使用动态性能视图调优实例
可用监控实例的性能视图有下面这些
These dynamic performance views can be queried for wait event statistics:
-
V$ACTIVE_SESSION_HISTORYThe
V$ACTIVE_SESSION_HISTORYview displays active database session activity, sampled once every second. See"Active Session History (ASH)". -
V$SESS_TIME_MODELandV$SYS_TIME_MODELThe
V$SESS_TIME_MODELandV$SYS_TIME_MODELviews contain time model statistics, includingDBtimewhich is the total time spent in database calls -
V$SESSION_WAITThe
V$SESSION_WAITview displays the resources or events for which active sessions are waiting. -
V$SESSIONThe
V$SESSIONview contains the same wait statistics that are contained in theV$SESSION_WAITview. If applicable, this view also contains detailed information on the object that the session is currently waiting for (object number, block number, file number, and row number), plus the blocking session responsible for the current wait. -
V$SESSION_EVENTThe
V$SESSION_EVENTview provides summary of all the events the session has waited for since it started. -
V$SESSION_WAIT_CLASSThe
V$SESSION_WAIT_CLASSview provides the number of waits and the time spent in each class of wait events for each session. -
V$SESSION_WAIT_HISTORYThe
V$SESSION_WAIT_HISTORYview displays the last ten wait events for each active session. -
V$SYSTEM_EVENTThe
V$SYSTEM_EVENTview provides a summary of all the event waits on the instance since it started. -
V$EVENT_HISTOGRAMThe
V$EVENT_HISTOGRAMview displays a histogram of the number of waits, the maximum wait, and total wait time on an event basis. -
V$FILE_HISTOGRAMThe
V$FILE_HISTOGRAMview displays a histogram of times waited during single block reads for each file. -
V$SYSTEM_WAIT_CLASSThe
V$SYSTEM_WAIT_CLASSview provides the instance wide time totals for the number of waits and the time spent in each class of wait events. -
V$TEMP_HISTOGRAMThe
V$TEMP_HISTOGRAMview displays a histogram of times waited during single block reads for each temporary file.
10.1.3.4.1 V$ACTIVE_SESSION_HISTORY
This view displays active database session activity, sampled once every second. See"Active Session History (ASH)".
This contains overall statistics for many different parts of Oracle, including rollback, logical and physical I/O, and parse data. Data fromV$SYSSTAT is used to compute ratios, such as the buffer cache hit ratio.
This contains detailed file I/O statistics for each file, including the number of I/Os for each file and the average read time.
This contains detailed rollback and undo segment statistics for each segment.
This contains detailed enqueue statistics for each enqueue, including the number of times an enqueue was requested and the number of times an enqueue was waited for, and the wait time.
10.1.3.4.6 V$LATCH
This contains detailed latch usage statistics for each latch, including the number of times each latch was requested and the number of times the latch was waited for.
段级别的信息 对热表或索引收集段级别的信息是有帮助的。
You can query segment-level statistics through the following dynamic performance views:
-
V$SEGSTAT_NAMEThis view lists the segment statistics being collected, as well as the properties of each statistic (for instance, if it is a sampled statistic). -
V$SEGSTATThis is a highly efficient, real-time monitoring view that shows the statistic value, statistic name, and other basic information. -
V$SEGMENT_STATISTICSThis is a user-friendly view of statistic values. In addition to all the columns ofV$SEGSTAT, it has information about such things as the segment owner and table space name. It makes the statistics easy to understand, but it is more costly.
Load-related statistics to examine include redo size,sessionlogicalreads,db block changes, physical reads, physical read total bytes, physicalwrites,physical write total bytes, parsecount (total),parsecount (hard), andusercalls. This data is queried fromV$SYSSTAT.
