深入new/malloc共同点与区别
共同点:
由于malloc和new都是在堆上分配的空间,无法自动释放,需要调用free/delete释放空间。malloc分配的空间用free释放,而new分配的空间用delete释放。
malloc()到底从哪里得到了内存空间?
答案是从堆里面获得空间。也就是说函数返回的指针是指向堆里面的一块内存。操作系统中有一个记录空闲内存地址的链表。
malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表。
1-调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块。
2-然后,将该内存块一分为二(一块的大小与用户请求的大小相等,另一块的大小就是剩下的字节)。
3-接下来,将分配给用户的那块内存传给用户,并将剩下的那块(如果有的话)返回到连接表上。
调用free函数时,它将用户释放的内存块连接到空闲链上。
4-到最后,空闲链会被切成很多的小内存片段,如果这时用户申请一个大的内存片段,那么空闲链上可能没有可以满足用户要求的片段了。于是,malloc函数请求延时,并开始在空闲链上翻箱倒柜地检查各内存片段,对它们进行整理,将相邻的小空闲块合并成较大的内存块。
申请的时候实际上占用的内存要比申请的大。因为超出的空间是用来记录对这块内存的管理信息 大多数实现所分配的存储空间比所要求的要稍大一些,额外的空间用来记录管理信息——分配块的长度,指向下一个分配块的指针等等。
例如:free的源代码:
struct mem_control_block {
int is_available; //这是一个标记
int size; //这是实际空间的大小
}
void free(void *ptr)
{
struct mem_control_block *free;
free = ptr - sizeof(struct mem_control_block);
free->is_available = 1;
return;
}
堆内存分配(引用自百度百科)
操作系统有一个记录空闲内存地址的链表;
1.当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,
然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
2.对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。
3.另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。堆内存是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。
4.堆内存的大小受限于计算机系统中有效的虚拟内存。由此可见,堆内存获得的空间比较灵活,也比较大。
堆内存是由new分配的内存,一般速度比较慢,而且容易产生内存碎片。
不同点:
同理delete会调用类的析构函数,free也不会调用析构函数
int *pi=new int;//pi 指向一个没有初始化的int
string *ps=new string( );//初始化为空字符串 (对于提供了默认构造函数的类类型,没有必要对其对象进行值初始化)
在delete之后,重设指针的值
delete p; //执行完该语句后,p变成了不确定的指针,在很多机器上,尽管p值没有明确定义,但仍然存放了它之前所指对象的地址,
然后p所指向的内存已经被释放了,所以p不再有效。此时,该指针变成了悬垂指针(悬垂指针指向曾经存放对象的内存,但该对象已经不存在了)。悬垂指针往往导致程序错误,而且很难检测出来。
一旦删除了指针所指的对象,立即将指针置为0,这样就非常清楚的指明指针不再指向任何对象。(零值指针:int *ip=0;)
这是因为C++程序经常要调用C函数,而C程序只能用malloc/free管理动态内存。
--------------------------------------------------------------------------------------------------------------------------------------------
扩充知识:《计算机操作系统》内存管理中的动态分区分配
连续分配方式:为一个用户程序分配一个连续的内存空间。
其中的动态分区分配:根据进程的实际需要,动态地为之分配内存空间。
1.分区分配中的数据结构:
空闲分区表;
空闲分区链
2.分区分配算法(从空闲分区表或空闲分区链中选出一分区分配)
1) 首次适应算法(first fit)
2) 循环首次适应算法
3) 最佳适应算法
4) 最坏适应算法
5) 快速适应算法(将空闲分区根据其容量大小进行分类,对于每一类具有
相同容量的所有空闲分区,单独设立一个空闲分区链表)
1) 分配内存
流程图如下:
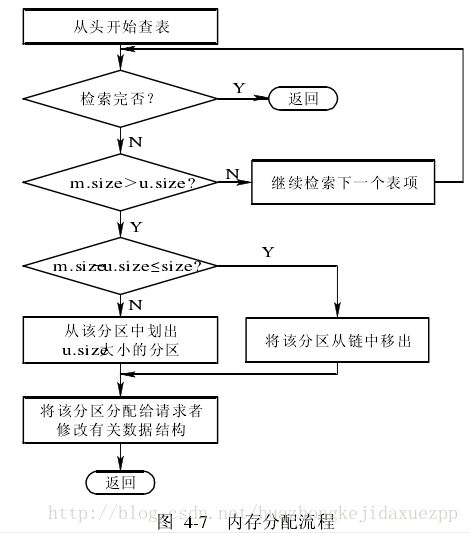
注意:将分配区的首址返回给调用者
2) 回收内存
4种情况:
(1) 回收区与插入点的前一个空闲分区F1相邻接;
(2) 回收分区与插入点的后一空闲分区F2相邻接;
(3) 回收区同时与插入点的前、后两个分区邻接;
(4) 回收区既不与 F1邻接,又不与 F2邻接
-------------------------------------------------------------------------------------------------------------------------
深入new 操作符(new operator)
原链接:http://www.cnblogs.com/xue-wen/archive/2009/11/07/1597983.html
{
int i;
