量ThreadId。
线程id还会被返回到pthread_create( )的调用线程。如果成功创建了线程,则线程id保存在pthread_t中。
比较线程id
您可以将线程id按照非透明类型进行处理。线程id可以进行比较,但是使用的不是一般的比较操作符。您可以通过调用pthread_equal( )来比较两个线程的id是否相等。
调用形式
- #include <pthread.h>
-
- int pthread_equal(pthread_t tid1, pthread_t tid2);
如果两个线程id指向相同的线程,则pthread_equal( )返回一个非零值。如果它们指向不同的线程,则返回零。
6.6.4 使用pthread属性对象
6.6.4 使用pthread属性对象
线程有一组属性是可以在线程被创建时指定的。该组属性被封装在一个对象中,该对象可用来设置一个或一组线程的属性。线程属性对象的类型为pthread_attr_t。这个结构体可用来设置这些线程属性:
线程栈的大小
线程栈的位置
调度继承机制、策略和参数
线程是否是分离的或可结合的
线程的范围
pthread_attr_t拥有一些方法来设置和获取这些属性。表6-3列出了用于设置属性的方法。
表6-3
| 属性函数的类型 |
pthread属性函数 |
| 初始化 |
pthread_attr_init( ) pthread_attr_destroy( ) |
| 栈管理 |
pthread_attr_setstacksize( ) pthread_attr_getstacksize( ) pthread_attr_setguardsize( ) pthread_attr_getguardsize( ) pthread_attr_setstack( ) pthread_attr_getstack( ) pthread_attr_setstackaddr( ) pthread_attr_getstackaddr( ) |
| 属性函数的类型 |
pthread属性函数 |
| 分离状态 |
pthread_attr_setdetachstate( ) pthread_attr_getdetachstate( ) |
| 竞争范围 |
pthread_attr_setscope( ) pthread_attr_getscope( ) |
| 调度继承机制 |
pthread_attr_setinheritsched( ) pthread_attr_getinheritsched( ) |
| 调度策略 |
pthread_attr_setschedpolicy( ) pthread_attr_getschedpolicy( ) |
| 调度参数 |
pthread_attr_setschedparam( ) pthread_attr_getschedparam( ) |
调用形式
- #include <pthread.h>
-
- int pthread_attr_init(pthread_attr_t *attr);
- int pthread_attr_destroy(pthread_attr_t *attr);
pthread_attr_init( )使用默认值对线程属性对象的所有属性进行初始化。attr是指向pthread_attr_t对象的指针。一旦attr被初始化之后,它的属性值可以通过表6-3中列出的pthread_attr_set函数进行改变。一旦属性已经进行了适当的更改,则attr可用作任何对pthread_create( )函数的调用中的参数。如果函数调用成功,则返回0,如果调用没有成功,则函数返回错误号。如果没有足够的内存来创建对象,则pthread_attr_init( )函数失败。
pthread_attr_destroy( )函数可用于销毁由attr指定的pthread_attr_t对象。对这个函数的调用会删除所有同该线程属性对象相关联的隐藏的存储。如果成功,则函数返回0,如果失败,函数返回一个错误号。
1. 属性对象的默认值
属性对象首先会通过对所有个别属性使用给定实现所使用的默认值进行初始化。有些实现不支持某个属性的可能值。如果成功完成,则pthread_attr_init( )返回0。如果返回的是一个错误号,这可能意味着该值不被支持。例如,对于竞争范围,Linux环境不支持PTHREAD_SCOPE_PROCESS。调用:
- int pthread_attr_setscope(pthread_attr_t *attr, int contentionscope);
会返回一个错误编码。表6-4列出了Linux和Solaris环境的默认值。
表6-4
| pthread属性函数 |
SuSE Linux 2.6.13的默认值 |
Solaris 10的默认值 |
| pthread_attr_ setdetachstate( ) |
PTHREAD_CREATE_JOINABLE |
PTHREAD_CREATE_JOINABLE |
| pthread_attr_ setscope( ) |
PTHREAD_SCOPE_SYSTEM (PTHREAD_SCOPE_ PROCESS不被支持) |
PTHREAD_SCOPE_PROCESS |
| pthread_attr_ setinheritsched( ) |
PTHREAD_EXPLICIT_SCHED |
PTHREAD_EXPLICIT_SCHED |
| pthread_attr_ setschedpolicy( ) |
SCHED_OTHER |
SCHED_OTHER |
| pthread_attr_ setschedparam( ) |
sched_priority = 0 |
sched_priority = 0 |
| pthread_attr_ setstacksize( ) |
未指定 |
NULL 由系统分配 |
| pthread_attr_ setstackaddr( ) |
未指定 |
NULL 1~2MB |
| pthread_attr_ setguardsize( ) |
未指定 |
PAGESIZE |
在默认情况下,当线程退出时,操作系统在线程同另一个线程结合时保存线程的完成状态以及线程id。如果退出的线程不同其他线程结合,则称退出的线程是分离的(detached)。这种情况下不保存完成状态和线程id。在分离的线程上不能够使用pthread_join( )。如果使用了,则pthread_join( )返回一个错误。
调用形式
- #include <pthread.h>
-
- int pthread_attr_setdetachstate(pthread_attr_t *attr,
- int *detachstate);
- int pthread_attr_getdetachstate(const pthread_attr_t *attr,
- int *detachstate);
pthread_attr_setdetachstate( )函数可用于设置属性对象的detachstate属性。detachstate参数描述了线程是分离的还是可结合的。它可以为以下的值之一:
- PTHREAD_CREATE_DETACHED
-
- PTHREAD_CREATE_JOINABLE
值PTHREAD_CREATE_DETACHED使得所有使用这个属性对象的线程都被创建为分离的线程。值PTHREAD_CREATE_JOINABLE使得所有使用这个属性对象来创建的线程都被创建为可结合的线程。detachstate的默认值是PTHREAD_CREATE_JOINABLE。如果成功,则函数返回0;如果没有成功,函数返回一个错误号。如果detachstate的值无效,则函数pthread_attr_setdetachstate( )会失败。
函数pthread_attr_getdetachstate( )返回属性对象的detachstate。如果成功,则函数将detachstate的值返回给detachstate参数,并以0作为返回值。如果没有成功,则函数返回一个错误号。
已经在运行的线程也可以成为分离的。例如,线程可能不再对目标线程的结果感兴趣。线程可以分离,使得线程一旦退出,它的资源可以被收回。
调用形式
- int pthread_detach(pthread_t tid);
在示例6-2中,ThreadA是使用属性对象作为分离的线程创建的。ThreadB是在创建之后分离的。
示例6-2
- // Example 6-2 Using an attribute object to create a detached thread and changing
- // a joinable thread to a detached thread.
-
- //...
-
- int main(int argc, char *argv[])
- {
-
- pthread_t ThreadA,ThreadB;
- pthread_attr_t DetachedAttr;
-
- pthread_attr_init(&DetachedAttr);
- pthread_attr_setdetachstate(&DetachedAttr,PTHREAD_CREATE_DETACHED);
- pthread_create(&ThreadA,&DetachedAttr,task1,NULL);
-
- pthread_create(&ThreadB,NULL,task2,NULL);
-
- //...
