《Hadoop:The Definitive Guide 4th Edition》Chapter 17 Hive——B部分
一、Hive与常规关系型数据库的比较
1.1、“读一致”模型和“写一致”模型
常规关系型数据库采用“写一致”模型,当写入数据到表时,对数据进行检验,只有当数据格式符合表结构时,才允许写入;Hive采用“读一致”模型,当写入数据到表时,不进行检验,只有当从表中读取数据时,才进行检验,当数据格式不符合表结构时,会给出提示。
1.2、同类替代项目
可替代Hive的同类项目有:Cloudera Impala,Presto,Apache Drill,Spark SQL,Hive On Spark,Apache Phoenix。(Hive On Spark和Spark SQL的区别在于,Spark SQL是一个全新的项目,Hive On Spark只是使用Spark替换MapReduce作为执行引擎)。
二、HiveQL
HiveQL语法是SQL-92,Mysql和Oracle SQL语法的混杂。HiveQL与SQL(SQL-92,Mysql和Oracle SQL)的总体比较如表1所示。
另外,总的来说,HiveQL语句是不区分大小写的,除非是在字符串比较中,比如“Hello”与“hello”的比较结果是false。
表1
| 特性 | SQL | HiveQL |
|---|---|---|
| 支持操作 | UPDATE,INSERT,DELETE | UPDATE,INSERT,DELETE |
| 事务 | 支持 | 有限支持 |
| 索引 | 支持 | 支持 |
| 数据类型 | 整型,浮点型,字符串,时间类型 | 布尔型,整型,浮点型,字符串,时间类型,数组,映射,结构体,联合体 |
| 函数 | 大量内置函数 | 大量内置函数 |
| Multiple Inserts | 不支持 | 支持 |
| CREATE TABLE…AS SELECT | SQL92中不支持,Mysql中支持 | 支持 |
| Join | 支持 | 支持 |
| 子查询 | 支持 | 支持 |
| 视图 | 支持 | 支持,只可读 |
| 扩展性 | 支持自定义函数,存储过程 | 支持自定义函数,MapReduce脚本 |
2.1、数据类型
数据类型包括基本数据类型和复杂数据类型。
基本数据类型包括:
BOOLEAN,TINYINT,SMALLINT,INT,BIGINT,FLOAT,DOUBLE,DECIMAL,STRING,VARCHAR,CHAR,BINARY,TIMESTAMP,DATE;
复杂数据类型包括:
ARRAY,MAP,STRUCT,UNION。
2.2、操作符和函数
SQL中的一般操作符,比如“=”,“IS NULL”,“LIKE”,“+”,“OR”等,在HiveQL中都得到了支持。HiveQL内建了大量的函数,可通过SHOW FUNCTIONS命令查看这些函数,如果想获取某个函数的说明,可通过DESCRIBE FUNCTION functionname命令。
三、Hive表
Hive表由两部分组成:表数据和表结构数据。表数据一般存放在HDFS文件系统中,以文件形式存在;表结构数据即表元数据,存放在Metastore中。
Hive支持多个数据库和表,这些数据库和表的元数据信息都存放在Metastore中。
接下来分为“创建表”,“表数据存储格式”,“导入表数据”,“更改表”和“删除表”5部分来进行介绍。
3.1、创建表
3.1.1、两种表
Hive表分为“一般表”和“外部表”两种。对于这两种表的描述见表2。
表2
| 表 | 表创建语句 | 表创建发生行为 | 表删除语句 | 表删除发生行为 |
|---|---|---|---|---|
| 一般表 | CREATE TABLE tablename … | 表元数据保存到Metastore,在HDFS文件系统中特定目录下建立以表名为名称的目录,作为表数据存放目录 | DROP TABLE tablename | 删除元数据,删除表数据存放目录 |
