apache-hadoop-1.2.1、hbase、hive、mahout、nutch、solr安装教程
1 软件环境:
VMware8.0
Ubuntu-12.10-desktop-i386
jdk-7u40-linux-i586.tar.gz
hadoop-1.2.1.tar.gz
eclipse-dsl-juno-SR1-linux-gtk.tar.gz
hadoop-eclipse-plugin-1.2.1.jar
apache-maven-2.2.1-bin.tar.gz
hbase-0.94.11.tar.gz
hive-0.10.0.tar.gz
mahout-distribution-0.8.tar.gz
apache-tomcat-7.0.42.tar.gz
apache-nutch-1.2-bin.tar.gz
solr-4.4.0.tgz
2 角色配置:
master节点:master
slave节点:slave01
3 Hadoop完全分布式集群配置
3.1 下载安装JDK
3.1.1 下载jdk-7u40-linux-i586.tar.gz
3.1.2 在/usr/下新建文件夹java
$cd /usr
$sudo mkdir java
3.1.3 解压jdk-7u40-linux-i586.tar.gz在java文件夹下
3.1.4 配置环境变量
$sudo gedit /etc/profile //在最后加入
export JAVA_HOME=/usr/java/jdk1.7.0_40
export JRE_HOME=/usr/java/jdk1.7.0_40/jre
exportPATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
exportCLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JRE_HOME/lib
source /etc/profile //使环境变量生效
3.1.5 修改系统默认的jdk
$sudo update-alternatives --install/usr/bin/java java /usr/java/jdk1.7.0_40/bin/java 300
$sudo update-alternatives --install/usr/bin/javac javac /usr/java/jdk1.7.0_40/bin/javac 300
$sudoupdate-alternatives --config java
$sudoupdate-alternatives --config javac
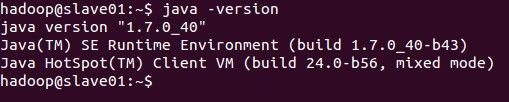
3.1.6 检查安装是否成功
$java-version
3.2 SSH安装及设置
通过ssh安全协议master与slaves之间进行通信,实现hadoop完全分布式部署。
3.2.1 ifconfig 查看主机ip:
这里:
master:10.10.20.103
slave01:10.10.20.101
3.2.2在hosts文件中加上集群中所有机器的IP地址及其对应的主机名
在namenode(这里为master)上:$ sudo gedit /etc/hosts
127.0.0.1 localhost
10.10.20.103 master
10.10.20.101 slave01
3.2.3 ping测试
每台机器互ping ip地址和主机名,看是否可以ping通。
3.2.4 安装设置ssh(说明:每台电脑上都要安装ssh)
3.2.4.1在namenode(master)上:
$ sudo apt-get install ssh //安装ssh(这步在每台电脑上都要执行!)
$ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa//生成密钥(这里密码为空) 文件如:id_dsa id_dsa.pub
$cat ~/.ssh/id_dsa.pub >>~/.ssh/authorized_keys //加入受信列表
$ ssh localhost 或者 ssh master //第一次需输入"yes",成功就能无密码访问 这个是进行的本地测试
3.2.4.2把master上的id_dsa.pub 文件追加到slave01的authorized_keys 内:
拷贝master的id_dsa.pub文件到slave01:
$ scp id_dsa.pub hadoop@slave01:/home/hadoop/Desktop
//如果拷贝到其它目录下,可能会出现permission denied错误,如拷贝到home下,这是因为其它用户没有写权限
3.2.4.3在datanode(这里为slave01)上:
进入/home/hadoop/Desktop目录执行:
$ cat id_dsa.pub >> .ssh/authorized_keys
//可以在master上不输入密码直接访问slave01
说明:1、若要实现datanode无密码访问namenode,只需按照上面的步骤将datanode的*.pub文件复制到namenode上,并追加到authorized_keys中
3.3安装hadoop
注意:由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
我的为:/usr/hadoop/
3.3.1在namenode上
cd /usr/hadoop
tar -xzvf hadoop-1.2.1.tar.gz //将压缩包解压到/usr/hadoop/hadoop-1.2.1
配置hadoop-1.2.1/conf 下的 hadoop-env.sh文件将 # exportJAVA_HOME=/usr/lib/j2sdk1.5-sun 改为:exportJAVA_HOME=/usr/java/jdk1.7.0_40
配置hadoop-1.2.1/conf下的slaves文件,一行一个DataNode,格式为: 用户名@hostip slave01@slave01 //必须这样写
修改masters文件内容为: master //也可以是namenode的ip,由于在/etc/hosts中设置了matraxa与ip的对应,可以写为master
配置hadoop-1.2.1/conf下的三个xml文件
修 改 core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
修改 mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
</property>
修改hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop_tmp_dir/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
g)进入/usr/hadoop/hadoop-1.2.1
bin/hadoop namenode -format //必需初始化 只需要初始化namenode
h)bin/start-all.sh //启动namdnode
3.3.2在datanode(这里为slave01)上:
注意:由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
我的为:/usr/hadoop/
a) 在slave01机器上建立了一个录:/usr/hadoop。
将master机器上/usr/hadoop /hadoop-1.2.1文件夹拷贝到slave机器上的/usr/hadoop/ 命令为:scp -r /usr/hadoop /hadoop-1.2.1 [email protected]:/usr/hadoop/
/etc/hosts和namenode的一样 //参照3.1.2
3.3.3、启动Hadoop
a) 格式化namenode:启动之前要先格式化namenode,进入/usr/hadoop /hadoop-1.2.1目录,执行下面的命令:bin/hadoop namenode –format
启动namenode:执行命令bin/start-all.sh
停止Hadoop:执行如下命令:bin/stop-all.sh
注意:如果datanode无法启动,先检查conf/masters,conf/slaves,然后尝试删除所有节点的hadoop.tmp.dir
3.4安装eclipse
a) 下载eclipse-dsl-juno-SR1-linux-gtk.tar.gz
解压到 /usr/ 目录
进入/ usr/eclipse
命令行输入./eclipse 即可打开eclipse
3.5安装hadoop的eclipse插件
利用eclipse开发,需安装hadoop-eclipse插件。
a) 下载hadoop-eclipse-plugin-1.2.1.jar,将其复制到eclipse安装目录下的plugins目录中。
