Apache-Hama框架简介–BSP模型的实现
Hama概况
Hama是基于BSP(BulkSynchronous Parallel)计算技术的并行计算框架,用于大量的科学计算(比如矩阵、图论、网络等)。BSP计算技术最大的优势是加快迭代,在解决最小路径等问题中可以快速得到可行解(http://wiki.apache.org/hama/Benchmarks)。同时,Hama提供简单的编程,比如flexible模型、传统的消息传递模型,而且兼容很多分布式文件系统,比如HDFS、Hbase等。用户可以使用现有的Hadoop集群进行Hama BSP.
现在Hama最新的版本为2012年6月31号发行的0.5.0.这是 Hama 做为 Apache 顶级项目后首次发布的版本,该版本包含两个显著的新特性,分别是消息压缩器和完整的 Google Pregel 克隆,另外在计算系统性能和可持续性上都得以提升。
Hama结构
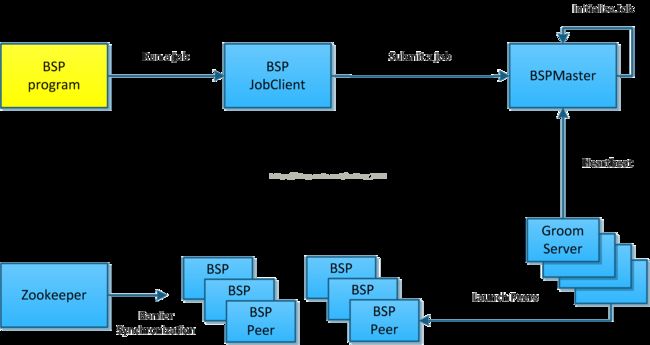
Hama主要有三部分构成:BSPMaster、GroomServers 和Zookeeper。与Hadoop结构很相似,但没有通信和同步机制的部分。
Hama的集群由一个BSPMaster和多个互不关联的GroomServer作计算结点组成,HDFS和Zookeeper都可以是独立的集群。启动从BSPMaster开始,如果是master会启动BSPMaster、GroomServer两个进程,如果只是计算结点则只会启动GroomServer,启动/关闭脚本都是Master机器远程在GroomServer机器上执行。
BSPMaster
BSPMaster 即集群的主,负责了集群各GroomServer结点的管理与作业的调度,就我所知它还存在单点的问题。相当于Hadoop的JobTracker或HDFS的NameNode。其基本作用如下:
1. 维持Groom服务器状态。
2. 维护supersteps和集群中的计数器。
3. 维护Job的进度信息。
4. 调度作业和任务分配给Groom服务器
5. 分配执行的类和配置,整个Groom服务器。
6. 为用户提供集群控制接口(Web和基于控制台)。
GroomServer
GroomServer是一个process,通过BSPMaster启动BSP任务。每一个Groom都有BSPMaster通信,可以通过BSPMaster获取任务,报告状态。GroomServer在HDFS或者其他文件系统上运行,通常,GroomServer与与数据结点在一个物理结点上运行,以保证获得最佳性能。
Zookeeper
Zookeeper用来管理BSPPeer的同步,用于实现BarrierSynchronisation机制。在ZK上,进入BSPPeer主要有进入Barrier和离开Barrier操作,所有进入Barrier的Peer会在zk上创建一个EPHEMERAL的node(/bsp/JobID/Superstep NO./TaskID),最后一个进入Barrier的Peer同时还会创建一个readynode(/bsp/JobID/Superstep NO./ready),Peer进入阻塞状态等待zk上所有task的node都删除后退出Barrier
BSPProgramming Model
BSP(BulkSynchronous Parallel,整体同步并行计算模型)是英国计算机科学家Viliant在上世纪80年代提出的一种并行计算模型。Google发布的一往篇论文(《Pregel: A System for Large-Scale Graph Processing》)使得这一概念被更多人所认识,据说在Google 80%的程序运行在MapReduce上,20%的程序运行在Pregel上。和MapReduce一样,Google并没有开源Pregel,Apache按Pregel的思想提供了类似框架Hama。
Hama BSP 是基于大容量同步并行模型,利用分布式节点计算大量步骤。通常,BSP程序包含一序列的superstep。每一个superstep包含三个步骤:
Local computation
Process communication
Barrier synchronization
Bulk Synchronous Parallel Model(http://en.wikipedia.org/wiki/Bulk_synchronous_parallel)
Hama提供用户自定义的函数bsf(),通过bsf函数,用户可以编写自己的BSP程序,并且BSP程序可以控制整个程序的并行部分,意味着bsf函数不仅仅是程序普通的一部分。在0.2版本中,完成BSF函数,仅仅需要达成通信接口协议,这样就可以获得更多的参数。
BSP是一种跟MapReduce平行的一种并行计算方法, 如果说MapReduce是把底层的数据传输和分配完全对用户屏蔽了的话, 那BSP就是一种要对底层的数据传输和分配进行手动编程规定的模式了. 这点上跟MPI(一种古老的并行模式)很像.
