Fuzzing技术的研究
Fuzzing技术源于软件测试中的黑盒测试技术,它的基本思想是把一组随机数据作为程序的输入,并监视程序运行过程中的任何异常,通过记录导致异常的输入数据进一步定位软件中缺陷的位置。1990年Miller等人发现,通过简单的Fuzzing可以使运行于UNIX系统上的多于25%的程序崩溃;2002年Aitel通过自己设计实现的Fuzzing工具SPIKE成功地发现了多个未知漏洞;2008年Godefroid等人利用Fuzzing工具SAGE发现大型Windows应用程序中二十多个未知漏洞。
1、Fuzzing的定义
关于Fuzzing的定义,人们从不同的角度进行了描述。Miller等人认为Fuzzing(或Fuzz testing)是软件测试中的随机测试技术;Sutton等人认为Fuzzing的重要组成部分是暴力测试;Andrea等人认为Fuzzing是一种简单的黑盒测试技术;Oehlert认为Fuzzing是黑盒测试技术中的边界测试技术,Vuagnoux认为Fuzzing是黑盒测试、错误注入、压力测试的技术融合。总体来说,传统的Fuzzing是指一种非常简单的黑盒测试技术或者随机测试技术,用来发现软件的缺陷(flaws)。
完整地说,Fuzzing是一种基于缺陷注入的自动软件测试技术,它利用黑盒测试的思想,使用大量半有效的数据作为应用程序的输入,以程序是否出现异常为标志,来发现应用程序中可能存在的安全漏洞。
Fuzzing作为一项发现软件错误的测试技术具备如下优点:其测试目标是二进制可执行代码,比基于源代码的白盒测试方法适用范围更广泛;Fuzzing是动态实际执行的,不存在静态分析技术中存在的大量的误报问题;Fuzzing原理简单没有大量的理论推导和公式计算,不存在符号执行技术中的路径状态爆炸问题;Fuzzing自动化程度高,无须在逆向工程过程中大量的人工参与。因此,Fuzzing技术是一种有效且代价低的方法,在许多领域受到欢迎,许多公司和组织用其来提高软件质量,漏洞分析者使用它发现和报告漏洞,黑客使用它发现并秘密利用漏洞。国内对Fuzzing技术有了初步的研究和简单的应用。
2、早期的Fuzzing技术
早期的Fuzzing技术仅是一种简单的随机测试技术,但却有效地发现了许多程序中的错误。早期的程序中出现的错误也比较简单,如代码中因没有对输入的字符串的长度进行检查,而导致栈溢出。
由于早期的Fuzzing技术操作起来简单,与其测试目标程序的关联性小,它的优点包括:1)可用性,不需要获得目标程序的源代码就可以测试;2)复用性,如测试FTP(file transfer protocol)的Fuzzing程序可以用来测试任何FTP服务器;3)简单性,无须过多了解目标程序。然而, Fuzzing技术不可避免地带有随机测试产生大量冗余测试输入、覆盖率低导致发现软件缺陷概率低的缺点,同时带有黑盒测试的低智能性的缺点,即黑盒测试只测试了程序的初始状态,而很多程序尤其是网络协议程序的很多错误是隐藏在程序的后序状态中的。
3、Fuzzing技术的研究现状
3.1 与黑盒测试技术的区别
经过近二十年的发展,源于黑盒测试技术的Fuzzing技术显示出与前者的不同,主要表现在:1)测试需求的着眼点不同。Fuzzing测试着眼于发现软件安全性相关的错误,黑盒测试着眼于测试软件的功能的正确性。2)测试用例的侧重点不同。由于测试需求的不同,Fuzzing的测试用例大多数都是畸形的测试用例,黑盒测试的用例的大多数都是正确的测试用例。Fuzzing为了提高测试用例的有效性,则必须提高测试用例的正确性,从而使测试用例的畸形数据能够达到程序的潜在不安全点。3)由于测试用例的产生机理不同,Fuzzing为了产生有效的畸形数据,需要考虑到测试用例的数据格式、目标程序的结构流程和程序运行的中间状态;而黑盒测试只关心目标程序的外部接口和外部输入,从这个意义上讲,现在的Fuzzing技术更接近于灰盒测试。