重启eclipse,配置hadoop installation directory。如果安装插件成功,打开Window-->Preferens,会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installationdirectory。配置完成后退出。
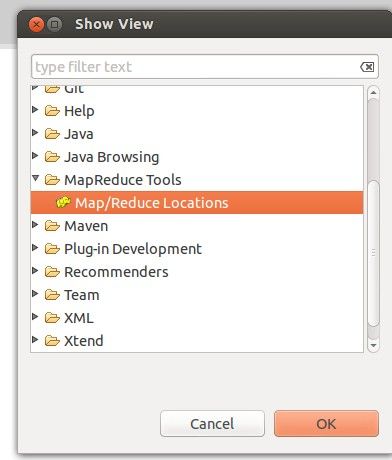
在Map/Reduce Locations(Eclipse界面的正下方)中新建一个Hadoop Location。在这个View中,点击鼠标右键-->New Hadoop Location。在弹出的对话框中你需要配置Location name,可任意填,如Hadoop,以及Map/Reduce Master和DFS Master。这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。我的这两个文件中配置如下:
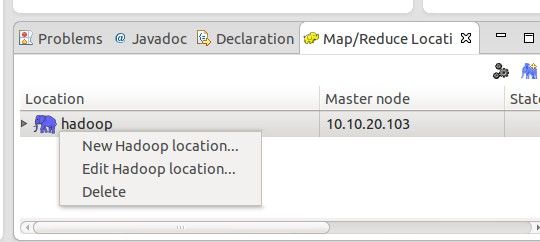
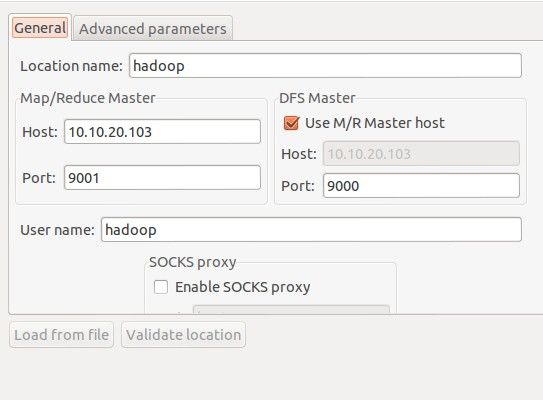
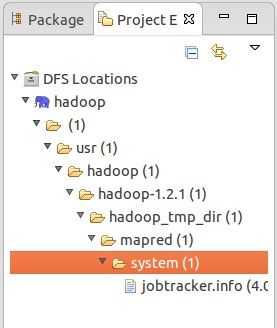
设置完成后,点击Finish就应用了该设置。然后,在最左边的Project Explorer中就能看到DFS的目录,如下图所示:
4安装maven
a) 下载apache-maven-2.2.1-bin.tar.gz
解压在/usr/ 目录下
sudo gedit/etc/profile加入环境变量
export MAVEN_HOME=/usr/apache-maven-2.2.1
export PATH=$PATH:MAVEN_HOME/bin
mvn –version
出现如下信息即成功

5安装hbase
a) 解压hbase-0.94.11.tar.gz到/usr/hadoop 解压命令:$tar zxvf hbase-0.94.11.tar.gz
b) 配置/usr/hadoop/hbase-0.94.11/conf下文件hbase-env.sh 用gedit打开hbase-env.sh修改
文件未尾加:
# Tell HBasewhether it should manage it's own instance of Zookeeper or not.
exportHBASE_MANAGES_ZK=true
export JAVA_HOME=/usr/java/jdk1.6.0_20
配置/usr/hadoop/hbase-0.94.11/conf下文件hbase-site.xml
<?xmlversion="1.0"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave01</value>
</property>
</configuration>
u hbase.rootdir设置hbase在hdfs上的目录,主机名为hdfs的namenode节点所在的主机
u hbase.cluster.distributed设置为true,表明是完全分布式的hbase集群
u hbase.master设置hbase的master主机名和端口
u hbase.zookeeper.quorum设置zookeeper的主机,官方推荐设置为3,5,7比较好,奇数。
d) 配置/usr/hadoop/hbase-0.94.11/conf下文件regionservers
slave01
e) 设置环境变量,用gedit打开/etc/profile文件在文件未尾添加:
export HBASE_HOME=/usr/hadoop/hbase-0.94.11
exportPATH=$PATH:$HBASE_HOME/bin
f) 在完成以上修改之后,把master上的hbase-0.94.11原样复制到slave01上,保证目录结构一致,可使用如下命令:
scp –r /usr/hadoop/hbase-0.94.11 slave01@slave01: /usr/hadoop/hbase-0.94.11
c) 启动Hbase(首先要启动hadoop)
bin/start-hbase.sh
bin/stop-hbase.sh
登陆http://master:60010,出现如下图,说明hbase分布式搭建成功。

u permission denied的解决方法
如果想让bin下的所有文件都可执行
则 chmod a+x bin/*
6 安装hive
Hive只需要在master主机上安装
a) 解压hive-0.10.1.gar.gz到/usr/hadoop下
b) 用gedit打开/etc/profile配置环境变量
exportHIVE_HOME=/usr/hadoop/hive-0.10.0
exportHIVE_CONF_DIR=/usr/hadoop/hive-0.10.0/conf
export PATH=$PATH:$HIVE_HOME/bin
c) 进入HIVE_HOME运行bin/hive 出现hive shell 命令行说明安装成功。
支持多用户会话,需要一个独立的元数据库,常用的是使用MySQL作为元数据库。
a) sudoapt-get install mysql-server mysql-client安装mysql
完成后通过netstat –tap |grep mysql 来车看是否已经有了mysql服务,如下图即成功。

