过渡到SSAS之一:简单模型认识
在许多不需要实时而具有海量或需要足够灵活的分析模型中,ssas比传统的sql有很大的优势,比如性能和用户可定制性。性能上的优势体现在mdx语句对比大数据量sql聚合函数上;而可定制性,这里指的是在有对于mdx来说,开发一个适合各类用户自由分析统计数据的展示工具比用sql语句成本要小的多。
mdx的中文意思是多维表达式,从设计上就是用来做数据分析的。
如果你有项目适合上述特点的话,真的需要考虑来过度到SSAS,来OLAP一下了。下面用一个实例来展示一下他的一个简单应用,可以让没有接触过的人来简单了解一下。
今天在论坛上看到这么一个需求,是分析web日志的,比如PV之类的,还要分日期来做比较。一般此类源数据量很大,如果用sql语句的case when配合聚合函数,加上复杂的行列转换和透视语句运行起来会比较吃力,一个SSAS模型就可以轻松解决问题。
我们来做个测试的数据库环境
sTime是开始访问时间,sLeaveTime是最后访问时间,sCount是这个IP访问页面数量
-- 建立测试环境
create database TestSSAS
go
use TestSSAS
go
-- 事实表
create table Logs( sId varchar ( 20), sWebsiteId varchar ( 20), sTime datetime , sLeaveTime datetime , sIp varchar ( 20), sCount int )
insert into Logs select '1' , '542' , '2008-11-18 09:18:35.000' , '2008-11-18 14:51:29.000' , '61.183.248.218' , '87'
insert into Logs select '2' , '542' , '2008-11-18 09:38:36.000' , '2008-11-18 17:04:23.000' , '61.144.207.115' , '128'
insert into Logs select '3' , '543' , '2008-11-18 09:42:35.000' , '2008-11-18 10:36:46.000' , '61.183.248.218' , '5'
insert into Logs select '4' , '552' , '2008-11-18 16:45:19.000' , '2008-11-18 16:45:21.000' , '61.144.207.115' , '4'
insert into Logs select '5' , '551' , '2008-11-18 16:45:54.000' , '2008-11-18 16:45:55.000' , '61.144.207.115' , '5'
insert into Logs select '7' , '549' , '2008-11-18 16:46:58.000' , '2008-11-18 16:46:59.000' , '61.144.207.115' , '3'
insert into Logs select '8' , '548' , '2008-11-18 16:47:15.000' , '2008-11-18 16:47:16.000' , '61.144.207.115' , '4'
insert into Logs select '5' , '551' , '2008-11-19 16:45:54.000' , '2008-11-19 16:45:55.000' , '61.144.207.115' , '15'
insert into Logs select '7' , '549' , '2008-11-19 16:46:58.000' , '2008-11-19 16:46:59.000' , '61.144.207.115' , '13'
insert into Logs select '8' , '548' , '2008-11-19 16:47:15.000' , '2008-11-19 16:47:16.000' , '61.144.207.115' , '14'
go
-- 事实表对应视图
create view v_Fac_logs as
select sid, swebsiteid, convert ( varchar ( 10), stime, 120) as date, sIP, sCount from Logs
go
-- 维度表
create table dim_datetime ( date varchar ( 10))
insert dim_datetime
select '2008-11-15' union
select '2008-11-16' union
select '2008-11-17' union
select '2008-11-18' union
select '2008-11-19'
go
-- 事实表抽取的维度,这里用视图实现
create view dim_Ip as
select distinct sip from Logs
对于前面的 Logs表部分是测试数据,和普通的sql环境一样,后面的事实和维度部分是为了ssas模型做准备的,说的简单点,就是把需要group by的字段拎出来,作为单独的维度表存在,他们和事实表(这里是 v_Fac_logs视图 )做主从关系。
然后我们用一些纯UI上的功夫来生成一个SSAS的多维数据集。
1、打开SQLServer2005自带的SQL Server Business Intelligence Development Studio,或者你机器上有vss2005也可以。
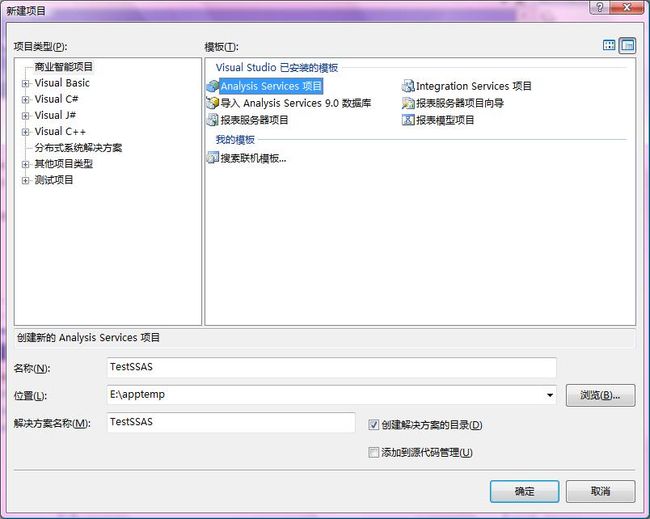
2、新建项目,选择商业智能模板中的分析服务项目
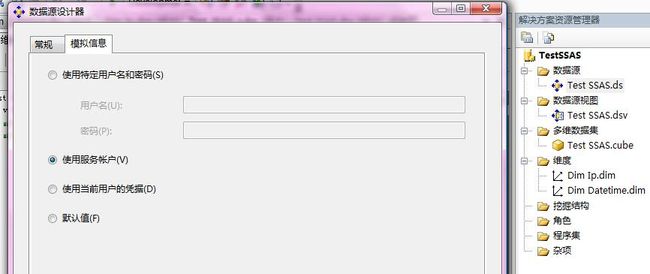
3、如图建立一个数据库连接,这个很简单,连接刚刚的测试数据库就可以了。