等待事件与可能的原因列表
Table 10-1 Wait Events and Potential Causes
| Wait Event | General Area | Possible Causes | Look for / Examine |
|---|---|---|---|
|
|
Buffer cache, DBWR |
Depends on buffer type. For example, waits for an index block may be caused by a primary key that is based on an ascending sequence. |
Examine |
|
|
Buffer cache, DBWR, I/O |
Slow DBWR (possibly due to I/O?) Cache too small |
Examine write time using operating system statistics. Check buffer cache statistics for evidence of too small cache. |
|
|
I/O, SQL statement tuning |
Poorly tuned SQL Slow I/O system |
Investigate |
|
|
I/O, SQL statement tuning |
Poorly tuned SQL Slow I/O system |
Investigate |
|
|
Locks |
Depends on type of enqueue |
Look at |
|
|
Latch contention |
SQL parsing or sharing |
Check |
|
|
Log buffer, I/O |
Log buffer small Slow I/O system |
Check the statistic |
|
|
I/O, over- committing |
Slow disks that store the online logs Un-batched commits |
Check the disks that house the online redo logs for resource contention. Check the number of transactions ( |
v$sysstat视图中的redo log space request 暗示着服务器进程等待在线日志文件空间的事件 而不是redo log buffer 这个事件意味着检查点 dbwr 或archive 应该被调优 而不是lgwr 增加log buffer也是没有帮助的。
一致性读
为了维护一致性读你的系统可能花费大量时间来回滚块 查看V$SYSSTAT的数据来确定是否正在发生
consistent changes这个指明了有多少次的块回滚了。consistent gets这个是逻辑读的次数。
如果有很大的回滚段 那么系统在延迟块清除的情况下可能会花费很多的时间来回滚事务表来查找事务提交的scn。当oracle提交事务 所有的修改块不立即使用提交时的scn来更新块 这种情况下 块在下次被读取或是更新的时候被更新 这就叫延迟块更新。
The ratio of the following V$SYSSTAT statistics should be close to 1:
ratio = transaction tables consistent reads - undo records applied /
transaction tables consistent read rollbacks
如果没有足够的回滚段 在回滚段头或块就有竞争 检查下面2个方面
-
Comparing the number of
WAITSto the number ofGETSinV$ROLLSTAT; the proportion ofWAITStoGETSshould be small. -
Examining
V$WAITSTATto see whether there are manyWAITSfor buffers ofCLASS'undoheader'.
你可以通过检查V$SYSSTAT的table fetch continued row来检测迁移或链接的行数。如果一个update语句增大了行,使得行不能再数据块中存放下,那么oracle试着找别的块来放整行,如果有这样的块,oracle就把整行迁移过去,这叫做行迁移,如果行太大了不能再任意额一个块中放下,那么oracle就把行分裂成多块并且存放这些块到不同的数据块中,这叫做行链接,当行被插入的时候,可能发生行链接。
行链接与行迁移有下面的害处:
1update语句引起的迁移与链接使性能变差
2查询迁移和链接的行变差因为有了额外的输入输出
增大pctfree可以避免行迁移,也可以重新组织创建表和索引对那些有高删除率的表来说。
解析相关的数据
如果parse time cpu占cpu时间的很大部分,那么时间都用来解析而不是执行了。查看下面的值
SELECT NAME, VALUE FROM V$SYSSTAT WHERE NAME IN ( 'parse time cpu', 'parse time elapsed', 'parse count (hard)', 'CPU used by this session' );
有几个比率可以确定解析是否是一个问题:
parse time CPU / parse time elapsed
This ratio indicates how much of the time spent parsing was due to the parse operation itself, rather than waiting for resources, such as latches. A ratio of one is good, indicating that the elapsed time was not spent waiting for highly contended resources.
parse time CPU / CPU used by this session
This ratio indicates how much of the total CPU used by Oracle server processes was spent on parse-related operations. A ratio closer to zero is good, indicating that the majority of CPU is not spent on parsing
等待事件信息
The following views contain related, but different, views of the same data:
-
V$SESSIONlists session information for each current session. It lists either the event currently being waited for or the event last waited for on each session. This view also contains information on blocking sessions. -
V$SESSION_WAITis a current state view. It lists either the event currently being waited for or the event last waited for on each session -
V$SESSION_EVENTlists the cumulative history of events waited for on each session. After a session exits, the wait event statistics for that session are removed from this view. -
V$SYSTEM_EVENTlists the events and times waited for by the whole instance (that is, all session wait events data rolled up) since instance startup.