-
- pthread_detach(pthread_t ThreadB);
-
- //pthread_join(ThreadB,NULL); cannot call once detached
- return (0);
- }
示例6-2声明了一个属性对象DetachedAttr。函数pthread_attr_init( )用来初始化属性对象。ThreadA是使用DetachedAttr属性对象创建的。这个属性对象已经将detachstate设置为PTHREAD_CREATE_DETACHED。ThreadB是使用detachstate的默认值,即PTHREAD_CREATE_JOINABLE来创建的。一旦创建完毕,就调用pthread_detech( )。既然ThreadB是分离的,就不能够为这个线程调用pthread_join( )。
6.7.1 终止线程(1)
6.7 管理线程
到此为止,我们已经谈论了如何创建线程、使用线程属性对象、创建可结合和分离的线程,以及返回线程id的方法。接下来我们将讨论如何管理线程。当创建有着多个线程的应用程序时,有多种方法可以控制线程的行为以及它们如何使用资源和竞争资源。管理线程中包含设置调度策略、线程优先级等部分,这能够提高线程的性能,因此也提高了应用程序的性能。线程的性能还由线程如何竞争资源所决定,无论是系统范围还是进程范围。可以通过使用线程属性对象来设置线程的调度策略、优先级和竞争范围。由于线程共享资源,因此对资源的访问必须加以同步。线程同步包含线程何时以及如何终止和取消。
6.7.1 终止线程(1)
当线程到达程序指令的结尾时,就会终止。当线程终止后,pthread库收回线程使用的系统资源并保存它的退出状态。线程也可能会在执行完它所有的指令之前,被另一个对等线程提前终止。线程可能已经破坏某些进程数据,因此必须被终止。
线程的执行可以通过几种方式来停止:
通过从它被分派的任务返回,返回时有或者没有退出状态或返回值
显式终止自身并提供一个退出状态
被相同地址空间中的其他线程取消
1. 自终止
线程可以通过调用pthread_exit( )来自终止。
调用形式
- #include <pthread.h>
-
- int pthread_exit(void *value_ptr);
当可结合线程函数结束执行之后,它返回到将它作为目标线程调用pthread_join( )的线程。当终止的线程调用pthread_exit( )时,它在value_ptr中得到了退出状态。退出状态被返回到pthread_join( )。还没有执行的取消清理处理任务(cancellation cleanup handler task)与线程特有数据的析构器一起执行。
当调用这个函数时,线程所使用的资源不会被释放。应用程序可以看到的进程资源也不会被释放,如互斥量和文件描述符。不会执行进程级清理动作。当进程中最后一个线程退出时,进程终止,且退出状态为0。这个函数不能够返回到调用线程,也没有为它定义错误。
2. 终止对等线程
有时候一个线程有必要终止另一个对等线程。pthread_cancel( )用于终止对等线程。参数thread是要取消的线程。这个函数如果成功则返回0,如果不成功就返回一个错误。当参数thread不对应任何现有线程时,函数pthread_cancel( )会失败。
调用形式
- #include <pthread.h>
-
- int pthread_cancel(pthread_t thread);
应用程序中可能会有一个线程监视其他线程的工作。如果某个线程执行不力或不再需要,为了节省系统资源,有必要终止该线程。用户可能期望取消执行中的操作。多个线程可能用于解决一个问题,但是一旦某个线程得到了解答,所有其他线程可以被监视线程或得到解答的线程取消。
对pthread_cancel( )的调用是取消一个对等线程的请求。这个请求可能立即被同意、稍后被同意、甚至被忽略。目标线程可能立即终止,或者延迟到它的执行中的某个逻辑点。线程可能必须在终止之前执行一些清理任务,线程也可以选择拒绝终止。
3. 理解取消过程
在取消一个对等线程的请求被同意时,会有一个取消过程同pthread_cancel( )的返回异步发生。目标线程的取消类型和取消状态决定了取消何时真正发生。可取消性状态描述了线程的取消状况为可取消或不可取消。线程的可取消性类型决定了线程在收到取消请求后继续执行的能力。可取消性状态和类型是由线程自己动态设置的。
调用线程的可取消性状态和类型是由pthread_setcancelstate( )和pthread_setcanceltype( )设置的。pthread_setcancelstate( )将调用线程设置为state所指定的可取消性状态,并将之前的状态在oldstate中返回。pthread_setcanceltype( ) 将调用线程设置为type所指定的可取消性类型,并将之前的类型在oldtype中返回。
调用形式
- #include <pthread.h>
-
- int pthread_setcancelstate(int state, int *oldstate);
- int pthread_setcanceltype(int type, int *oldtype);
用于设置线程取消状态的state和oldstate的值是:
- PTHREAD_CANCEL_DISABLE
-
- PTHREAD_CANCEL_ENABLE
PTHREAD_CANCEL_DISABLE使得线程忽略取消请求。PTHREAD_CANCEL_ENABLE使得线程允许取消请求。PTHREAD_CANCEL_ENABLE是任何新近创建的线程的默认状态。如果成功,函数返回0。如果没有成功,函数返回一个错误号。如果没有传递有效的state值,则pthread_setcancelstate( )会失败。
函数pthread_setcanceltype( )将调用线程的可取消性状态设置为type指定的类型,并将之前的状态通过oldtype返回。type和oldtype的值可以为:
- PTHREAD_CANCEL_DEFFERED
-
- PTHREAD_CANCEL_ASYNCHRONOUS
PTHREAD_CANCEL_DEFFERED使得线程推迟终止,直到它到达它的取消点。这是任何新近创建的线程的默认可取消性类型。PTHREAD_CANCEL_ASYNCHRONOUS使得线程立即终止。如果成功,函数返回0。如果不成功,函数返回一个错误号。如果没有传递有效的type,则pthread_setcanceltype( )会失败。
pthread_setcancelstate ( )和pthread_setcanceltype( )共同使用来建立线程的可取消性。表6-5列出了状态和类型的组合以及对每种组合的作用的描述。
表6-5
| 可取消性状态 |
可取消性类型 |
描 述 |
| PTHREAD_CANCEL_ENABLE |
PTHREAD_ CANCEL_DEFERRED |
延迟取消;这是线程的 默认取消状态和类型; 当线程到达一个取消点 或程序员通过调用 pthread_testcancel( )定 义的取消点时,会发 生线程的取消 |
| PTHREAD_CANCEL_ENABLE |
PTHREAD_CANCEL_ ASYNCHRONOUS |
异步取消;立即发 生线程的取消 |
| PTHREAD_CANCEL_DISABLE |
Ignored |
禁止取消;不会发 生线程的取消 |
示例6-3
- // Example 6-3 task3 thread sets its cancelability state to allow thread
- // to be canceled immediately.
-
- void *task3(void *X)
- {
- int OldState,OldType;
-
- // enable immediate cancelability
-
- pthread_setcancelstate(PTHREAD_CANCEL_ENABLE,&OldState);
- pthread_setcanceltype(PTHREAD_CANCEL_ASYNCHRONOUS,&OldType);
-
- ofstream Outfile("out3.txt");
- for(int Count = 1;Count < 100;Count++)
- {
- Outfile << "thread C is working: " << Count << endl;
-
- }
- Outfile.close();
- return (NULL);
- }
6.7.1 终止线程(2)
6.7.1 终止线程(2)
在示例6-3中,取消被设置为立即发生。这意味着取消线程的请求可以在线程的函数执行中的任何一点发生。这样,线程可以打开文件并在对文件进行写入时被取消。
取消对等线程不应当轻易进行。有些线程具有非常敏感的性质,可能会要求安全保护以防止不合时宜的取消。在线程的函数中安装安全保护能够防止不期望的状况发生。例如,考虑共享数据的线程。根据使用的线程模型,一个线程可能正在处理数据,这些数据要传递给另一个线程进行处理。当线程处理数据时,它通过对互斥量的加锁获得对数据的独自占有。如果线程在互斥量释放之前被取消,这将会导致死锁。在数据能够再次被使用之前,可能会要求它处于某种状态。如果线程在完成这些之前被取消,会发生不期望的状况。根据线程正在进行的处理的类型,线程取消只应当在安全的时候进行。
重要的线程可能会完全防止取消。因此,线程取消应当被限制在不重要的线程上,而且是没有对资源加锁或者没有在执行重要代码的执行点上。您应当将线程的可取消性设置为适当的状态和类型。取消应当被延迟,直到所有重要的清理都发生了,例如释放互斥量、关闭文件等。如果线程有着取消清理处理程序任务,它们应当在取消之前进行。当返回最后的处理程序后,调用线程特有数据的析构器,然后线程被终止。
使用取消点
当推迟取消请求时,线程的终止会推迟到线程的函数执行的后期。当取消发生时,应当是安全的,因为它不处于对互斥量加锁、执行关键代码、令数据处于某种不可用状态的情况中。代码的执行中,这些安全的位置是很好的取消点位置。取消点是一个检查点,线程在这里检查是否有任何取消请求未决,如果有,则终止。
取消点通过调用pthread_testcancel( )来标记。这个函数用于检查任意的未决取消请求。如果有未决的请求,它会导致取消过程发生在这个函数被调用的位置。如果没有未决的取消请求,则函数继续执行,调用不产生任何影响。这个函数调用应当放置在代码中认为可以安全终止进程的任意位置。
调用形式
- #include <pthread.h>
-
- void pthread_testcancel(void);
在示例6-3中,线程的可取消性被设置为立即可取消。示例6-4使用延迟取消,这是默认的设置。对pthread_testcancel( )的调用标记了在哪里取消这个线程是安全的,即在文件被打开之前,或线程关闭文件之后。
示例6-4
- // Example 6-4 task1 thread sets its cancelability state to be deferred.
