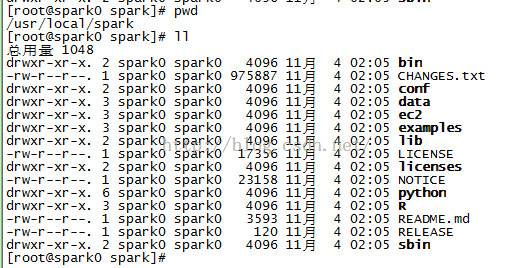
5-1、Spark环境搭建
2、Spark环境搭建
2.1、官网下载
Spark官网地址:http://spark.apache.org/
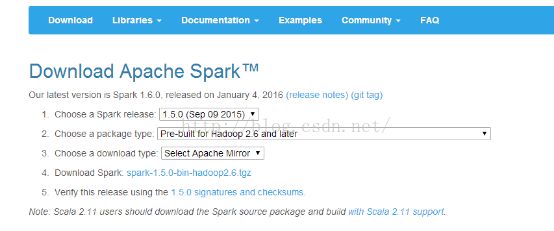
下载后如下:
![]()
Linux上安装部署Spark
Jdk
Scala
SSH
Hadoop
Spark
2.2、安装模式
Local模式(学习、测试之用)
Standalone模式(内置的资源管理和调度框架)
Mesos(Apache)
Yarn(Hadoop)
2.3、local模式
软件:
jdk1.8
centos6.5
hadoop2.6.0
spark-1.5.2-bin-hadoop2.6.tgz
1、解压,编辑spark-env.sh文件
[html] view plain copy print?
1. [root@spark0 conf]# cp spark-env.sh.template spark-env.sh
2. [root@spark0 conf]# vim spark-env.sh
3. SPARK_MASTER_IP=192.168.6.2

2、设置主节点IP地址:

3、设置从节点IP地址:
![]()
添加IP地址:
![]()
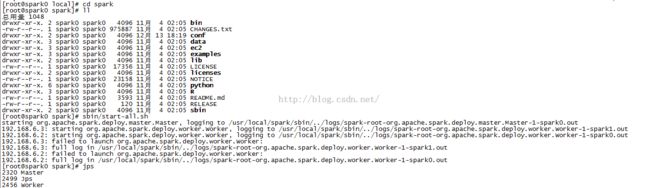
4、启动:
[html] view plain copy print?
1. sbin/start-all.sh

查看进程:
![]()
5、启动spark-shell:
[html] view plain copy print?
1. bin/spark-shell

6、运行一个简单的例子:
[html] view plain copy print?
1. val rdd=sc.textFile("/home/spark0/spark.txt").collect

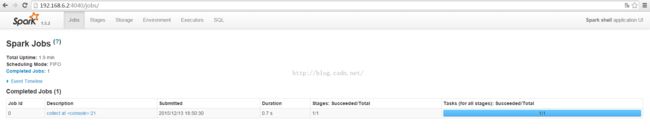
7、网页 http://192.168.6.2:4040/jobs/ 查看任务:
2.4、Standalone模式
提前安装好hadoop,
我准备了两个节点,jdk和hadoop先安装好。
我用的两个节点,电脑配置不行,3个节点演示能更好些
1、解压
2、编辑文件:
[html] view plain copy print?
1. [root@spark0 conf]# cpspark-env.sh.template spark-env.sh
2. [root@spark0 conf]# vim spark-env.sh
3. SPARK_MASTER_IP=192.168.6.2
4.
5. [root@spark0 conf]# cp slaves.templateslaves
6. [root@spark0 conf]# vim slaves
7. # A Spark Worker will be started on each ofthe machines listed below.
8. 192.168.6.2
9. 192.168.6.3
10.
3、配置好的拷贝到另一个几点上面去:
[root@spark0 local]# scp -r sparkspark1:/usr/local/
4、查看主节点的进程,除了worker还有master
5、查看另一个节点,除了hadoop进程,只有worker,没有master进程

