Jacobi迭代并行算法
Jacobi迭代是一种常见的迭代方法,迭代得到的新值是原来旧值点相邻数据点的平均。串行程序片段如下:

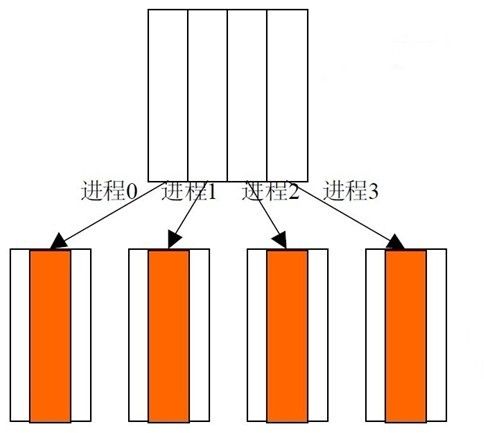
并行化方法之一,可以考虑按列划分,边界点新值的计算需要相邻边界其它块的数据,所以在划分后,每一个数据块的两边各增加一列,用于存放通信得到的数据。如下图:
program main
implicit none
include 'mpif.h'
! define the size of array, 100 x 100
integer, parameter::totalsize = 100, steps = 50
real(kind=8) time_begin, time_end
integer n, myid, numprocs, i, j, rc
integer dp(0:totalsize), delta
real a(totalsize, totalsize), b(totalsize, totalsize)
integer begin_col, end_col, ierr
integer left, right, tag1, tag2, tag
integer status(MPI_STATUS_SIZE),REQ(16)
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numprocs, ierr)
! print *, 'Process', myid, 'of', numprocs, 'is alive'
if(myid.eq.numprocs-1) then
time_begin = MPI_WTIME(ierr)
endif
! boundary values initialized as 8.0, others as 0
do j = 1, totalsize
do i = 1, totalsize
a(i, j) = 0.0
enddo
enddo
do i = 1, totalsize
a(1,i) = 8.0
a(totalsize, i) = 8.0
a(i, 1) = 8.0
a(i, totalsize) = 8.0
enddo
! partition the task
delta =ceiling(dfloat(totalsize) / numprocs)
dp(0) = 2
do i = 1, numprocs
dp(i) = dp(i-1) + delta
enddo
dp(numprocs) = totalsize
begin_col = dp(myid)
end_col = dp(myid+1) - 1
! print the computing domain of each process
call MPI_Barrier(MPI_COMM_WORLD,IERR)
! call sleep((myid+1)*5)
write(*,*) '[',begin_col,'-----------------------',end_col,']'
tag1 = 3
tag2 = 4
! define left process and right process
if(myid.gt.0) then
left = myid -1
else
left = MPI_PROC_NULL
endif
if(myid.lt.(numprocs-1)) then
right = myid + 1
else
right = MPI_PROC_NULL
endif
! Jacobi iteration begins, number of iterations: steps
do n = 1, steps
! data exchange before iteration begins
! shift from left to right
call MPI_SENDRECV(a(1, end_col), totalsize, MPI_REAL,
& right, tag1,a(1,begin_col-1),totalsize, MPI_REAL, left, tag1,
& MPI_COMM_WORLD, status, ierr)
! shift from right to left
call MPI_SENDRECV(a(1,begin_col), totalsize, MPI_REAL,
& left, tag2,a(1,end_col+1),totalsize, MPI_REAL, right, tag2,
& MPI_COMM_WORLD, status, ierr)
do j = begin_col, end_col
do i = 2, totalsize-1
b(i,j) = (a(i,j+1)+a(i,j-1)+a(i+1,j)+a(i-1,j))*0.25
enddo
enddo
do j = begin_col, end_col
do i = 2, totalsize-1
a(i,j) = b(i,j)
enddo
enddo
enddo
if(myid.eq.numprocs-1) then
time_end = MPI_WTIME(ierr)
write(*,*)time_end - time_begin
endif
! each process print the data in its computing domain
! do i = 2, totalsize-1
! print *,myid,(a(i,j),j=begin_col, end_col)
! enddo
! the last process (process numprocs-1) collects data. process 0 ~ numprocs-2 sends data to
! process numprocs-1.
! call MPI_Barrier(MPI_COMM_WORLD,IERR)
if(myid.ne.(numprocs-1)) then
tag = myid +10
call MPI_Isend(a(1,begin_col),totalsize*delta,
& MPI_DOUBLE_PRECISION ,numprocs-1,tag,
& MPI_COMM_WORLD,REQ(myid+1),IERR)
endif
if(myid.eq.(numprocs-1)) then
do i = 0, numprocs-2
tag = i + 10
call MPI_recv(a(1,dp(i)),totalsize*delta,MPI_DOUBLE_PRECISION,
& i,tag,MPI_COMM_WORLD,REQ(i+1),IERR)
enddo
endif
call MPI_FINALIZE(rc)
end
这是运行结果:
[root@c0108 ~]# mpiexec -n 5 ./jacobi [ 2 ----------------------- 21 ] [ 22 ----------------------- 41 ] [ 42 ----------------------- 61 ] [ 82 ----------------------- 99 ] 9.968996047973633E-003 [ 62 ----------------------- 81 ] [root@c0108 ~]# mpiexec -n 10 ./jacobi [ 2 ----------------------- 11 ] [ 12 ----------------------- 21 ] [ 22 ----------------------- 31 ] [ 42 ----------------------- 51 ] [ 32 ----------------------- 41 ] [ 82 ----------------------- 91 ] [ 72 ----------------------- 81 ] [ 92 ----------------------- 99 ] 1.573109626770020E-002 [ 62 ----------------------- 71 ] [ 52 ----------------------- 61 ] [root@c0108 ~]# mpiexec -n 3 ./jacobi [ 2 ----------------------- 35 ] [ 70 ----------------------- 99 ] 1.249790191650391E-002 [ 36 ----------------------- 69 ] [root@c0108 ~]# ls
上述代码中,使用了虚拟进程。虚拟进程(MPI_PROC_NULL)是不存在的假想进程,在MPI中的主要作用是充当真实进程通信的目的或源,引入虚拟进程的目的是在某些情况下,编写通信语句的方便。当一个真实进程向一个虚拟进程发送数据或从一个虚拟进程接收数据时,该真实进程会立即正确返回,如同执行了一个空操作。引入虚拟进程不仅可以大大简化处理边界的代码,而且使程序显得简洁易懂。在捆绑发送接收操作中经常这种通信手段。