hough forest目标检测原理
霍夫森林是随机森林和霍夫投票在计算机视觉中的应用,可以用在物体检测,跟踪和动作识别。
09年cvpr上提出霍夫森林的文章——Class-Specific Hough Forests for Object Detection
关于hough变换,请看我之前的一篇博客Hough直线检测
关于随机森林,请看我的另一篇博客Random Forest随机森林算法
下面这张图阐释了检测原理

Hough Forests(HF)分类器是 Random Forests(RF)算法与广义霍夫变换的结合。简单地说,HF是在RF的学习框架基础上,结合了位置偏移信息d=(x,y),d是被检测的图像块patch到目标中心的位移向量。因此,HF的训练样本集合比RF的样本集合多了一项位移信息,令S={xi, yi,di},其中xi为图像描述符,列如patch的颜色直方图、HoG描述子等等;yi∈{1,…K}是类别标签,K是分类数,一般取yi的取值有两个,即0和1,分别代表背景和目标;di是样本i到目标中心的位移向量,di的作用就是用来在hough image中找到object的。
与RF分类器—样,HF分类器是决策树F={t1,t2,…,Tr}的集合,r是F中决策树的裸数。
下面分训练和检测两个步骤说明
训练
训练时,每棵决策树由样本数据集合S的一个随机子集训练。决策树以递归的方式构建,按照指定的分割法则寻找最优分割函数分割到达节点的数据。到达节点的数据包括了xi,yi, di,即图像描述符向量,标签,和相对目标中心的位移信息。HF定义了两种节点分割法则:基于优化类别标签y的信息增益或基于偏移向量d误差的最小化。基于优化信息增益的优化分割函数与RF的优化准则相同,目标是最小化分类误差,通过分类的信息熵的最小化实现。节点的信息增益定义为:
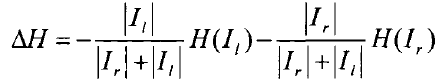
其中Ir和Il分别是样本S以分割函数分割后,落在左右子树上的子集。H()釆用信息熵

基于偏移向量误差最小化的优化函数通过最小化左右子树偏移向量的方差来优化误差
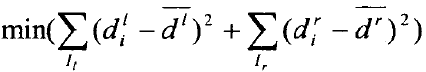
这里的![]() 和
和![]() 分别是落在左右子树的偏移向量的均值。节点分割时在两个优化准则中随机选择一个对当前节点进行分割。递归构建的过程在决策树生长达到最大深度时或节点上的样本全都属于同一类别时或样本个数少于指定数时停止。然后统计每个叶节点上的分类信息,包括每个类别k的概率pk和属于类别k的偏移向量集合d。
分别是落在左右子树的偏移向量的均值。节点分割时在两个优化准则中随机选择一个对当前节点进行分割。递归构建的过程在决策树生长达到最大深度时或节点上的样本全都属于同一类别时或样本个数少于指定数时停止。然后统计每个叶节点上的分类信息,包括每个类别k的概率pk和属于类别k的偏移向量集合d。
检测
HF分类器的检测过程与RF算法相同,按照分类器的每个节点的分割法则迭代判断图像块,最终到达图像块隶属的叶节点,得到的分类结果可表示为
![]()
![]() 是图像块Xi在第t棵树上隶属的叶节点。最后在Hough图像中用分类结果进行投票,将xi在分类器F的每棵树上的隶属节点
是图像块Xi在第t棵树上隶属的叶节点。最后在Hough图像中用分类结果进行投票,将xi在分类器F的每棵树上的隶属节点![]() 的pk累加到Hough图像中位置为
的pk累加到Hough图像中位置为![]() 的像素值上(I为图像块Pi的位置),这便是用节点的概率信息和偏移向量对测试图像的目标中心投票的过程。最后Hough图像上的投票结果通过非极大值抑制得到检测结果。
的像素值上(I为图像块Pi的位置),这便是用节点的概率信息和偏移向量对测试图像的目标中心投票的过程。最后Hough图像上的投票结果通过非极大值抑制得到检测结果。
这样说完了大家可能还不清楚是怎么一回事,举个例子大家应该就能明白,以上面的图为列,现在我的目标是要检测那个行人,好,我对整个人随机截取小patch,例如16*16的小图像块,这些小图像块附带有它们各自偏离行人中心的向量d,然后提取每个小图像块的描述子xi,这些就是正样本,即y=1;然后在图像其他区域提取16*16的小图像块,然后提取每个小图像块的描述子xi,这些就是负样本,即y=0,注意负样本没有偏移向量d,或者说d=0。好了,现在正负样本都有了,就用这些样本按之前说的规则生成许多树,这些树构成森林。
得到的每个树的叶节点可能是这样的

