oceanbase之RootServer(三)
琐事太多,又太懒了,好久不想动笔,进展也比较慢。
5 日志系统
有伟大的GFS作指引,OceanBase的master也是采用redo log加checkpoint机制,以保证master的响应速度。此外root server采取了主备机制,因此redo log一写两份, 在flush redolog时先写slave,成功了才写master并重置log的内存缓存区。
日志系统是比较核心的一块,这块的体量也不小。慢慢看吧。
5.1 类图
首先来一张类图,列示日志系统涉及到的类,显然我们需要从ObRootLogManager这个类入手。
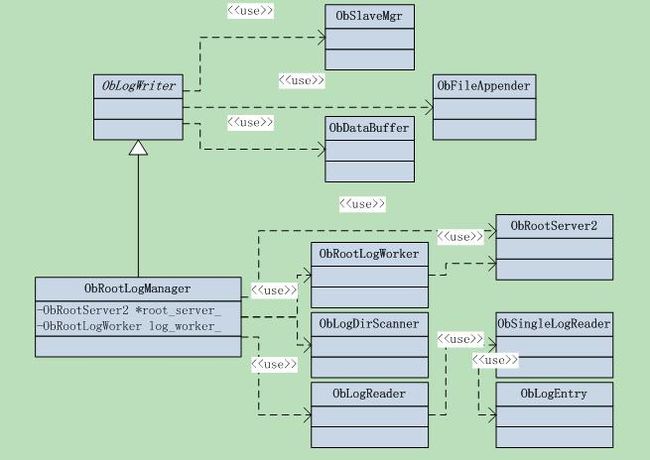
先来整理这几个类之间的关系,ObRootLogWorker向Root Server提供了写入各种系统log的接口,比如registerchunk server的regist_cs(),register merge server的regist_ms(),增加tablet的add_new_tablet()等等。
ObRootLogManager,如其名,日志管理器。主要就是日志系统初始化和回放log,以及做checkpoint,管理log目录等信息。
ObRootLogManager又继承了ObLogWriter,ObLogWriter是写log file的底层类。所以ObRootLogWorker写log的接口如regist_cs(),最终都是通过调用ObRootLogManager完成的,它看不到ObLogWriter。这种设计风格因人而异,最终结果大同小异。
5.2 LogManager初始化
接着上面master启动的流程,看看日志系统初始化和replay log的逻辑。初始化流程相对简单。Logmanager会在initialize时调用OpLogDirScanner扫描日志目录,取得log id和checkpoint id。
5.2.1 Scanner扫描
另外,log id和checkpoint id都是数字。Scanner将log id排序,得到最小和最大的log id,以及最大的checkpoint id,作为状态基点。
Scnner从最大id向前检查,如果碰到不连续的id,则跳出;
1 如果log文件集合为空,则设置max min log id为0,返回OK;
2 log文件id连续,最正常的情况,返回OK;
3 log文件id不连续,举个例子:2,3,5,6,7,8;那么此时在5处开始不连续了,min log id就等于5;并返回OB_DISCONTINUOUS_LOG。
5.2.2 获取扫描状态
1没有checkpoint
设置replay_point_ = 1;如果log为空,则设置max_log_id_ = 1;否则根据结果取出max log id,scanner.get_max_log_id(max_log_id_);
2 有checkpoint
scanner.get_max_ckpt_id(ckpt_id_),合法性检查,如果min log id > ckpt_id_+1,则表明有错误;
设置replay_point_ = ckpt_id_ + 1;
后面从checkpoint恢复后,master还将从id为replay_point_的log开始回放日志,以到达最终状态。
5.3 LogManager回放日志
5.3.1 回放逻辑
初始化之后,紧接着就是replay 日志了,这又有几个步骤。
1 从checkpoint文件读取server 状态,文件的第一个32byte是server的状态字段。
load_server_status()
2 执行成功就调用ObRootServer2接口从最近的checkpoint恢复状态
root_server_->recover_from_check_point(rt_server_status_,ckpt_id_)这块逻辑比较多,后面再详细分析。
3 恢复成功后,就调用do_after_recover_check_point(),它就是启动root_server_,并等待root_server_初始化完成。
4 调用ObLogReader从replay_point_开始读取日志并回放。
从这里也可以看明白了,checkpoint和log的id号都是严格按照事件顺序生产的。如果checkpoint的id为5,那么表明所有id>5的log都是在checkpoint之后生产的,其操作的结果都在checkpoint之后。
接下来看看日志回放的逻辑,这需要借助于ObLogReader完成redo log的读取。在当前log 读完后,ObLogReader会自动打开并读取下一个log文件(log id + 1)。
log_reader.init(log_dir_,replay_point_, 0, false);
log_reader.read_log(cmd,seq, log_data, log_length);
主要就是循环读取,每读到一条log entry,就调用log worker回放日志。
while (ret == OB_SUCCESS) {
