linux内存源码分析 - 零散知识点
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/
直接内存回收中的等待队列
内存回收详解见linux内存源码分析 - 内存回收(整体流程),在直接内存回收过程中,有可能会造成当前需要分配内存的进程被加入一个等待队列,当整个node的空闲页数量满足要求时,由kswapd唤醒它重新获取内存。这个等待队列头就是node结点描述符pgdat中的pfmemalloc_wait。如果当前进程加入到了pgdat->pfmemalloc_wait这个等待队列中,那么进程就不会进行直接内存回收,而是由kswapd唤醒后直接进行内存分配。
直接内存回收执行路径是:
__alloc_pages_slowpath() -> __alloc_pages_direct_reclaim() -> __perform_reclaim() -> try_to_free_pages() -> do_try_to_free_pages() -> shrink_zones() -> shrink_zone()
在__alloc_pages_slowpath()中可能唤醒了所有node的kswapd内核线程,也可能没有唤醒,每个node的kswapd是否在__alloc_pages_slowpath()中被唤醒有两个条件:
- 分配标志中没有__GFP_NO_KSWAPD,只有在透明大页的分配过程中会有这个标志。
- node中有至少一个zone的空闲页框没有达到 空闲页框数量 >= high阀值 + 1 << order + 保留内存,或者有至少一个zone需要进行内存压缩,这两种情况node的kswapd都会被唤醒。
而在kswapd中会对node中每一个不平衡的zone进行内存回收,直到所有zone都满足 zone分配页框后剩余的页框数量 > 此zone的high阀值 + 此zone保留的页框数量。kswapd就会停止内存回收,然后唤醒在等待队列的进程。
之后进程由于内存不足,对zonelist进行直接回收时,会调用到try_to_free_pages(),在这个函数内,决定了进程是否加入到node结点的pgdat->pfmemalloc_wait这个等待队列中,如下:
unsigned long try_to_free_pages(struct zonelist *zonelist, int order, gfp_t gfp_mask, nodemask_t *nodemask) { unsigned long nr_reclaimed; struct scan_control sc = { /* 打算回收32个页框 */ .nr_to_reclaim = SWAP_CLUSTER_MAX, .gfp_mask = (gfp_mask = memalloc_noio_flags(gfp_mask)), /* 本次内存分配的order值 */ .order = order, /* 允许进行回收的node掩码 */ .nodemask = nodemask, /* 优先级为默认的12 */ .priority = DEF_PRIORITY, /* 与/proc/sys/vm/laptop_mode文件有关 * laptop_mode为0,则允许进行回写操作,即使允许回写,直接内存回收也不能对脏文件页进行回写 * 不过允许回写时,可以对非文件页进行回写 */ .may_writepage = !laptop_mode, /* 允许进行unmap操作 */ .may_unmap = 1, /* 允许进行非文件页的操作 */ .may_swap = 1, }; /* * Do not enter reclaim if fatal signal was delivered while throttled. * 1 is returned so that the page allocator does not OOM kill at this * point. */ /* 当zonelist中获取到的第一个node平衡,则返回,如果获取到的第一个node不平衡,则将当前进程加入到pgdat->pfmemalloc_wait这个等待队列中 * 这个等待队列会在kswapd进行内存回收时,如果让node平衡了,则会唤醒这个等待队列中的进程 * 判断node平衡的标准: * 此node的ZONE_DMA和ZONE_NORMAL的总共空闲页框数量 是否大于 此node的ZONE_DMA和ZONE_NORMAL的平均min阀值数量,大于则说明node平衡 * 加入pgdat->pfmemalloc_wait的情况 * 1.