在检测阶段,对待检测图像提取许多许多16*16的小图像块,把这些一个一个小图像块丢进之前训练好的森林里,每个小图像块在森林的每棵树上会掉到一个叶节点上,这时就会得到它属于目标的概率p以及它相对目标中心的偏移向量d的预测,设小图像块自身在待检测图像中的位置为I,这些预测值的意义就是在hough image里,在I-d的位置为目标中心的概率为p(打个比方,其实不是概率),每个树上的结果累加后平均,就是这个小图像块得到的结果。所有的小图像块投票完毕之后,哪个位置的分最高,那个位置就最有可能是目标。比如上面图中头部图像块就可能掉进了之前训练的代表头部的叶节点里,好,我找到了一个头;然后我又找到了一个脚。。。所有的组合起来,它们各自预测的偏移向量都指向一个地方,即行人的中心,它的投票数最多,这样行人就检测出来了。
到这里我觉得大家应该大致明白了算法是怎么回事了,下面来讨论算法的细节。
特征描述子
前面说过,这个小图像块的特征描述子可以是HoG特征、LBP特征、颜色直方图等等。
用HoG的话可以这样来弄
这里的 HOG 计算方式有别于原始 HOG 特征计算方法。对于一个以关键点为中心的 16×16 图像块的梯度信息,我们在每个 5×5 邻域内计算 9 个方向的梯度方向直方图,5×5 邻域重叠 2 个像素,一个 16×16 像素的图像块重共分 4
×4 个子块,最终形成 4×4×9=144 维的 HOG 特征向量,直方图的统计值以梯度幅度大小加权。具体计算方法如下:
计算所有像素点的梯度:
![]()
方向梯度为:
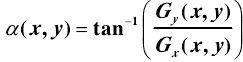
分别计算各个像素点在[-π/2,π/2]梯度方向上 9 个均匀区间内的幅值:
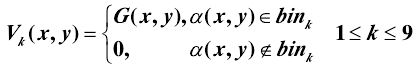
对其进行 L2-Norm 归一化,这一过程主要消除光照带来的影响。
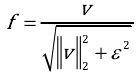
LBP算子
在3*3领域提取uniform LBP即可,59维。
Lab颜色直方图
对每个固定大小的图像块统计 Lab 空间下的颜色直方图。具体方法是,首先将原始图像块转化为 CIE-Lab 颜色空间模型表示。为了降低特征维度,分别对 L、a、b 三个通道进行量化,将L通道[0,100]均匀量化为 10 个区间。因为 Lab 空间在靠近 0 的地方,颜色变化较为明显,所以对 a、b通道采用非均匀量化。靠近 0 的地方,量化区间较小,反之则较大。量化区间为:[-128,-85]、[-85,-50]、[-50,-25]、[-25,-10],[-10,0]、[0,10] 、[10,25]、 [25,50]、 [50,85]、 [85,127]。一般情况下,忽略亮度信息 L,仅根据像素的 a,b 值投票至颜色直方图。当色阶 a、b 和亮度 L 均小于一定阈值时,认为该像素色彩色调不明显,而亮度信息较重要,此时忽略该像素 a、b 值,投票至颜色直方图的对应 L 柱条,整个颜色直方图由 10×10 维 a、b柱条加 10 维 L亮度柱条组成,共110 维。
Hough 森林训练过程如下:
Step1:多特征提取后可得每个 patch 的表达: P (xi , ci,di),其中 pos Pi(xi , 1,di) ,neg Pi(xi ,0,0)
,其中xi为多特征提取后串联所得的总特征向量,共 144+59+110=313 维。
Step2:Hough 森林通过生成随机的二值测试来分裂节点:
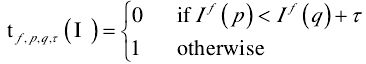
每次分裂生成 2000 种特征选择方法,不同的特征在各自的维度中进行比较,例如 144 维 HOG 特征中选择 2 维进行比较。其中,特征种类 f、维数 p、q、阈值τ均为随机选取。
原论文中是这样的

这里有很大的优化空间
在霍夫森林训练过程中,每棵树在做二叉测试的时候只选取了两个点的像素值作为比较,两个点的像素值所代表的信息是非常有限的,选用Haar-like特征能够获得所选取点邻域附近更多的信息,通过判断两个Harr-like响应值的大小决定树的左右走向。
Step3:计算最小化类别不确定性和最小化偏移向量不确定性,选择 2000 次分裂中的最优分类。
最优的分裂将形成一个子节点,子节点中储存了最优的特征种类 f、维数 p、q、阈值τ 。当满足一定条件时,当前子节点为叶节点,该节点不再分裂。每个叶节点 L 存储了一个图像块属于每一物体类别 c 的概率p(c|L) ,这个概率是由到达该叶节点的图像块中属于该类的图像块与总的图像元素数目的比值决定的。此外,节点 L 还存储了DL,即测试图像块相对于样本中心的偏移量。
Step4:当所有的子节点成为叶节点后,树停止生长,训练得到一颗随机树。

