深入JVM虚拟机(二) JVM运行机制
深入JVM虚拟机(二) JVM运行机制
1 JVM运行机制
1.1 JVM启动流程
JVM是Java程序运行的环境,同时是一个操作系统的一个应用程序进程,因此它有自己的生命周期,也有自己的代码和数据空间。JVM工作原理和特点主要是指操作系统装入JVM,是通过jdk中Java.exe来完成通过下面4步来完成JVM环境。
1、创建JVM装载环境和配置。
2、装载JVM.dll。
3、初始化JVM.dll并挂界到JNIENV(JNI调用接口)实例。
4、调用JNIEnv实例装载并处理class类。
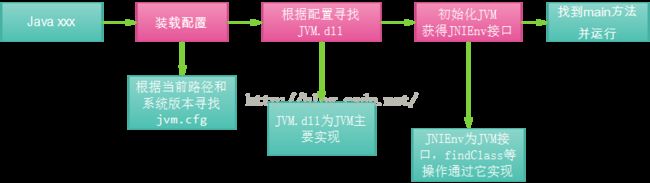
JVM启动流程图1-1
1.2 JVM基本结构
JVM中的内存主要划分为:方法区,Java堆区,Java虚拟机栈,本地方法栈,程序计数器栈五个部分,如下图:
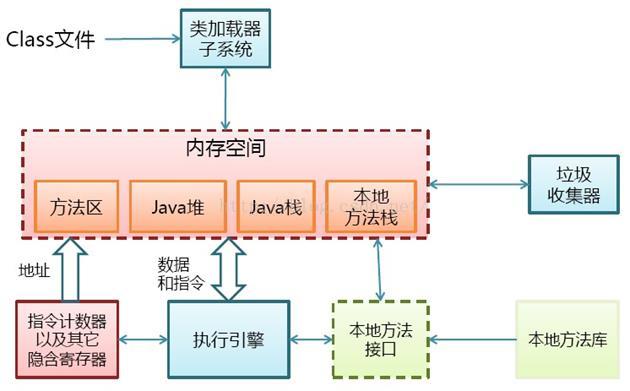
JVM基本结构图1-2
1、方法区:
也叫”永久代”,用于存储已经加载的类信息,常量,静态变量以及方法代码。方法区内存大小默认最小值为16MB,最大值为64MB。
2、Java堆:
线程共享的,存放所有对象实例和数组。垃圾回收的主要区域。可以分为新生代和老年代(tenured)。
新生代用于存放刚创建的对象以及年轻的对象,如果对象一直没有被回收,生存得足够长,老年对象就会被移入老年代。
新生代又可进一步细分为eden、survivorSpace0(s0,fromspace)、survivorSpace1(s1,tospace)。刚创建的对象都放入eden,s0和s1都至少经过一次GC并幸存。如果幸存对象经过一定时间仍存在,则进入老年代(tenured)。。

3、Java栈:
栈由一系列帧组成(因此Java栈也叫做帧栈),栈帧是后进先出的栈式结构,栈帧中存放方法运行时的局部变量、方法出口等信息。当调用一个方法时,就会在虚拟机栈中创建一个栈帧用于存放这些数据,方法调用完时栈帧消失。若方法中又调用了其他方法,则继续在栈顶创建新的栈。
4、本地方法栈:
与虚拟机栈类似,区别是本地方法栈是为Native方法服务的,而java虚拟机栈是为java方法服务的。
5、指令计数器:
多线程时,当线程数超过CPU数量或CPU内核数量,线程之间就要根据时间片轮询抢夺CPU时间资源。因此每个线程有要有一个独立的程序计数器,记录下一条要运行的指令。线程私有的内存区域。如果执行的是JAVA方法,计数器记录正在执行的java字节码地址,如果执行的是native方法,则计数器为空。
寄存器是最快的存储区,因为它位于不同于其他存储区的地方——处理器内部。但是寄存器的数量极其有限,所以寄存器根据需求进行分配。
6、垃圾收集器:
JVM分别对新生代和旧生代采用不同的垃圾回收机制。
7、执行引擎:
JVM通过执行引擎来完成字节码的执行,在执行过程中JVM采用的是自己的一套指令系统,每个线程在创建后,都会产生一个程序计数器(pc)和栈(Stack)。
1.3 Java栈
1、Java栈局部变量表:
public class StackDemo {
public static int runStatic(int i, long l, float f, Object o, byte b) {
return 0;
}
public int runInstance(char c, short s, boolean b) {
return 0;
}
}
静态方法runStatic()栈: 实例方法runInstance()栈:


2、函数调用组成帧栈:
public static int runStatic(int i, long l, float f, Object o, byte b) {
return runStatic(i, l, f, o, b);
}
runStatic()递归调用,每次调用都创建一个帧压到栈里面,直到栈帧溢出。方法调用结束后会自动移除。
 …
…
3、操作数栈
Java没有寄存器,所有参数传递使用操作数栈。