Because V$SESSION_WAIT is a current state view, it also contains a finer-granularity of information thanV$SESSION_EVENT orV$SYSTEM_EVENT. It includes additional identifying data for the current event in three parameter columns:P1,P2, and P3.
v$session_event与v$session_wait的区别,v$session_event可能显示等待事件db file scattered read,但是无法显示哪个文件和块号,然而,v$session_wait 中p1显示文件号,p2显示块号,p3显示行。
sql*net 事件
下面的时间暗示着数据库进程正在等待database link或是客户端的确认
SQL*Net break/reset to client
SQL*Net break/reset to dblink
SQL*Net message from client
SQL*Net message from dblink
SQL*Net message to client
SQL*Net message to dblink
SQL*Net more data from client
SQL*Net more data from dblink
SQL*Net more data to client
SQL*Net more data to dblink
如果这些等待构成了等待时间的大部分,或是用户响应时间有问题,那么网络或是中间层可能出问题了。
SQL*Net message from client
这个等待事件是个空闲事件,但是在诊断什么不是问题的时候却很重要。这个事件意味着服务进程正在等待客户进程。有几个情况可能是用户响应时间差的原因,一个可能是网络问题,一个可能是客户端进程资源有瓶颈。
网络有问题的症状如下:
1大量该等待事件
2数据库和客户端的处理器都很空闲。
解决方法:
1调优程序减少往返次数
2减少网络延迟
客户端资源瓶颈的症状
1等待事件的个数不是很多,但是等待事件很高
2客户端进程有很高的资源使用
buffter busy waits
这个事件就是在buffer cache中的buffer,有很多的进程试着去同时访问,查看v$session_wait:
P1 - File ID
P2 - Block ID
P3 - Class ID
如何分析这个等待事件
1SELECT row_wait_obj# FROM V$SESSION WHERE EVENT = 'buffer busy waits';找到这个对象
2SELECT owner, object_name, subobject_name, object_type FROM DBA_OBJECTS WHERE data_object_id =&row_wait_obj;
要是段头的争用,那么很可能是自由列表的争用。在本地管理表空间中的自动段空间管理中排出了指定PCTUSED, FREELISTS, andFREELISTGROUPS参数的需要,如果可以,转换手工空间管理到自动段空间管理。如果无法转换成自动段空间管理,那么下面的信息有帮助。
一个自由列表是空闲块的列表,通常包含一个段中不同extents的块。自由列表中的块都是没有达到pctree或使用空间在pctused下的块。使用freelists指定自由列表的数量。通过下面的查询来查看具体段的设置:
SELECT SEGMENT_NAME, FREELISTS FROM DBA_SEGMENTS WHERE SEGMENT_NAME = segment name AND SEGMENT_TYPE = segment type;
增加自由列表的数量,如果还不能解决问题就使用自由列表组,在rac中,确保每个实例有自己的列表组。
如果争用是数据块的争用
1检查 right-hand索引,这些索引被很多进程同时插入,例如用sequence来生成键值的。
2考虑使用assm,全局hash分区索引,或是增加自由链表。
如果争用是undo块头
如果没有使用自动undo管理,那么就增加更多的回滚段
如果是undo块争用
如果没有使用自动回滚段管理,那么考虑使回滚段尺寸更大些。
db file scattered read
这个等待事件是在读buffer到sga buffer cache中并等待物理io调用,一个db file scattered read指明了一个离散读,读取数据到多个不连续的内存位置中,一个离散读通常是多块读。可能发生在快速全索引或全表扫描上。这个等待事件暗示着全扫描正在发生,当全扫描到buffer cache中,读到内存中的位置不是物理上连续的,因为blocks在内存中是离散的,所以这个读取叫离散读。
Check the following V$SESSION_WAIT parameter columns:
-
P1- The absolute file number -
P2- The block being read -
P3- The number of blocks (should be greater than 1)
在一个健康的系统中,物理读取应该是空闲等待之后最大的等待,处理大量io等待有下面的几个方面可以调整:
1通过调整sql来减少io活动
2通过管理负载减少io需求
3收集系统统计信息,让优化器在使用全扫描时候获取准确的消耗
4使用自动存储管理asm
5增加更多的磁盘来减少每个盘的io
6在现存的磁盘上通过重新分配io减轻热点。
db file sequential read
顺序读是单块读,单块io通常是使用索引。
Check the following V$SESSION_WAIT parameter columns:
-
P1- The absolute file number -
P2- The block being read -
P3- The number of blocks (should be 1)
几种读取的区别
db file sequential read (single block read into one SGA buffer)