| 外部表 | CREATE EXTERNAL TABLE tablename … [LOCATION ‘pathname’] | 表元数据保存到Metastore,如果没有LOCATION语句,跟一般表创建过程一样,在HDFS文件系统中特定目录下建立以表名为名称的目录,作为表数据存放目录;否则,表示表数据存放目录为“pathname”指代目录 | DROP TABLE tablename | 只删除元数据,不删除表数据存放目录 |
3.1.2、表的分区形式和桶形式
3.1.2.1、表的分区
对表进行分区主要是为了更方便地管理维护这些分区的表数据。建表时通过PARTITIONED BY语句可以表明欲建表需要分区,分区表与未分区表在表数据存储结构上也不相同,具体是前者的表数据存储结构相对于后者有增加的“子目录”层(注意,可以有多层嵌套分区,自然也就有多层嵌套增加的“子目录”)。
1、未分区表
创建一个未分区表,例子命令如下:
CREATE TABLE unpartitioned(id STRING);本地有一个文件“a.txt”,内容如下所示:
1
2
3
4
5通过数据导入命令将“a.txt”文件内容导入到“unpartitioned”表中,导入命令如下:
LOAD DATA LOCAL INPATH 'a.txt' INTO TABLE unpartitioned;此时查看表“unpartitioned”表数据存放目录,可得如图1所示结果。
图1

2、分区表
创建一个分区表,例子命令如下:
CREATE TABLE partitioned(id STRING) PARTITIONED BY(date STRING);本地有一个文件“b.txt”,内容如下所示:
1
2
3
4
5通过数据导入命令将“b.txt”文件内容导入到“partitioned”表中,导入命令如下:
LOAD DATA LOCAL INPATH 'b.txt' INTO TABLE partitioned PARTITION(date='2016-02-22');此时查看表“partitioned”表数据存放目录,可得如图2和图3所示结果。
图2

图3

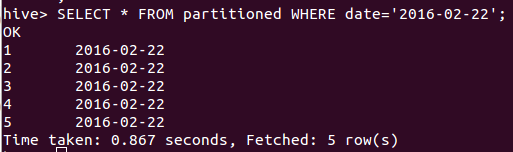
现在可以方便地根据分区查询表数据,比如:
SELECT * FROM partitioned WHERE date='2016-02-22';命令执行结果如图4所示。
图4
3.1.2.2、表的桶形式
本来,表数据存放时,哪些表数据存放到哪个HDFS文件是没有规则的。表的桶形式就是定义了这样的一个规则。比如根据表的某个字段(整型值)进行桶分配,现有4个桶,那么该字段的哈希值为“0,4,8…”的表记录数据保存到桶文件0,依此类推。
欲使用表的桶形式,需要使用CLUSTERED BY语句,比如如下所示:
#建立一个名为“bucketed_users”的表,使用“表的桶形式”,根据“id”字段进行桶的分配,共分为4个桶
CREATE TABLE bucketed_users(id INT,name STRING) CLUSTERED BY(id) INTO 4 BUCKETS;3.2、表数据存储格式
表数据存储格式主要有“row format”和“file format”这两方面内容。“row format”表示表中行数据的存储格式,比如行中字段之间以什么字符隔开,行与行之间以什么字符隔开,通过ROW FORMAT语句来指定;“file format”表示表中最终数据的存储格式,比如是以文本形式存储(当然最终还是保存为二进制形式),还是转换为二进制形式进行存储,通过STORED AS语句来指定。简单介绍见表3。
表3
| / | 文本存储形式 | 二进制形式存储 |
|---|---|---|
| file format | 以文本形式存储 | 以二进制形式存储 |
| row format | 默认以ASCII码表中值为1-8的8个字符作为字段之间的分隔符,比如’\001’,’\002’等,以’\n’作为行与行之间的分隔符 | 不能通过ROW FORMAT语句指定 |