JAVA代码:
public static int add(int a, int b) {
int c = 0;
c = a + b;
return c;
}
0: iconst_0 // 0压栈
1: istore_2 //弹出int,存放于局部变量2
2: iload_0 //把局部变量0压栈
3: iload_1 //局部变量1压栈
4: iadd //弹出2个变量,求和,结果压栈
5: istore_2 //弹出结果,放于局部变量2
6: iload_2 //局部变量2压栈
7: ireturn //返回
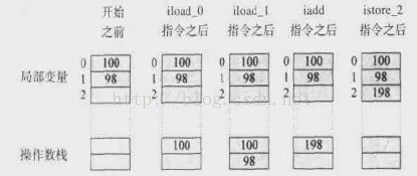
4、栈上分配
- 栈上一般都是分配的小对象(一般几十个bytes),并且在没有逃逸的情况下(逃逸:没有在别的地方进行引用)。
- 直接分配在栈上,可以自动回收,减轻GC压力。
- 大对象或者逃逸对象无法栈上分配。
1.4 栈、堆、方法区交互
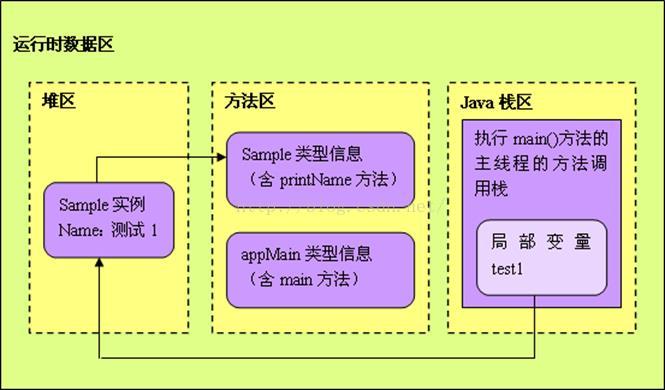
栈、堆、方法区交互图1-1
Java代码:
// 运行时, jvm 把appmain的信息都放入方法区
public class AppMain {
// main 方法本身放入方法区
public static void main(String[] args) {
// test1是引用,所以放到栈区里, Sample是自定义对象应该放到堆里面
Sample test1 = new Sample("测试1");
Sample test2 = new Sample("测试2");
test1.printName();
test2.printName();
}
}
public class Sample {
private String name;
// new Sample实例后, name 引用放入栈区里,name 对象放入堆里
public Sample(String name) {
this.name = name;
}
// print方法本身放入 方法区里
public void printName() {
System.out.println(name);
}
}
1.5 内存模型
1、内存模型:
- 每一个线程有一个工作内存和主存独立。
- 工作内存放主存中变量的值的拷贝。
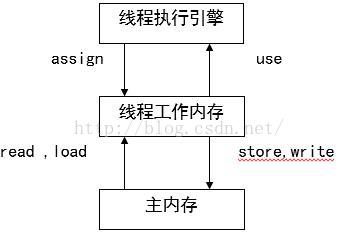
内存模型图1-1
- 当数据从主内存复制到工作存储时,必须出现两个动作:第一,由主内存执行的读(read)操作;第二,由工作内存执行的相应的load操作;当数据从工作内存拷贝到主内存时,也出现两个操作:第一个,由工作内存执行的存储(store)操作;第二,由主内存执行的相应的写(write)操作
- 每一个操作都是原子的,即执行期间不会被中断。
- 对于普通变量,一个线程中更新的值,不能马上反应在其他变量中,如果需要在其他线程中立即可见,需要使用 volatile关键字
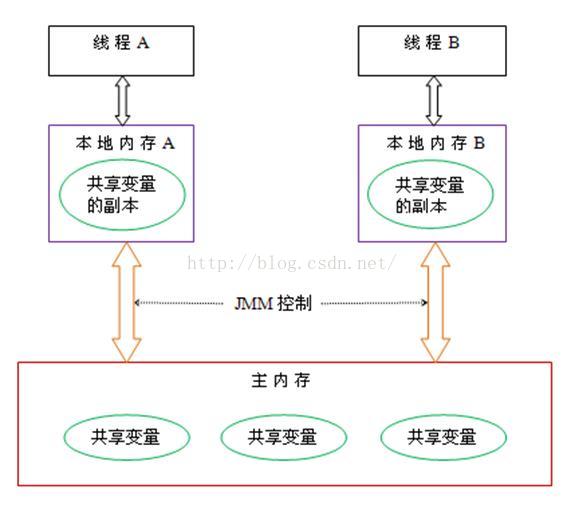
内存模型图1-2
2、volatile关键字
Java语言提供了一种稍弱的同步机制,即 volatile变量.用来确保将变量的更新操作通知到其他线程,保证了新值能立即同步到主内存,以及每次使用前立即从主内存刷新。当把变量声明为volatile类型后,编译器与运行时都会注意到这个变量是共享的。
JAVA代码:
public class VolatileStopThread extends Thread {
private volatile boolean stop = false;
// private boolean stop = false;
public void stopMe() {
stop = true;
}
public void run() {
int i = 0;
while (!stop) {
i++;
System.out.println("i=" + i);
}
