JVM内存解析以及GC基本算法
详解介绍链接:http://www.cnblogs.com/springsource/archive/2013/01/11/2856968.html
1、JVM内存图
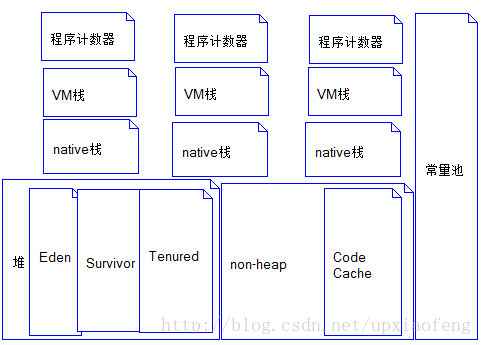
程序计数器:记录线程的执行位置
VM栈(线程栈):栈的默认大小是1M
native栈(本地方法栈):为一些native方法分配栈
堆:分Eden Survivor Tenured
年轻代:此代分为Eden space区,Survivo space区可以看成emptySurvivo区,Survivor。
老年代:Tenured
GC 常用算法:引用计数,标记清除,复制算法,标记整理
1)引用计数:
为每一个对象添加一个计数器,计数器记录对象的活跃引用数量。如果计数器为0,那么说明对象没有被引用,就会被作为垃圾回收。
引用计数的方法需要编译器的配合。编译器需要为此对象生成额外的代码。需要增加计数器和重置计数器,存在缺陷。
2)标记清除收集器:
收集过程先要停止所有工作,从根集遍历所有被引用的节点,然后进行标记,恢复所有工作;收集阶段会收集那些没有被标记的节点,返回空闲链表
缺点:暂停所有工作的时候,有可能导致换出内存;无论对象是否是垃圾都会被检查一遍,耗时过长;会产生大量的内存碎片
3)拷贝收集器:
推出这个算法是为了解决句柄的开销和堆碎片。内存被分为两个区(fromspace和tospace)。所有的对象被分配到fromspace,然后将活动的对象拷贝到tospace中,然后清空fromspace,之后将fromspace和tospce互换。
年轻代就采用次算法:分为eden区和两个survivor区,Eden和其中的一个Survivor区的存活对象将被复制到另外一个Survivor区,当另外一个Survivor区也满了的时候,从Eden和第一个Survivor区复制过来的并且此时还存活的对象,将被复制到tenured。
4)标记整理收集器(适合周期长的对象):
融合了标记清除和拷贝收集器的特点。分标记阶段(和标记清除一样的操作),整理阶段(将所有标记的对象放在堆底部)。
老年代中tenrued中用来存放这些生命周期较长的对象