b) 为hive建立相应的mysql账号:
进入mysql: mysql –u root –p
mysql> create user 'hive'@’localhost’identified by '123';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hive'@'localhost'IDENTIFIED BY '123' WITH GRANT OPTION;
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0rows affected (0.00 sec)
mysql> exit
Bye
如果出现新建用户denied的情况,是因为user表里面已经存在该用户。之后删除用户再并且可以附加flush privileges之后再新建。用新用户登录不进去可以尝试删除mysql的匿名用户。注意host的是localhost或者是127.0.0.1或者不填。
c) 从客户端用hive账号登陆mysql
mysql –u hive -p
d) 建立hive的元数据库
mysql>create database hive;
e) mysql中保存了hive的元数据信息,包括表的属性、桶信息和分区信息等,以hive帐号登陆hive查看元数据信息
f) 配置Hive
在Hive安装目录的conf目录下,将hive-default.xml.template复制一份命名为:hive-site.xml
修改以下内容,配置上mysql数据连接、驱动、用户名和密码
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
</property>
g) 把mysql的驱动包mysql-connector-java-5.1.15拷贝到Hive安装路径下的lib目录
h) 进入Hive,没报错说明安装成功
7 hive与hbase的整合(用hive读取hbase的数据)
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive与HBase的整合功能的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive_hbase-handler.jar工具类, 大致意思如图所示:

3.8.1整合hive与hbase的过程如下:
a) 将文件/usr/hadoop/hive-0.10.0/hbase-0.94.11.jar 与/usr/hadoop/hive-0.10.0/lib/zookeeper-3.4.5.jar拷贝到/usr/hadoop/hive-0.10.0/lib文件夹下面
注意:如果hive/lib下已经存在这两个文件的其他版本(例如zookeeper-3.3.1.jar),建议删除后使用hbase下的相关版本
b) 修改hive/conf下hive-site.xml文件,在底部添加如下内容:
<property>
<name>hive.querylog.location</name>
<value>/usr/hadoop/hive-0.10.0/logs</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>file:///usr/hadoop/hive-0.10.0/lib/hive-hbase-handler-0.10.0.jar,file:///usr/hadoop/hive-0.10.0/lib/hbase-0.94.11.jar,file:///usr/hadoop/hive-0.10.0/lib/zookeeper-3.4.5.jar</value>
</property>
注意:如果hive-site.xml不存在则自行创建,或者把hive-default.xml.template文件改名后使用。
c) 拷贝hbase-0.94.11.jar到所有hadoop节点(包括master)的usr/hadoop/hadoop-1.2.1/lib下。
d) 拷贝usr/hadoop/hbase-0.94.11/conf下的hbase-site.xml文件到所有hadoop节点(包括master)的usr/hadoop/hadoop-1.2.1/conf下。
注意,如果3,4两步跳过的话,运行hive时很可能出现如下错误:org.apache.hadoop.hbase.ZooKeeperConnectionException:HBase is able to connect to ZooKeeper but the connection closes immediately.
This could be a sign that the server has too many connections (30 is thedefault). Consider inspecting your ZK server logs for that error and
then make sure you are reusing HBaseConfiguration as often as you can. SeeHTable's javadoc for more information. at org.apache.hadoop.
hbase.zookeeper.ZooKeeperWatcher.