-
-
- void *task1(void *X)
- {
- int OldState,OldType;
-
- //not needed default settings for cancelability
- pthread_setcancelstate(PTHREAD_CANCEL_ENABLE,&OldState);
- pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED,&OldType);
-
- pthread_testcancel();
-
- ofstream Outfile("out1.txt");
- for(int Count = 1;Count < 1000;Count++)
- {
- Outfile << "thread 1 is working: " << Count << endl;
-
- }
- Outfile.close();
- pthread_testcancel();return (NULL);
- }
在示例6-5中,我们创建了两个线程并将它们取消。
示例6-5
- //Example 6-5 shows two threads being canceled.
-
- //...
- int main(int argc, char *argv[])
- {
- pthread_t Threads[2];
- void *Status;
-
- pthread_create(&(Threads[0]),NULL,task1,NULL);
- pthread_create(&(Threads[1]),NULL,task3,NULL);
-
-
- // ...
-
- pthread_cancel(Threads[0]);
- pthread_cancel(Threads[1]);
-
-
- for(int Count = 0;Count < 2;Count++)
- {
- pthread_join(Threads[Count],&Status);
- if(Status == PTHREAD_CANCELED){
- cout << "thread" << Count << " has been canceled" << endl;
- }
- else{
- cout << "thread" << Count << " has survived" << endl;
- }
- }
- return (0);
- }
在示例6-5中,主线程创建两个线程,然后对每个线程发出了取消请求。主线程为每个线程调用了pthread_join( )。函数pthread_join( )如果试图同已经被终止的线程进行结合,则不会失败。结合函数提取被终止线程的退出状态。这种方式较好,因为发出取消请求的线程可能不是调用pthread_join( )的线程。监视所有worker线程的工作情况可能是某个线程的主要任务,该线程也负责取消线程。另一个线程可能会通过调用pthread_join( )函数来检测线程们的退出状态。这种信息可用于静态评估哪个线程的性能最好。在本例中,主线程在循环中结合并检查每个线程的退出状态。被取消的线程会返回退出状态PTHREAD_CANCELED。
利用可安全取消的库函数和系统调用
在这些例子中,通过调用pthread_testcancel( )标记的取消点放置在用户定义的函数中。当您从使用异步取消的线程函数中调用库函数时,取消这些线程是安全的吗?
pthread库定义了可作为取消点的函数以及认为可异步安全取消的函数。这些函数阻塞调用线程,当调用线程被阻塞时,取消线程是安全的。这些是用作取消点的pthread库函数:
- pthread_testcancel( )
-
- pthread_cond_wait( )
-
- pthread_timedwait( )
-
- pthread_join( )
如果状态为延迟取消的线程在做出对这些pthread库函数的调用时,有挂起的取消请求,则开始进行取消过程。
表6-6列出了一些被要求为取消点的POSIX系统调用。这些pthread和POSIX函数可以安全地用作延迟取消点,但是可能对于异步取消是不安全的。如果不是可安全异步取消的库调用在执行期间被取消,则可能导致库数据处于矛盾的状态。库可能已经为线程分配了内存,当线程被取消时,可能仍占有该内存。在这种情况下,当从不是可异步取消的线程进行这样的库调用时,有必要在调用之前改变可取消状态,并在函数返回后将可取消状态改变回来。
表6-6
| POSIX系统调用(取消点) |
||
| accept( ) |
nanosleep( ) |
sem_wait( ) |
| aio_suspend( ) |
open( ) |
send( ) |
| clock_nanosleep( ) |
pause( ) |
sendmsg( ) |
| close( ) |
poll( ) |
sendto( ) |
| connect( ) |
pread( ) |
sigpause( ) |
| create( ) |
pthread_ cond_timedwait( ) |
sigsuspend( ) |
| fcntl( ) |
pthread_cond_wait( ) |
sigtimedwait( ) |
| fsync( ) |
pthread_join( ) |
sigwait( ) |
| getmsg( ) |
putmsg( ) |
sigwaitinfo( ) |
| lockf( ) |
putpmsg( ) |
sleep( ) |
| mq_receive( ) |
pwrite( ) |
system( ) |
| mq_send( ) |
read( ) |
usleep( ) |
| mq_timedreceive( ) |
readv( ) |
wait( ) |
| mq_timedsend( ) |
recvfrom( ) |
waitpid( ) |
| msgrcv( ) |
recvmsg( ) |
write( ) |
| msgsnd( ) |
select( ) |
writev( ) |
| msync( ) |
sem_timedwait( ) |
|
示例6-6是对库调用或系统调用的封装。通过封装将可取消性改为延迟的、进行函数或系统调用,然后将可取消性重设回之前的类型。现在就可以安全地调用pthread_testcancel( )了。
示例6-6
- //Example 6-6 shows a wrapper for system functions.
-
- int OldType;
- pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED,&OldType);
- system_call(); //some library of system call
- pthread_setcanceltype(OldType,NULL);
- pthread_testcancel();
-
- //...
终止之前进行清理
我们在前面提到过,线程在终止之前,可能需要执行一些最终的处理,例如关闭文件、将共享资源重设为一致的状态、释放锁和释放资源。pthread库定义了一种机制,来为每个线程在终止之前执行最后的任务。清理栈(cleanup stack)同每个线程关联,在清理栈中包含了指向取消过程中要执行的例程的指针。函数pthread_cleanup_push( )将一个指向例程的指针压入清理栈中。
调用形式
- #include <pthread.h>
-
- void pthread_cleanup_push(void (*routine)(void *), void *arg);
- void pthread_cleanup_pop(int execute);
参数routine是要被压入栈中的函数指针,参数arg被传递给该函数。当线程在这些环境下退出时,会以arg为参数调用函数routine:
当调用pthread_exit( )时
当线程接受终止请求时
当线程使用非零execute值显式调用pthread_cleanup_pop( )时
该函数不进行返回。
函数pthread_cleanup_pop( )从调用线程的清理栈的顶部删除routine的指针。参数execute的值可以为1或0。如果为1,线程执行routine,即使它没有被终止。线程从调用该函数之后的位置继续执行。如果值为0,则指针会从栈顶移除,指向的函数不会被执行。
对于每次入栈,需要在相同的词法范围(lexical scope)中存在出栈。例如,task4( )要求函数退出或被取消时执行清理处理程序。
在示例6-7中,task4( )通过调用pthread_cleanup_push( )函数将清理处理程序cleanup_task4( )压入栈中。对于每个对pthread_cleanup_push( )函数的调用,都要求有相应的pthread_cleanup_pop( )。pop函数被传递参数0,意味着此时处理程序已经从清理栈中移出,但是此时尚未被执行。如果取消了执行task4( )的线程,则会执行该处理程序。
示例6-7
-
//Example 6-7 task4 () pushes cleanup handler
cleanup_task4 () onto cleanup stack.