如果分配标志禁止了文件系统操作,则将要进行内存回收的进程设置为TASK_INTERRUPTIBLE状态,然后加入到node的pgdat->pfmemalloc_wait,并且会设置超时时间为1s * 2.如果分配标志没有禁止了文件系统操作,则将要进行内存回收的进程加入到node的pgdat->pfmemalloc_wait,并设置为TASK_KILLABLE状态,表示允许 TASK_UNINTERRUPTIBLE 响应致命信号的状态 * 返回真,表示此进程加入过pgdat->pfmemalloc_wait等待队列,并且已经被唤醒 * 返回假,表示此进程没有加入过pgdat->pfmemalloc_wait等待队列 */ if (throttle_direct_reclaim(gfp_mask, zonelist, nodemask)) return 1; trace_mm_vmscan_direct_reclaim_begin(order, sc.may_writepage, gfp_mask); /* 进行内存回收,有三种情况到这里 * 1.当前进程为内核线程 * 2.最优node是平衡的,当前进程没有加入到pgdat->pfmemalloc_wait中 * 3.当前进程接收到了kill信号 */ nr_reclaimed = do_try_to_free_pages(zonelist, &sc); trace_mm_vmscan_direct_reclaim_end(nr_reclaimed); return nr_reclaimed; }
主要通过throttle_direct_reclaim()函数判断是否加入到pgdat->pfmemalloc_wait等待队列中,主要看此函数:
/* 当zonelist中第一个node平衡,则返回,如果node不平衡,则将当前进程加入到pgdat->pfmemalloc_wait这个等待队列中 * 这个等待队列会在kswapd进行内存回收时,如果让node平衡了,则会唤醒这个等待队列中的进程 * 判断node平衡的标准: * 此node的ZONE_DMA和ZONE_NORMAL的总共空闲页框数量 是否大于 此node的ZONE_DMA和ZONE_NORMAL的平均min阀值数量,大于则说明node平衡 * 加入pgdat->pfmemalloc_wait的情况 * 1.如果分配标志禁止了文件系统操作,则将要进行内存回收的进程设置为TASK_INTERRUPTIBLE状态,然后加入到node的pgdat->pfmemalloc_wait,并且会设置超时时间为1s * 2.如果分配标志没有禁止了文件系统操作,则将要进行内存回收的进程加入到node的pgdat->pfmemalloc_wait,并设置为TASK_KILLABLE状态,表示允许 TASK_UNINTERRUPTIBLE 响应致命信号的状态 */ static bool throttle_direct_reclaim(gfp_t gfp_mask, struct zonelist *zonelist, nodemask_t *nodemask) { struct zoneref *z; struct zone *zone; pg_data_t *pgdat = NULL; /* 如果标记了PF_KTHREAD,表示此进程是一个内核线程,则不会往下执行 */ if (current->flags & PF_KTHREAD) goto out; /* 此进程已经接收到了kill信号,准备要被杀掉了 */ if (fatal_signal_pending(current)) goto out;