e) 启动hive
单节点启动
bin/hive -hiveconf hbase.master=master:60000
f) 集群启动
bin/hive
注意:如果hive-site.xml文件中没有配置hive.aux.jars.path,则可以按照如下方式启动。hive --auxpath /opt/mapr/hive/hive-0.7.1/lib/hive-hbase-handler-0.7.1.jar,/opt/mapr/hive/hive-0.7.1/lib/hbase-0.90.4.jar,/opt/mapr/hive/hive-0.7.1/lib/zookeeper-3.3.2.jar-hiveconf hbase.master=localhost:60000
3.8.2启动后进行测试
a) 创建hbase识别的表
CREATE TABLE hbase_table_1(key int, value string) STORED BY'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES("hbase.columns.mapping" = ":key,cf1:val")TBLPROPERTIES ("hbase.table.name" = "xyz");
b) 新建hive的数据表
create tablepokes(foo int,bar string)row format delimited fields terminated by ',';
c) 批量导入数据
load data localinpath '/home/hadoop/Desktop//1.txt' overwrite into table pokes;
1.txt文件的内容为
1,hello
2,pear
3,world
d) 使用sql导入hbase_table_1
insert overwrite table hbase_table_1 select * frompokes;
e) 查看数据
hive>select * from hbase_table_1;
OK
1 hello
2 pear
3 world
8安装mahout
a) 解压mahout-distribution-0.8.tar.gz到/usr/hadoop/下
b) sudo/etc/profile配置环境变量
exportMAHOUT_HOME=/usr/hadoop/mahout-distribution-0.8
export HADOOP_HOME=/usr/hadoop/hadoop-1.2.1
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-1.2.1/conf
export PATH=$HADOOP_HOME/bin
exportCLASSPATH=$CLASSPATH:$MAHOUT_HOME/lib:HADOOP_CONF_DIR
c) 启动hadoop
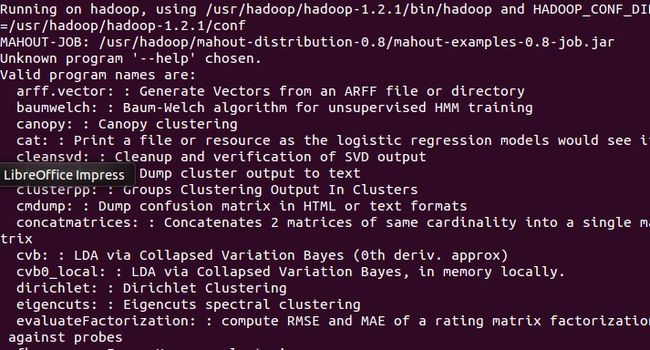
d) bin/mahout--help //检查Mahout是否安装完好,看是否列出了一些算法
9 Tomcat安装配置
9.1下载apache-tomcat-7.0.42.tar.gz
9.2 在/usr/下新建文件夹tomcat
$cd /usr
$sudo mkdir tomcat
9.3 解压apache-tomcat-7.0.42.tar.gz在tomcat文件夹下
$cd /usr/tomcat
$sudo tar –zxvf apache-tomcat-7.0.42.tar.gz
解压之后tomcat文件夹下会生成一个叫做apache-tomcat-7.0.42的文件夹
9.4 配置环境变量
$sudo gedit /etc/profile,加入以下红色部分
export JAVA_HOME=/usr/java/jdk1.7.0_40
export HADOOP_HOME=/usr/hadoop/hadoop-1.2.1
exportHADOOP_CONF_DIR=/usr/hadoop/hadoop-1.2.1/conf
exportMAHOUT_HOME=/usr/hadoop/mahout-distribution-0.8
exportMAVEN_HOME=/usr/maven/apache-maven-2.2.1
exportCATALINA_HOME=/usr/tomcat/apache-tomcat-7.0.42