-
- void *task4(void *X)
- {
- int *Tid;
- Tid = new int;
- // do some work
- //...
- pthread_cleanup_push(cleanup_task4,Tid);
- // do some more work
- //...
- pthread_cleanup_pop(0);
- }
在示例6-8中,task5( )将清理处理程序cleanup_task5( )压入到清理栈中。这个例子同上一个例子的区别在于传递给pthread_cleanup_pop( )的参数为1,意味着处理程序从清理栈中移出,并在这个位置被执行。无论执行task5( )的线程是否被取消,处理程序都会被执行。清理处理程序cleanup_task4( )和cleanup_task5( )都是正规的函数,可用于关闭文件、释放资源、解锁互斥量等。
示例6-8
-
//Example 6-8 task5 () pushes cleanup handler
cleanup_task5 () onto cleanup stack.
-
- void *task5(void *X)
- {
- int *Tid;
- Tid = new int;
- // do some work
- //...
- pthread_cleanup_push(cleanup_task5,Tid);
- // do some more work
- //...
- pthread_cleanup_pop(1);
- }
6.7.2 管理线程的栈
6.7.2 管理线程的栈
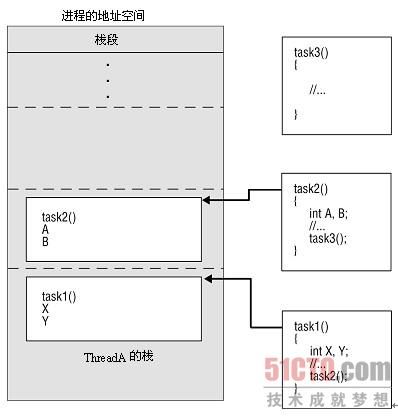
管理线程的栈包括设置栈的大小以及确定栈的位置。线程的栈通常是由系统自动管理的。但是您应当清楚由默认的栈管理系统导致的系统特定限制。它们可能过于受限,这时就有必要进行一些栈管理了。如果应用程序有着大量的线程,则您可能不得不增加具有默认大小的栈的上限。如果应用程序利用递归或调用多个函数,则会需要很多栈帧。有些应用程序要求对地址空间进行精确的控制。例如,有着垃圾收集的应用程序必须跟踪内存的分配。
进程的地址空间分成代码段、静态数据段、堆和栈段。线程栈的位置和大小是从它所属的进程的栈中切分出来的。线程栈为线程调用且尚未退出的每个例程保存一个栈帧。栈帧包含临时变量、局部变量、返回地址以及线程回到之前执行的例程所需要的任何附加信息。一旦例程退出,该例程的栈帧会从栈中删除。图6-5显示了栈帧如何生成以及如何放置到栈中。
 |
| (点击查看大图)图6-5 |
在图6-5中,ThreadA执行task1( )。task1()创建一些局部变量,进行一些处理,然后调用task2( )。会为task1( )创建一个栈帧并放置到栈中。task2( )创建局部变量,然后调用task3( )。task2( )的栈帧也被放置到栈中。当task3( )结束之后,控制流返回到task2( ),它从栈中弹出。当task2( )执行完之后,控制流返回到task1( ),它也从栈中弹出。每个栈必须足够大,以容纳所有对等线程的函数的执行以及它们将会调用的例程链。线程栈的大小和位置可以通过由属性对象定义的几种方法进行设置或检测。
1. 设置栈的大小
有两个属性方法同线程栈的大小有关。
调用形式
- #include <pthread.h>
-
- int pthread_attr_getstacksize(const pthread_attr_t *restrict attr,
- size_t *restrict stacksize);
- int pthread_attr_setstacksize(pthread_attr_t *attr, size_t *stacksize);
pthread_attr_getstacksize( )返回默认栈大小的最小值。attr是从中提取默认栈大小的线程属性对象。当函数返回时,默认栈大小保存在stacksize中(以字节为单位),且返回值为0。如果没有成功,则函数返回错误号。
pthread_attr_setstacksize( )设置栈大小的最小值。attr是设置栈大小的线程属性对象。stacksize是栈大小的最小值(以字节为单位)。如果函数成功,返回值为0。如果没有成功,函数返回一个错误号。如果stacksize小于PTHREAD_MIN_STACK或小于系统最小值,则函数会失败。PTHREAD_STACK_MIN很可能会是一个比由pthread_attr_getstacksize( )返回的默认栈最小值还要小的最小值。在增加线程栈的最小大小之前,需要考虑由pthread_attr_getstacksize( )返回的值。
在示例6-9中,线程的栈大小通过使用线程属性对象进行了更改。它从属性对象中提取默认值,然后判断默认值是否小于期望的最小栈大小。如果是,则将偏移量加到默认栈大小上,得到的结果成为线程新的最小栈大小。
示例6-9
- // Example 6-9 Changing the stack size of a thread using an offset.
-
- #include <limits.h>
- //...
-
- pthread_attr_getstacksize(&SchedAttr,&DefaultSize);
- if(DefaultSize < PTHREAD_STACK_MIN){
- SizeOffset = PTHREAD_STACK_MIN - DefaultSize;
- NewSize = DefaultSize + SizeOffset;
- pthread_attr_setstacksize(&Attr1,(size_t)NewSize);
- }
在设置大小时需要进行权衡。栈大小是固定的,较大的栈意味着发生栈溢出的可能性较小,但是另一方面,较大的栈意味着在栈的交换空间和实际内存方面占用得更多。
注意:
设置栈大小和栈的位置可能使得您的程序无法移植。您在一个平台上为程序设置的栈大小和位置可能无法匹配上另一个平台上的栈大小和位置。
2. 设置线程栈的位置
一旦您决定管理线程的栈,您可以通过使用这些属性对象方法来提取并设置栈的位置。
调用形式
- #include <pthread.h>
-
- int pthread_attr_setstackaddr(pthread_attr_t *attr, void *stackaddr);
- int pthread_attr_getstackaddr(const pthread_attr_t *restrict attr,
- void **restrict stackaddr);
pthread_attr_setstackaddr( )将栈的基地址设置为stackattr指定的地址,该栈用于使用attr线程属性对象创建的线程。地址addr应当位于进程的虚拟地址空间中。栈的大小最少应当等于由PTHREAD_STACK_MIN所指定的最小栈大小。如果成功,函数返回0。如果不成功,函数返回一个错误号。
pthread_attr_getstackaddr( )获取线程的栈地址的基地址,该线程是通过使用由attr指定的线程属性对象创建的。地址返回并保存在stackaddr中。如果成功,则函数返回0。如果不成功,函数返回一个错误号。
3. 设置一个函数设置栈大小和位置
栈属性(大小和位置)可以通过使用一个函数来设置。
调用形式
- #include <pthread.h>
-
- int pthread_attr_setstack(pthread_attr_t *attr, void *stackaddr,
- size_t stacksize);
- int pthread_attr_getstack(const pthread_attr_t *restrict attr,
-
void **restrict stackaddr,
size_t *restrict stacksize);
函数pthread_attr_setstack( )为使用指定的属性对象attr创建的线程设置栈大小和位置。栈的基地址设置为stackaddr,栈的大小设置为stacksize。pthread_attr_getstack( )提取使用指定属性对象attr创建的线程的栈大小和位置。如果提取成功,则栈的位置保存在stackaddr,栈的大小保存在stacksize。如果成功,这些函数会返回0。如果不成功,则返回错误号。如果stacksize小于PTHREAD_STACK_MIN或超出一些根据实现定义的限制,则pthread_attr_setstack( )会失败。
6.7.3 设置线程调度和优先级
6.7.3 设置线程调度和优先级
线程是独立执行的。它们被分派到处理器内核上,并执行分给它们的任务。每个线程均有一个调度策略和优先级,决定何时以及如何分配到处理器上。线程或线程组的调度策略可以使用这些函数通过属性对象来设置:
调用形式
- #include <pthread.h>
- #include <sched.h>
-
- int pthread_attr_setinheritsched(pthread_attr_t *attr, int inheritsched);
- void pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy);
- int pthread_attr_setschedparam(pthread_attr_t *restrict attr,
- const struct sched_param *restrict param);
pthread_attr_setinheritesched( )用于确定如何设置线程的调度属性,可以从创建者线程或从一个属性对象来继承调度属性。inheritsched可以为如下值。
PTHREAD_INHERIT_SCHED:线程调度属性是从创建者线程继承得到,attr的任何调度属性都被忽略。
PTHREAD_EXPLICIT_SCHED:线程调度属性设置为属性对象attr的调度属性。
如果inheritsched值是PTHREAD_EXPLICIT_SCHED,则pthread_attr_setschedpolicy( )被用于设置调度策略,而pthread_attr_setschedparam( )被用于设置优先级。
pthread_attr_setschedpolicy( )设置线程属性对象attr的调度策略。policy的值可以为在<sched.h>头文件中定义的以下值。
SCHED_FIFO:先进先出调度策略,执行线程运行到结束。
SCHED_RR:轮询调度策略,按照时间片将每个线程分配到处理器上。
SCHED_OTHER:另外的调度策略(根据实现定义)。这是任何新创建线程的默认调度策略。
使用pthread_attr_setschedparam( )可以设置调度策略所使用的属性对象attr的调度参数。param是包含参数的结构体。sched_param结构体至少需要定义这个数据成员:
- struct sched_param {
- int sched_priority;
- //...
