OpenCV进阶之路:神经网络识别车牌字符
1. 关于OpenCV进阶之路
前段时间写过一些关于OpenCV基础知识方面的系列文章,主要内容是面向OpenCV初学者,介绍OpenCV中一些常用的函数的接口和调用方法,相关的内容在OpenCV的手册里都有更详细的解释,当时自己也是边学边写,权当为一种笔记的形式,所以难免有浅尝辄止的感觉,现在回头看来,很多地方描述上都存在不足,以后有时间,我会重新考虑每一篇文章,让成长系列对基础操作的介绍更加详细一些。
OpenCV进阶之路相比于成长系列,不会有太多的基础函数的介绍,相对来说会更偏向于工程实践,通过解决实际问题来说明某些较高级函数的用法和注意事项,主要内容会集中在特征提取、机器学习和目标跟踪几个方向。所以这个系列文章知识点没有先后顺序之分,根据个人平时工作学习中遇到的问题而定。
这篇文章主要介绍OpenCV中神经网络的用法,并通过车牌字符的识别来说明一些参数设置,函数调用顺序等,而关于神经网络的原理在博客机器学习分类里已经详细的讲解与实现了,所以本文中就不多加说明。
2. 车牌字符识别
车牌识别是计算机视觉在实际工程中一个非常成功的应用,虽然现在技术相对来说已经成熟,但是围绕着车牌定位、车牌二值化、车牌字符识别等方向,还是不时的有新的算法出现。通过学习车牌识别来提升自己在图像识别方面的工程经验是非常好的,因为它非常好的说明了计算机视觉的一般过程:
图像→预处理→图像分析→目标提取→目标识别
而整个车牌识别过程实际上相当于包含了两个上述过程:1,是车牌的识别;2,车牌字符的识别。
这篇文章其实主要是想介绍OpenCV中神经网络的用法,而不是介绍车牌识别技术。所以我们主要讨论的内容集中在车牌字符的识别上,关于定位、分割等不多加叙述叙述。
3. 字符特征提取
在深度学习(将特征提取作为训练的一部分)这个概念引入之前,一般在准备分类器进行识别之前都需要进行特征提取。因为一幅图像包含的内容太多,有些信息能区分差异性,而有些信息却代表了共性。所以我们要进行适当的特征提取把它们之间的差异性特征提取出来。
这里面我们计算二种简单的字符特征:梯度分布特征、灰度统计特征。这两个特征只是配合本篇文章来说明神经网络的普遍用法,实际中进行字符识别需要考虑的字符特征远远要比这复杂,还包括相似字特征的选取等,也由于工作上的原因,这一部分并不深入的介绍。
1,首先是梯度分布特征,该特征计算图像水平方向和竖直方向的梯度图像,然后通过给梯度图像分划不同的区域,进行梯度图像每个区域亮度值的统计,以下是算法步骤:
<1>将字符由RGB转化为灰度,然后将图像归一化到16*8。<2>定义soble水平检测算子:x_mask=[−1,0,1;−2,0,2;–1,0,1]和竖直方向梯度检测算子y_mask=x_maskT。<3>对图像分别用mask_x和mask_y进行图像滤波得到SobelX和SobelY,下图分别代表原图像、SobelX和SobelY。<4>对滤波后的图像,计算图像总的像素和,然后划分4*2的网络,计算每个网格内的像素值的总和。<5>将每个网络内总灰度值占整个图像的百分比统计在一起写入一个向量,将两个方向各自得到的向量并在一起,组成特征向量。void calcGradientFeat(const Mat& imgSrc, vector<float>& feat)
{
float sumMatValue(const Mat& image); // 计算图像中像素灰度值总和 Mat image;
cvtColor(imgSrc,image,CV_BGR2GRAY);
resize(image,image,Size(8,16)); // 计算x方向和y方向上的滤波
float mask[3][3] = { { 1, 2, 1 }, { 0, 0, 0 }, { -1, -2, -1 } }; Mat y_mask = Mat(3, 3, CV_32F, mask) / 8;
Mat x_mask = y_mask.t(); // 转置
Mat sobelX, sobelY; filter2D(image, sobelX, CV_32F, x_mask);
filter2D(image, sobelY, CV_32F, y_mask); sobelX = abs(sobelX);
sobelY = abs(sobelY); float totleValueX = sumMatValue(sobelX);
