浅谈多节点CPU+GPU协同计算负载均衡性设计
转自:http://blog.csdn.net/zhang0311/article/details/8224093
近年来,基于CPU+GPU的混合异构计算系统开始逐渐成为国内外高性能计算领域的热点研究方向。在实际应用中,许多基于 CPU+GPU 的混合异构计算机系统表现出了良好的性能。但是,由于各种历史和现实原因的制约,异构计算仍然面临着诸多方面的问题,其中最突出的问题是程序开发困难,尤其是扩展到集群规模级别时这个问题更为突出。主要表现在扩展性、负载均衡、自适应性、通信、内存等方面。
一、 CPU+GPU协同计算模式
CPU+GPU异构协同计算集群如图1所示,CPU+GPU异构集群可以划分成三个并行层次:节点间并行、节点内CPU与GPU异构并行、设备(CPU或GPU)内并行。根据这三个层次我们可以得到CPU+GPU异构协同计算模式为:节点间分布式+节点内异构式+设备内共享式。
1 节点间分布式
CPU+GPU异构协同计算集群中,各个节点之间的连接与传统CPU集群一样,采用网络连接,因此,节点间采用了分布式的计算方式,可以采用MPI消息通信的并行编程语言。
2 节点内异构式
CPU+GPU异构协同计算集群中,每个节点上包含多核CPU和一块或多块GPU卡,节点内采用了异构的架构,采用主从式的编程模型,即每个GPU卡需要由CPU进程/线程调用。
由于每个节点上,CPU核数也比较多,计算能力也很大,因此,在多数情况下,CPU也会参与部分并行计算,根据CPU是否参与并行计算,我们可以把CPU+GPU异构协同计算划分成两种计算模式:
1) CPU/GPU协同计算:CPU只负责复杂逻辑和事务处理等串行计算,GPU 进行大规模并行计算;
2) CPU+GPU共同计算:由一个CPU进程/线程负责复杂逻辑和事务处理等串行计算,其它CPU进程/线程负责小部分并行计算,GPU负责大部分并行计算。
由于CPU/GPU协同计算模式比CPU+GPU共同计算模式简单,下面的介绍中,我们以CPU+GPU共同计算模式为例进行展开介绍各种编程模式。
在CPU+GPU共同计算模式下,我们把所有的CPU统称为一个设备(device),如双路8核CPU共有16个核,我们把这16个核统称成一个设备;每个GPU卡成为一个设备。根据这种划分方式,我们可以采用MPI进程或OpenMP线程控制节点内的各设备之间的通信和数据划分。
3 设备内共享式
1) CPU设备:每个节点内的所有多核CPU采用了共享存储模型,因此,把节点内的所有多核CPU看作一个设备, 可以采用MPI进程或OpenMP线程、pThread线程控制这些CPU核的并行计算。
2) GPU设备:GPU设备内有自己独立的DRAM存储,GPU设备也是共享存储模型,在GPU上采用CUDA或OpenCL编程控制GPU众核的并行计算。CUDA编程模式只在NVIDIA GPU上支持,OpenCL编程模式在NVIDIA GPU和AMD GPU都支持。
根据前面对CPU+GPU异构协同计算模式的描述,我们可以得到CPU+GPU异构协同计算的编程模型(以MPI和OpenMP为例)如表1所示。

