Harris角点检测算法优化
Harris角点检测算法优化
一、综述
用 Harris 算法进行检测,有三点不足:
(1 )该算法不具有尺度不变性;
(2 )该算法提取的角点是像素级的;
(3 )该算法检测时间不是很令人满意。
基于以上认识,我们主要针对第(3)点对Harris 角点检测算法提出了改进。
二、改进 Harris 算法原理
在介绍方法之前,我们先提出如下概念:图像区域像素的相似度。
我们知道, Harris角点检测是基于图像像素灰度值变化梯度的, 灰度值图像的角点附近,是其像素灰度值变化非常大的区域,其梯度也非常大。
换句话说,在非角点位置邻域里,各点的像素值变化不大,甚至几乎相等,其梯度相对也比较小。从这个角度着眼,于是提出了图像区域像素的相似度的概念,它是指检测窗口中心点灰度值与其周围n 邻域内其他像素点灰度值的相似程度,这种相似程度是用其灰度值之差来描述的。如果邻域内点的灰度值与中心点Image (i,j) 的灰度值之差 的绝对值 在一个阈值t 范围 内,那就认为这个点与中心点是相似的。
与此同时,属于该Image (i,j) 点的相似点计数器nlike(i,j) 也随之加一。在Image (i,j) 点的n 邻域 全部被遍历一边之后,就能得到在这个邻域范围内 与中心点相似的 点个数的统计值nlike(i,j) 。根据nlike(i,j)的大小,就可以判断这个中心点是否可能为角点。
由于我们选择3*3 的检测窗口,所以,对于中心像素点 , 在下面的讨论中只考虑其8 邻域内像素点的相似度。计算该范围的像素点与中心像素点的灰度值之差的绝对值 ( 记为 Δ ) , 如果该值小于等于设定的阈值( 记为 t), 则认为该像素点与目标像素点相似 。
nlike( i , j ) = sum( R ( i+ x , j + y ) ) ,( - 1 ≤ x ≤ 1 , - 1 ≤ y≤ 1 , 且 x ≠ 0 , y ≠ 0),
其中 : 1 , Δ( i + x, j + y) ≤ t ,R(i+x, j+y)= 0 , Δ( i + x , j + y) > t
从定义中可以看出 : 0 ≤nlike ( i , j ) ≤ 8 。
现在讨论 nlike( i , j) 值的含义 :
(1)nlike (i , j) = 8 , 表示当前中心像素点的 8 邻域范围内都是与之相似的像素点 , 所以该像素点邻域范围内的梯度不会很大 , 因此角点检测时 , 应该排除此类像素点,不将其作为角点的候选点 。
(2)nlike (i , j) = 0 , 表示当前中心像素点的 8 邻域范围内没有与之相似的像素点 , 所以该像素点为孤立像素点或者是噪声点 , 因此角点检测时 , 也应该排除此类像素点 。
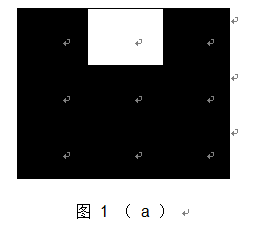
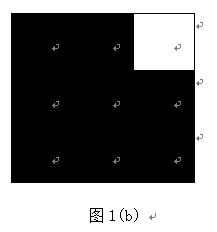
(3)nlike (i , j) = 7 , 可以归结为以下的两者情况 , 其他情形都可以通过旋转来得到( 图中黑色区域仅表示与中心像素相似 , 而两个黑色区域像素可能是相似的, 也可能不相似 ) 。 对于图 1 (a) 中 , 可能的角点应该是中心像素点的正上方的那个像素点 , 1(b) 图中可能的角点应该是中心像素点右上方的那个像素点 , 故这种情况下, 中心像素点不应该作为角点的候选点 。
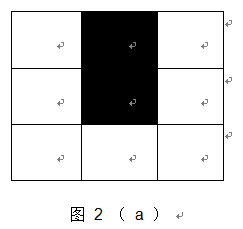
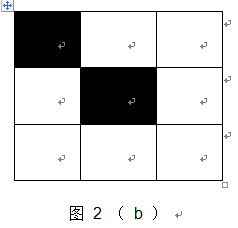
(4)nlike (i , j) = 1 ,可以归结为图2中的两种情况 ( 图中白色区域仅表示与中心像素不相似 , 而两个白色区域像素可能是相似的 , 也可能不相似 ) , 在这两种情况下 , 中心像素点也不可能为角点 。
(5) 2 ≤ nlike ( i , j) ≤ 6 , 情况比较复杂 , 无法确认像素点准确的性质。我们采取的方法是先将其列入候选角点之列,对其进行计算CRF 等后续操作。