机器学习:介绍及分类 (1)
自己归纳下最近在学的机器学习的知识,主要来源于在coursera上听的机器学习基石这门课,这门课是台湾大学的林轩田老师开的,侧重介绍了机器学习的原理,讲述了什么时候可以使用机器学习,为什么可以使用机器学习,机器可以怎么学习,怎么让机器学的更好,更侧重于理论和思想,学完这门课基本可以跟朋友们扯扯什么是机器学习了,哈哈
本篇博文主要介绍下什么是机器学习,还有常见的几种分类,还比较浅显,不涉及算法,算法的介绍的话等之后写的稍微多点再写吧。![]()
一、机器学习介绍
机器学习涉及的概念和学科特别多,主要是数学和计算机,通过计算机实现由数据推导而来的各种算法,目的就是让机器(计算机)模拟人类的学习行为,获得技能(skill),帮助进行预测和识别(如识别图像)。一般来说,人通过观察,学习,掌握一项技能。而机器则是通过数据,ML(Machine Learning,在计算机内部叫做演算法Algorithm),来掌握一项技能(多为预测、识别)。
人的学习基本是每时每刻的,我们的五感每时每刻都在接收着外界的信息,并把这些信息的特征提取出来进行识别,然后分类。就像一个你认识的人突然出现在你面前,你几乎就能马上识别出他是谁谁,这是因为我们的大脑在一瞬间对这个人提取了特征,例如:这是一个人→这是一个男人→这是一个短发的男人→他的脸是XXX,通过对这些特征的提取,使得我们能识别并进行分类。机器目前的识别还无法达到这么快速,不过已经能在某些领域得到很好的应用了,如自动驾驶,便是采用的神经网络,通过传感器传递路上的路标和周围的车辆情况,完成自动驾驶任务。
现在应用比较广泛的主要是人工智能,数据挖掘等。关于数据挖掘,还是有点小小的区别,机器学习的目的是通过学习获得某项技能,这项技能本来就是用来决策某些事情,而数据挖掘则是从历史数据中发现“有趣”的东西(KDD:knowledge discovery of dataset,知识发现),这项东西可以帮助人们进行更好的决策。
之所以需要机器学习的原因:
1、数据量庞大,且人无法获取
2、人的处理无法满足需求或者需要定义的规则太多。
关于第二点,举个通俗的例子。例如:一张图片,要判断这是不是一张含树的图片,如果要通过定义来让机器识别,恐怕要几百个定义还未必能让机器正确识别,所以就需要用到机器学习。设定一个初始值,让机器通过演算来最终获得这项识别的技能。
那要使用机器学习一般要满足什么条件?如下:
1、要有数据,没有数据学个蛋蛋。
2、数据要存在某种模式,这种模式可以通过学习来发现或提高。
3、这种规则比较难定义。
了解了机器学习的原理和使用条件,我们接下来介绍下机器学习的一般组成元素:
将各个部分抽象成如下的数学符号。以视频中提到的银行是否会发布信用卡给客户的案例来解释:
1.输入(input):x∈X(代表银行所掌握的用户信息)
2.输出(output):y∈Y (是否会发信用卡给用户)
3.未知的函数,即目标函数(targetfunction):f:X→Y(理想的信用卡发放公式)
4.数据或者叫做资料(data),即训练样本(training examples):D = {(x1,y1), (x2,y2 ),…, (xn,yn )}(银行的历史记录)
5.假设(hypothesis),即前面提到的技能,能够具有更好地表现:g:X→Y (能够学习到的公式)
可以通过一个简单的流程图表示,如图1-2所示。
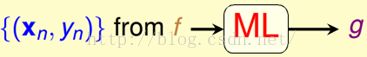
图1-2 机器学习的简单流程图
从图中可以清楚机器学习就是从我们未知但是却存在的一个规则或者公式f中得到大量的数据或者说资料(训练样本),在这些资料的基础上得到一个近似于未知规则g的过程。
这么说还是有点抽象,特别是目标函数f又是未知的,那为什么还能找到一个假设g能够接近f呢?