System.out.println("Stop thread");
}
public static void main(String args[]) throws InterruptedException {
VolatileStopThread t = new VolatileStopThread();
t.start();
Thread.sleep(1000);
t.stopMe();
Thread.sleep(1000);
}
}
看了上面的代码 stop变量没有加,我们期待的是线程一直在执行,一直在while条件里面循环i++,实际执行结果:
i=145411
i=145412
Stop thread
分析原因:内存区域是jvm虚拟机栈,每一个线程运行时都有一个线程栈,线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了。
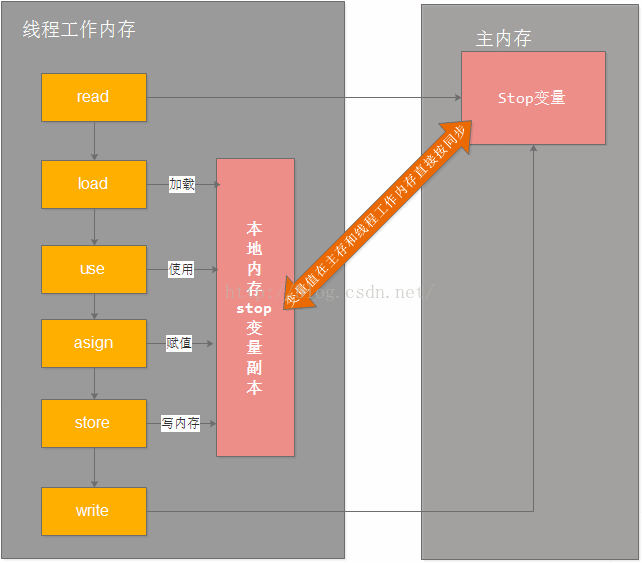
3、可见性
一个线程修改了变量,其他线程可以立即知道,保证可见性的方法:
volatile
synchronized(unlock之前,写变量值回主存)
final(一旦初始化完成,其他线程就可见)
4、有序性
- 在本线程内,操作都是有序的
- 在线程多线程情况下观察,操作都是无序的。无序有两种情况:
1:指令重排。
2:主内存同步延迟。
1.6 指令重排
1、指令重排:
- 线程内串行语义:
不可重排语句:
写后读 a = 1;b = a;写一个变量之后,再读这个位置。
写后写 a = 1;a = 2;写一个变量之后,再写这个变量。
读后写 a = b;b = 1;读一个变量之后,再写这个变量。
- 编译器不考虑多线程间的语义
- 可重排: a=1;b=2
2、指令重排–破坏线程间的有序性
JAVA代码:
public class OrderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1;
flag = true;
}
public void reader() {
if (flag) {
int i = a + 1;
}
}
}
线程A首先执行writer()方法
线程B线程接着执行reader()方法
线程B在int i=a+1 是不一定能看到a已经被赋值为1,因为在writer中,两句话顺序可能打乱
线程A:flag=true a=1
线程B:flag=true(此时a=0)
3、指令重排–保证有序性的方法
public class OrderExample {
int a = 0;
boolean flag = false;
public synchronized void writer() {
a = 1;
flag = true;
}
public synchronized void reader() {
if (flag) {
int i = a + 1;
}
}
}
同步后,即使做了writer重排,因为互斥的缘故,reader线程看writer线程也是顺序执行的。
线程A:flag=true a=1
线程B:flag=true(此时a=1)
4、指令重排的基本原则
- 程序顺序原则:一个线程内保证语义的串行性
- volatile规则:volatile变量的写,先发生于读
- 锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
- 传递性:A先于B,B先于C那么A必然先于C
- 线程的start方法先于它的每一个动作
- 线程的所有操作先于线程的终结(Thread.join())
- 线程的中断(interrupt())先于被中断线程的代码
- 对象的构造函数执行结束先于finalize()方法
1.7 字节码运行方式
1、解释运行
- 解释执行以解释方式运行字节码
- 解释执行的意思是:读一句执行一句
2、编译运行(JIT)
- 将字节码编译成机器码
- 直接执行机器码
- 运行时编译
- 编译后性能有数量级的提升
——厚积薄发(yuanxw)