分布式日志收集系统: Facebook Scribe之结构及源码分析
scribe结构及源码详细分析
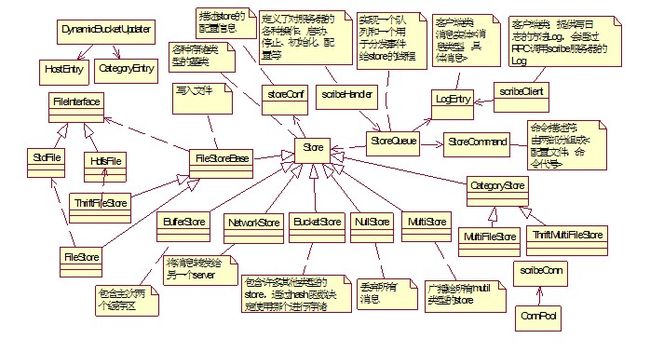
1. 整体类关系图
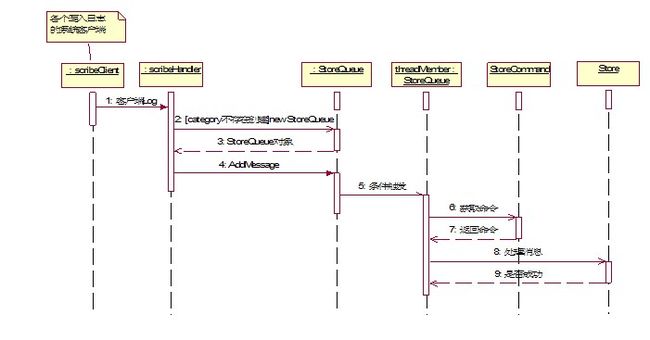
2. 客户端写日志序列图
3. 活动及状态图
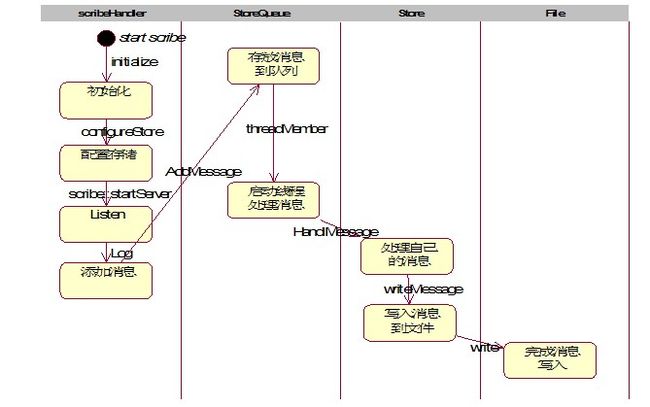
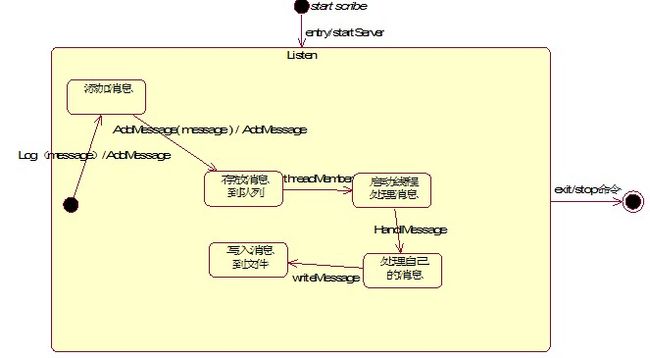
Scribe活动图
4. 启动代码详解
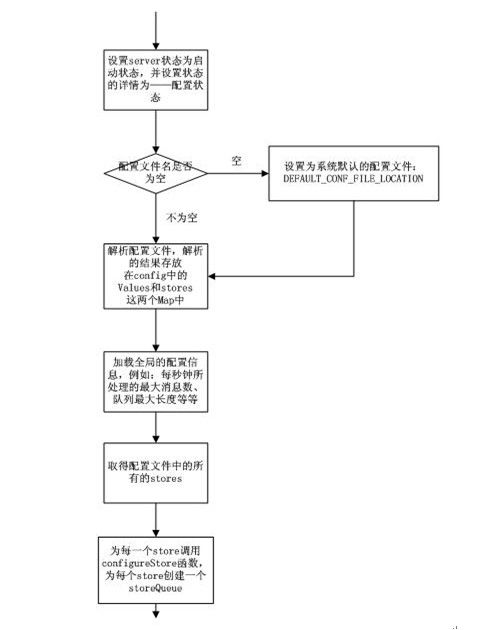
启动过程流程图
(1) 调用setrlimit函数设置能够打开的最大文件数为65535;
(2) 调用getopt_long函数解析运行scribe所带参数信息,如-p port指定运行端口号;
(3) 调用srand、time和getpid产生唯一的随机种子(不知道有什么作用);
(4) 根据端口号和配置文件new一个scribe服务器全局控制器对象g_Handler:scribeHandler类型;
(5) 调用initialize()函数初始化scribe服务器---->设置scribe运行状态信息---->调用StoreConf的parseConfig解析配置文件信息(解析过程后面单独详解)---->根据解析的配置文件信息载入全局配置信息到程序---->根据解析的配置文件信息调用configureStore函数配置模型信息---->获取存储分类名称并保存---->根据分类名称调用configureStoreCategory建立存储队列(包含有存储类型,具体的消息存入是由相应store完成的);
(6) 调用scribe::startServer()启动scribe服务器。
说明:上面第五点的箭头代表调用其他函数实现功能,就是函数一直嵌套下去。启动代码的文件是scribe_server.cpp,入口函数是main。
5. 配置文件解析源码详解
(1) 配置文件解析入口是在启动代码被调用的parseConfig函数,唯一的参数就是配置文件的名称;
(2) 调用readConfFile函数读入配置文件到一个字符串队列中,每一行数据为队列中的一个值,通过ifstream打开文件流,并getline一行一行的读入数据,并压入队列;
(3) 调用parseStore函数来解析存储的配置信息,参数是刚才读入的字符串队列和this指针(这个参数的作用是把解析的信息存入这个对象中,这个参数本身意义不大,但是在内部递归调用的时候需要新建一个StoreConf的对象存放下一级的配置信息时,就必须传入这个参数,所以统一考虑这个函数就设计成两个参数,第一调用就把this作为参数就可以了);
(4) 在parseStore函数中一行一行的取出,然后去掉注释和空白。然后判断这次读入的行是不是store开始行(<store>)或结束行(</store>)。如果是开始行就继续递归parseStore函数解析下一行数据;如果是结束行就解析完毕;如果都不是代表是一个配置项参数设置(名称=值),就分别提取出参数名称和值,并按键值对存放入map中。
(5) 配置文件解析完毕,解析的结果就按键值对存放在StoreConf的对象中,以后哪一个需要使用参数时直接在里面查找就可以了。
6. 存储配置详解
(1) 在启动代码详解中说明了存储信息的配置是通过configureStore和configureStoreCategory着两个函数实现的;
(2) 在configureStore函数中根据传递进来的StoreConf对象存放的配置信息,解析出此store存放哪个(参数名称category:单个分类)或哪几个(参数名称categories:多个分类mutil)分类的消息,并将其保持到分类向量中,然后针对单个和多个分类分别创建StoreQueue对象来执行消息的分发处理;