- };
它可能还有其他的数据成员,以及多个用来返回和设置最小优先级、最大优先级、调度器、参数等的函数。如果调度策略是SCHED_FIFO或SCHED_RR,那么要求具有值的唯一成员是sched_priority。
按照如下方法使用sched_get_priority_max( )和sched_get_priority_max( ),可以得到优先级的最大值和最小值。
调用形式
- #include <sched.h>
-
- int sched_get_priority_max(int policy);
- int sched_get_priority_min(int policy);
两个函数都以调度策略policy为参数,目的是获得对应调度策略的优先级值,而且都返回调度策略的最大或最小优先级值。
示例6-10显示了如何使用线程属性对象设置线程的调度策略和优先级。
示例6-10
- // Example 6-10 Using the thread attribute object to set scheduling
- // policy and priority of a thread.
-
- #include <pthread.h>
- #include <sched.h>
-
- //...
-
- pthread_t ThreadA;
- pthread_attr_t SchedAttr;
- sched_param SchedParam;
- int MidPriority,MaxPriority,MinPriority;
-
- int main(int argc, char *argv[])
- {
- //...
-
- // Step 1: initialize attribute object
- pthread_attr_init(&SchedAttr);
-
- // Step 2: retrieve min and max priority values for scheduling policy
- MinPriority = sched_get_priority_max(SCHED_RR);
- MaxPriority = sched_get_priority_min(SCHED_RR);
-
- // Step 3: calculate priority value
- MidPriority = (MaxPriority + MinPriority)/2;
-
- // Step 4: assign priority value to sched_param structure
- SchedParam.sched_priority = MidPriority;
-
- // Step 5: set attribute object with scheduling parameter
- pthread_attr_setschedparam(&SchedAttr,&SchedParam);
-
- // Step 6: set scheduling attributes to be determined by attribute object
- pthread_attr_setinheritsched(&SchedAttr,PTHREAD_EXPLICIT_SCHED);
-
- // Step 7: set scheduling policy
- pthread_attr_setschedpolicy(&SchedAttr,SCHED_RR);
-
- // Step 8: create thread with scheduling attribute object
- pthread_create(&ThreadA,&SchedAttr,task1,NULL);
-
- //...
- }
在示例6-10中,ThreadA的调度策略和优先级是使用线程属性对象SchedAttr来设置的。通过8个步骤完成:
(1) 初始化属性对象
(2) 为调度策略提取最大和最小优先级值
(3) 计算优先级值
(4) 将优先级值赋给sched_param结构体
(5) 使用调度参数设置属性对象
(6) 将调度属性设置为由属性对象决定
(7) 设置调度策略
(8) 使用调度属性对象创建一个线程
在示例6-10中,我们将优先级设置为一个平均值。但是优先级可以设置为介于线程调度策略所允许的最大和最小优先级值之间的任何值。有了这些方法,调度策略和优先级可以在线程被创建或运行之前,先设置在线程属性对象中。为了动态改变调度策略和优先级,可以使用pthread_setschedparam( )和pthread_setschedprio( )。
调用形式
- #include <pthread.h>
-
- int pthread_setschedparam(pthread_t thread, int policy,
- const struct sched_param *param);
- int pthread_getschedparam(pthread_t thread, int *restrict policy,
- struct sched_param *restrict param);
- int pthread_setschedprio(pthread_t thread, int prio);
pthread_setschedparam( )不需要使用属性对象即可直接设置线程的调度策略和优先级。thread是线程的id,policy是新的调度策略,param包含调度优先级。如果成功,则pthread_getschedparam( )返回调度策略和调度参数,并将它们的值分别保存在policy和param参数中。如果成功,则两个函数都返回0。如果不成功,两个函数都返回错误号。表6-7列出了这些函数可能失败的条件。
pthread_setschedprio( )用来设置正在执行中的线程的调度优先级,该进程的id由thread指定。prio指定了线程的新调度优先级。如果函数失败,线程的优先级不发生变化,返回一个错误号。如果成功,则函数返回0。表6-7也列出了这个函数可能失败的条件。
表6-7
| pthread调度和优先级函数 |
失败的条件 |
| int pthread_getschedparam (pthread_t thread, int *restrict policy, struct sched_param *restrict param); |
thread参数所指向的线程不存在 |
| int pthread_setschedparam (pthread_t thread, int *policy, const struct sched_param *param); |
参数policy或同参数policy 关联的调度参数之一无效; 参数policy或调度参数之一的值不被支持; 调用线程没有适当的权限来设 置指定线程的调度参数或策略; 参数thread指向的线程不存在; 实现不允许应用程序将参数 改动为特定的值 |
| int pthread_setschedprio (pthread_t thread, int prio); |
参数prio对于指定线程的调度策略无效; 参数prio的值不被支持; 调用线程没有适当的权限来设 置指定线程的调度优先级; 参数thread指向的线程不存在; 实现不允许应用程序将优先 级改变为指定的值 |
要记得仔细考虑为何有必要改变运行线程的调度策略或优先级。这可能会严重影响应用程序的总体性能。有着较高优先级的线程会抢占运行的较低优先级的线程。这可能会产生饿死,即线程持续被抢占,因此无法完成执行。
6.7.4 设置线程的竞争范围
线程的竞争范围决定了线程同哪些其他线程竞争处理器的使用。竞争范围是由线程属性对象设置的。
调用形式
- #include <pthread.h>
-
- int pthread_attr_setscope(pthread_attr_t *attr, int contentionscope);
- int pthread_attr_getscope(const pthread_attr_t *restrict attr,
- int *restrict contentionscope);
pthread_attr_setscope( )设置由attr指定的线程属性对象的竞争范围属性。线程属性对象的竞争范围会设置为保存在contentionscope中的值。contentionscope可以为以下值。
PTHREAD_SCOPE_SYSTEM:系统调度竞争范围
PTHREAD_SCOPE_PROCESS:进程调度竞争范围
系统竞争范围意味线程同系统范围内其他进程的线程进行竞争。pthread_attr_getscope( )从attr指定的线程属性对象返回竞争范围属性。如果函数成功,则返回线程属性对象的竞争范围,并保存到contentionscope中。这两个函数如果成功则返回0,否则返回错误号。