db file scattered read (multiblock read into many discontinuous SGA buffers)
direct read (single or multiblock read into the PGA, bypassing the SGA)
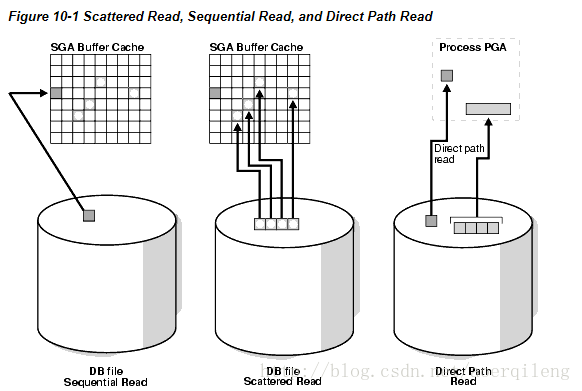
direct path read and direct path read temp
当一个会话读取buffer直接到pga中,出现该等待事件
Check the following V$SESSION_WAIT parameter columns:
-
P1- File_id for the read call -
P2- Start block_id for the read call -
P3- Number of blocks in the read call
Check the following V$SESSION_WAIT parameter columns:
-
P1- File_id for the read call -
P2- Start block_id for the read call -
P3- Number of blocks in the read call
下面的几个情况可能会发生该等待事件
1并行被使用
2排序太大了在内存中放不下,一些排序的数据直接写到磁盘上,然后使用直接读又读回来了。
3The server process is processing buffers faster than the I/O system can return the buffers. This can indicate an overloaded I/O system
排序到磁盘
查看v$tempseg_usage来找到生成排序的sql语句,同时查看v$segstat来看排序的大小,看是否能通过sql调优减少排序,如果workarea_size_policy是manual那么增加sort_area_size大小,要是workarea_size_policy是auto,那么增加pga_aggregate_target大小。
hash area size
对于使用hash join的查询计划,如果hash_area_size太小,那么大量的io可能会发生,如果workarea_size_policy是manual那么增加hash_area_size大小,如果workarea_size_policy是auto,那么增加pga_aggregate_target大小。
direct path write and direct path write temp
Check the following V$SESSION_WAIT parameter columns:
-
P1- File_id for the write call -
P2- Start block_id for the write call -
P3- Number of blocks in the write call
This happens in the following situations:
-
Sorts are too large to fit in memory and are written to disk
-
Parallel DML are issued to create/populate objects
-
Direct path loads
For parallel DML, check the I/O distribution across disks and make sure that the I/O subsystem is adequately configured for the degree of parallelism.
enqueue (enq:) waits
队列是锁协调访问数据库资源,这个事件意味着会话正在等待被别的会话持有的锁,命名如下:enq: enqueue_type-related_details,
enq: TX - allocate ITLentry
enq: TX - contention
enq: TX - index contention
enq: TX - row lockcontention
You can check the following V$SESSION_WAIT parameter columns for additional information:
-
P1- LockTYPE(or name) andMODE -
P2- Resource identifier ID1 for the lock -
P3- Resource identifier ID2 for the lock
查看锁和锁持有者
If there are enqueue waits, you can see these using the following statement:
SELECT * FROM V$LOCK WHERE request > 0;
To show only holders and waiters for locks being waited on, use the following:
SELECT DECODE(request,0,'Holder: ','Waiter: ') ||
sid sess, id1, id2, lmode, request, type
FROM V$LOCK
WHERE (id1, id2, type) IN (SELECT id1, id2, type FROM V$LOCK WHERE request > 0)
ORDER BY id1, request;
HW enqueue
The HW enqueue is used to serialize the allocation of space beyond the high water mark of a segment.
-
V$SESSION_WAIT.P2/V$LOCK.ID1is the tablespace number. -
V$SESSION_WAIT.P3/V$LOCK.ID2is the relative dba of segment header of the object for which space is being allocated.