| 建表 | STORED AS语句只能为STORED AS TEXTFILE。可通过 ROW FORMAT语句来指定‘row format’。比如 CREATE TABLE ... ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' COLLECTION ITEMS TERMINATED BY '\002' MAP KEYS TERMINATED BY '\003' LINES TERMINATED BY '\n' STORED AS TEXTFILE。默认的 CREATE TABLE语句其实等价于上面的语句 |
无需ROW FORMAT语句。有多种二进制存储形式:“Sequence file”,“Avro datafile”,“Parquet file”,“RCFile”,“ORCFile”等,因此 STORED AS语句可以是:STORED AS SEQUENCEFILE[AVRO,PARQUET,RCFile,ORC]。比如 CREATE TABLE users_parquet STORED AS PARQUET |
3.3、导入表数据
见《Hive表导入数据的几种方式》
3.4、更改表
可以使用ALTER TABLE命令更改Hive表,包括表结构,增加或者删除表分区,改变或者替换表的列,改变表的属性等。
3.5、删除表
可以使用DROP TABLE命令删除Hive表。对于一般表来说,该命令会删除表的元数据和表数据存放目录;对于外部表来说,该命令只会删除表的元数据。
四、查询表数据
通过SELECT命令查询Hive表的数据。
4.1、连接
Hive中两表的连接表达式只支持“等号”,比如如下形式不被支持:
SELECT * FROM a INNER JOIN b ON a.id>b.idHive中支持内连接,外连接(包含左外连接,右外连接和全外连接),半连接和映射连接。简单介绍见表4。
表4
| 中文名 | 英文名 | 关键词 | 含义 |
|---|---|---|---|
| 内连接 | Inner Joins | INNER JOIN | 只有匹配的行才在最终结果表中出现 |
| 外连接 | Outer Joins | LEFT OUTER JOIN,RIGHT OUTER JOIN,FULL OUTER JOIN | LEFT OUTER JOIN:左侧表中的行一定会在最终结果表中出现;RIGHT OUTER JOIN:右侧表中的行一定会在最终结果表中出现;FULL OUTER JOIN:左侧或者右侧表中的行一定会在最终结果表中出现 |
| 半连接 | Semi Joins | LEFT SEMI JOIN | 能够使用“IN语句”替代,没有多大意义 |
| 映射连接 | Map Joins | 没有特定的关键词,使用通用关键词“JOIN” | 将一个小表的内容载入内存,加快效率。通过设置“hive.auto.convert.join=true”,使得大小小于“hive.mapjoin.smalltable.filesize”值的表被自动载入内存 |
4.2、子查询
Hive支持在FROM语句或者WHERE语句后面使用子查询语句。
4.3、视图
使用CREATE VIEW viewname AS SELECT语句建立Hive视图,注意与CREATE TABLE tablename AS SELECT语句的对比。
五、自定义函数
Hive中自定义函数的实现只能使用Java语言。Hive中支持3种自定义函数,分别为:UDF,UDAF和UDTF。这3种自定义函数的简单介绍见表5。
表5
| 名称 | 含义 |
|---|---|
| UDF | 输入一行,输出也是一行 |
| UDAF | 输入多行,输出一行 |
| UDTF | 输入一行,输出多行。在实际使用中,有诸多限制,故而使用“LATERAL VIEW”作为替换 |
接下来简单介绍UDF和UDAF。
5.1、UDF
5.1.1、创建UDF