6.7.5 使用sysconf( )
6.7.5 使用sysconf( )
了解系统的线程资源限制是使得应用程序恰当地管理它们的关键。前面已经讨论了利用系统资源的示例。当设置线程的栈大小时,最小值为PTHREAD_MIN_STACK。栈大小不应当低于由pthread_attr_getstacksize( )返回的默认栈大小的最小值。每个进程的最大线程数决定了能够为每个进程创建的worker线程的上限。函数sysconf( )用于返回可配置系统限制或选项的当前值。系统中定义了同线程、进程和信号量相关的多个变量和常量。在表6-8中,列出了部分变量和常量。
表6-8
| 变 量 |
名字值(Name Value) |
描 述 |
| _SC_THREADS |
_POSIX_THREADS |
支持线程 |
| _SC_THREAD_ATTR_ STACKADDR |
_POSIX_THREAD_ATTR_ STACKADDR |
支持线程栈地址属性 |
| _SC_THREAD_ATTR_ STACKSIZE |
_POSIX_THREAD_ATTR_ STACKSIZE |
支持线程栈大小属性 |
| _SC_THREAD_STACK_MIN |
PTHREAD_STACK_MIN |
线程栈存储区的 最小大小,以字节为单位 |
| 变 量 |
名字值(Name Value) |
描 述 |
| _SC_THREAD_THREADS_MAX |
PTHREAD_THREADS_MAX |
每个进程的 最大线程数 |
| _SC_THREAD_KEYS_MAX |
PTHREAD_KEYS_MAX |
每个进程关键 字的最大数目 |
| _SC_THREAD_PRIO_INHERIT |
_POSIX_THREAD_PRIO_ INHERIT |
支持优先 级继承选项 |
| _SC_THREAD_PRIO |
_POSIX_THREAD_PRIO_ |
支持线程 优先级选项 |
| _SC_THREAD_PRIORITY_ SCHEDULING |
_POSIX_THREAD_PRIORITY_ SCHEDULING |
支持线程优 先级调度选项 |
| _SC_THREAD_PROCESS_ SHARED |
_POSIX_THREAD_PROCESS_ SHARED |
支持进程共享同步 |
| _SC_THREAD_SAFE_ FUNCTIONS |
_POSIX_THREAD_SAFE_ FUNCTIONS |
支持线程安全函数 |
| _SC_THREAD_DESTRUCTOR_ ITERATIONS |
_PTHREAD_THREAD_ DESTRUCTOR_ITERATIONS |
决定在线程退 出时尝试销毁 线程特定数据 的尝试次数 |
| _SC_CHILD_MAX |
CHILD_MAX |
每个UID允许 的最大进程数目 |
| _SC_PRIORITY_SCHEDULING |
_POSIX_PRIORITY_ SCHEDULING |
支持进程调度 |
| _SC_REALTIME_SIGNALS |
_POSIX_ REALTIME_SIGNALS |
支持实时信号 |
| _SC_XOPEN_REALTIME_ THREADS |
_XOPEN_ REALTIME_THREADS |
支持X/Open POSIX实时 线程特性组 |
| _SC_STREAM_MAX |
STREAM_MAX |
决定进程能够 打开的流的数目 |
| _SC_SEMAPHORES |
_POSIX_SEMAPHORES |
支持信号量 |
| _SC_SEM_NSEMS_MAX |
SEM_NSEMS_MAX |
决定线程能 够拥有的信号 量的最大数目 |
| _SC_SEM_VALUE_MAX |
SEM_VALUE_MAX |
决定信号量的最大值 |
| _SC_SHARED_MEMORY_ OBJECTS |
_POSIX_SHARED_MEMORY_ OBJECTS |
支持共享内存对象 |
下面是调用sysconf( )的示例:
- if(PTHREAD_STACK_MIN == (sysconf(_SC_THREAD_STACK_MIN))){
- //...
- }
代码中将sysconf( )返回的_SC_THREAD_STACK_MIN的值同PTHREAD_STACK_MIN这个常量值进行了比较。
6.7.6 线程安全和库
6.7.6 线程安全和库
如果不需要采取任何其他动作,库中的函数就可以在某个时刻被多个线程调用,则称该库是线程安全或可重入的。在设计多线程应用程序时,必须小心地确保并发执行的函数是线程安全的。我们已经讨论了如何使用户定义的函数成为线程安全的,但是应用程序经常会调用系统定义的库或第三方提供的库。我们前面讨论了在取消点安全的系统函数,但是这些函数和库中,部分是线程安全的,而部分不是。如果函数不是线程安全的,则意味着该函数:
包含静态变量
访问全局数据
是不可重入的
如果函数包含静态变量,那么这些变量在函数调用之间保持它们的值。函数要求静态变量的值,才能够正确地操作。当多个并发线程调用这个函数时,会产生竞争条件。
如果函数更改一个全局变量,那么多个调用该函数的线程可能每个都尝试更改该全局变量。如果对全局变量的多个并发访问不是同步的,则也可能会产生竞争条件。考虑多个并发线程执行设置errno的函数。对于某些线程,函数失败,errno被设置为错误消息。与此同时,其他线程成功执行。依赖于编译器实现,errno是线程安全的,但假如它不是线程安全的,那么当一个线程检查errno的状态时,它会报告哪个消息?
可重入代码是在使用期间不能够被改变的代码块。可重入代码通过去除对全局变量以及可改动静态数据的引用避免竞争条件。多个并发线程或进程可以共享代码,而其不会发生竞争条件。POSIX标准将多个函数定义为可重入的。可以简单地通过函数名后缀_r来同对应的不可重入的函数进行识别。下面列出了部分可重入函数:
getgrgid_r( )
getgrnam_r( )
getpwuid_r( )
sterror_r( )
strtok_r( )
readdir_r( )
rand_r( )
ttyname_r( )
如果函数访问未经保护的全局变量、包含静态可更改变量、不可重入,则认为该函数不是线程安全的。
1. 使用多线程版本的库和函数
系统库和第三方提供的库可能为它们的标准库提供两个不同的版本,一个版本用于单线程应用程序,另一个版本用于多线程应用程序。只要预计到可能会用于多线程环境,就要链接到库的多线程版本。其他环境不要求链接到库的多线程版本的多线程应用程序,只要求为声明可重入版本的函数定义一些宏。然后这个应用程序就可以作为线程安全的来进行编译。
并不总是可能使用函数的多线程版本。在某些实例中,对于给定的编译器或环境,特定函数的多线程版本不可用。某些函数的接口不能够简单地变成线程安全的。此外,您可能面临增加线程到一个环境中,该环境使用了只打算用在单线程环境中的函数。在这些情况下,可以在程序中使用互斥量来封装所有这样的函数。
例如,某个程序有3个并发执行的线程。其中两个线程ThreadA和ThreadB都并发地执行task1( ),task1( )不是线程安全的。第三个线程,即ThreadC,执行task2( )。为了解决task1( )的问题,方法就是简单地通过一个互斥量来封装ThreadA和ThreadB对task1( )的访问:
- ThreadA
- {
- lock()
- task1()
- unlock()
- }
-
- ThreadB
- {
- lock()
- task1()
- unlock()
- }
-
- ThreadC
- {
- task2()
- }
如果这样做,则任意时刻只有一个线程访问task1( )。但是如果task1( )和task2( )都改动相同的全局变量或静态变量会怎样呢?尽管ThreadA和ThreadB对task1( )使用了互斥量,但ThreadC执行task2( )同它们两者之一是并发的。在这种情况下,会发生竞争条件。为了避免竞争条件,需要对全局数据的访问进行同步。我们将在第7章中讨论这个话题。
2. 线程安全标准输出
为了示范在涉及iostream库时的另一种竞争条件,假定有两个线程ThreadA和ThreadB向标准输出流cout发送输出。cout是类型为ostream的对象,使用插入符(>>)和提取符(<<)来调用cout对象的方法。这些方法是线程安全的吗?如果ThreadA在发送如下的消息:
- Global warming is a real problem.
到stdout,且ThreadB发送如下消息:
- Global warming is not a real problem.
那么输出是否会交错并产生如下的消息?
- Global warming is a Global warming is not a real problem real problem.