export HIVE_HOME=/usr/hadoop/hive-0.10.0
export HBASE_HOME=/usr/hadoop/hbase-0.94.11
exportPATH=$JAVA_HOME/bin:$MAHOUT_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/conf:$MAVEN_HOME/bin:$CATALINA_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$MAHOUT_HOME/lib:$HADOOP_HOME/lib:$HADOOP_CONF_DIR:$MAVEN_HOME/lib:$CATALINA_HOME/lib:$HIVE_HOME/lib:$HBASE_HOME/lib:$JAVA_HOME/lib/tools.jar
$source etc/profile //使环境变量生效
9.5检查安装是否成功
$cd /usr/tomcat/apache-tomcat-7.0.42
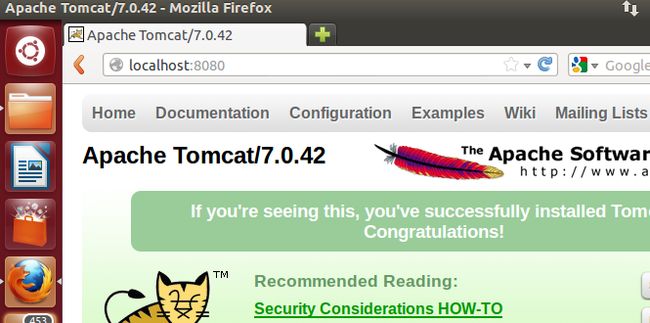
$bin/startup.sh

打开firefox,输入http://localhost:8080,如果正常访问,则表示成功。
10Nutch安装及设置
10.1 下载apache-nutch-1.2-bin.tar.gz
10.2 解压apache-nutch-1.2-bin.tar.gz在/usr/hadoop文件夹下
$cd /usr/hadoop
$sudo tar –zxvf apache-nutch-1.2-bin.tar.gz
解压之后hadoop文件夹下会生成一个叫做nutch-1.2的文件夹
10.3 修改nutch-site.xml文件
在根目录conf文件夹找到nutch-site.xml,打开在configuration标签里面添加:
<property>
<name>http.agent.name</name>
<value>openlab</value>
</property>
10.4添加nutch命令到/usr/bin
$cd /usr/bin
$ln -s {nutch根目录}/bin/nutch ./nutch
在任意目录输入nutch命令,有选项提示,则配置成功.
11Solr安装及设置
11.1 下载solr-4.4.0.tgz
11.2 解压solr-4.4.0.tgz在/usr/hadoop文件夹下
$cd /usr/hadoop
$sudo tar –zxvf solr-4.4.0.tgz
解压之后hadoop文件夹下会生成一个叫做solr-4.4.0的文件夹
11.3将solr-4.4.0下面dist/solr-4.4.0.war拷到tomcat的webapps文件夹下面,修改为solr.war
启动一次tomcat,在解压出的war包文件夹里面找到WEB-INF/lib,然后把mmseg4j-all-1.8.5.jar包拷进去。
如solr.war,tomcat启动之后会产生solr目录。
11.4将solr-4.4.0\example\ 下的 solr 目录拷贝到任意位置,
我是放在:~/solr_home
11.5 在tomcat目录下的conf\Catalina\localhost\solr.xml文件,添加如下内容:
<Context docBase="/usr/tomcat/apache-tomcat-7.0.42/webapps/solr.war"debug="0" crossContext="true" >
<Environment name="solr/home"type="java.lang.String" value="/home/hadoop/solr_home"override="true" />
</Context>
若目录下没有该solr.xml文件,则新建一个,注意还要在文件开头添加xml头:
<?xml version="1.0"encoding="UTF-8"?>
11.6 修改solr工作目录conf文件夹下的配置文件solrconfig.xml
<dataDir>${solr.data.dir:/home/hadoop/solr_home/data}</dataDir>
11.7 检查是否配置正确
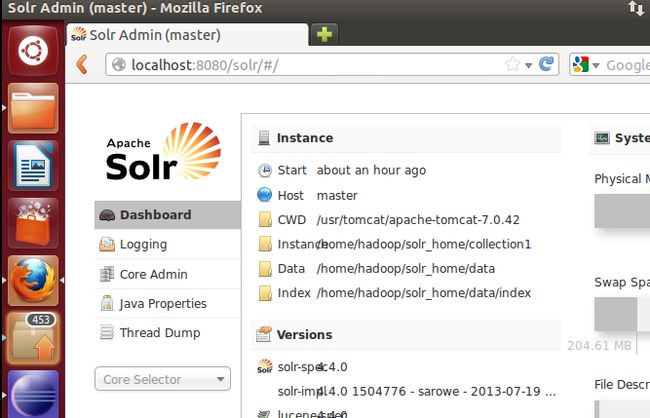
首先启动tomcat
运行localhost:8080/solr
如果成功进入,则部署成功。