If this is a point of contention for an object, then manual allocation of extents solves the problem.
TX enqueue
These are acquired exclusive when a transaction initiates its first change and held until the transaction does aCOMMIT orROLLBACK.
-
Waits for TX in mode 6: occurs when a session is waiting for a row level lock that is already held by another session. This occurs when one user is updating or deleting a row, which another session wishes to update or delete. This type of TX enqueue wait corresponds to the wait event
enq:TX-rowlockcontention.The solution is to have the first session already holding the lock perform a
COMMITorROLLBACK. -
Waits for TX in mode 4 can occur if the session is waiting for an ITL (interested transaction list) slot in a block. This happens when the session wants to lock a row in the block but one or more other sessions have rows locked in the same block, and there is no free ITL slot in the block. Usually, Oracle dynamically adds another ITL slot. This may not be possible if there is insufficient free space in the block to add an ITL. If so, the session waits for a slot with a TX enqueue in mode 4. This type of TX enqueue wait corresponds to the wait event
enq:TX-allocateITLentry.The solution is to increase the number of ITLs available, either by changing the
INITRANSorMAXTRANSfor the table (either by using anALTERstatement, or by re-creating the table with the higher values). -
Waits for TX in mode 4 can also occur if a session is waiting due to potential duplicates in
UNIQUEindex. If two sessions try to insert the same key value the second session has to wait to see if anORA-0001should be raised or not. This type of TX enqueue wait corresponds to the wait eventenq:TX-rowlockcontention.The solution is to have the first session already holding the lock perform a
COMMITorROLLBACK. -
Waits for TX in mode 4 is also possible if the session is waiting due to shared bitmap index fragment. Bitmap indexes index key values and a range of ROWIDs. Each 'entry' in a bitmap index can cover many rows in the actual table. If two sessions want to update rows covered by the same bitmap index fragment, then the second session waits for the first transaction to either
COMMITorROLLBACKby waiting for the TX lock in mode 4. This type of TX enqueue wait corresponds to the wait eventenq:TX-rowlockcontention. -
Waits for TX in Mode 4 can also occur waiting for a
PREPAREDtransaction. -
Waits for TX in mode 4 also occur when a transaction inserting a row in an index has to wait for the end of an index block split being done by another transaction. This type of TX enqueue wait corresponds to the wait event
enq:TX-indexcontention.
free buffer waits
这个等待事件意味着服务器进程不能找到一个空闲的buffer。原因:
DBWR may not be keeping up with writing dirty buffers in the following situations:
-
The I/O system is slow.
-
There are resources it is waiting for, such as latches.
-
The buffer cache is so small that DBWR spends most of its time cleaning out buffers for server processes.
-
The buffer cache is so big that one DBWR process is not enough to free enough buffers in the cache to satisfy requests.
DB_WRITER_PROCESSES
The DB_WRITER_PROCESSES initialization parameter lets you configure multiple database writer processes (from DBW0 to DBW9 and from DBWa to DBWj). Configuring multiple DBWR processes distributes the work required to identify buffers to be written, and it also distributes the I/O load over these processes. Multiple db writer processes are highly recommended for systems with multiple CPUs (at least one db writer for every 8 CPUs) or multiple processor groups (at least as many db writers as processor groups).
Based upon the number of CPUs and the number of processor groups, Oracle either selects an appropriate default setting forDB_WRITER_PROCESSES or adjusts a user-specified setting.
DBWR_IO_SLAVES
If it is not practical to use multiple DBWR processes, then Oracle provides a facility whereby the I/O load can be distributed over multiple slave processes. The DBWR process is the only process that scans the buffer cache LRU list for blocks to be written out. However, the I/O for those blocks is performed by the I/O slaves. The number of I/O slaves is determined by the parameterDBWR_IO_SLAVES.
DBWR_IO_SLAVES is intended for scenarios where you cannot use multipleDB_WRITER_PROCESSES (for example, where you have a single CPU). I/O slaves are also useful when asynchronous I/O is not available, because the multiple I/O slaves simulate nonblocking, asynchronous requests by freeing DBWR to continue identifying blocks in the cache to be written. Asynchronous I/O at the operating system level, if you have it, is generally preferred.