在某些情况下,线程安全函数是通过原子(atomic)函数来实现的。原子函数是一旦开始执行就不能够被中断的函数。对于cout,如果插入操作是原子的,那么这种交错不会发生。当您多次调用插入符操作时,它们会像按照串行顺序那样来执行。先显示ThreadA的消息,然后显示ThreadB的消息,或者反之。这是将函数或操作串行化,使之成为线程安全的实例。
这并非令函数线程安全的唯一途径。如果没有不利的影响,函数可能会交错地操作。例如,如果某个方法向未排序的结构中增加或删除元素,而且两个不同的线程调用该方法,那么交错它们的操作将不会有不利的影响。
如果不知道库中的哪些函数是线程安全的,而哪些不是,您有以下3种选择:
所有非线程安全函数的使用限制为单线程使用
不使用任何非线程安全函数
将所有潜在的非线程安全的函数封装到单独的一套同步机制中
为了扩展最后一个选择,您可以为所有将被用在多线程应用程序中的所有非线程安全函数创建接口类。包装器的思想已经在本章前面部分中为系统调用设置取消点时示范过。非线程安全的函数封装在一个接口类中。该类可以同适当的同步对象结合,并可被宿主类(host class)通过继承或组合来使用。这种方法降低了竞争条件的可能性,将在第7章中讨论。然而,首先我们希望讨论第4章引入的thread_object接口类,并对它进行扩展,以封装线程属性对象。
6.8 扩展线程接口类(1)
6.8 扩展线程接口类(1)
线程接口类是在第4章引入的。接口类的作用就像包装器,使得某些事物显得同正常的情况不同。接口类提供的新的接口是为了使得类更易用、功能性更强、更安全或语义上更加正确。在本章中,我们已经介绍了很多用于管理线程的pthread函数,包括线程属性对象的创建和使用。thread_object类是一个简单的框架类。它的目的是封装pthread线程接口并提供面向对象的语义和组件,使得您可以更加容易地实现在SDLC中产生的模型。现在我们将对thread_object类进行扩展,封装线程属性对象的一些功能。程序清单6-2显示了新的thread_object类和user_thread类的声明。
程序清单6-2
- //Listing 6-2 Declaration of the new thread_object and user_thread.
-
- 1 #ifndef __THREAD_OBJECT_H
- 2 #define __THREAD_OBJECT_H
- 3
- 4 using namespace std;
- 5 #include <iostream>
- 6 #include <pthread.h>
- 7 #include <string>
- 8
- 9 class thread_object{
- 10 pthread_t Tid;
- 11
- 12 protected:
- 13 virtual void do_something(void) = 0;
- 14 pthread_attr_t SchedAttr;
- 15 struct sched_param SchedParam;
- 16 string Name;
- 17 int NewPolicy;
- 18 int NewState;
- 19 int NewScope;
- 20 public:
- 21 thread_object(void);
- 22 ~thread_object(void);
- 23 void setPriority(int Priority);
- 24 void setSchedPolicy(int Policy);
- 25 void setContentionScope(int Scope);
- 26 void setDetached(void);
- 27 void setJoinable(void);
- 28
- 29 void name(string X);
- 30 void run(void);
- 31 void join(void);
- 32 friend void *thread(void *X);
- 33 };
- 34
- 35
- 36 class filter_thread : public thread_object{
- 37 protected:
- 38 void do_something(void);
- 39 public:
- 40 filter_thread(void);
- 41 ~filter_thread(void);
- 42 };
- 43
- 44 #endif
- 45
- 46
对于thread_object,我们加入了设置如下内容的方法:
调度策略
优先级
状态
竞争范围
我们定义了filter_thread类,其中定义了do_something( )方法,而不是在user_thread中定义该方法。这个类在下一章介绍同步时会使用到。
程序清单6-3是新的thread_object类的定义。
程序清单6-3
- //Listing 6-3 A definition of the new thread_object class.
-
- 1 #include "thread_object.h"
- 2
- 3 thread_object::thread_object(void)
- 4 {
- 5 pthread_attr_init(&SchedAttr);
- 6 pthread_attr_setinheritsched(&SchedAttr,PTHREAD_EXPLICIT_SCHED);
- 7 NewState = PTHREAD_CREATE_JOINABLE;
- 8 NewScope = PTHREAD_SCOPE_PROCESS;
- 9 NewPolicy = SCHED_OTHER;
- 10 }
- 11
- 12 thread_object::~thread_object(void)
- 13 {
- 14
- 15 }
- 16
- 17 void thread_object::join(void)
- 18 {
- 19 if(NewState == PTHREAD_CREATE_JOINABLE){
- 20 pthread_join(Tid,NULL);
- 21 }
- 22 }
- 23
- 24 void thread_object::setPriority(int Priority)
- 25 {
- 26 int Policy;
- 27 struct sched_param Param;
- 28
- 29 Param.sched_priority = Priority;
- 30 pthread_attr_setschedparam(&SchedAttr,&Param);
- 31 }
- 32
- 33
- 34 void thread_object::setSchedPolicy(int Policy)
- 35 {
- 36 if(Policy == 1){
- 37 pthread_attr_setschedpolicy(&SchedAttr,SCHED_RR);
- 38 pthread_attr_getschedpolicy(&SchedAttr,&NewPolicy);
- 39 }
- 40
- 41 if(Policy == 2){
- 42 pthread_attr_setschedpolicy(&SchedAttr,SCHED_FIFO);
- 43 pthread_attr_getschedpolicy(&SchedAttr,&NewPolicy);
- 44 }
- 45 }
- 46
- 47
- 48 void thread_object::setContentionScope(int Scope)
- 49 {
- 50 if(Scope == 1){
- 51 pthread_attr_setscope(&SchedAttr,PTHREAD_SCOPE_SYSTEM);
- 52 pthread_attr_getscope(&SchedAttr,&NewScope);
- 53 }
- 54
- 55 if(Scope == 2){
- 56 pthread_attr_setscope(&SchedAttr,PTHREAD_SCOPE_PROCESS);
- 57 pthread_attr_getscope(&SchedAttr,&NewScope);
- 58 }
- 59 }
- 60
- 61
- 62 void thread_object::setDetached(void)
- 63 {
- 64 pthread_attr_setdetachstate(&SchedAttr,PTHREAD_CREATE_DETACHED);
- 65 pthread_attr_getdetachstate(&SchedAttr,&NewState);
- 66
- 67 }
- 68
- 69 void thread_object::setJoinable(void)
- 70 {
- 71 pthread_attr_setdetachstate(&SchedAttr,PTHREAD_CREATE_JOINABLE);
- 72 pthread_attr_getdetachstate(&SchedAttr,&NewState);
- 73 }
- 74
- 75
- 76 void thread_object::run(void)
- 77 {
- 78 pthread_create(&Tid,&SchedAttr,thread,this);
- 79 }
- 80
- 81
- 82 void thread_object::name(string X)
- 83 {
- 84 Name = X;
- 85 }
- 86
- 87
- 88 void * thread (void * X)
- 89 {
- 90 thread_object *Thread;
- 91 Thread = static_cast<thread_object *>(X);
- 92 Thread->do_something();
- 93 return(NULL);
- 94 }
6.8 扩展线程接口类(2)
6.8 扩展线程接口类(2)
在程序清单6-3中,第3行~第10行定义的构造函数为SchedAttr这个类初始化一个线程属性对象。它将inheritsched属性设置为PTHREAD_EXPLICIT_SCHED,这样使用这个属性的对象创建的线程负责定义它的调度策略和优先级,而不是从创建者线程继承调度策略和优先级。默认情况下,线程的状态是JOINABLE。其他方法的含义一看便知:
- setPriority(int Priority)
- setSchedPolicy(int Policy)
- setContentionscope(int Scope)
- setDetached()
- setJoinable()
在第20行调用pthread_join( )之前,使用join( )检查线程是不是可结合的。当在第78行中创建线程时,pthread_create( )使用SchedAttr对象:
- pthread_create(&Tid, &SchedAttr, thread,this);
程序清单6-4显示了filter_thread的定义。
程序清单6-4
- //Listing 6-4 A definition of the filter_thread class.