6、例子,先在本地设置一个文件

7、打开spark-shell,运行一个小例子:
[html] view plain copy print?
1. scala> val rdd=sc.textFile("/home/spark0/spark.txt").collect

8、关闭,两个节点的spark集群:

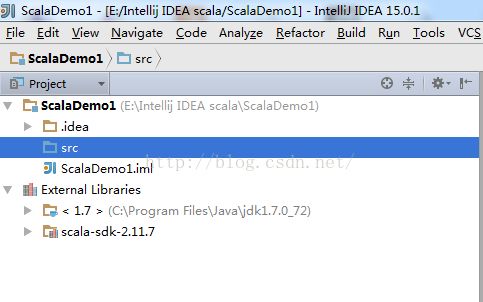
2.5、Intellij IDEA搭建配置Scala环境
Intellij IDEA搭建配置Scala环境
1、配置Scala插件:

选择安装插件:

点击Install:

安装进度:

安装完插件之后,重启Intellij IDEA:

2、配置JDK:
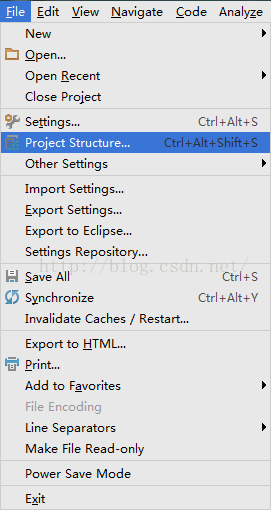
把本地的JDK加载进去:

加载了Jdk和Scala:
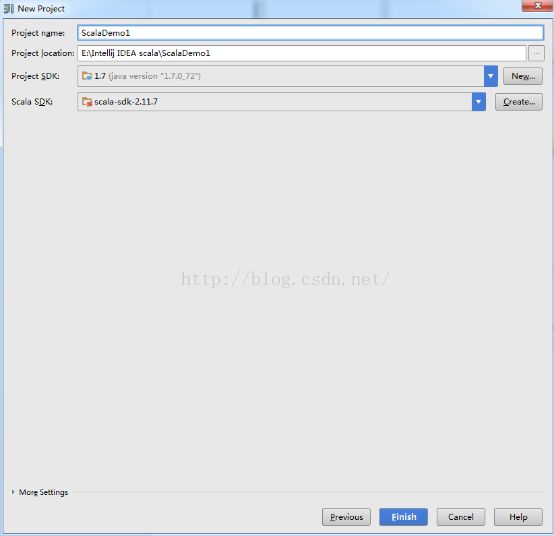
3、搭建一个Scala项目:

项目名称和项目地址:
右键src目录,新建package和类:
书写简单的测验代码:
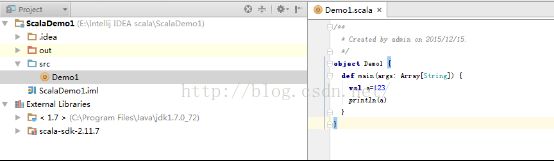
代码如下:
| /**
|
右键该类,运行代码:
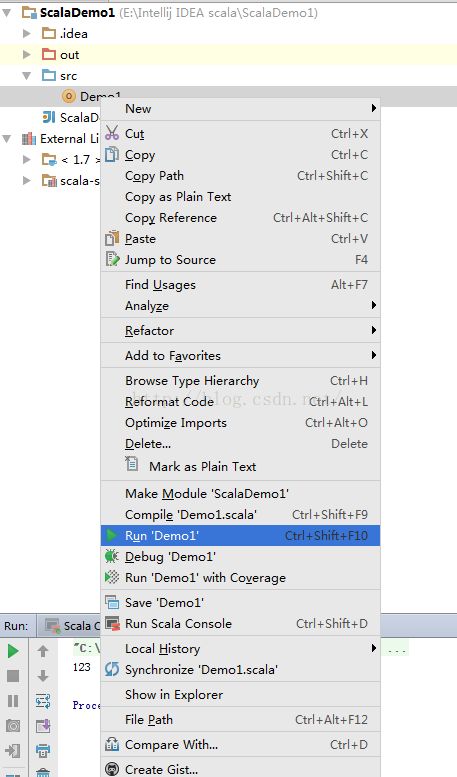
运行结果:
4、打包:
Next step:
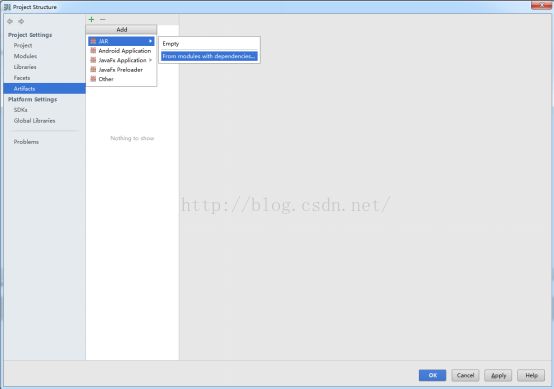
选择主类:
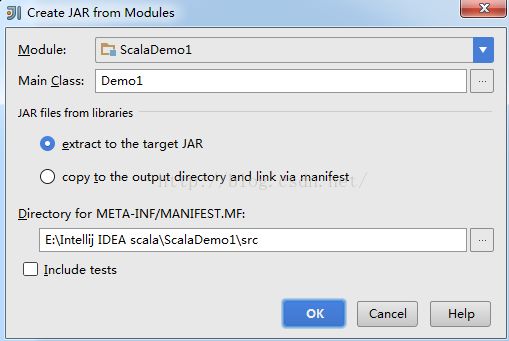
Next step:
点击应用、OK
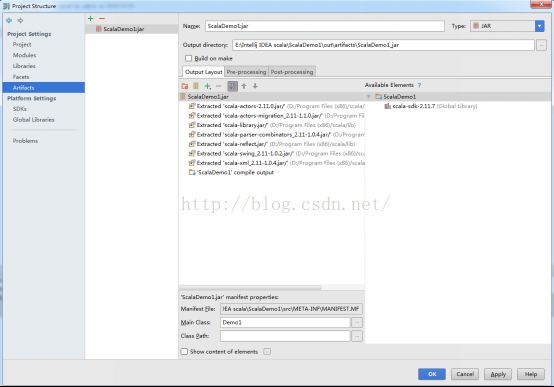
Next step:
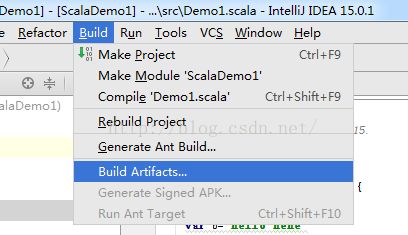
Next step:

Next step:
本地打好的包:
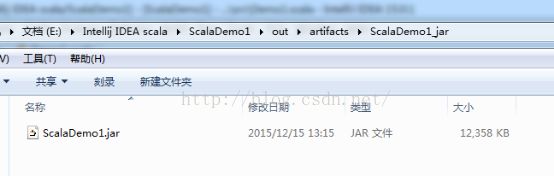
2.6、Intellij IDEA开发集群提交运行Spark代码
Intellij IDEA开发集群提交运行Spark代码
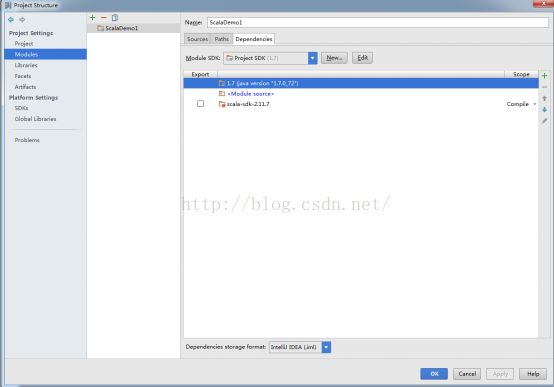
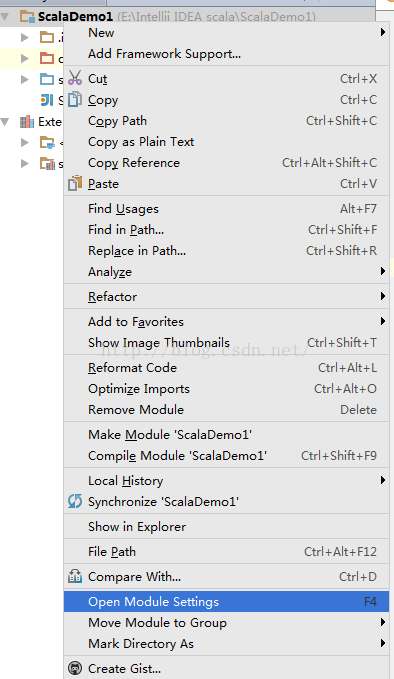
1、 右键项目:
选择倒第四个Open Module Settings:
2、添加Spark依赖包:
添加进去:

3、进度:
![]()
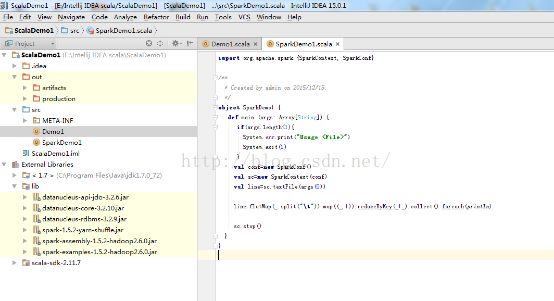
4、编写Wc代码:
新建一个Scala类,开始编写spark代码:
| import org.apache.spark.{SparkContext, SparkConf}
|
Intellij IDA视图如下:
5、打包:
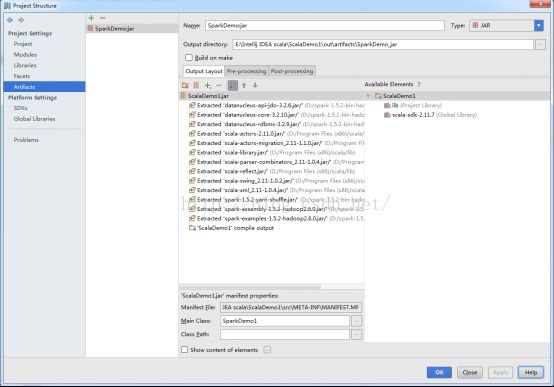
打好的包:

用的是Standalone集群:

![]()
6、集群运行代码:
[root@spark0 spark]# bin/spark-submit --class SparkDemo1 /usr/local/spark/ScalaDemo1.jar /usr/local/spark-1.5.2-bin-hadoop2.6/bigdata/wcDemo1.txt
![]()
运行结果:
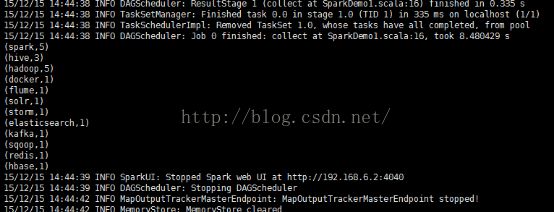
整个运行过程:
| [root@spark0 spark]# bin/spark-submit --class SparkDemo1 /usr/local/spark/ScalaDemo1.jar /usr/local/spark-1.5.2-bin-hadoop2.6/bigdata/wcDemo1.txt Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties 15/12/15 14:44:21 INFO SparkContext: Running Spark version 1.5.2 15/12/15 14:44:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 15/12/15 14:44:21 INFO SecurityManager: Changing view acls to: root 15/12/15 14:44:21 INFO SecurityManager: Changing modify acls to: root 15/12/15 14:44:21 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root) 15/12/15 14:44:23 INFO Slf4jLogger: Slf4jLogger started 15/12/15 14:44:23 INFO Remoting: Starting remoting 15/12/15 14:44:23 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:40172] 15/12/15 14:44:23 INFO Utils: Successfully started service 'sparkDriver' on port 40172. 15/12/15 14:44:23 INFO SparkEnv: Registering MapOutputTracker 15/12/15 14:44:23 INFO SparkEnv: Registering BlockManagerMaster 15/12/15 14:44:23 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-dbd5e9f3-bfa1-4c03-9bbe-9ff2661049f2 15/12/15 14:44:23 INFO MemoryStore: MemoryStore started with capacity 534.5 MB 15/12/15 14:44:23 INFO HttpFileServer: HTTP File server directory is /tmp/spark-ffda6806-746c-4740-9558-bd3a047fafe2/httpd-0ded5c18-fb57-4ab7-bcd2-3ef6a5fa550d 15/12/15 14:44:23 INFO HttpServer: Starting HTTP Server 15/12/15 14:44:23 INFO Utils: Successfully started service 'HTTP file server' on port 40716. 15/12/15 14:44:23 INFO SparkEnv: Registering OutputCommitCoordinator 15/12/15 14:44:24 INFO Utils: Successfully started service 'SparkUI' on port 4040. 15/12/15 14:44:24 INFO SparkUI: Started SparkUI at http://192.168.6.2:4040 15/12/15 14:44:24 INFO SparkContext: Added JAR file:/usr/local/spark/ScalaDemo1.jar at http://192.168.6.2:40716/jars/ScalaDemo1.jar with timestamp 1450161864561 15/12/15 14:44:24 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set. 15/12/15 14:44:24 INFO Executor: Starting executor ID driver on host localhost 15/12/15 14:44:25 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 40076. 15/12/15 14:44:25 INFO NettyBlockTransferService: Server created on 40076 15/12/15 14:44:25 INFO BlockManagerMaster: Trying to register BlockManager 15/12/15 14:44:25 INFO BlockManagerMasterEndpoint: Registering block manager localhost:40076 with 534.5 MB RAM, BlockManagerId(driver, localhost, 40076) 15/12/15 14:44:25 INFO BlockManagerMaster: Registered BlockManager 15/12/15 14:44:29 INFO MemoryStore: ensureFreeSpace(130448) called with curMem=0, maxMem=560497950 15/12/15 14:44:29 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 127.4 KB, free 534.4 MB) 15/12/15 14:44:29 INFO MemoryStore: ensureFreeSpace(14276) called with curMem=130448, maxMem=560497950 15/12/15 14:44:29 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 13.9 KB, free 534.4 MB) 15/12/15 14:44:29 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:40076 (size: 13.9 KB, free: 534.5 MB) 15/12/15 14:44:29 INFO SparkContext: Created broadcast 0 from textFile at SparkDemo1.scala:14 15/12/15 14:44:30 INFO FileInputFormat: Total input paths to process : 1 15/12/15 14:44:30 INFO SparkContext: Starting job: collect at SparkDemo1.scala:16 15/12/15 14:44:30 INFO DAGScheduler: Registering RDD 3 (map at SparkDemo1.scala:16) 15/12/15 14:44:30 INFO DAGScheduler: Got job 0 (collect at SparkDemo1.scala:16) with 1 output partitions 15/12/15 14:44:30 INFO DAGScheduler: Final stage: ResultStage 1(collect at SparkDemo1.scala:16) 15/12/15 14:44:30 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0) 15/12/15 14:44:30 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0) 15/12/15 14:44:30 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at SparkDemo1.scala:16), which has no missing parents 15/12/15 14:44:30 INFO MemoryStore: ensureFreeSpace(4064) called with curMem=144724, maxMem=560497950 15/12/15 14:44:30 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.0 KB, free 534.4 MB) 15/12/15 14:44:30 INFO MemoryStore: ensureFreeSpace(2328) called with curMem=148788, maxMem=560497950 15/12/15 14:44:30 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.3 KB, free 534.4 MB) 15/12/15 14:44:30 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:40076 (size: 2.3 KB, free: 534.5 MB) 15/12/15 14:44:30 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:861 15/12/15 14:44:30 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at