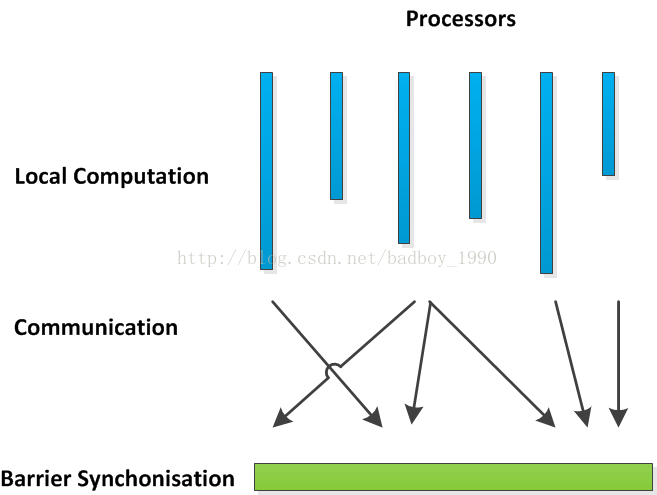
每个计算节点进行并行计算, 在communication的阶段进行收发, 将运行结果记录在barrier上, 等到所有计算节点运行到barrier,所有的计算节点在继续运行。通过这些原理可以理解为三个步骤:send, sync, receive.
Communication
在bsp函数中,用户可以使用communication函数通过使用BSPPeerProtocol完成多种操作,BSF通信标准库中会提供多种communication函数:
| Function |
Description |
| send(String peerName, BSPMessage msg) |
Sends a message to another peer |
| put(BSPMessage msg) |
Puts a message to local queue |
| getCurrentMessage() |
Returns a received message |
| getNumCurrentMessages() |
Returns the number of received messages |
| sync() |
Barrier synchronization |
| getPeerName() |
Returns a peer’s hostname |
| getAllPeerNames() |
Returns all peer’s hostname. |
| getSuperstepCount() |
Returns the count of supersteps |
图计算涉及到大量消息传递,Hama不完全是实时传送,消息的传输发生在Peer进入同步阶段后,并且对同一个目标GroomServer的消息进行了合并,两个物理结点之间每一次超步其实只会发生一次传输。
这些函数非常灵活,比如send函数可以给所有的peer发送消息,其代码如下:
|
@Override public void bsp( BSPPeer<NullWritable, NullWritable, Text, DoubleWritable, LongMessage> peer) throws IOException, SyncException, InterruptedException {
for (String peerName : peer.getAllPeerNames()) { peer.send(peerName, new LongMessage("Hello from " + peer.getPeerName(), System.currentTimeMillis())); }
peer.sync(); }
|
Synchronization
通过sync()函数可以将所有的进程进入barrier,Hama运行到下一个superstep,在上面send函数中,BSP发送消息给所有的peer,这一过程的结束是通过sync函数完成的。
@Override public void bsp( BSPPeer<NullWritable, NullWritable, Text, DoubleWritable, Writable> peer) throws IOException, SyncException, InterruptedException {
for (int i = 0; i < 100; i++) {
// send some messages peer.sync(); } }
|
用户将所有的进程关闭时,BSP工作将会结束。
Counters
跟Hadoop的MapReduce类似,用户可以使用Counter。
Counter的基本原理是用户可以增加枚举数量。在用户的程序中跟踪这个有意义的指标,这样的话就像一个循环,一直在执行。
下面的这段代码是来展示在BSP中Counter是如何执行的
// enum definition enum LoopCounter{
LOOPS } @Override public void bsp( BSPPeer<NullWritable, NullWritable, Text, DoubleWritable, DoubleWritable> peer) throws IOException, SyncException, InterruptedException {
for (int i = 0; i < iterations; i++) {
// details ommitted peer.getCounter(LoopCounter.LOOPS).increment(1L); } // rest ommitted }
|
Setup and Cleanup
在0.4.0版本之后,用户可以在BSP代码中完成Setup 和 Cleanup 方法,这些方法可以从BSP类中继承:
public class MyEstimator extends BSP<NullWritable, NullWritable, Text, DoubleWritable, DoubleWritable> {
@Override public void setup( BSPPeer<NullWritable, NullWritable, Text, DoubleWritable, DoubleWritable> peer) throws IOException {