创建UDF需要满足两个条件:1)UDF类必须继承“org.apache.hadoop.hive.ql.exec.UDF”;2)UDF类中必须实现一个“evaluate”方法。
Hive中使用反射来调用实现的“evaluate”方法,因而对于“evaluate”方法没有“方法参数类型和数量”的限制,也没有“返回类型”的限制。
一个UDF类的例子如下:
package com.hadoopbook.hive;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class Strip extends UDF {
private Text result = new Text();
public Text evaluate(Text str) {
if (str == null) {
return null;
}
result.set(StringUtils.strip(str.toString()));
return result;
}
public Text evaluate(Text str, String stripChars) {
if (str == null) {
return null;
}
result.set(StringUtils.strip(str.toString(), stripChars));
return result;
}
}
5.1.2、使用UDF
想要使用该UDF,首先得将包含UDF类的代码打包成一个JAR包,然后将该JAR包复制到Hive使用的“auxlib”目录下(这个“auxlib”目录可以通过“–auxpath”选项或者“HIVE_AUX_JARS_PATH”环境变量来指定),或者也可以使用USING JAR语句加载该特定的JAR包。
在HiveQL脚本中,通过CREATE FUNCTION(持久化定义)或者CREATE TEMPORARY FUNCTION(临时定义)进行自定义函数的定义声明。
通过DROP FUNCTION进行自定义函数定义声明的删除。
5.2、UDAF
5.2.1、创建UDAF
创建UDAF需要满足两个条件:1)UDAF类必须继承“org.apache.hadoop.hive.ql.exec.UDAF”;2)UDAF类中必须实现“init”,“iterate”,“terminatePartial”,“merge”和“terminate”这5个方法。
Hive中使用反射来调用实现的以上5个方法。
5.2.2、使用UDAF
跟使用UDF基本一致。
六、其他
6.1、EXPLAIN语句
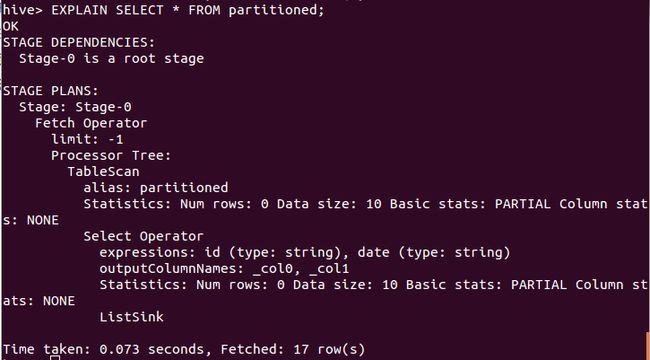
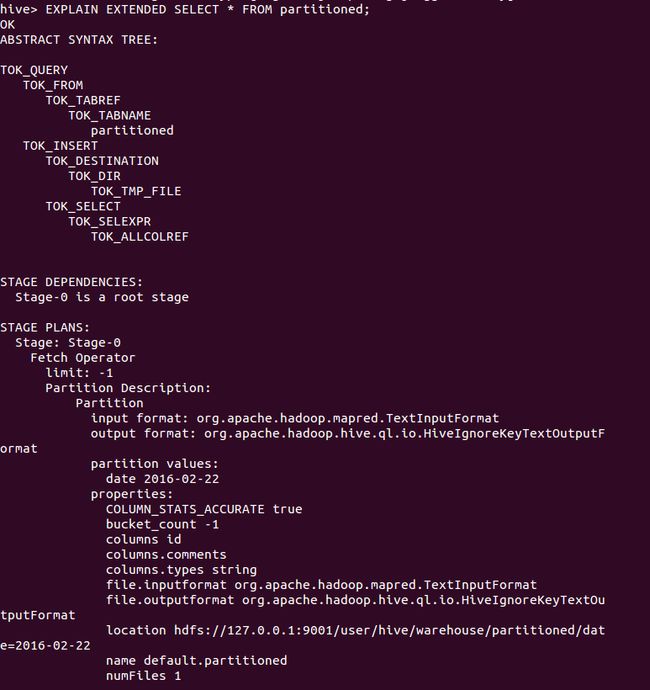
可以使用EXPLAIN前缀查看某条HiveQL查询语句的执行计划,使用EXPLAIN EXTENDED前缀查询更详细的执行计划。
比如执行如下语句,可得到如图5所示结果。
EXPLAIN SELECT * FROM partitioned;图5
又比如执行如下语句,可得到如图6所示结果(注意由于篇幅关系,图6只是部分截图)。
EXPLAIN EXTENDED SELECT * FROM partitioned;图6
6.2、DESCRIBE语句
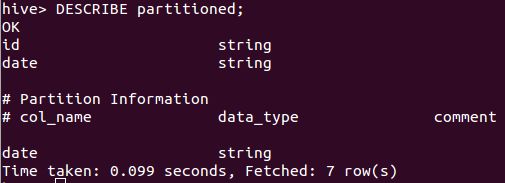
可以使用DESCRIBE前缀来查看Hive表的信息,使用DESCRIBE EXTENDED前缀查看更加详细的信息。
比如执行如下语句,可得到如图7所示结果。
DESCRIBE partitioned;图7
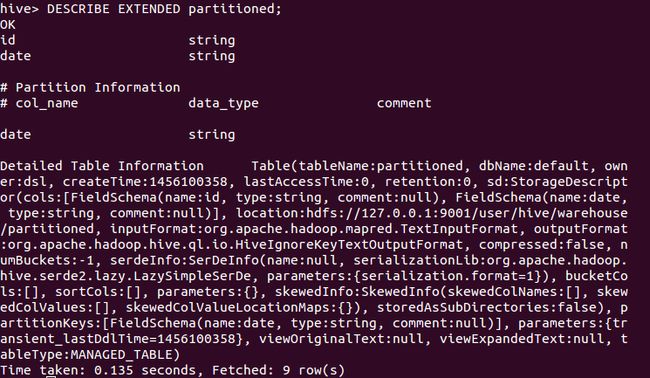
又比如执行如下语句,可得到如图8所示结果。
DESCRIBE EXTENDED partitioned;图8
参考文献:
[1]http://grisha.org/blog/2013/04/19/mapjoin-a-simple-way-to-speed-up-your-hive-queries/