float totleValueY = sumMatValue(sobelY); // 将图像划分为4*2共8个格子,计算每个格子里灰度值总和的百分比
for (int i = 0; i < image.rows; i = i + 4)
{
for (int j = 0; j < image.cols; j = j + 4)
{
Mat subImageX = sobelX(Rect(j, i, 4, 4));
feat.push_back(sumMatValue(subImageX) / totleValueX);
Mat subImageY= sobelY(Rect(j, i, 4, 4));
feat.push_back(sumMatValue(subImageY) / totleValueY);
}
}
}
float sumMatValue(const Mat& image)
{
float sumValue = 0;
int r = image.rows;
int c = image.cols;
if (image.isContinuous())
{
c = r*c;
r = 1;
}
for (int i = 0; i < r; i++)
{
const uchar* linePtr = image.ptr<uchar>(i);
for (int j = 0; j < c; j++)
{
sumValue += linePtr[j];
}
}
return sumValue;
}2,第二个特征非常简单,只需要将图像归一化到特定的大小,然后将图像每个点的灰度值作为特征即可。
<1>将图像由RGB图像转换为灰度图像;
<2>将图像归一化大小为8×4,并将图像展开为一行,组成特征向量。
4. OpenCV中的神经网络
关于神经网络的原理我的博客里已经写了两篇文章,并且给出了C++的实现,所以这里我就不提了,下面主要说明在OpenCV中怎么使用它提供的库函数。
CvANN_MLP是OpenCV中提供的一个神经网络的类,正如它的名字一样(multi-layer perceptrons),它是一个多层感知网络,它有一个输入层,一个输出层以及1或多个隐藏层。
4.1. 首先我们来创建一个网络,我们可以利用CvANN_MLP的构造函数或者create函数。
CvANN_MLP::CvANN_MLP(const Mat& layerSizes, int activateFunc=CvANN_MLP::SIGMOID_SYM, double fparam1=0, double fparam2=0 );
void CvANN_MLP::create(const Mat& layerSizes, int activateFunc=CvANN_MLP::SIGMOID_SYM, double fparam1=0, double fparam2=0 );上面是分别是构造函数和cteate成员函数的接口,我们来分析各个形参的意思。
layerSizes:一个整型的数组,这里面用Mat存储。它是一个1*N的Mat,N代表神经网络的层数,第i列的值表示第i层的结点数。这里需要注意的是,在创建这个Mat时,一定要是整型的,uchar和float型都会报错。
比如我们要创建一个3层的神经网络,其中第一层结点数为x1,第二层结点数为x2,第三层结点数为x3,则layerSizes可以采用如下定义:
Mat layerSizes=(Mat_<int>(1,3)<<x1,x2,x3);或者用一个数组来初始化:
int ar[]={x1,x2,x3};
Mat layerSizes(1,3,CV_32S,ar);activateFunc:这个参数用于指定激活函数,不熟悉的可以去看我博客里的这篇文章《神经网络:感知器与梯度下降》,一般情况下我们用SIGMOID函数就可以了,当然你也可以选择正切函数或高斯函数作为激活函数。OpenCV里提供了三种激活函数,线性函数(CvANN_MLP::IDENTITY)、sigmoid函数(CvANN_MLP::SIGMOID_SYM)和高斯激活函数(CvANN_MLP::GAUSSIAN)。
后面两个参数则是SIGMOID激活函数中的两个参数α和β,默认情况下会都被设置为1。
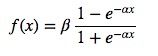
4.2. 设置神经网络训练参数