set_cur_log_seq(seq);
if (OB_LOG_NOP != cmd)
ret = log_worker_.apply(cmd, log_data, log_length);
ret = log_reader.read_log(cmd,seq, log_data, log_length);
} // end while
// handle exception, when the last log filecontain SWITCH_LOG entry
// but the next log file is missing
if(OB_FILE_NOT_EXIST == ret) {
max_log_id_++;
ret = OB_SUCCESS;
}
// reach the end ofcommit log
if(OB_READ_NOTHING == ret) ret = OB_SUCCESS;
这两个函数都很简单,来看原型:
init(constchar* log_dir, const uint64_t log_file_id_start,
const uint64_t log_seq,boolis_wait)
read_log(LogCommand &cmd,uint64_t &seq, char* &log_data, int64_t &data_len)
其中seq表明从哪一条log开始读,read_log会把读取的log entry的seq赋予参数seq传出来;参数cmd是log类型。
日志回放的主体逻辑就这么多,不过我们还欠了不少功课,包括:
1 日志文件格式和读取;
2负责日志回放的类ObRootLogWorker;
3 从checkpoint恢复状态;
5.3.2 完整日志文件的结束标志
OB_LOG_SWITCH_LOG这条日志用来标记一个完整日志文件的结尾,在ObRootLogManager的读取回放循环中,如果最后一条记录不是OB_LOG_SWITCH_LOG,将会被认为是最后一个日志文件,read_log返回OB_READ_NOTHING,于是循环停止,Root server认为回放完成;
如果遇到OB_LOG_SWITCH_LOG记录,read_log函数会自动切换到下一个日志文件,并尝试读取;
5.4 日志log格式&读取&校验
实际上真正的log文件读取由ObLogReader通过调用ObSingleLogReader完成,一个注意点就是它使用的是dio的文件接口,这个类的主要操作逻辑在read_log和read_log_两个函数里。
5.4.1 日志格式
先来看看log的格式,首先是logheader,长度是256byte,分别是:
int16_t magic_; // magicnumber,固定值
int16_t header_length_; // header length= sizeof(log header struct)
int16_t version_; // version
int16_t header_checksum_;// header checksum
int64_t reserved_; //reserved,must be 0
int32_t data_length_; // lengthbefore compress
int32_t data_zlength_; // length aftercompress, if without compresssion
// data_length_=data_zlength_
int64_t data_checksum_; // record checksum
其后是
int64_tseq // 本条log entry的seq no
int32_tcmd;// 本条log entry的命令类型
最后就是log entry的内容了。
5.4.2 读取log entry和校验
前面讲过主要逻辑在ObSingleLogReader的read_log和read_log_中,简单点来说就是读取文件内容到一个循环使用的buffer中,然后调用OpLogEntry的deserialize()接口反向序列log header、seq和cmd;如果序列化失败,说明内容不是一个完整的entry header,继续读取文件内容到buffer中,再次尝试。
每次调用都期望读取到buffer可用大小的数据。
代码实现并没有压缩log,因此接下来的data_zlength – sizeof(cmd) –sizeof(seq)就是实际的log内容。
读取到一条完整的log entry就返回,并做正确性检查。反序列化、检查逻辑都在类ObLogEntry中。
这两个函数被ObLogReader调用,顺便来看看相关的函数。
intObLogReader::read_log(LogCommand &cmd, uint64_t &seq,
char* &log_data, int64_t&data_len)
该函数尝试读取log entry,如果遇到OB_LOG_SWITCH_LOG日志,则自动切换到下一个log文件,尝试读取。逻辑如下,这里省去了错误处理逻辑。
ret = read_log_(cmd, seq,log_data, data_len);
