leetcode -- Regular Expression Matching -- dp 重点
https://leetcode.com/problems/regular-expression-matching/
trick: 如果有两个str list, 考虑用2D dp[i][j]
思路1 递归
pyton TLE
思路2: dp
思路参考http://bangbingsyb.blogspot.hk/2014/11/leetcode-regular-expression-matching.html
关键在于如何处理这个’*’号。
状态:和Mininum Edit Distance这类题目一样。
这里要注意dp[i][j]的概念,即s里面有i个元素,对应的是s[0:i-1], p里面有j个元素,对应的是p[0:j-1]。因为最后要return dp[len(s)][len(p)]所以要申请len(s)+1以及len(p) +1的空间
dp[i][j]表示s[0:i-1]是否能和p[0:j-1]匹配。
这里要注意的是‘a*’可以是 ‘empty’ ,’a’, ‘aaaaaa…a’,这三种情况。要把’a*’看成一个整体。
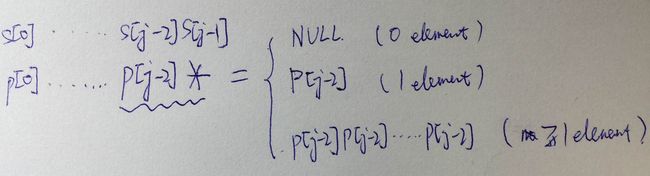
递推公式:由于只有p中会含有regular expression,所以以p[j-1]来进行分类。
p[j-1] != ‘.’ && p[j-1] != ‘*’:dp[i][j] = dp[i-1][j-1] && (s[i-1] == p[j-1])
p[j-1] == ‘.’:dp[i][j] = dp[i-1][j-1]
而关键的难点在于 p[j-1] = ‘*’。由于星号可以匹配0,1,乃至多个p[j-2]。
匹配0个元素,即消去p[j-2],此时p[0: j-1] = p[0: j-3]
dp[i][j] = dp[i][j-2]匹配1个元素,此时p[0: j-1] = p[0: j-2]
dp[i][j] = dp[i][j-1]匹配多个元素,此时p[0: j-1] = { p[0: j-2], p[j-2], … , p[j-2] }
dp[i][j] = dp[i-1][j] && (p[j-2]==’.’ || s[i-1]==p[j-2])。这里的意思就是因为p[j-2]会重复,至少有两个,所以如果s[i-1] == p[j-2],(ref里面写错了),就可以把s[i-1]在s中的这个元素剔除,还剩下至少有一个p[j-2], 看看s[i-1]之前的元素有没有很多p[j-2], 这种情况就是dp[i-1][j]
python code 参考http://www.cnblogs.com/zuoyuan/p/3781773.html
class Solution(object):
def isMatch(self, s, p):
""" :type s: str :type p: str :rtype: bool """
dp=[[False for i in range(len(p)+1)] for j in range(len(s)+1)]
dp[0][0]=True
for i in range(1,len(p)+1):
if p[i-1]=='*':
if i>=2:
dp[0][i]=dp[0][i-2]
for i in range(1,len(s)+1):
for j in range(1,len(p)+1):
if p[j-1]=='.':
dp[i][j]=dp[i-1][j-1]
elif p[j-1]=='*':
dp[i][j]=dp[i][j-1] or dp[i][j-2] or (dp[i-1][j] and (s[i-1]==p[j-2] or p[j-2]=='.'))
else:
dp[i][j]=dp[i-1][j-1] and s[i-1]==p[j-1]
return dp[len(s)][len(p)]重写code
上述程序是按p[j-1]分类的,p[j-1]==’.’:, p[j-1]==’*’:, p[j-1]为字母。
也可以按照自己的分类方法,如下。
class Solution(object):
def isMatch(self, s, p):
""" :type s: str :type p: str :rtype: bool """
#dp = [[False] * (len(p) + 1)] * (len(s) + 1)
dp=[[False for i in range(len(p)+1)] for j in range(len(s)+1)]
#print dp
dp[0][0] = True
#for i in xrange(1, len(s)):这个其实不需要,因为已经初始化为False
#dp[i][0] = False
#print dp
for j in xrange(1, len(p) + 1):
if p[j-1] == '*':
if j>=2:
dp[0][j] = dp[0][j-2]
for i in xrange(1, len(s) + 1):
for j in xrange(1, len(p) + 1):
if p[j-1] == s[i-1] or p[j-1] == '.':
dp[i][j] = dp[i-1][j-1]
elif p[j-1] == '*':
dp[i][j] = dp[i][j-2] or dp[i][j-1] or (dp[i-1][j] and (s[i-1] == p[j-2] or p[j-2] == '.'))
#else:这个其实不需要,因为已经初始化为False
#dp[i][j] = False
return dp[len(s)][len(p)]这里要注意的是dp矩阵的初始化,如果初始化为
dp = [[False] * (len(p) + 1)] * (len(s) + 1)会有问题,还不清楚为什么。如果是申请3*2的matrix,dp初始化之后是正确的,
[[False, False], [False, False], [False, False]]在dp[0][0] = True之后,就错了, 第一列全部变为True了
[[True, False], [True, False], [True, False]]正确的办法如下
dp = [[False for j in xrange(len(p) + 1)] for i in xrange(len(s) + 1)]