深入分析字符编码之三-Java 中如何编解码
前面介绍了几种常见的编码格式,这里将以实际例子介绍 Java 中如何实现编码及解码,下面我们以“I am 君山”这个字符串为例介绍 Java 中如何把它以 ISO-8859-1、GB2312、GBK、UTF-16、UTF-8 编码格式进行编码的。
清单 2.String 编码
public static void encode() { String name = "I am 君山"; toHex(name.toCharArray()); try { byte[] iso8859 = name.getBytes("ISO-8859-1"); toHex(iso8859); byte[] gb2312 = name.getBytes("GB2312"); toHex(gb2312); byte[] gbk = name.getBytes("GBK"); toHex(gbk); byte[] utf16 = name.getBytes("UTF-16"); toHex(utf16); byte[] utf8 = name.getBytes("UTF-8"); toHex(utf8); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } }
我们把 name 字符串按照前面说的几种编码格式进行编码转化成 byte 数组,然后以 16 进制输出,我们先看一下 Java 是如何进行编码的。
下面是 Java 中编码需要用到的类图
图 1. Java 编码类图
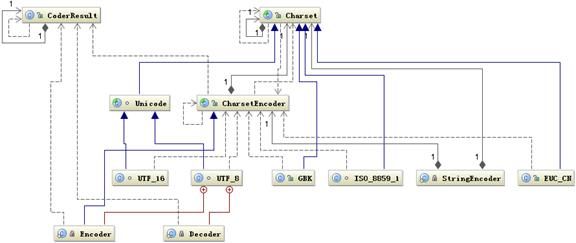
首先根据指定的 charsetName 通过 Charset.forName(charsetName) 设置 Charset 类,然后根据 Charset 创建 CharsetEncoder 对象,再调用 CharsetEncoder.encode 对字符串进行编码,不同的编码类型都会对应到一个类中,实际的编码过程是在这些类中完成的。下面是 String. getBytes(charsetName) 编码过程的时序图
图 2.Java 编码时序图
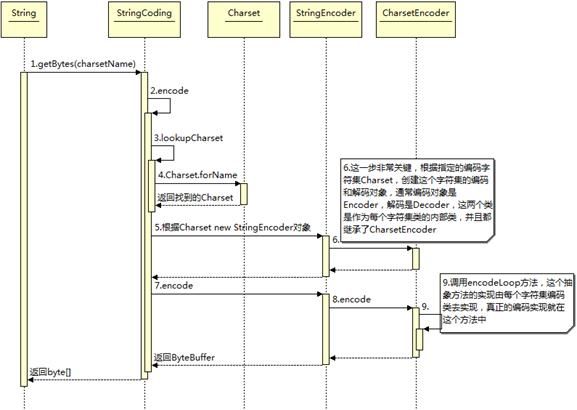
从上图可以看出根据 charsetName 找到 Charset 类,然后根据这个字符集编码生成 CharsetEncoder,这个类是所有字符编码的父类,针对不同的字符编码集在其子类中定义了如何实现编码,有了 CharsetEncoder 对象后就可以调用 encode 方法去实现编码了。这个是 String.getBytes 编码方法,其它的如 StreamEncoder 中也是类似的方式。下面看看不同的字符集是如何将前面的字符串编码成 byte 数组的?
如字符串“I am 君山”的 char 数组为 49 20 61 6d 20 541b 5c71,下面把它按照不同的编码格式转化成相应的字节。
按照 ISO-8859-1 编码
字符串“I am 君山”用 ISO-8859-1 编码,下面是编码结果:

从上图看出 7 个 char 字符经过 ISO-8859-1 编码转变成 7 个 byte 数组,ISO-8859-1 是单字节编码,中文“君山”被转化成值是 3f 的 byte。3f 也就是“?”字符,所以经常会出现中文变成“?”很可能就是错误的使用了 ISO-8859-1 这个编码导致的。中文字符经过 ISO-8859-1 编码会丢失信息,通常我们称之为“黑洞”,它会把不认识的字符吸收掉。由于现在大部分基础的 Java 框架或系统默认的字符集编码都是 ISO-8859-1,所以很容易出现乱码问题,后面将会分析不同的乱码形式是怎么出现的。
按照 GB2312 编码
字符串“I am 君山”用 GB2312 编码,下面是编码结果:
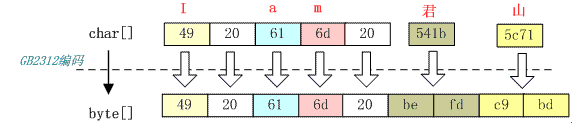
GB2312 对应的 Charset 是 sun.nio.cs.ext. EUC_CN 而对应的 CharsetDecoder 编码类是 sun.nio.cs.ext. DoubleByte,GB2312 字符集有一个 char 到 byte 的码表,不同的字符编码就是查这个码表找到与每个字符的对应的字节,然后拼装成 byte 数组。查表的规则如下:
c2b[c2bIndex[char >> 8] + (char & 0xff)]
如果查到的码位值大于 oxff 则是双字节,否则是单字节。双字节高 8 位作为第一个字节,低 8 位作为第二个字节,如下代码所示:
if (bb > 0xff) { // DoubleByte if (dl - dp < 2) return CoderResult.OVERFLOW; da[dp++] = (byte) (bb >> 8); da[dp++] = (byte) bb; } else { // SingleByte if (dl - dp < 1) return CoderResult.OVERFLOW; da[dp++] = (byte) bb; }
从上图可以看出前 5 个字符经过编码后仍然是 5 个字节,而汉字被编码成双字节,在第一节中介绍到 GB2312 只支持 6763 个汉字,所以并不是所有汉字都能够用 GB2312 编码。
按照 GBK 编码
字符串“I am 君山”用 GBK 编码,下面是编码结果:

你可能已经发现上图与 GB2312 编码的结果是一样的,没错 GBK 与 GB2312 编码结果是一样的,由此可以得出 GBK 编码是兼容 GB2312 编码的,它们的编码算法也是一样的。不同的是它们的码表长度不一样,GBK 包含的汉字字符更多。所以只要是经过 GB2312 编码的汉字都可以用 GBK 进行解码,反过来则不然。
按照 UTF-16 编码
字符串“I am 君山”用 UTF-16 编码,下面是编码结果:

用 UTF-16 编码将 char 数组放大了一倍,单字节范围内的字符,在高位补 0 变成两个字节,中文字符也变成两个字节。从 UTF-16 编码规则来看,仅仅将字符的高位和地位进行拆分变成两个字节。特点是编码效率非常高,规则很简单,由于不同处理器对 2 字节处理方式不同,Big-endian(高位字节在前,低位字节在后)或 Little-endian(低位字节在前,高位字节在后)编码,所以在对一串字符串进行编码是需要指明到底是 Big-endian 还是 Little-endian,所以前面有两个字节用来保存 BYTE_ORDER_MARK 值,UTF-16 是用定长 16 位(2 字节)来表示的 UCS-2 或 Unicode 转换格式,通过代理对来访问 BMP 之外的字符编码。
按照 UTF-8 编码
字符串“I am 君山”用 UTF-8 编码,下面是编码结果:

UTF-16 虽然编码效率很高,但是对单字节范围内字符也放大了一倍,这无形也浪费了存储空间,另外 UTF-16 采用顺序编码,不能对单个字符的编码值进行校验,如果中间的一个字符码值损坏,后面的所有码值都将受影响。而 UTF-8 这些问题都不存在,UTF-8 对单字节范围内字符仍然用一个字节表示,对汉字采用三个字节表示。它的编码规则如下:
清单 3.UTF-8 编码代码片段
private CoderResult encodeArrayLoop(CharBuffer src, ByteBuffer dst){ char[] sa = src.array(); int sp = src.arrayOffset() + src.position(); int sl = src.arrayOffset() + src.limit(); byte[] da = dst.array(); int dp = dst.arrayOffset() + dst.position(); int dl = dst.arrayOffset() + dst.limit(); int dlASCII = dp + Math.min(sl - sp, dl - dp); // ASCII only loop while (dp < dlASCII && sa[sp] < '\u0080') da[dp++] = (byte) sa[sp++]; while (sp < sl) { char c = sa[sp]; if (c < 0x80) { // Have at most seven bits if (dp >= dl) return overflow(src, sp, dst, dp); da[dp++] = (byte)c; } else if (c < 0x800) { // 2 bytes, 11 bits if (dl - dp < 2) return overflow(src, sp, dst, dp); da[dp++] = (byte)(0xc0 | (c >> 6)); da[dp++] = (byte)(0x80 | (c & 0x3f)); } else if (Character.isSurrogate(c)) { // Have a surrogate pair if (sgp == null) sgp = new Surrogate.Parser(); int uc = sgp.parse(c, sa, sp, sl); if (uc < 0) { updatePositions(src, sp, dst, dp); return sgp.error(); } if (dl - dp < 4) return overflow(src, sp, dst, dp); da[dp++] = (byte)(0xf0 | ((uc >> 18))); da[dp++] = (byte)(0x80 | ((uc >> 12) & 0x3f)); da[dp++] = (byte)(0x80 | ((uc >> 6) & 0x3f)); da[dp++] = (byte)(0x80 | (uc & 0x3f)); sp++; // 2 chars } else { // 3 bytes, 16 bits if (dl - dp < 3) return overflow(src, sp, dst, dp); da[dp++] = (byte)(0xe0 | ((c >> 12))); da[dp++] = (byte)(0x80 | ((c >> 6) & 0x3f)); da[dp++] = (byte)(0x80 | (c & 0x3f)); } sp++; } updatePositions(src, sp, dst, dp); return CoderResult.UNDERFLOW; }
UTF-8 编码与 GBK 和 GB2312 不同,不用查码表,所以在编码效率上 UTF-8 的效率会更好,所以在存储中文字符时 UTF-8 编码比较理想。
几种编码格式的比较
对中文字符后面四种编码格式都能处理,GB2312 与 GBK 编码规则类似,但是 GBK 范围更大,它能处理所有汉字字符,所以 GB2312 与 GBK 比较应该选择 GBK。UTF-16 与 UTF-8 都是处理 Unicode 编码,它们的编码规则不太相同,相对来说 UTF-16 编码效率最高,字符到字节相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间快速切换,如 Java 的内存编码就是采用 UTF-16 编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难恢复,想比较而言 UTF-8 更适合网络传输,对 ASCII 字符采用单字节存储,另外单个字符损坏也不会影响后面其它字符,在编码效率上介于 GBK 和 UTF-16 之间,所以 UTF-8 在编码效率上和编码安全性上做了平衡,是理想的中文编码方式。
原创文章,转载请注明:转载自http://www.whohelpme.com/blog/main/NO1.html