while (OB_SUCCESS == ret&& OB_LOG_SWITCH_LOG == cmd) {
ret = log_file_reader_.close();
cur_log_file_id_ ++;
ret = open_log_(cur_log_file_id_, seq);
ret = log_file_reader_.read_log(cmd, seq,log_data, data_len);
}
而其中的read_log_,则是直接调用ObSingleLogReader的read_log()函数。
5.4.3 校验
正确性检查就是分别对header和body做校验和,校验和在创建填充log entry的时候生成。
其中header的校验和借鉴了TCP的做法,是header各个字段每16byte做XOR运算的结果;body的校验和是CRC64,先对seq做CRC64,得到的结果和cmd做CRC64,得到的结果再和log data做CRC64运算。
5.5 ObRootLogWorker概览
如前面所示,主要调用入口就是
apply(common::LogCommand cmd,const char* log_data, const int64_t& data_len)
该函数根据不同的cmd执行不同的处理流程,
所有的具体处理流程都在对应的do_xxx系列函数中,这些函数被定义为public,而实际上,只会在本类内调用。
具体处理流程还应该在相应的场景中分析才能理清上下文,抛开整体流程,孤立的分析处理流程是不合适的。
ObRootLogWorker对日志的回放最终都是调用ObRootServer2 root_server_这个成员变量完成的。
有必要先对LogCommand做一个了解。日志类型定义在LogCommand中,文件common/ob_log_entry.h中,这是一个enum类型。摘录几个类型:
OB_LOG_SWITCH_LOG = 101, //日志切换命令
OB_LOG_CHECKPOINT = 102, //checkpoint操作
OB_RT_CS_REGIST = 401, // chunk server注册
OB_RT_ADD_NEW_TABLET = 409, // 添加新的tablet
文件定义了超过20种日志类型,遇到时再具体分析。
5.6 写入日志
在后面分析root server时将会看到,最终所有类型的日志都是通过flush_log函数写入的。其函数原型为:
intObRootLogWorker::flush_log(const LogCommand cmd, const char* log_data,
const int64_t& serialize_size)
函数flush_log,就两行代码:加锁,调用log manager flush flog。
tbsys::CThreadGuardguard(log_manager_->get_log_sync_mutex());
log_manager_->write_and_flush_log(cmd,log_data, serialize_size);
函数write_and_flush_log继承自ObLogWriter,来看看函数实现。
ret = write_log(cmd, log_data,data_len);
ret = flush_log();
在write_log中,如果当前日志文件大小超过了设置的值,将会触发switch log操作,切换日志文件。
切换日志文件时,首先调用flush_log(),刷新当前日志;然后生产一条SWITCH的日志记录,再次flush当前日志;类型为OB_LOG_SWITCH_LOG,并且日志seq等于当前seq,而其它日志seq都是当前seq+1,递增的。OB_LOG_SWITCH_LOG这条日志用来标记一个完整日志文件的结尾。
最后打开新的日志文件,文件id等于当前文件id+1。
接着再看flush_log()这个函数,基本逻辑就4行代码。
ret = serialize_nop_log_();
ret =slave_mgr_->send_data(log_buffer_.get_data(), log_buffer_.get_position());
ret = store_log(log_buffer_.get_data(),log_buffer_.get_position());
if (OB_SUCCESS == ret) log_buffer_.get_position() = 0;
1 函数serialize_nop_log_是干什么的呢,还记得前面说过oceanbase使用的是dio文件吗,因此每次写入必须保证是对齐的。如果没有对齐,就构造一个OB_LOG_NOP类型的日志,对其到边界。
2 向slave发送日志,比较土;多个slave,就依次发送,由ObSlaveMgr完成。ObSlaveMgr很简单,管理注册的salve server,后面单独讲讲。
3 只要有一部分slave发送成功了,就调用store_log,以append方式追加写入文件,写入成功就清空buffer。