//Setup: Choose one as a master this.masterTask = peer.getPeerName(peer.getNumPeers() / 2); } @Override public void cleanup( BSPPeer<NullWritable, NullWritable, Text, DoubleWritable, DoubleWritable> peer) throws IOException {
// your cleanup here } @Override public void bsp( BSPPeer<NullWritable, NullWritable, Text, DoubleWritable, DoubleWritable> peer) throws IOException, SyncException, InterruptedException {
// your computation here } }
|
Hama的应用情况
有许多应用和组织使用Apache的Hama,例如:
Korea Telecom
Hama is used fornetflow traffic analysis
NHN, corp.
Analysis ofsocial network data as a evaluation tool.
Oracle corporation
Social networkanalysis on 100 TB tweets dataset
2 Racks +InfiniBand network
University of the State of Mato Grosso andFaculty Campo Limpo Paulista
12microcomputers totaling 30 cores
Graphs with upto 65,000 vertices
Study of anexact solution to the problem of centrality in large graphs.
同时,Google和Wikipedia也使用了HamaGraphFile作为数据存储和处理。
从2002年开始,Google Web Graph已经包含了875,713个node和5,105,039个edge。
具体的数据集如下表:(http://snap.stanford.edu/data/web-Google.html)
| Dataset statistics |
|
| Nodes |
875713 |
| Edges |
5105039 |
| Nodes in largest WCC |
855802 (0.977) |
| Edges in largest WCC |
5066842 (0.993) |
| Nodes in largest SCC |
434818 (0.497) |
| Edges in largest SCC |
3419124 (0.670) |
| Average clustering coefficient |
0.6047 |
| Number of triangles |
13391903 |
| Fraction of closed triangles |
0.05523 |
| Diameter (longest shortest path) |
22 |
| 90-percentile effective diameter |
8.1 |
利用HamaGraphFile作为数据存储和处理的不仅仅是Google,Wikipedia同样利用HamaGraphFile进行页面之间(page-to-page link)数据存储、分析和处理。这可能是最成功的中间数据集的计算。但是,在SQL文件中所提供的格式相当不方便,其中有很多没有意义的链接,Wikipedia对其中的SQL文件做了优化处理。
下图展示的是Wikipedia利用Hama的GraphFile储存的数据量:
| Total # pages |
5,716,808 |
| Total # links |
130,160,392 |
| Max. # outlinks from a single page |
5,775 |
| Max. # inlinks to a single page |
374,934 |
| # pages with no outlinks |
10,438 |
| # pages with no inlinks |
1,942,943 |
引用:
Bulk Synchronous Parallel, http://en.wikipedia.org/wiki/Bulk_synchronous_parallel
Edward J. Yoon Apache Hama (v0.2) : UserGuide a BSP-based distributed computing framework
IEEE_CLOUDCOM2010_HAMA
Ben H H Juurlink;Harry A G WijshoffCommunication primitives for BSP computers 1996doi:10.1016/0020-0190(96)00073-7