-
- 1 #include "thread_object.h"
- 2
- 3
- 4 filter_thread::filter_thread(void)
- 5 {
- 6 pthread_attr_init(&SchedAttr);
- 7
- 8
- 9 }
- 10
- 11
- 12 filter_thread::~filter_thread(void)
- 13 {
- 14
- 15 }
- 16
- 17 void filter_thread::do_something(void)
- 18 {
- 19 struct sched_param Param;
- 20 int Policy;
- 21 pthread_t thread_id = pthread_self();
- 22 string Schedule;
- 23 string State;
- 24 string Scope;
- 25
- 26 pthread_getschedparam(thread_id,&Policy,&Param);
- 27 if(NewPolicy == SCHED_RR){Schedule.assign("RR");}
- 28 if(NewPolicy == SCHED_FIFO){Schedule.assign("FIFO");}
- 29 if(NewPolicy == SCHED_OTHER){Schedule.assign("OTHER");}
- 30 if(NewState == PTHREAD_CREATE_DETACHED){State.assign("DETACHED");}
- 31 if(NewState == PTHREAD_CREATE_JOINABLE){State.assign("JOINABLE");}
- 32 if(NewScope == PTHREAD_SCOPE_PROCESS){Scope.assign("PROCESS");}
- 33 if(NewScope == PTHREAD_SCOPE_SYSTEM){Scope.assign("SYSTEM");}
- 34 cout << Name << ":" << thread_id << endl
- 35 << "----------------------" << endl
- 36 << " priority: "<< Param.sched_priority << endl
-
37
<
< " policy: "
<
<
Schedule
<
<
endl
- 38 << " state: "<< State << endl
-
39
<
< " scope: "
<
<
Scope
<
<
endl
<
<
endl;
- 40
- 41 }
- 42
在程序清单6-4中,第4行~第9行的filter_thread构造函数使用线程属性对象SchedAttr进行初始化。定义了do_something( )方法。在filter_thread中,这个方法将如下线程信息发送到cout:
线程名称
线程id
优先级
调度策略
状态
范围
有些值可能未被初始化,因为它们不是在属性对象中设置的。下一章将会对这个方法进行重新定义。
现在可以创建多个filter_thread对象,每个对象可以设置线程的属性。程序清单6-5显示了如何创建多个filter_thread对象。
程序清单6-5
- //Listing 6-5 is main line to create multiple filter_thread objects.
-
- 1 #include "thread_object.h"
- 2 #include <unistd.h>
- 3
- 4
- 5 int main(int argc,char *argv[])
- 6 {
- 7 filter_thread MyThread[4];
- 8
- 9 MyThread[0].name("Proteus");
- 10 MyThread[0].setSchedPolicy(2);
- 11 MyThread[0].setPriority(7);
- 12 MyThread[0].setDetached();
- 13
- 14 MyThread[1].name("Stand Alone Complex");
- 15 MyThread[1].setContentionScope(1);
- 16 MyThread[1].setPriority(5);
- 17 MyThread[1].setSchedPolicy(2);
- 18
- 19 MyThread[2].name("Krell Space");
- 20 MyThread[2].setPriority(3);
- 21
- 22 MyThread[3].name("Cylon Space");
- 23 MyThread[3].setPriority(2);
- 24 MyThread[3].setSchedPolicy(2);
- 25
- 26 for(int N = 0;N < 4;N++)
- 27 {
- 28 MyThread[N].run();
- 29 MyThread[N].join();
- 30 }
- 31 return (0);
- 32 }
6.8 扩展线程接口类(3)
6.8 扩展线程接口类(3)
在程序清单6-5中,创建了4个filter_threads。下面是程序清单6-5的输出:
- Proteus:Stand Alone Complex:32
-
- ----------------------
- priority: 7
- ----------------------
- policy: FIFO priority:5
- state: policy: DETACHEDFIFO
-
- scope: state: PROCESSJOINABLE
-
-
- scope: SYSTEM
-
- Krell Space:4
- ----------------------
- priority: 3
- policy: OTHER
- state: JOINABLE
- scope: PROCESS
-
- Cylon Space:5
- ----------------------
- priority: 2
- policy: FIFO
- state: JOINABLE
- scope: PROCESS
主线程不等待分离的线程(Proteus),输出有一些混乱。Proteus开始进行输出,然后被来自Stand Alone Complex的输出打断。如前所述,标准cout不是线程安全的。如果所有的线程都是可结合的,那么输出将会像您所期望的那样:
- Proteus:2
- ----------------------
- priority: 7
- policy: FIFO
- state: JOINABLE
- scope: PROCESS
-
- Stand Alone Complex:3
- ----------------------
- priority: 5
- policy: FIFO
- state: JOINABLE
- scope: SYSTEM
-
- Krell Space:4
- ----------------------
- priority: 3
- policy: OTHER
- state: JOINABLE
- scope: PROCESS
-
- Cylon Space:5
- ----------------------
- priority: 2
- policy: FIFO
- state: JOINABLE
- scope: PROCESS
程序概要6-2
程序名:
- program6-2.cc
描述:
示范filter_thread类的使用。创建了4个线程,对每个线程进行了命名。每个线程调用更改将要创建的线程的一些属性的方法。
必需的库:
- libpthread
必需的头文件:
- thread_object.h
编译和链接指令:
-
c++ -o program6-2 program6-2.cc thread_
object.cc filter_thread.cc -lpthread
测试环境:
- Solaris 10、gcc 3.4.3和gcc 3.4.6
处理器:
- AMD Opteron和UltraSparc T1
执行指令:
- ./program6-2
thread_object类封装了线程属性对象的部分功能。filter_thread是用户线程,它继承了thread_object并定义了do_something( ),该函数由线程执行。在第7章中,将会再次扩展这个类的功能,以构成用作流水线模型中的一部分的assertion类。
6.9 小结
6.9 小结
线程是进程中可执行代码序列或流,操作系统将线程调度到处理器或内核上运行。本章介绍了多线程的相关内容,通过以上内容,您应当了解的关键知识包括:
所有进程都有一个主线程,它是进程的控制流。有着多个线程的进程有同样数目的控制流,它们独立且并发地执行。有着多个线程的进程是多线程的。
内核级线程或轻量级进程同进程相比,在创建、维护、管理方面带给操作系统的负担要轻一些,因为同线程关联的信息很少。内核线程在处理器上执行,它们由系统创建和管理。用户级线程通过运行时库来创建和管理。
通过使用线程,可以简化程序结构、使用最少的资源对固有并发进行建模、执行程序中独立的并发任务。线程可以改进应用程序的吞吐量和性能。
线程和进程都有id、寄存器组、状态和优先级,而且都遵从某种调度策略。两者均有上下文,用于重新构建被抢占的进程或线程。线程和子进程共享它们的父进程的资源并竞争对处理器的使用。父进程可以对子进程或线程具有一定的控制。线程或进程可以改变它们的属性并创建新的资源,但是不能够访问属于其他进程的资源。线程和进程之前最大的区别在于每个进程有着自己的地址空间,而线程则位于它所属于的进程的地址空间内。
POSIX线程库定义了线程属性对象,它封装了线程属性的一个子集。这些属性是可访问和可更改的。线程属性的类型为pthread_attr_t。pthread_attr_init( )使用默认值来初始化线程属性对象。一旦属性被适当地更改了,则可以把属性对象用作对任何pthread_create( )函数的调用中的参数。
thread_object接口类用作一个包装器,使得事物看上去同通常情况下的行为不同。设计新的接口的目的是使得类更易于使用、更具功能性、更安全或语义更正确。可以扩展thread_object来封装属性对象。
第7章将讨论进程和线程之间的通信和同步。并发任务之间可能会需要通信,以同步工作或对共享全局数据的访问。