3.2 Fuzzing的测试对象
在Fuzzing技术的有效性进一步得到验证之后,出现了许多针对特定类型应用程序或者协议的Fuzzing工具,如针对浏览器的mangleme、针对文件应用程序的FileFuzzing和SPIKE-file、针对ActiveX的COMRaider和AxMan,尤其突出的是2002年出现的针对网络协议的SPIKE。后来,进一步出现了针对性更强、功能也更为单一的Fuzzing工具,如针对IRC协议的ircfuzz,针对DHCP协议的dhcpfuzz[34]和针对FTP的tftp-fuzz工具等。当前的Fuzz工具主要是针对文件格式应用程序和网络协议应用程序,但也出现了可以测试浏览器、操作系统内核、Web应用程序的Fuzz工具。另外,引入了agent思想的工具Peach可以对分布式系统进行Fuzz测试。
3.3 Fuzzing的架构
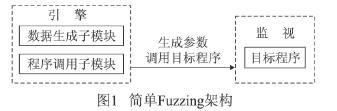
最为简单的Fuzzing架构如图1所示,包含引擎和监视两个模块。引擎模块的功能是产生Fuzzing需要的数据并把数据发送到目标程序使之运行;监视模块的功能是监视目标程序的运行状态是否出错。早期Fuzzing的实现就是采用了该模型,监视模块功能的实现借助于简单的脚本来记录程序出错的信息。
随着Fuzzing技术的进一步发展,出现了如图2所示的架构设计。为了避免产生大量无效的测试数据,新架构中出现了参数脚本和样本文件。参数脚本给出了引擎生成的测试用例中的数据的格式、长度等与数据之间的一些关系,如SPIKE、Sulley使用的类C格式的脚本, Peach使用的XML格式的脚本。样本文件是许多基于变异技术(mutation-based)的数据生成方式的Fuzzing工具用来变异测试数据的基准。基于样本文件产生的测试数据可以大大提高测试用例的有效性,可以提高测试的代码覆盖率,可以减轻测试用例构造的复杂度。Fuzzing测试文件格式应用程序依据的样本文件是其相应格式(如DOC、PDF等)的样本文件(如Peach),Fuzzing测试网络协议应用程序的样本文件是通过嗅探工具(如Ethereal或W ireShark)的数据包转换的样本文件(如Peach、Sulley、AutoDafe、SPIKE Proxy等)。
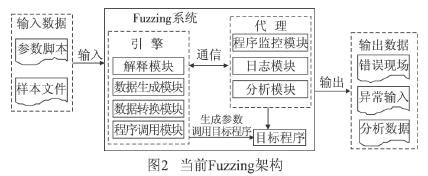
在图2所示的架构中,Fuzzing引擎的模块划分粒度更为细化,其目的是加强代码的可复用性和整个Fuzzing构架的灵活性,以方便用户根据需求快速制定适合其他多种协议的Fuzzing程序。
Fuzzing的监视模块发生了很大的变化,转换为功能更为丰富的代理(agent)模块(如工具Peach、Sulley),一方面可以并行Fuzzing的过程以提高Fuzzing的效率,一方面可以使引擎和代理分离开来在不同的机子上运行,可以对分布式应用程序进行Fuzzing测试
3.4 Fuzzing测试数据的产生机理
早期的Fuzzing技术就是随机测试技术,测试数据多数是随机产生的畸形数据。为了提高Fuzzing产生数据的有效性,出现了下面两种产生测试数据的思想:
1)基于格式分析和程序理解相结合的数据产生方法,其代表工具有SPIKE、Peach、Sulley、AutoDafe等。通过对文件和协议的理解,该方法产生的数据可以有效地越过应用程序中对固定字段、校验和、长度的检查,从而使Fuzzing的测试数据的有效性大大加强。该方法又可以分为基于生成技术的方法(generation-based)和基于变异技术的方法(mutation-based)或两者相结合(如工具Peach)的方法。基于生成技术的测试数据产生方法通常是给出文件格式或者网络协议具体的描述规则,然后依据此规则产生测试数据。该方法需要用户对格式或者协议有非常深的了解,并需要大量的人工参与。