不过这里要注意一个细节,配置链接的窗口中,有个模拟信息,需要把登录方式改为“服务帐户”
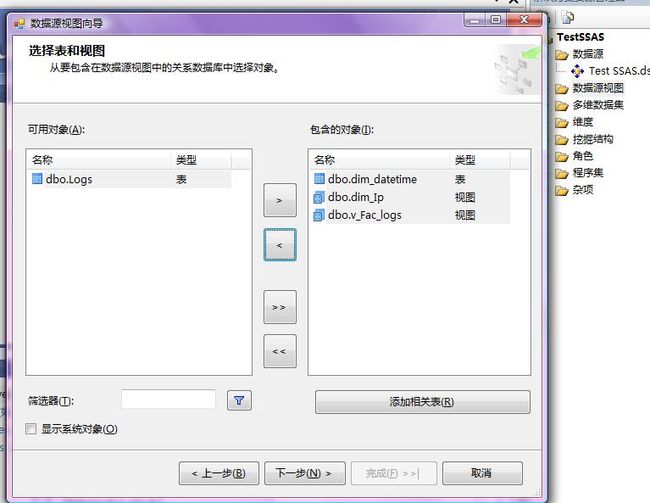
4、新建一个数据源视图,选择事实表和维度表,注意这里选择了v_Fac_logs作为事实表而不是Logs。
建立维度和事实之间的逻辑关系,就是主外键关系,事实表必须制定逻辑主键。这个不需要在sqlserver的真实环境中设定,只要这里设定了就可以了。
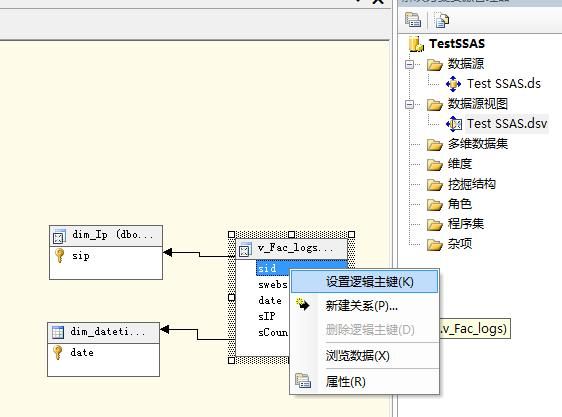
5、新建一个多维数据集,只要按照向导默认建立就可以了。