/* 遍历zonelist,但是里面只会在获取到第一个pgdat时就跳出 */ for_each_zone_zonelist_nodemask(zone, z, zonelist, gfp_mask, nodemask) { /* 只遍历ZONE_NORMAL和ZONE_DMA区 */ if (zone_idx(zone) > ZONE_NORMAL) continue; /* 获取zone对应的node */ pgdat = zone->zone_pgdat; /* 判断node是否平衡,如果平衡,则返回真 * 如果不平衡,如果此node的kswapd没有被唤醒,则唤醒,并且这里唤醒kswapd只会对ZONE_NORMAL以下的zone进行内存回收 * node是否平衡的判断标准是: * 此node的ZONE_DMA和ZONE_NORMAL的总共空闲页框数量 是否大于 此node的ZONE_DMA和ZONE_NORMAL的平均min阀值数量,大于则说明node平衡 */ if (pfmemalloc_watermark_ok(pgdat)) goto out; break; } if (!pgdat) goto out; count_vm_event(PGSCAN_DIRECT_THROTTLE); if (!(gfp_mask & __GFP_FS)) { /* 如果分配标志禁止了文件系统操作,则将要进行内存回收的进程设置为TASK_INTERRUPTIBLE状态,然后加入到node的pgdat->pfmemalloc_wait,并且会设置超时时间为1s * 1.pfmemalloc_watermark_ok(pgdat)为真时被唤醒,而1s没超时,返回剩余timeout(jiffies) * 2.睡眠超过1s时会唤醒,而pfmemalloc_watermark_ok(pgdat)此时为真,返回1 * 3.睡眠超过1s时会唤醒,而pfmemalloc_watermark_ok(pgdat)此时为假,返回0 * 4.接收到信号被唤醒,返回-ERESTARTSYS */ wait_event_interruptible_timeout(pgdat->pfmemalloc_wait, pfmemalloc_watermark_ok(pgdat), HZ); goto check_pending; } /* Throttle until kswapd wakes the process */ /* 如果分配标志没有禁止了文件系统操作,则将要进行内存回收的进程加入到node的pgdat->pfmemalloc_wait,并设置为TASK_KILLABLE状态,表示允许 TASK_UNINTERRUPTIBLE 响应致命信号的状态 * 这些进程在两种情况下被唤醒 * 1.pfmemalloc_watermark_ok(pgdat)为真时 * 2.接收到致命信号时 */ wait_event_killable(zone->zone_pgdat->pfmemalloc_wait, pfmemalloc_watermark_ok(pgdat)); check_pending: /* 如果加入到了pgdat->pfmemalloc_wait后被唤醒,就会执行到这 */ /* 唤醒后再次检查当前进程是否接受到了kill信号,准备退出 */ if (fatal_signal_pending(current)) return true; out: return false; }
有四点需要注意:
- 当前进程已经接收到kill信号,则不会将其加入到pgdat->pfmemalloc_wait中。
- 只获取第一个node,也就是当前进程最希望从此node中分配到内存。
- 判断一个node是否平衡的条件是:此node的ZONE_NORMAL和ZONE_DMA两个区的空闲页框数量 > 此node的ZONE_NORMAL和ZONE_DMA两个区的平均min阀值。如果不平衡,则加入到pgdat->pfmemalloc_wait等待队列中,如果平衡,则直接返回,并由当前进程自己进行直接内存回收。
- 如果当前进程分配内存时使用的标志没有__GFP_FS,则加入pgdat->pfmemalloc_wait中会有一个超时限制,为1s。并且加入后的状态是TASK_INTERRUPTABLE。
- 其他情况的进程加入到pgdat->pfmemalloc_wait中没有超时限制,并且状态是TASK_KILLABLE。