图1 CPU+GPU异构协同计算架构
表1 CPU+GPU异构协同计算编程模型
|
|
节点间分布式 |
节点内异构式 |
设备内共享式 |
|
| CPU |
GPU |
|||
| 模式1 |
MPI |
OpenMP |
OpenMP |
CUDA/OpenCL |
| 模式2 |
MPI |
MPI |
OpenMP |
CUDA/OpenCL |
| 模式3 |
MPI |
MPI |
MPI |
CUDA/OpenCL |
二、 CPU+GPU协同计算负载均衡性设计
下面以模式2为例简单介绍多节点CPU+GPU协同计算任务划分和负载均衡,模式2的进程和线程与CPU核和GPU设备对应关系如图2所示。若采用主从式MPI通信机制,我们在节点0上多起一个进程(0号进程)作为主进程,控制其它所有进程。每个节点上启动3个计算进程,其中两个控制GPU设备,一个控制其余所有CPU核的并行,在GPU内采用CUDA/OpenCL并行,在CPU设备内采用OpenMP多线程并行。
由于CPU+GPU协同计算模式分为3个层次,那么负载均衡性也需要在这3个层次上分别设计。在模式2的编程方式下,节点内和节点间均采用MPI进程,合二为一,设计负载均衡时,只需要做到进程间(设备之间)的负载均衡和CPU设备内OpenMP线程负载均衡、GPU设备内CUDA线程负载均衡即可。
对于设备内,采用的是共享存储器模型,CPU设备上的OpenMP线程可以采用schedule(static/ dynamic/ guided )方式;GPU设备上只要保证同一warp内的线程负载均衡即可。
对于CPU+GPU协同计算,由于CPU和GPU计算能力相差很大,因此,在对任务和数据划分时不能给CPU设备和GPU设备划分相同的任务/数据量,这就增加了CPU与GPU设备间负载均衡的难度。CPU与GPU之间的负载均衡最好的方式是采用动态负载均衡的方法,然而有些应用无法用动态划分而只能采用静态划分的方式。下面我们分别介绍动态划分和静态划分。
1) 动态划分:对于一些高性能计算应用程序,在CPU与GPU之间的负载均衡可以采用动态负载均衡的优化方法,例如有N个任务/数据,一个节点内有2个GPU卡,即三个设备(CPU和2个GPU),动态负载均衡的方法是每个设备先获取一个任务/数据进行计算,计算之后立即获取下一个任务,不需要等待其他设备,直到N个任务/数据计算完成。这种方式只需要在集群上设定一个主进程,负责给各个计算进程分配任务/数据。
2) 静态划分:在一些应用中,无法采用动态划分的方式,需要静态划分方法,然而静态划分方法使异构设备间的负载均衡变得困难,有时甚至无法实现。对于一些迭代应用程序,我们可以采用学习型的数据划分方法,如先让CPU和GPU分别做一次相同计算量的计算,然后通过各自的运行时间计算出CPU与GPU的计算能力比例,然后再对数据进行划分。

图2 CPU+GPU协同计算示意图(以每个节点2个GPU为例)
三、 CPU+GPU协同计算数据划分示例
假设某一应用的数据特点如图3所示,从输出看,结果中的每个值的计算需要所有输入数据的信息,所有输出值的计算之间没有任何数据依赖性,可以表示成outj=;从输入看,每个输入值对所有的输出值都产生影响,所有输入数据之间也没有任何数据依赖性。从数据特点可以看出,该应用既可以对输入进行并行数据划分也可以对输出进行数据划分。下面我们分析CPU+GPU协同计算时的数据划分方式。
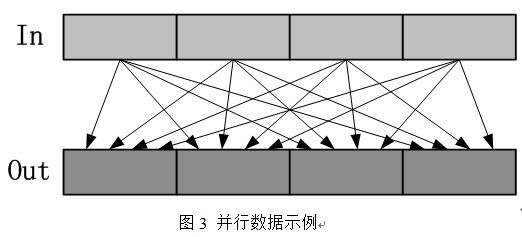
图3 并行数据示例
1 按输入数据划分
假设按输入数据划分,我们可以采用动态的方式给每个CPU或GPU设备分配数据,做到动态负载均衡,然而这种划分方式,使所有的线程向同一个输出位置保存结果,为了正确性,需要使所有的线程对每个结果进行原子操作,这样将会严重影响性能,极端情况下,所有线程还是按顺序执行的。因此,这种方式效果很差。
2 按输出数据划分
按输出数据划分的话可以让每个线程做不同位置的结果计算,计算完全独立,没有依赖性。如果采用静态划分的方式,由于CPU和GPU计算能力不同,因此,很难做到负载均衡。采用动态的方式可以做到负载均衡,即把结果每次给CPU或GPU设备一块,当设备计算完本次之后,立即向主进程申请下一个分块,这样可以做到完全负载均衡。按输出数据划分,无论采用静态划分还是动态划分,都会带来另外一个问题,由于每个结果的计算都需要所有输入信息,那么所有进程(设备)都需要读取一遍所有输入数据,动态划分时还不只一次,尤其对于输入数据很大时,这将会对输入数据的IO产生很大的影响,很有可能使IO程序性能瓶颈。
3 按输入和输出同时划分
由于按输入或按输出划分都存在不同的缺点,我们可以采用输入和输出同时划分的方式进行数据划分,如图4所示。
从输出角度,让所有的计算进程(设备)都有一份计算结果,设备内的线程对结果进行并行计算,每个设备都有一份局部的计算结果,所有设备都计算完毕之后,利用MPI进程对所有设备的计算结果进行规约,规约最后的结果即是最终的结果。
从输入角度,按输入数据动态划分给不同的计算进程(设备),这样可以满足所有的计算进程负载均衡。

图4 CPU+GPU协同计算数据划分示例