Impala是如何提升3~90倍查询效率的
Impala是如何提升3~90倍查询效率的?
存储,学习,共享
【CSDN编译】正如CSDN此前的报道,Cloudera Impala是基于Hadoop的实时检索引擎开源项目,其 效率较Hive提升3~90倍,详见Cloudera的 blog。
为什么是代码生成?
这一切的基础是最优的查询引擎一定是原生的应用,因为它们针对你的数据格式而开发,而且仅仅支持你的查询。举个例子,这是一个理想的代码:
- select count(*)
- from tbl
- where col like %XYZ%
另一个例子,select sum(col) from tbl。如果表格只有一个int64的列,使用little endian编码,这可以通过专用的应用来运行:
- int64_t sum = 0;
- int64_t* values = (int64_t*)buffer;
- for (int i = 0; i < num_rows; ++i) {
- sum += values[i];
- }
增加的运行成本来自:
- 调用虚函数。没有编译就解释执行表达式(例如col1 + col2 < col3),致使在每个表达式上产生虚函数调用。(这当然依赖于安装启用,但是我们,也可能包括大多数其它人采用一种类似“Eval”函数,每一个操作符都会生效。)在这种情况下,表达式自身占用资源很少,但虚函数调用的资源占用是很多的。
- 各种类型的大的代码分支判断,操作符,以及没有被查询引用的函数。分支预测器可以缓和这类问题,但同时分支指令会阻止流水线的效率以及指令集的并行性。
- 不能传送所有的常量。Impala能计算一个固定宽度的元组格式(列3字节偏移值为16)。好处是这些常量不用重复写入代码,而不用在内存中去查找。
生成代码的目标就是让每个查询都使用同样数量的指令,就像定制代码一样,因为查询执行支持广泛的功能, 工具可以精确的匹配查询,而并不需要额外的资源。
LLVM介绍
(略,详见 原文。)
Impala的IR(Intermediate Representation)使用
在SQL语义分析阶段后,我们为查询的操作符生成独立的“内核”代码:这意味着代码内部循环花费了大部分CPU周期。在代码生成的时候,我们知道所有类型,包括元组的布局、SQL操作以及表达式都将用于这个查询。其结果是非常紧密的内循环并与所有函数调用内联,并且没有外来的指令。
我们首先需要得到IR函数对象的代码路径。LLVM提供两种机制生成IR。第一种是使用LLVM的IrBuilder (C++) API,通过它编程生成IR, 逐条按指令产生。第二种方式是是用Clang的编译器将C++源码转换成IR。Impala同时使用这两种方式。
简单的说,关于执行代码生成,我们:
- 通过IRBuilder生成IR,可以获得更高效率的代码以及附加的运行时间信息。
- 我们需要为函数读取预编译的IR,但不会从运行时间信息中获取价值。
- 通过同时使用以上的1和2方法来置换调用的函数。这让我们可以把本应该用虚函数实现的地方改用内联来实现。
- LLVM优化随同一些我们定制的优化一同进行。这与将你的代码进行优化编译很相似,要考虑很多事情。除了可以有更少的代码,这一步还可以帮助去掉子表达式、常量传播、更多函数插入、指令重排序、无用代码去除以及其它编译优化技术。
- 运行时进行编译执行优化将IR转换到机器编码。LLVM返回一个函数指针,用于替代请求引擎的解释函数。
实例和结果
关于代码生成话题,我们讨论最多的问题是究竟可以提升多少速度?性能有多大变化?
这是一个运行 TPCH-Q1查询的测试,该集群拥有10个数据节点,每个节点有10块硬盘、48GB内存以及8核CPU(16个超线程)。查询代码如下:
- select
- l_returnflag,
- l_linestatus,
- sum(l_quantity),
- sum(l_extendedprice),
- sum(l_extendedprice * (1 - l_discount)),
- sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)),
- avg(l_quantity),
- avg(l_extendedprice),
- avg(l_discount),
- count(1)
- from
- tpch.lineitem
- where
- l_shipdate<='1998-09-02'
- group by
- l_returnflag,
- l_linestatus
我们将关注点放到聚合这步。对于哈希聚合,我们一批一批的对元组进行迭代,评估并哈希分组列(l_returnflags and l_linestatus),检查哈希表,然后评估聚合表达式(求和、平均值以及select的元素个数)。对于聚合的操作符,代码生成阶段编译所有的行组进入一个独立的完整内联循环的评估逻辑。
我们将在两个不同大小的数据集上运行这个查询,首先将在1TB的数据集上运行,接下来在100GB的数据集上运行。文件顺序用 Snappy块压缩。对于100GB的数据集,它足够小以适应集群的操作系统缓存。这可以防止可能出现的磁盘性能瓶颈。
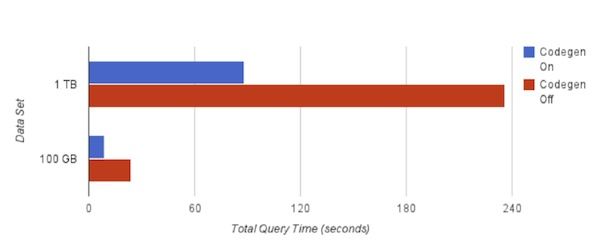
对于这两个数据集,代码生成可以减少2/3的查询时间。所有的生成代码的时间大约150ms。(生成代码可以通过设置查询时的参数打开或关闭,所以你可以做同样的测试。你可以通过在Impala的shell中输入‘set’来查看查询选项。) 为了更长远的生成代码所带来的好处,我们可以对比更详细的数值。在这里例子中,查询运行在一台服务器上,它的数据集小得多(只有700MB)。使用 perf stat工具,它通过概括精简的方式提供被调试程序运行的整体情况和汇总数据。结果来自5次查询后的汇总。

你能发现,没有代码生成的情况下,我们的指令运行了两次,分支错误多过了两倍。
结论
我们在代码生成的投资已经获得回报,同时也期望通过持续的升级查询引擎获得更好的新能提升。对于列式数据格式,将有更高效的编码,以及更大的(内存)缓存,我们期待I/O性能戏剧性的提升,这导致CPU的性能越来越重要。
代码生成对执行简单表达式的查询性能非常有帮助。例如,一个使用常用表达式的查询对每一行的性能提升不会很明显,因为解释成本要少于正则表达式的运行时间。
目前的Impala 0.5版里仍然还有部分执行路径没有被转化为本地代码,我们还没有时间来完成。大部分的代码补丁将会集成在即将推出的GA发行版中。我们有很多方法,让GA发行版的代码生成发挥最大的优势。(编译/包研 责编/仲浩)