(3) 单个分类:直接调用configureStoreCategory创建StoreQueue对象;
(4) 多个分类:先调用针对分类列表的调用创建一个StoreQueue对象副本,后然根据分类的数量依次拷贝这个副本创建StoreQueue对象;
(5) 每创建一个StoreQueue对象就对这个对象计数的变量numstores加1操作;
(6) 在configureStoreCategory函数中首先确实是否是一个前缀分类,然后根据model是否为null来决定是拷贝一个StoreQueue对象还是新建一个StoreQueue对象。如果是拷贝,判断是否为每一个分类都创建一个线程并且不是默认的分类和前缀分类,如果是就调用StoreQueue的拷贝构造函数生成一个StoreQueue对象;如果不满足条件就直接赋值表示已经存在分类了。如果是新建就根据各种条件生成新建需要的各个参数值调用StoreQueue构造函数生成新对象。接着如果是拷贝的就直接打开StoreQueue(调用StoreQueue的open),否则需要配置在打开(调用StoreQueue的configureAndOpen)。最后将相应的分类或前缀分类存放入对象的map中,把新建StoreQueue对象也存放入StoreQueue向量中。
7. StoreQueue功能详解
(1) 在4中的(6)中介绍了在configureStoreCategory函数中分别用了构造函数和拷贝构造函数创建StoreQueue对象;
(2) 在StoreQueue构造函数中用初始化列表初始化了各个配置变量,然后调用Store的全局createStore函数创建一个Store对象(后面详解Store模块功能),最后调用storeInitCommon函数初始化用于多线程的互斥和条件变量并创建启动线程(model为true不创建);拷贝构造实现同样功能,只是很多配置变量的初始化直接拷贝;
(3) 一个全局的线程入口函数threadStatic,参数为一个StoreQueue对象,启动这个线程以后,每个StoreQueue对象调用自己的线程成员函数;
(4) 线程成员函数threadMember开始执行,初始化最后一次检查存储的时间为0和最后一次处理消息为当前时间,然后开始处理命令(StoreCommand描述,这里处理三种CMD_OPEN、CMD_CLOSE和CMD_CONFIGURE),如果是CMD_CONFIGURE命令就会启动在线配置(调用函数configureInline实现),在线配置会针对具体的存储类型配置相应的存储类型(例如是file存储就会配置file存储相应的参数),调用Store的confige实现(动态绑定到具体的实现类)。接着根据设置的检查存储的时间间隔看是否超过,超过就开始执行存储检查(实现函数是Store的periodicCheck,同样利用多态动态绑定)。下面继续执行处理消息的任务,两种情况下都需要处理消息:一是超过了设置的最大写入时间间隔;二是消息长度超过了设置的目标长度(缓存功能),如果有失败的消息没有处理就先处理失败的消息。处理消息是调用Store的handleMessages函数,如果处理失败调用StoreQueue的processFailedMessages函数将处理失败的消息保存起来,以便下次继续处理,防止消息(或数据)丢失。最后没有需要处理的消息或命令时让本线程挂起等待,并根据设置的存储检查时间为等待设置超时,以便能够定期检查存储。
(5) 线程函数在没有收到CMD_STOP命令会一直执行下去。
8. Store以及各个继承子类代码详解