中间的维度和事实结构,系统都会帮你自动搞定,在还不清楚他们的具体用法的时候,你可以不管他。最终的效果如下

6、配置一个角色,这个角色日后用在登录ssas服务器的认证,这里用系统管理员。

7、简单的模型建立好了,然后就是部署和数据处理,默认部署在自己的服务器Localhost。
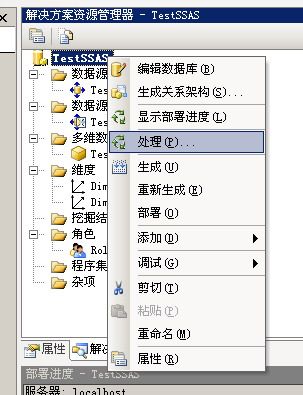
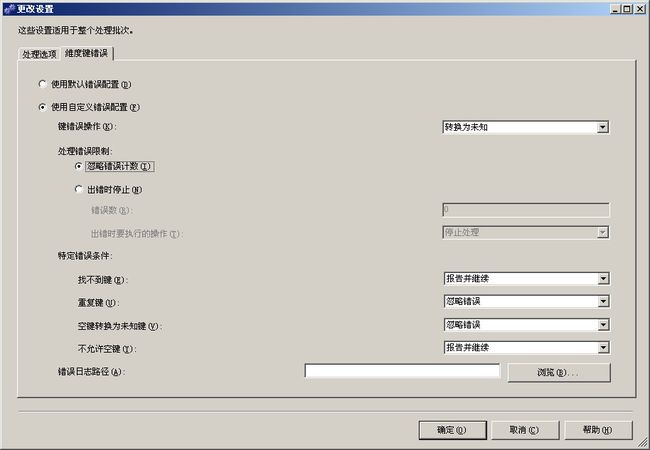
8、处理的时候可以更改设置,并忽略错误,ssas处理会因为一些逻辑上的或者数据上的错误导致失败,如果忽略错误的话,只跳过单条记录(continue),否则整个过程就会退出(break),然后点击运行。

忽略错误的方法
处理成功的结果。
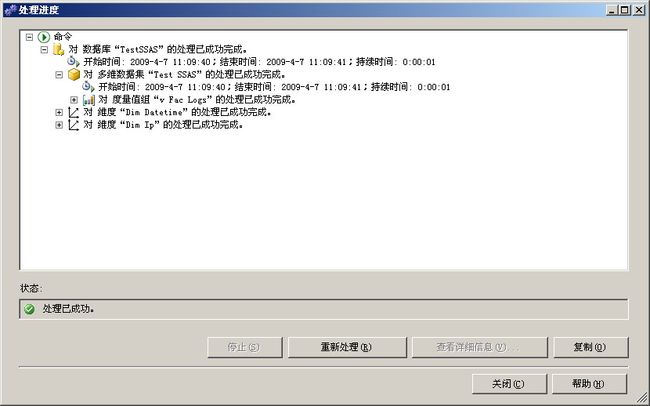
9、现在一个可用的多维数据集就做好了,我们可以用我们的建模工具来浏览数据。选择多维数据集-浏览器:

只要把Dim相关的维度拖到上图的对应维度区域(这里的行和列都是维度)中,然后把Measures对应的度量拖到上图的数据区,就可以看到数据了。

一个简单的多维数据集就建好了,这里只是感性的人是一下,细心的朋友可能看到最后已经会发现他的行列转换很方便了,只要把ip的datetime的位置对调一下就可以了。
之所以说他简单,首先测试数据很少,不需要复杂的ETL过程,可用的维度只有2个,可统计的度量实际只有一个,还体现不出任何优越性来。但你真正用到实际项目中就会发现他的强大了。
本片文章只是我们过渡到SSAS的BI项目的第一步,一个简单的模型,接下来我们会围绕这个模型来讨论如何部署到web服务器供其他客户端,比如SQL Server Management Studio、.Net客户端等来访问、以及如何使用Mdx语句来做分析统计,如果遇到庞大的项目、比如需要分析的数据来源复杂的,如何做资源整合以及ETL数据清理。