还是以一个更加详细的流程图来说明这一问题,如下图1-3。
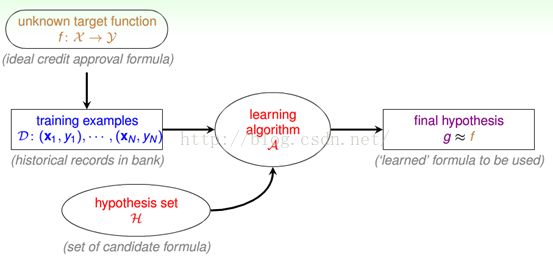
图1-3 详细的机器学习流程图
这个流程图和图1-2有些不同,其中ML被更详细的定义为机器学习算法(learningalgorithm)一般用A表示。还多出来一个新的项目,就是假设空间或者叫做假设集合(hypothesis set)一般用H表示,它是包含各种各样的假设,其中包括好的假设和坏的假设,而这时A的作用就体现了,它可以从H这个集合中挑选出它认为最好的假设作为g。
注:
1、这里还要说明的是机器学习的输入在这个流程图中就变成了两个部分,一个是训练样本集,而另一个就是假设空间H。
2、还有一点需要注意的是,我们所说的机器学习模型在这个流程图中也不仅仅是算法A,而且还包含了假设空间H。
3、给出了机器学习的一个更准确点的定义,就是通过数据来计算得到一个假设g使它接近未知目标函数f。
小结:以上主要介绍了
什么是机器学习
为什么要使用机器学习
具有什么条件时可以使用机器学习
机器学习主要有哪些元素
二、机器学习的分类
1、按照输出空间的不同来分类
①二元分类:输出y有+1和-1两种,二元分类问题主要包括:线性可分、线性不可分、多项式可分,如下:
二元分类问题是机器学习中很重要的一类问题,因为他可以衍生出多元分类的问题,所以这方面的算法研究特别多。
②多元分类:输出不止两种,如图像识别水果,可能有苹果,梨,香蕉等分类
③线性回归:输出为连续的实数范围,例如通过用户的数据来预测用户的年收入范围,年收入是一个连续的数值。
④逻辑(logistic)回归:输出为二元0/1,但实际是一个概率p,实质是以线性回归为基础衍生出的一种回归。例如仍以银行发布信用卡为例,二元分类给出的答案是发或不发,逻辑回归则给出对当下这种特征的用户,他有多大的概率会使用信用卡,然后我们决定是要给这样的用户发或不发信用卡。
⑤结构学习等
2、按学习方式分类
①监督式学习
监督式学习就是有输入数据X和真实数据Y,让机器不断试错,拟合,就是有题目跟正确答案,让机器不断向正确答案靠拢
②非监督式学习
非监督式学习常用于聚类或分群。他没有给定y,只能将所输入的数据按照某种学习到的规则来对其进行分类。如分硬币问题,不告诉你硬币总共有1毛,5毛,1元的输出y,而是让机器根据硬币的体积和质量来自动判断有几个类别。
PS:区分聚类和分类。分类的意思是已经给出了总共有多少类,让你根据类别进行划分,而聚类则是根据从数据间发现的某种规则分类,让同类间的相似性最大,不同类间的相似性最小。
③半监督式学习
输入数据集X中有少部分有标记的Y和绝大部分无标记,通过这种方式来学习。常用于标记代价特别昂贵的时候。
④强化学习
强化学习指对机器得出的结果给予good和bad的判断,通过这种方式来引导机器学习,有点类似于对宠物下命令,当宠物做出符合命令的动作时,就喂给他们食物作为奖励,一点点引导。
3、按照获取输入数据集的方式
①批量(batch)学习:将很多数据一次性喂给机器,最普遍的方式
②线上(online)学习:一点一点将数据喂给机器,如增强学习,属于引导式,越来越正确。
③主动(active)学习:通过提问题的方式来让算法解决,节省标记的时间。如字母识别,让机器抽出他还无法识别的字,问人这是’你’还是’您’,通过这种主动让机器提问题的方式来学习。
小结:以上主要介绍了几种常见的对机器学习种类的划分,不同的划分方式之间并不存在很明显的界限,如监督式学习,经常采用的就是批量学习式的方式,一次性喂给机器很多的资料让他去演算,而强化学习一般采用线上学习,一点一点的引导机器学习。
三、机器学习的输入数据集(data)分类
我们把一个具体x叫做一个实例,x上有很多维度分别来表示他的不同特征,或叫属性,如x1=(a1,a2,a3,a4)仍以银行是否发给用户信用卡为例,这里x可能代表一个指定的人,而其中的a1表示用户ID,a2表示是否有贷款,a3代表婚否,a4代表年收入
1、常用分类
①具体特征(concrete):我们一般使用的数据就是这类数据,具有某些具体可描述的有意义的数据,例如身高,体重等。
②原始特征:这类数据通常也需经过处理,一般像一张照片,他的像素点储存的信息我们就把他叫做原始数据。
③抽象特征:这类数据几乎不可用,如用户ID等,不具有特殊的意义,需要转化为具体特征才行。
2、
数据还可以进一步划分为分类型数据和数量型数据。
分类型数据(离散型)又可以从两个尺度来衡量,一个是名义尺度,一个是顺序尺度。名义尺度用来识别个体所属的类别,如水果里代表苹果、梨、香蕉的这一栏属性,他们的排列顺序没有意义;顺序尺度则表示数据的排列或等级意义明确,如评价一栏里的好、普通、差,按顺序呈现出了差别。此外,要注意的是,即使将苹果梨香蕉抽象成用数字1,2,3来表示,他仍然是名义尺度,他们的排列顺序没有意义。
②数量型数据(连续型),同样有两个衡量的尺度,间隔尺度和比率尺度。他们是从连续的角度来衡量的,所以他们始终是数值型数据。如学生的分数排列就可以划分为间隔尺度,而汽车的售价这种可以直接进行比较来得出XX车是X车的售价多少倍的尺度则是比较尺度,也就是说比较尺度比间隔尺度多了一个可以用倍数来表示的功能,而前面的学生分数则不行。(其实个人感觉这两个尺度区别不大,实际操作的时候一般也就直接叫数值型数据,不会刻意再细分这两个尺度)
四、机器学习几大算法
机器学习目前比较火的算法主要如下:

还有最近特别火的深度学习,基本上是多层神经网络的别名,这些算法我也是最近刚开始了解,还在学习中,目前看了Mitchell的<机器学习>,了解了几种常见算法的推导和应用范围,之后会针对每个算法总结一下!
以上内容主要来源于coursera的机器学习基石课程,同时还参考了杜少的博客和经济统计学的课本,要是有什么写的不对的,欢迎大家一起探讨哈~毕竟我还只是个初学者,共勉!
附杜少博客:
http://www.cnblogs.com/ymingjingr/p/4271742.html