(1) store类:函数createStore根据存储类型创建相应的子类对象,其他的实现的方法都很简单,一句话的事,一看就明白,具体处理消息的方法在相应的子类中实现。
(2) FileStoreBase类:
a) 这个是文件存储共同的基类,不同的文件格式写入具体的子类实现;
b) 它的构造函数用函数初始化列表初始化了所有的文件存储的配置参数,config函数对默认的参数进行重新配置,copyCommon函数复制已有对象的配置信息参数;
c) Open函数调用子类具体openInternal函数,具体实现子类中介绍;
d) periodicCheck函数检查是否符合滚动文件,如果满足调用滚动文件函数rotateFile;
e) rotateFile函数调用printStatus函数根据配置是否记录滚动状态的信息来决定是否创建并写入状态信息到状态文件,然后调用子类openInternal函数滚动文件创建;
f) 其他一些基本函数实现功能:根据时间配置信息制作完全文件名,制作基本文件名,找最新和最旧文件,制作符号链接的完全文件名和基本文件名,找到文件后缀,对齐到块大小,设置主机子目录。
(3) FileStore类:
a) 此类继承FileStoreBase类,构造函数调用基类构造函数初始化基本配置信息,然后初始化列表初始化此类单独用的配置参数信息,config函数重新配置默认的参数信息
b) openInternal函数根据滚动类型(rollPeriod)配置和当前的时间新建存储的文件名,并根据需要创建相应目录、符号链接文件和缓存文件;根据创建过程返回信息设置状态信息等;文件和目录的创建都是通过FileInterface类提供的接口完成了,具体创建哪种类型的文件(目前只支持STD和hdfs)由子类实现;
c) 处理消息函数handleMessages是重点功能,首先它确保文件打开,然后调用writeMessages函数将消息写入文件;
d) writeMessages函数执行具体的写入过程,根据配置组合需要写入消息的字符串通过FileInterface类的write方法写入文件;
e) 其他函数功能:删除、替换和读最老文件,判断一个时间点的文件是否为空等。
(4) ThriftFileStore类:和FileStore类的功能基本相同。
(5) BufferStore类:
a) 构造函数和config参数配置函数和其他存储类都是同样的功能,只是初始化和配置的参数都是各自存储需要的,本类的配置涉及到主从存储的配置,配置好以后就调用createStore创建对于的存储类型,然后根据主从配置采用的存储类型在调用相应的config配置函数;copy函数复制本类以创建好的一个对象及它的配置信息;
b) changeState函数改变buffer存储的当前状态(三种:STREAMING、DISCONNECTED和SENDING_BUFFER),每种状态下处理消息是不同的,所以这个状态也很重要;
c) handleMessages函数就是处理消息,根据不同的状态信息做不同的消息处理,分别调用主存储和从从存储的消息处理函数;这里面有很重要的一点内容是:如果我们设置了自适应算法确定的重试时间的参数,就会调用函数setNewRetryInterval来设置具体的重试时间。这个消息处理函数首先用主存储来处理消息,如果处理失败改变状态,后面状态改变了就会执行从存储来处理消息。
d) setNewRetryInterval函数设置重试时间;