public:
A(int _i) :i(_i*_i) {}
void Say() { printf("i=%dn", i); }
};
// 调用new:
A* pa = new A(3);
pa->A::A(3);
return pa;
{
public:
void* operator new(size_t size)
{
printf( "operator new calledn");
return ::operator new(size);
}
};
A* a = new A();
{
printf( "global newn");
return malloc(size);
}
{
void* p = null
while(!(p = malloc(size)))
{
if(null == new_handler)
throw bad_alloc();
try
{
new_handler();
}
catch(bad_alloc e)
{
throw e;
}
catch(…)
{}
}
return p;
}
{
printf(“New handler called!n”);
throw std::bad_alloc();
}
std::set_new_handler(MyNewHandler);
void main()
{
char s[sizeof(A)];
A* p = (A*)s;
new(p) A(3); //p->A::A(3);
p->Say();
}
1]这里“new(p) A(3)”这种奇怪的写法便是placement new了,它实现了在指定内存地址上用指定类型的构造函数来构造一个对象的功能,后面A(3)就是对构造函数的显式调用。注:指定的地址既可以是栈,又可以是堆,placement对此不加区分。
2】但是,除非特别必要,不要直接使用placement new ,这毕竟不是用来构造对象的正式写法,只不过是new operator的一个步骤而已。使用new operator地编译器会自动生成对placement new的调用的代码,因此也会相应的生成使用delete时调用析构函数的代码。如果是像上面那样在栈上使用了placement new,则必须手工调用析构函数,这也是显式调用析构函数的唯一情况:
inline void construct(T1* p, const T2& value)
{
new(p) T1(value);
}
inline void destory(T* pointer)
{
pointer->~T();
}
inline void destory(ForwardIterator first, ForwardIterator last)
{
__destory(first, last, value_type(first));
}
inline void __destory(ForwardIterator first, ForwardIterator last, T*)
{
typedef typename __type_traits<T>::has_trivial_destructor trivial_destructor;
__destory_aux(first, last, trivial_destructor());
}
// 如果需要调用析构函数:
template<class ForwardIterator>
inline void __destory_aux(ForwardIterator first, ForwardIterator last, __false_type)
{
for(; first < last; ++first)
destory(&*first); // 因first是迭代器,*first取出其真正内容,然后再用&取地址
}
//如果不需要,就什么也不做:
tempalte<class ForwardIterator>
inline void __destory_aux(ForwardIterator first, ForwardIterator last, __true_type)
{}
struct __false_type {};
template <class T>
struct __type_traits
{
public:
typedef __false _type has_trivial_destructor;
……
};
template<> // 模板特化
struct __type_traits<int> //int 的特化版本
{
public:
typedef __true_type has_trivial_destructor;
……
};
…… //其他简单类型的特化版本
struct __type_traits<MyClass>
{
public:
typedef __true_type has_trivial_destructor;
……
};
……
delete s;
释放内存时如何知道长度?
既然申请无需调用析构函数的类或简单类型的数组时并没有记录 个数信息,那么operator delete,或更直接的说free()是如何来回收这块内存的呢?这就要研究malloc()返回的内存的结构了。与new[]类似的是,实际上在 malloc()申请内存时也多申请了数个字节的内容,只不过这与所申请的变量的类型没有任何关系,我们从调用malloc时所传入的参数也可以理解这一 点——它只接收了要申请的内存的长度,并不关系这块内存用来保存什么类型。
当我们要分配一段内存时,所得的内存地址和上一次的尾地址至少要相距8个字节,这8个字节中的前两个字节记录了一次分配内存的长度信息,后面的六个字节可能与空闲内存链表的信息有关,在翻译内存时用来提供必要的信息。这就 解答了前面提出的问题,原来C/C++在分配内存时已经记录了足够充分的信息用于回收内存,