mysql大数据量分页场景的查询优化
本文主要实测验证如何在不分表不使用程序并发的方式尽可能提升大数据量分页的应用场景。
预测条件:
数据量:400w
字 段:id 主索引,title、create_at 普通索引
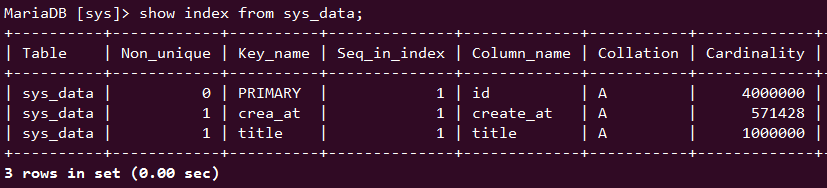
通过 Cardinality 我们也能想出要尽量使用哪个索引,id 索引势 是 title 索引势的4倍,也就说 title 索引的检索能力只有 25 %, id 1 vs 1,title 这里 1 vs 25
1、先来清理下 order by 的一些小要点
网上有不少博文都写着 order by 会启用索引 这么一个观点,其实这个观点并不是在所有场景下都适用的。当数据量比较小的时候,万级,此时 order by 会启用索引,这也是有时你使用 limit 做辅助检索也会帮助 order by 启用索引的原因。但当数据量达到十万,百万,千万级别时,此时 order by 就不会启用索引了。
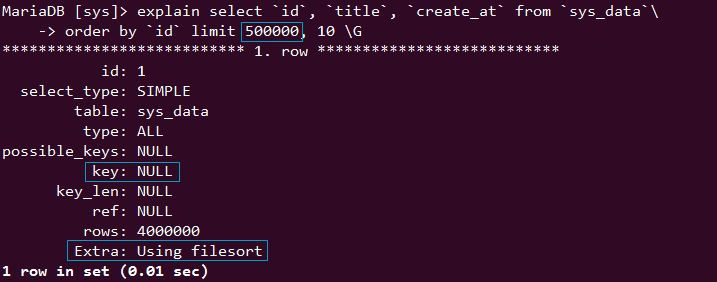
select `id`, `title`, `create_at` from `sys_data` order by `id` limit 500000, 10;
上面这种查询方式,数据量一大 order by 就不使用索引了
5w 使用 索引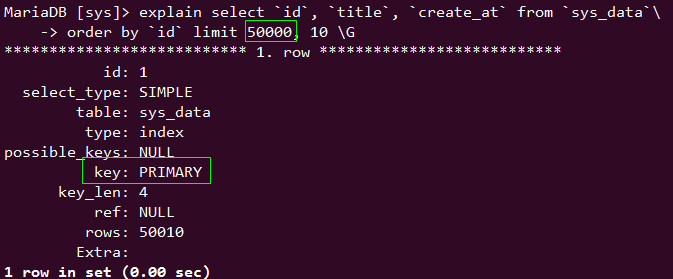
50w 索引失效了
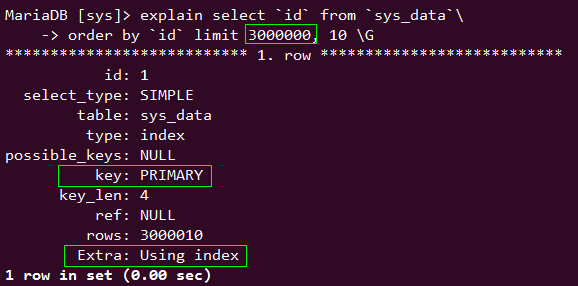
order by 在什么情况下才会一定使用索引呢,这个其实是有一个很确切的场景的
select `id` from `sys_data` order by `id` limit 3000000, 10;
当 select 的列与 order by 完全对应时,order by 会一直使用索引。虽然可能会因为数据量比较大检索起来稍微有些慢,但比不使用索引快多了。
300w select 字段 与 order by 字段一致
所以,如果乱用 order by,很可能会让你步入 Using filesort 的深渊....