基于变异技术的数据产生方式通常是在对格式或者协议有所了解的前提下,对获得的样本数据中的某些域进行变化,从而产生新的变异数据。该方法对初始值有着很强的依赖性,不同的初始值会带来差异很大的代码覆盖率,从而会产生差异很大的Fuzzing效果。还有一种完全自动化的基于变异技术的数据产生方式,如工具AutoDafe和SPIKE Proxy,该方法利用协议的自动分析技术实施对测试数据的自动生成。但由于协议自动分析技术的准确率还有待进一步提高,其Fuzzing测试效果并不理想。总之,基于格式分析和程序理解相结合的数据产生方法的优点是执行效率比较高、应用范围广、通用性强,缺点是仍然需要大量的人工参与来进行多种知识(如协议知识、数据格式知识、应用程序知识)的获取并实现这些知识到测试用例的转换。
2)基于静态分析与动态测试相结合的数据产生方法。通过与静态分析技术、符号执行技术、具体执行技术等多种技术[4, 5, 8]相结合,从而在达到一个较高的代码覆盖率的测试基础上进行Fuzzing测试。本质上来说,这种方法是白盒测试与Fuzzing测试技术的融合。该方法通过借助软件测试中的技术使Fuzzing技术得到一个不错的代码覆盖率,该方法的缺点是仍然无法克服符号执行中的状态爆炸问题,也无法完全自动解决部分程序自带的高强度的程序检查(如校验和和加密数据)问题;另外,该方法采用了类似于穷搜索的思路,每次执行需要大量的时间,效率低;而且每次执行都需要复杂的符号运算,从而消耗了大量的时间。
4、Fuzzing技术的研究方向
Fuzzing技术以其简单有效的优点得到了越来越多的关注,结合上述技术的不足和实际应用中的需求,其研究方向可以归纳为以下几个方面:
1)Fuzzing测试平台的通用性研究。由于Fuzzing的测试对象越来越广泛,如何构建通用的、可扩展性强的通用平台对于提高Fuzzing技术的整体发展十分必要。通用的测试平台应该具备下面几个功能:具备数据格式的解释功能从而产生适合多种数据格式的有效的畸形测试数据;具备独立的、可定制的数据产生变异功能,可以产生多种类型的、针对性强的畸形数据;具备可操作的跟踪调试功能以反馈运行时的多种信息;具备高效的引擎以协调多个模块之间的自动化运行。
2)知识获取的自动化程度的提高。实际的Fuzzing测试过程显示绝大部分的时间都花费在输入数据格式、程序状态转换的人工分析上;提高测试数据或通信协议的自动化分析或半自动化分析水平可以有效提高Fuzzing的测试效率。
3)多维的Fuzzing测试用例生成技术研究。当前的Fuzzing测试用例生成技术都是一维的,即每次只变化一个输入元素,而许多漏洞是由多个输入元素共同作用引起的。多维测试用例生成技术的研究可以有效扩展Fuzzing发现的漏洞范围,但是多维Fuzzing测试用例会带来类似于组合测试中的状态爆炸问题,现有的组合测试理论成果对于解决Fuzzing多维测试中的状态爆炸问题有一定的借鉴意义。
4)智能的测试用例生成技术研究。利用漏洞知识给出合适的导向,结合智能算法像遗传算法、模拟退火算法可以有效避免Fuzzing随机性强、漏洞漏报率高的缺点。
5)Fuzzing测试的程序多状态的自动覆盖技术研究。可以解决需要人工参与才能覆盖程序的多个状态问题,从而提高整体Fuzzing测试的效率。
6)Fuzzing测试效果的评估技术研究。以黑盒测试中的代码覆盖率来评价Fuzzing的测试效果是不直接、不科学的;从覆盖不安全代码的覆盖率、程序状态的覆盖率、输入边界测试的充分性、缓冲区边界覆盖的充分性、测试数据的有效性和知识获取的充分性等多个角度来衡量Fuzzing的测试效果会更加科学,也会更好地指导Fuzzing测试用例的生成和Fuzzing技术的进一步发展。
参考文献:
[1] Fuzzing技术综述 吴志勇; 王红川; 孙乐昌; 潘祖烈; 刘京菊 计算机应用研究 2010(3)
[2] 漏洞挖掘分析技术综述 迟强; 罗红; 乔向东 计算机与信息技术 2009(Z2)