DBWR I/O slaves are allocated immediately following database open when the first I/O request is made. The DBWR continues to perform all of the DBWR-related work, apart from performing I/O. I/O slaves simply perform the I/O on behalf of DBWR. The writing of the batch is parallelized between the I/O slaves.
Choosing Between Multiple DBWR Processes and I/O Slaves
Configuring multiple DBWR processes benefits performance when a single DBWR process is unable to keep up with the required workload. However, before configuring multiple DBWR processes, check whether asynchronous I/O is available and configured on the system. If the system supports asynchronous I/O but it is not currently used, then enable asynchronous I/O to see if this alleviates the problem. If the system does not support asynchronous I/O, or if asynchronous I/O is already configured and there is still a DBWR bottleneck, then configure multiple DBWR processe
Using multiple DBWRs parallelizes the gathering and writing of buffers. Therefore, multiple DBWn processes should deliver more throughput than one DBWR process with the same number of I/O slaves. For this reason, the use of I/O slaves has been deprecated in favor of multiple DBWR processes. I/O slaves should only be used if multiple DBWR processes cannot be configured.
latch 等待事件
latch是一个低级别的内部锁,用来保护内存结构。
Check the following V$SESSION_WAIT parameter columns:
-
P1- Address of the latch -
P2- Latch number -
P3- Number of times process has already slept, waiting for the latch
Find Latches Currently Waited For
SELECT EVENT, SUM(P3) SLEEPS, SUM(SECONDS_IN_WAIT) SECONDS_IN_WAIT FROM V$SESSION_WAIT WHERE EVENT LIKE 'latch%' GROUP BY EVENT;
The following query provides more information about long duration instance tuning, showing whether the latch waits are significant in the overall database time.
SELECT EVENT, TIME_WAITED_MICRO,
ROUND(TIME_WAITED_MICRO*100/S.DBTIME,1) PCT_DB_TIME
FROM V$SYSTEM_EVENT,
(SELECT VALUE DBTIME FROM V$SYS_TIME_MODEL WHERE STAT_NAME = 'DB time') S
WHERE EVENT LIKE 'latch%'
ORDER BY PCT_DB_TIME ASC;
A more general query that is not specific to latch waits is the following:
SELECT EVENT, WAIT_CLASS,
TIME_WAITED_MICRO,ROUND(TIME_WAITED_MICRO*100/S.DBTIME,1) PCT_DB_TIME
FROM V$SYSTEM_EVENT E, V$EVENT_NAME N,
(SELECT VALUE DBTIME FROM V$SYS_TIME_MODEL WHERE STAT_NAME = 'DB time') S
WHERE E.EVENT_ID = N.EVENT_ID
AND N.WAIT_CLASS NOT IN ('Idle', 'System I/O')
ORDER BY PCT_DB_TIME ASC;
Table 10-2 Latch Wait Event
| Latch | SGA Area | Possible Causes | Look For: |
|---|---|---|---|
| Shared pool, library cache | Shared pool | Lack of statement reuse Statements not using bind variables Insufficient size of application cursor cache Cursors closed explicitly after each execution Frequent logon/logoffs Underlying object structure being modified (for example truncate) Shared pool too small |
Sessions (in V$SESSTAT) with high:
Cursors (in
|
| cache buffers lru chain | Buffer cache LRU lists | Excessive buffer cache throughput. For example, inefficient SQL that accesses incorrect indexes iteratively (large index range scans) or many full table scans DBWR not keeping up with the dirty workload; hence, foreground process spends longer holding the latch looking for a free buffer Cache may be too small |
Statements with very high logical I/O or physical I/O, using unselective indexes |
| cache buffers chains | Buffer cache buffers | Repeated access to a block (or small number of blocks), known as a hot block | Sequence number generation code that updates a row in a table to generate the number, rather than using a sequence number generator Index leaf chasing from very many processes scanning the same unselective index with very similar predicate Identify the segment the hot block belongs to |
| row cache objects |
SELECT OBJ data_object_id, FILE#, DBABLK,CLASS, STATE, TCH FROM X$BH WHERE HLADDR = 'address of latch' ORDER BY TCH;library cache pin