如果进程加入到了node的pgdat->pfmemalloc_wait等待队列中。在此node的kswapd进行内存回收后,会通过再次判断此node是否平衡来唤醒这些进程,如果node平衡,则唤醒这些进程,否则不唤醒。实际上,不唤醒也说明了node没有平衡,kswapd还是会继续进行内存回收,最后kswapd实在没办法让node达到平衡水平下,会在kswapd睡眠前,将这些进程全部进行唤醒。
zone的保留内存
之前很多地方说明到,判断一个zone是否达到阀值,主要通过zone_watermark_ok()函数实现的,而在此函数中,又以 zone当前空闲内存 >= zone阀值(min/low/high) + 1 << order + 保留内存 这个公式进行判断的,而对于zone阀值和1<<order都很好理解,这里主要说说最后的那个保留内存。我们知道,如果打算从ZONE_HIGHMEM进行内存分配时,使用的zonelist是ZONE_HIGHMEM -> ZONE_NORMAL -> ZONE_DMA,当ZONE_HIGHMEM没有足够内存时,就会去ZONE_NORMAL和ZONE_DMA进行分配,这样会造成一种情况,有可能ZONE_NORMAL和ZONE_DMA的内存都被本应该从ZONE_HIGHMEM分配的内存占完了,特定需要从ZONE_NORMAL和ZONE_DMA分配的内存则无法进行分配,所以内核设计了一个功能,就是让其他ZONE内存不足时,可以在本ZONE进行内存分配,但是必须保留一些页框出来,不能让你所有都用完,而应该从本ZONE进行分配的时候则没办法获取页框,这个值就保存在struct zone中:
struct zone { ...... long lowmem_reserve[MAX_NR_ZONES]; ...... }
注意是以数组保存这个必须保留的页框数量的,而数组长度是node中zone的数量,为什么要这样组织,其实很好理解,对于对不同的zone进行的内存分配,如果因为目标zone的内存不足导致从本zone进行分配时,会因为目标zone的不同而保留的页框数量不同,比如说,一次内存分配本来打算在ZONE_HIGHMEM进行分配,然后内存不足,最后到了ZONE_DMA进行分配,这时候ZONE_DMA使用的保留内存数量就是lowmem_reserve[ZONE_HIGHMEM];而如果一次内存分配是打算在ZONE_NORMAL进行分配,因为内存不足导致到了ZONE_DMA进行分配,这时候ZONE_DMA使用的保留内存数量就是lowmem_reserve[ZONE_NORMAL]。这样,对于这两次内存分配过程中,当对ZONE_DMA调用zone_watermark_ok()进行阀值判断能否从ZONE_DMA进行内存分配时,公式就会变为 zone当前空闲内存 >= zone阀值(min/low/high) + 1 << order + lowmem_reserve[ZONE_HIGHMEM] 和 zone当前空闲内存 >= zone阀值(min/low/high) + 1 << order + lowmem_reserve[ZONE_NORMAL]。这样就可能会因为lowmem_reserve[ZONE_HIGHMEM]和lowmem_reserve[ZONE_NORMAL]的不同,导致一种能够顺利从ZONE_DMA分配到内存,另一种不能够。而对于本来就打算从本zone进行内存分配时,比如本来就打算从ZONE_DMA进行内存分配,就会使用lowmem_reserve[ZONE_DMA],而由于zone本来就是ZONE_DMA,所以ZONE_DMA的lowmem_reserve[ZONE_DMA]为0,也就是,当打算从ZONE_DMA进行内存分配时,会使用zone_watermark_ok()判断ZONE_DMA是否达到阀值,而判断公式中的保留内存lowmem_reverve[ZONE_DMA]是为0的。同理,当本来就打算从ZONE_NORMAL进行内存分配,并通过zone_watermark_ok()对ZONE_NORMAL进行阀值判断时,会使用ZONE_NORMAL区的lowmem_reserve[ZONE_NORAML],这个值也是0。对于ZONE_NORMAL区而言,它的lowmem_reserve[ZONE_DMA]和lowmem_reserve[ZONE_NORMAL]为0,因为需要从ZONE_DMA进行内存分配时,即使内存不足也不会到ZONE_NORMAL进行分配,而由于自己又是ZONE_NORMAL区,所有这两个数为0;而对于ZONE_HIGHMEM,它的lowmem_reserve[]中所有值都为0,它不必为其他zone限制保留内存,因为其他zone当内存不足时不会到ZONE_HIGHMEM中进行尝试分配内存。
