MapReduce
MapReduce 是Google 提出的一个软件架构,用于大规模数据集(大于1TB )的并行运算。概念"Map(映射)"和"Reduce(化简)",和他们的主要思想,都是从函数式编程语言 借来的,还有从矢量编程语言 借来的特性。
当前的软件实现是指定一个Map(映射) 函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简) 函数,用来保证所有映射的键值对中的每一个共享相同的键组。
目录[隐藏 ]
|
[编辑 ] 映射和化简
简单说来,一个映射函数就是对一些独立元素组成的概念上的列表(例如,一个测试成绩的列表)的每一个元素进行指定的操作(比如前面的例子里,有人发 现所有学生的成绩都被高估了一分,他可以定义一个“减一”的映射函数,用来修正这个错误。)。事实上,每个元素都是被独立操作的,而原始列表没有被更改, 因为这里创建了一个新的列表来保存新的答案 。这就是说,Map操作是可以高度并行的 ,这对高性能要求的应用以及并行计算 领域的需求非常有用。
而化简操作指的是对一个列表的元素进行适当的合并 (继续看前面的例子,如果有人想知道班级的平均分该怎么做?他可以定义一个化简函数,通过让列表中 的奇数(odd)或偶数(even)元素跟自己的相邻的元素相加的方式把列表减半,如此递归运算直到列表只剩下一个元素,然后用这个元素除以人数,就得到 了平均分)。虽然他不如映射函数那么并行,但是因为化简总是有一个简单的答案,大规模的运算相对独立,所以化简函数在高度并行环境下也很有用。
[编辑 ] 分布和可靠性
MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性;每个节点会周期性的把完成的工作和状态的更新报告回来。如果一个节点保持沉默超过一个预设的时间间隔,主节点(类同Google档案系统 中的主服务器)记录下这个节点状态为死亡,并把分配给这个节点的数据发到别的节点。每个操作使用命名文件的原子操作以确保不会发生并行线程间的冲突;当文件被改名的时候,系统可能会把他们复制到任务名以外的另一个名字上去。(避免副作用 )。
化简操作工作方式很类似,但是由于化简操作在并行能力较差,主节点会尽量把化简操作调度在一个节点上,或者离需要操作的数据尽可能近的节点上了;这个特性可以满足Google的需求,因为他们有足够的带宽,他们的内部网络没有那么多的机器。
[编辑 ] 用途
在Google,MapReduce用在非常广泛的应用程序中,包括“分布grep ,分布排序,web连接图反转,每台机器的词矢量,web访问日志分析,反向索引构建,文档聚类,机器学习 ,基于统计的机器翻译……”值得注意的是,MapReduce实现以后,它被用来重新生成Google的整个索引,并取代老的ad hoc程序去更新索引。
MapReduce会生成大量的临时文件 ,为了提高效率,它利用Google档案系统 来管理和访问这些文件。
首先,在Google数据中心会有大规模数据需要处理,比如被网络爬虫(Web Crawler)抓取的大量网页等。由于这些数据很多都是PB级别,导致处理工作不得不尽可能的并行化,而Google为了解决这个问题,引入了 MapReduce这个编程模型,MapReduce是源自函数式语言,主要通过"Map(映射)"和"Reduce(化简)"这两个步骤来并行处理大规 模的数据集。Map会先对由很多独立元素组成的逻辑列表中的每一个元素进行指定的操作,且原始列表不会被更改,会创建多个新的列表来保存Map的处理结果。也就意味着,Map操作是高度并行的。当Map工作完成之后,系统会先对新生成的多个列表进行清理(Shuffle)和排序,之后会这些新创建的列表进行Reduce操作,也就是对一个列表中的元素根据Key值进行适当的合并。
下图为MapReduce的运行机制:
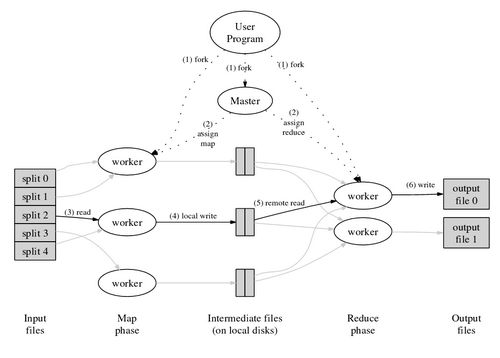
图2. MapReduce的运行机制
接下来,将根据上图来举一个MapReduce的例子:比如,通过搜索Spider将海量的Web页面抓取到本地的GFS 集群中,然后Index系统将会对这个GFS集群中多个数据Chunk进行平行的Map处理,生成多个Key为URL,value为html页面的键值对 (Key-Value Map),接着系统会对这些刚生成的键值对进行Shuffle(清理),之后系统会通过Reduce操作来根据相同的key值(也就是URL)合并这些键 值对。
最后,通过MapReduce这么简单的编程模型,不仅能用于处理大规模数据,而且能将很多繁琐的细节隐藏起来,比如自动并行化,负载均衡和机器宕 机处理等,这样将极大地简化程序员的开发工作。MapReduce可用于包括“分布grep,分布排序 ,web访问日志分析,反向索引构建,文档聚类 ,机器学习,基于统计的机器翻译,生成Google的整个搜索的索引“等大规模数据处理工作。Yahoo也推出MapReduce的开源版本Hadoop,而 且Hadoop在业界也已经被大规模使用。