SparkDemo1.scala:16) 15/12/15 14:44:30 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks 15/12/15 14:44:30 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 2213 bytes) 15/12/15 14:44:30 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 15/12/15 14:44:30 INFO Executor: Fetching http://192.168.6.2:40716/jars/ScalaDemo1.jar with timestamp 1450161864561 15/12/15 14:44:31 INFO Utils: Fetching http://192.168.6.2:40716/jars/ScalaDemo1.jar to /tmp/spark-ffda6806-746c-4740-9558-bd3a047fafe2/userFiles-e4174a0b-997b-424c-893b-0570668f9320/fetchFileTemp8876302010385452933.tmp 15/12/15 14:44:36 INFO Executor: Adding file:/tmp/spark-ffda6806-746c-4740-9558-bd3a047fafe2/userFiles-e4174a0b-997b-424c-893b-0570668f9320/ScalaDemo1.jar to class loader 15/12/15 14:44:36 INFO HadoopRDD: Input split: file:/usr/local/spark-1.5.2-bin-hadoop2.6/bigdata/wcDemo1.txt:0+142 15/12/15 14:44:36 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 15/12/15 14:44:36 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 15/12/15 14:44:36 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 15/12/15 14:44:36 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 15/12/15 14:44:36 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 15/12/15 14:44:37 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2253 bytes result sent to driver 15/12/15 14:44:37 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 7131 ms on localhost (1/1) 15/12/15 14:44:37 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 15/12/15 14:44:38 INFO DAGScheduler: ShuffleMapStage 0 (map at SparkDemo1.scala:16) finished in 7.402 s 15/12/15 14:44:38 INFO DAGScheduler: looking for newly runnable stages 15/12/15 14:44:38 INFO DAGScheduler: running: Set() 15/12/15 14:44:38 INFO DAGScheduler: waiting: Set(ResultStage 1) 15/12/15 14:44:38 INFO DAGScheduler: failed: Set() 15/12/15 14:44:38 INFO DAGScheduler: Missing parents for ResultStage 1: List() 15/12/15 14:44:38 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at SparkDemo1.scala:16), which is now runnable 15/12/15 14:44:38 INFO MemoryStore: ensureFreeSpace(2288) called with curMem=151116, maxMem=560497950 15/12/15 14:44:38 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.2 KB, free 534.4 MB) 15/12/15 14:44:38 INFO MemoryStore: ensureFreeSpace(1375) called with curMem=153404, maxMem=560497950 15/12/15 14:44:38 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1375.0 B, free 534.4 MB) 15/12/15 14:44:38 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:40076 (size: 1375.0 B, free: 534.5 MB) 15/12/15 14:44:38 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:861 15/12/15 14:44:38 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at SparkDemo1.scala:16) 15/12/15 14:44:38 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks 15/12/15 14:44:38 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, PROCESS_LOCAL, 1955 bytes) 15/12/15 14:44:38 INFO Executor: Running task 0.0 in stage 1.0 (TID 1) 15/12/15 14:44:38 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks 15/12/15 14:44:38 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 96 ms 15/12/15 14:44:38 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1541 bytes result sent to driver 15/12/15 14:44:38 INFO DAGScheduler: ResultStage 1 (collect at SparkDemo1.scala:16) finished in 0.335 s 15/12/15 14:44:38 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 335 ms on localhost (1/1) 15/12/15 14:44:38 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 15/12/15 14:44:38 INFO DAGScheduler: Job 0 finished: collect at SparkDemo1.scala:16, took 8.480429 s (spark,5) (hive,3) (hadoop,5) (docker,1) (flume,1) (solr,1) (storm,1) (elasticsearch,1) (kafka,1) (sqoop,1) (redis,1) (hbase,1) 15/12/15 14:44:39 INFO SparkUI: Stopped Spark web UI at http://192.168.6.2:4040 15/12/15 14:44:39 INFO DAGScheduler: Stopping DAGScheduler 15/12/15 14:44:42 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 15/12/15 14:44:42 INFO MemoryStore: MemoryStore cleared 15/12/15 14:44:42 INFO BlockManager: BlockManager stopped 15/12/15 14:44:42 INFO BlockManagerMaster: BlockManagerMaster stopped 15/12/15 14:44:42 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 15/12/15 14:44:42 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon. 15/12/15 14:44:42 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. 15/12/15 14:44:42 INFO SparkContext: Successfully stopped SparkContext 15/12/15 14:44:42 INFO ShutdownHookManager: Shutdown hook called 15/12/15 14:44:42 INFO ShutdownHookManager: Deleting directory /tmp/spark-ffda6806-746c-4740-9558-bd3a047fafe2 [root@spark0 spark]# |
7、关闭Spark集群:

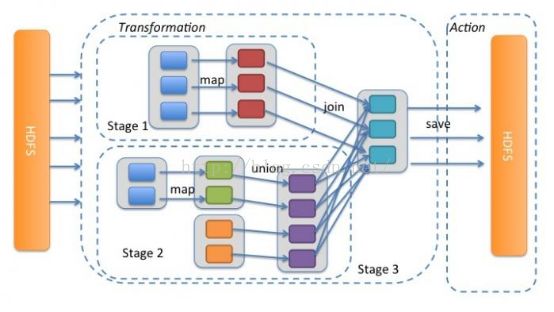
2.7、spark的union和join操作演示
union简介:
通常如果我们需要将两个select语句的结果作为一个整体显示出来,我们就需要用到union或者union all关键字。union(或称为联合)的作用是将多个结果合并在一起显示出来。
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
(Union All:对两个结果集进行并集操作,包括重复行,不进行排序;)
Join连接:
SQL中大概有这么几种JOIN:
cross join 交叉连接(笛卡尔积)
inner join 内连接
left outer join 左外连接(左面有的,右面没有的,右面填NULL)
right outer join 右外连接
full outer join 全连接
创建rdd1:
scala> val rdd1=sc.parallelize(List(('a',2),('b',4),('c',6),('d',9)))
rdd1: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[6] at parallelize at <console>:15
创建rdd2:
scala> val rdd2=sc.parallelize(List(('c',6),('c',7),('d',8),('e',10)))
rdd2: org.apache.spark.rdd.RDD[(Char, Int)] = ParallelCollectionRDD[7] at parallelize at <console>:15
执行union:
scala> val unionrdd=rdd1 union rdd2
unionrdd: org.apache.spark.rdd.RDD[(Char, Int)] = UnionRDD[8] at union at <console>:19
scala> unionrdd.collect
res2: Array[(Char, Int)] = Array((a,2), (b,4), (c,6), (d,9), (c,6), (c,7), (d,8), (e,10))
执行:join:
scala> val joinrdd=rdd1 join rdd2
joinrdd: org.apache.spark.rdd.RDD[(Char, (Int, Int))] = MapPartitionsRDD[11] at join at <console>:19
scala> joinrdd.collect
res3: Array[(Char, (Int, Int))] = Array((d,(9,8)), (c,(6,6)), (c,(6,7)))