可以通过cat /proc/zoneinfo查看这个数组中的值为多少:
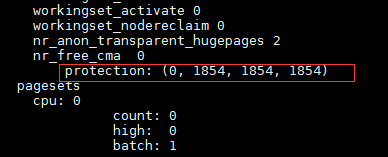
这个是我的ZONE_DMA的区的参数,可以看到,对应ZONE_DMA就是为0,然后ZONE_NORMAL和ZONE_HIGHMEM都为1854,最后一个是虚拟的zone,叫ZONE_MOVABLE。
对于zone保留内存的多少,可以通过/proc/sys/vm/lowmem_reserve_ratio进行修改。具体可见内核文档Documentation/sysctl/vm.txt,我的系统默认的lowmem_reserve_ratio如下:
![]()
这个256和32代表的是1/256和1/32。而第一个256用于代表DMA区的,第二个256代表NORMAL区的,第三个32代表HIGHMEM区的,计算公式是:
ZONE_DMA对于ZONE_NORMAL分配需要保留的内存:
zone_dma->lowmem_reserve[ZONE_NORMAL] = zone_normal.managed / lowmem_reserve_ratio[ZONE_DMA]
ZONE_DMA对于ZONE_HIGHMEM分配需要保留的内存:
zone_dma->lowmem_reserve[ZONE_HIGHMEM] = zone_highmem.managed / lowmem_reserve_ratio[ZONE_HIGHMEM]
drop_caches
在/proc/sys/vm/目录下有个drop_caches文件,可以通过将1,2,3写入此文件达到内存回收的效果,这三个值会达到不同的效果,效果如下:
- echo 1 > /proc/sys/vm/drop_caches:对干净的pagecache进行内存回收
- echo 2 > /proc/sys/vm/drop_caches:对空闲的slab进行内存回收
- echo 3 > /proc/sys/vm/drop_caches:对干净的pagecache和slab进行内存回收
注意只会对干净的pagecache和空闲的slab进行回收。干净的pagecache就是页中的数据与磁盘对应文件一致,没有被修改过的页,对于脏的pagecache,是不会进行回收的。而空闲的slab指的就是没有被分配给内核模块使用的slab。
先看看/proc/meminfo文件:
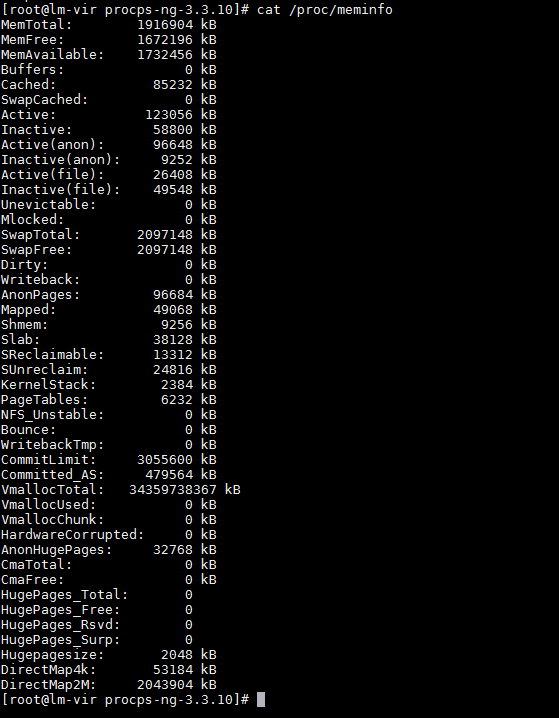
主要注意Buffers、Cached、Slab、Shmem这四行。
再看看free -k命令:

我们主要关注shared和buff/cache这两列。
- shared:记录的是当前系统中shmem使用的内存数量,对应meminfo的Shmem行。
- buff/cache:记录的是当前系统中buffers、cached、slab总共使用的内存数量。对应于meminfo中的Buffers + Cached + Slab。
然后我们通过free -k看看当前系统在使用echo 3 > /proc/sys/vm/drop_caches清空了pagecache和slab之后的情况:

这里为什么buff/cache在echo 3 > /proc/sys/vm/drop_caches后没有被清0,因为之前也说了,drop_caches只回收空闲的pagecache和空闲的slab。
之后使用shmem创建一个100M的shmem共享内存,再通过echo 3 > /proc/sys/vm/drop_caches清空pagecache和slab之后的情况:

很明显看出来,两次的shared相差102400,两次的buff/cache相差102364。也就是这段shmem共享内存没有被drop_caches回收,实际上,mmap共享内存也是与shmem相同的情况,也就是说,共享内存是不会被drop_caches进行回收的。实际总体上drop_caches不会回收以下内存:
- 正在使用的slab,一些空闲的slab会被drop_caches回收
- 所有类型的mmap共享内存使用的页(包括私有匿名mmap共享内存),不会被drop_caches回收,但是在内存不足时会被内存回收换出
- shmem共享内存使用的页,不会被drop_caches回收,但是在内存不足时会被内存回收换出
- tmpfs使用的页
- 被mlock锁在内存中的pagecache
- 脏的pagecache
有些人会很好奇,为什么shmem和私有匿名mmap共享内存使用的页都算成了pagecache,而在linux内存源码分析 - 内存回收(lru链表)中明确说明了,这两种页是会加到匿名页lru链表中的,在匿名页lru链表中的页有个特点,在要被换出时,会加入到swapcache中,然后再进行换出。实际上,这两种类型的共享内存,在创建时,系统会为它们分配一个没有映射到磁盘上的inode结点,当然也会有inode对应pagecache,但是它们会设置PG_swapbacked,并加入到匿名页lru链表中,当对它们进行换出时,它们会加入到swapcache中进行换出。也就是在没有被换出时,这些没有指定磁盘文件的共享内存,是有属于自己的inode和pagecache的,所以系统也将它们算作了pagecache。
以上说了为什么shmem和私有匿名mmap共享内存被系统算作pagecache,这里再说说为什么drop_caches没有对它们这种pagecache进行释放。首先,drop_caches的实现原理时,遍历系统中所有挂载了的文件系统的超级块struct super_block,对每个文件系统的超级块中的每个文件的inode进行遍历,然后再对每个文件inode中的所有page进行遍历,然后将能够回收的回收掉,实际上,严格地判断pagecache能否回收的条件如下:
- 标记了PG_dirty的脏pagecache不能回收
- 有进程页表项映射的pagecache不能回收
- 被mlock锁在内存中的pagecache不能回收
- 标记了PG_writeback的正在回写的pagecache不能回收
- 没有buffer_head并且page->_count不等于2的pagecache不能进行回收
- 有buffer_head并且page->_count不等于3的pagecache不能进行回收
到这里,实际上已经很清晰了,对于只有write、read进行读写的文件,只要它是干净并且没有被mlock锁在内存中,基本上都是能够回收的,因为write、read系统调用不会让进程页表映射此pagecache。而相反,mmap和shmem都会让进程页表映射到pagecache,这样当某个pagecache被使用了mmap或shmem的进程映射时,这个pagecache就不能够进行回收了。而shmem相对于mmap还有所不同,mmap在进程退出时,会取消映射,这时候这些被mmap取消映射的pagecache是可以进行回收的,但是当一个进程使用shmem进行共享内存时,然后进程退出,shmem共享内存使用的pagecache也还是不能够被drop_caches进行回收,原因是shmem共享内存使用的pagecache的page->_count为4,不为上面的2或者3的情况,具体shmem共享内存的pagecache被哪个模块引用了,还待排查。总的来说,mmap使用的页不能够回收是因为有进程映射了此页,shmem使用的页不能够回收是因为有其他模块引用了此页。
再说说tmpfs,tmpfs中的文件页也是不能够被drop_caches回收的,原因是tmpfs中的文件页生来就是脏页,而又因为它们在磁盘上没有对应的具体磁盘文件,所以tmpfs中的文件页不会被回写到磁盘,又因为生来是脏页,所以tmpfs的文件页在内存充足的情况下,它的整个生命周期都为脏页,所以不会被drop_caches回收。
需要注意,上面所说的所有情况,都表示是drop_caches不能进行回收,但是不代表这些页是不能进行回收的,在内存不足时导致的内存回收流程,就会将shmem、mmap、tmpfs中的页进行换出到swap分区或者对应磁盘文件中。