2、优化建议
首先,我们要明确,使用 Cardinality 比较高的索引有助于我们快速检索,像 primary key 这种索引定位查询的时间复杂度是O(1),指哪查哪。即是用来做 range 范围检索也要快的多
网上比较流行的优化方式如下
//升序
select * from sys_data where id > (select id from sys_data order by id limit 500000, 1) limit 10;
//降序
select * from sys_data where id < (select id from sys_data order by id desc limit 500000, 1) limit 10;
通过子查询启用 id 索引检索出第 50 w 条数据的 id,然后取后面或前面的 10 条
这样就能实现高效的分页场景,比 'select id from sys_data order by id desc limit 500000, 1' 这种方式效率提高十几倍
其实也可以这样子
先通过
select id from sys_data order by id limit 500000, 10;
检索出所有符合条件的 id,然后将id组装成 in 模式,二次查询
select * from sys_data where id in(5000001, 5000002, 5000003, 5000004, .....5000010);
这种方式比较容易在业务层实现,方便控制和筛选
代码是这样写的
example_1是我自己写的in二次查询
example_2是网上流行的方法
example_3则是网上流传的错误知识点的方法 当 select 字段与 order by 字段不吻合时 order by 只有在少量数据下才会启用索引,否则无效,大家看结果吧
<?php
/**
* mysql 大数据量分页优化
* @author sallency@osc 2016-5-11 16:48:44
*/
$conn = new mysqli('localhost', 'root', '123456', 'sys');
/**
* 400w数据分页优化
*/
/**
* 自己在业务层做写的
* 先通过 order by 索引的特性将符合条件的 id 检索出来
* 再次拼接成 in 条件进行检索 链接没断掉 虽然二次查询但不消耗再次建立链接的资源
* 但遗憾的是你不能把它写成一条语句去执行 mysql 无法优化成我们想要的执行逻辑
*/
$sql = "select sql_no_cache id from sys_data order by id limit 3000020, 10";
$start = microtime(true);
$result = $conn->query($sql);
$id_arr = array_column($result->fetch_all(), 0);
$id_set_str = implode(',', $id_arr);
$sql = "select * from sys_data where id in($id_set_str)";
$result = $conn->query($sql);
$data_1 = $result->fetch_all();
$end = microtime(true);
echo "example_1:";
echo number_format($end - $start, 3) . ' secs' . PHP_EOL;
/**
* 业界流传的经典方法
* 通过子查询查处符合条件的 id,取偏移量获得记录
*/
$sql = "select sql_no_cache * from sys_data where id > (select id from sys_data order by id limit 3000020, 1) limit 10";
$start = microtime(true);
$result = $conn->query($sql);
$data_2 = $result->fetch_all();
$end = microtime(true);
echo "example_2:";
echo number_format($end - $start, 3) . ' secs' . PHP_EOL;
/**
* 普通方法
* 此类方法针对对数据量比较小的时候还可以应对
* 数据量十万时可能order by 就无法启用索引了 具体我也没测
*/
$sql = "select sql_no_cache * from sys_data order by id limit 3000020, 10";
$start = microtime(true);
$result = $conn->query($sql);
$data_3 = $result->fetch_all();
$end = microtime(true);
echo "example_3:";
echo number_format($end - $start, 3) . ' secs' . PHP_EOL;
然后我惊喜的发现我自己的方式比业界流行的还要快一些
limit 500, 10 在数据量比较小的时候最基本的方法效率反而更高一些
example_1:0.006 secs
example_2:0.015 secs
example_3:0.003 secs
limit 5000, 10 我突然发现我的方法比网上的还好一些 哈哈
example_1:0.004 secs
example_2:0.008 secs
example_3:0.013 secs
limit 50000,10 5w 我的方法依然雄壮
example_1:0.029 secs
example_2:0.042 secs
example_3:0.109 secs
limit 500000,10 50w 差距一目了然了
example_1:0.286 secs
example_2:0.346 secs
example_3:4.563 secs
limit 3000000, 10 300w 原始方法已经无法忍受了
300w 第一次
example_1:1.356 secs
example_2:1.936 secs
example_3:6.097 secs
300w 第二次
example_1:1.013 secs
example_2:1.534 secs
example_3:6.306 secs
300w 第三次
example_1:1.248 secs
example_2:1.924 secs
example_3:5.769 secs
300w 第四次
example_1:0.782 secs
example_2:1.582 secs
example_3:5.324 secs
我自己写的方法可能有些麻烦,分两步,但性能还是可以的,对比业界流行的方法或者普通的乱用方法显而易见,但比较蛋疼的是你不能把子查询写到 in 里面去,分析一下:
大家都知道 in 和 exists 的争论,大致就是 大子表用 exists 小子表用 in,exists会根据主表条件去遍历子表,选取同时符合exists条件的记录。in 则是根据子表条件来卡主表,先将子表的数据查询出来,然后再检索主表看是否有符合的记录存在。
所以大子表的时候我们应该偏向检索主表,这样记录才会比较少,速度会更快,所以用 exists 比较合适;小子表的时候应该先用 in 将子查询条件检索出来,然后再去检索主表。
最后来个重量级的测试,其实我主表里一共有 34105584 (三千四百一十万 零五千五百八十四)条数据, 17 个字段, 而且字段大都设计的不合理,很多都是 varchar,不关我事,项目一直在线,我也不能改,现在用分表缓解的查询压力,看下测试结果吧
limit 34105450, 100 我的方法又再度雄起,虽然超过了 3秒 但和其他方法比起来性能很不错了
example_1:17.915 secs
example_2:51.673 secs
example_3:209.536 secs
就写到这里吧