神经网络训练参数的类型存放在CvANN_MLP_TrainParams这个类里,它提供了一个默认的构造函数,我们可以直接调用,也可以一项一项去设。
CvANN_MLP_TrainParams::CvANN_MLP_TrainParams()
{
term_crit = cvTermCriteria( CV_TERMCRIT_ITER + CV_TERMCRIT_EPS, 1000, 0.01 );
train_method = RPROP;
bp_dw_scale = bp_moment_scale = 0.1;
rp_dw0 = 0.1; rp_dw_plus = 1.2; rp_dw_minus = 0.5;
rp_dw_min = FLT_EPSILON; rp_dw_max = 50.;
}它的参数大概包括以下几项。
term_crit:终止条件,它包括了两项,迭代次数(CV_TERMCRIT_ITER)和误差最小值(CV_TERMCRIT_EPS),一旦有一个达到条件就终止训练。
train_method:训练方法,OpenCV里提供了两个方法一个是很经典的反向传播算法BACKPROP,另一个是弹性反馈算法RPROP,对第二种训练方法,没有仔细去研究过,这里我们运用第一种方法。
剩下就是关于每种训练方法的相关参数,针对于反向传播法,主要是两个参数,一个是权值更新率bp_dw_scale和权值更新冲量bp_moment_scale。这两个量一般情况设置为0.1就行了;太小了网络收敛速度会很慢,太大了可能会让网络越过最小值点。
我们一般先运用它的默认构造函数,然后根据需要再修改相应的参数就可以了。如下面代码所示,我们将迭代次数改为了5000次。
CvANN_MLP_TRainParams param;
param.term_crit=cvTermCriteria(CV_TerMCrIT_ITER+CV_TERMCRIT_EPS,5000,0.01);4.3. 神经网络的训练
我们先看训练函数的接口,然后按接口去准备数据。
int CvANN_MLP::train(const Mat& inputs, const Mat& outputs, const Mat& sampleWeights, const Mat& sampleIdx=Mat(), CvANN_MLP_TrainParams params=CvANN_MLP_TrainParams(), int flags=0 );inputs:输入矩阵。它存储了所有训练样本的特征。假设所有样本总数为nSamples,而我们提取的特征维数为ndims,则inputs是一个nSamples∗ndims的矩阵,我们可以这样创建它。
Mat inputs(nSamples,ndims,CV_32FC1); //CV_32FC1说明它储存的数据是float型的。我们需要将我们的训练集,经过特征提取把得到的特征向量存储在inputs中,每个样本的特征占一行。
outputs:输出矩阵。我们实际在训练中,我们知道每个样本所属的种类,假设一共有nClass类。那么我们将outputs设置为一个nSample行nClass列的矩阵,每一行表示一个样本的预期输出结果,该样本所属的那类对应的列设置为1,其他都为0。比如我们需要识别0-9这10个数字,则总的类数为10类,那么样本数字“3”的预期输出为[0,0,1,0,0,0,0,0,0,0];
sampleWeights:一个在使用RPROP方法训练时才需要的数据,所以这里我们不设置,直接设置为Mat()即可。
sampleIdx:相当于一个遮罩,它指定哪些行的数据参与训练。如果设置为Mat(),则所有行都参与。
params:这个在刚才已经说过了,是训练相关的参数。
flag:它提供了3个可选项参数,用来指定数据处理的方式,我们可以用逻辑符号去组合它们。UPDATE_WEIGHTS指定用一定的算法去初始化权值矩阵而不是用随机的方法。NO_INPUT_SCALE和NO_OUTPUT_SCALE分别用于禁止输入与输出矩阵的归一化。
一切都准备好后,直接开始训练吧!
4.4. 识别
识别是通过Cv_ANN_MLP类提供的predict来实现的,知道原理的会明白,它实际上就是做了一次向前传播。
float CvANN_MLP::predict(const Mat& inputs, Mat& outputs) const