e) periodicCheck函数:定期检查存储函数;首先检查主从存储的存储,不同的存储类型有不同的检查功能;如果现在处于DISCONNECTED状态并且现在的时间减去最后一次尝试打开的时间大于重试时间,就尝试重新打开主存储(因为当主存储不可用的情况下才会进入DISCONNECTED状态),根据打开结果重新设置现在的状态;如果是SENDING_BUFFER状态并且是刷新流,就判断存储队列的大小是否大于设置的最大存储队列大小乘以设置的某个百分比,如果大于直接返回了保持现在的状态,以便有时间让消息可以直接发生到主存储处理,不用在到本地缓存,提高了一定的效率;后面接着读取本地缓存中的文件数据并交给主存储处理,如果处理成功就删除本地缓存,否则将这些没有成功处理的消息重新放回文件,以便以后处理,如果放回本地缓存出错,这些消息就丢失,报告一个数据丢失的信息;
f) 其他功能函数:打开、关闭和判断是否打开等。
(6) NetworkStore类:
a) 配置、构造函数、copy、open、isOpen、close等和其他存储分类功能相似;
b) periodicCheck函数唯一功能就是定期检查服务器的IP和端口是否改变,如果改变先关闭链接,然后重新设置IP和端口,最后在重新打开链接;
c) handleMessages函数,如果消息的长度大于设置的瓶颈值就先发送一个空的消息测试;发送根据配置选择是否使用连接池。
(7) BucketStore类:
a) 配置、构造函数、copy、open、isOpen、close等和其他存储分类功能相似;
b) createBuckets和createBucketsFromBucket函数根据配置参数和规则创建相应的存储目录和文件,为每个配置的bucket创建配置的存储并配置;
c) periodicCheck函数:先就bucket的数量生成随机数序列,然后根据这个序列一次调用每个bucket配置的相应存储类型存储检查函数;
d) handleMessages函数:首先调用bucketize函数(根据不同配置有不同的算法确定)确定写入哪一个bucket,然后判断是否需要移除消息里面的key,需要就移除后写入,不需要就直接写入;如果写入失败把消息保存起来。
(8) NullStore类:不将消息记录下来,只是简单的留下一个被忽略的记录。
(9) MultiStore类:
a) 配置、构造函数、copy、open、isOpen、close等和其他存储分类功能相似;
b) periodicCheck函数:
c) handleMessages函数:分别调用每一个存储相应的消息处理函数,根据配置决定是有一个处理成功就是成功还是所有的处理成功才算成功;
(10) CategoryStore类:分别调用每一个存储相应的存储检查函数。
(11) MultiFileStore类:只有框架,还没有具体实现什么功能!
(12) ThriftMultiFileStore类:只有框架,还没有具体实现什么功能!
9. File相关(FileInterface、StdFile和HdfsFile)
a) 这几个类主要实现了文件系统的常用操作,比如创建文件、打开和关闭文件、计算文件长度等;
b) 实现文件系统常用功能主要使用的是boost库里面处理文件系统的部分库函数(boost::filesystem);
c) 这些类是最终实现消息写入文件的地方,和我们平时直接读写文件类似,前面几个模块介绍了怎样一步一步到达最后这里,前面消息基本上都是在缓存中处理。
10.总结:今天把以前自己分析scribe的源码的文档与大家分享了,里面并没有涉及到具体的源代码,算不上真正的源代码分析,主要介绍了一些源码实现的功能,有了这些功能说明,你去看源代码可能会更加快捷一些!粘贴一些源码本来不是什么费劲的事情,但是我觉得看源代码最好还是完整的看或者至少是一个完整的模块的去看更好,更能体会源码设计者的思路、思想和编码技巧。如果你想更深入理解学习scribe的原理并通过源码去分析上一篇博文提到的各种配置选项的用作,那么你可以结合本篇更加详细去分析scribe源代码!源代码可以到google上搜索!