鲁棒性语音识别系统设计与实现
本文主要采用matlab和C语言设计并实现了一个鲁棒性语音识别实验系统,通过该系统验证各种抗噪语音特征在不同信噪比的噪声环境下的识别率,并详细介绍了系统的结构以及开发工具与平台,最后介绍了系统的功能、实验流程以及该系统的实现。
系统演示下载路径:http://pan.baidu.com/s/1o61Kaa2
一、系统结构
本文研究的是非特定人鲁棒性语音识别,采用的是小词汇量孤立词语音。本系统使用了两种语音识别模型,分别为HMM模型和VQ模型。在系统中,利用HMM模型进行抗噪鲁棒性语音识别,采用VQ模型进行SLVQ算法的评估。通过语音库的训练得到识别模型,然后对待测试语音进行识别。其系统结构如图1-1。

图1-1系统结构图
在图1-1所示的结构图中,语音预处理与特征和模型训练器是整个系统的核心。特征提取是训练器的前提,同时也是识别器的前提。语音采集模块完成录音,可以作为语音库来训练识别模型。结果输出模块主要用于将中间识别结果以及系统其他状态信息显示出来。
二、开发工具与平台
本文的语音识别系统在PC上,采用Matlab(R2010b)作为开发工具。语音识别模型HMM采用PMT(Probabilistic Model Toolkit)[97]工具包进行二次开发。下面简单介绍下Matlab和PMT。
Matlab是一个功能强大的科学及工程计算工具,它将矩阵运算、数值分析、图形处理、编程技术等功能有机地结合在一起,被广泛应用于自动控制、系统仿真、图形图像分析、数字信号处理、人工智能、虚拟现实等领域。本系统采用Matlab的主要原因如下:
(1) 丰富的数学函数库;Matlab包含了大量的数学函数库,有求和、复数运算、矩阵运算以及傅里叶变换等函数,这些都为语音信号的处理带来了方便。
(2) 强大的图形功能;它提供了丰富的图形函数库,用一些简单的命令就可以完成多维数据的显示以及图像处理,也可以完成图形用户界面的设计,很方便地完成自己的运算和控制代码。
(3) 应用程序接口(API);它提供了应用程序接口函数库,允许用户使用C或C++语言编写程序与Matlab连接,本系统多处采用C语言编写的程序,采用MEX接口调用,弥补了Matlab速度慢的缺点。
PMT工具包是惠普开发公司提供的一个Matlab和C语言编写的概率模型包,它可以用来建立基本的静态和动态概率模型,目前支持的概率模型包括高斯混合、马尔可夫链、隐马尔可夫模型、线性动态系统等。对于每个概率模型都包括推理、学习的函数,采用最大似然估计来计算模型参数。由于工具包中很多核心函数是采用C语言编写的,提高了运行速度并且可以进行功能扩展。
2.1C-MEX技术
所谓MEX是Matlab Executable的缩写,即Matlab的可执行程序。在Windows操作系统中,它是以DLL为后缀名的文件。MEX文件是Matlab调用其他语言编写的程序算法接口。通过它,用户可以完成以下功能[98]。
(1)代码重用
可以在Matlab系统中像调用Matlab的内在函数一样调用已经存在的用C语言或C++语言编写完成的算法,通过添加入口程序mexFunciton,而无须将这些函数重新编写为Matlab的M文件,从而使资源得到充分利用。
(2)速度提升
当需要进行大量的数据处理时,Matlab的执行效率往往比较低,这时可以使用其他高级编程语言进行算法的设计,然后在Matlab环境中调用,从而大幅度提高数据处理的速度。在Matlab中,可以把含有大量循环迭代的代码用C语言代替,然后编译为MEX文件。
(3)功能扩展
通过MEX文件,用户可以服Matlab对硬件访问功能不足的缺点直接对硬件进行编程,如A/D采集,D/A输出卡等,以用于数据采集或控制,进一步扩展Matlab的应用领域。
2.2MEX文件结构与执行流程
MEX文件由两个部分组成,一部分是对mex.h头文件进行包含,该文件定义了矩阵的相关操作,另一部分是入口子程序,其构成形式如下:
void mexFunciton(int nlhs,mxArray *plhs[],intnrhs,const mxArray *prhs[]);
该函数包括四个参数,从右往左分别为一个mxArray结构体类型的指针数组prhs,该数组指向所有的输入参数;整数类型的nrhs,表示输入参数的个数;一个mxArray类型的指针数组plhs,它指向所有的输出参数;nlhs标明了输出参数的个数,为整数类型。这些参数是用来传递Matlab启动MEX文件的参数。
在该入口函数中,用户主要完成两个方面的任务。一方面,从输入的mxArray结构体中获取计算完毕的数据,然后在用户子程序中利用。另一方面,用户可以将计算完毕的结果返回给一个用于输出的mxArray的结构体,这样Matlab系统就能够识别从用户计算子程序返回的结果。
MEX文件的执行流程图如下:

图2-2 MEX文件执行流程图
三、系统实现
系统的运行主界面如图3-3所示。从运行主界面图可以看到,系统分为四个部分:数据集区、参数设置区、结果输出区和识别控制区。下面分别介绍这四个部分。
1、数据集区:它包括新增词汇、删除词汇及语音、语音录制以及载入训练集。新增词汇和删除词汇主要为训练语音库和测试语音库增加和删除新的类别。录制语音主要为各词汇采集语音文件,用于训练和识别。录制语音界面如图3-4。
2、参数设置区:它包括特征提取参数设置、端点检测参数设置、识别器参数设置。在特征参数类型中可选择并实现了的参数有MFCC、DAS-MFCC、RASTA-PLP、PNCC、APNSCC等。端点检测参数设置主要包括是否使用端点检测以及检查方法,本系统暂不考虑端点检测给识别结果带来的影响。识别器参数设置包括识别方法的选择(VQ 、HMM)及它们的参数设置(如HMM状态个数、高斯分量数)。图3-3 系统主界面图
图3-4 声音录制界面
3、结果输出区:主要用于输出系统操作状态信息以及识别结果信息等。
4、识别控制区:主要用于选择识别方式,主要分为测试语音数据识别、训练语音数据识别、单文件语音数据识别、批量语音数据识别、和实时语音识别(包含噪声语音识别)。测试语音数据和训练语音数据识别选项分别表示对所选数据库中的测试语音集合和训练语音集合进行识别,然后在输出模块输出该数据集的正确识别率。单语音识别对单个语音文件进行识别,给出识别结果。批量语音识别对多个语音进行识别,然后输出正确识别率(前提是这些语音文件已经加标签分类)。实时语音识别界面如图3-5所示:
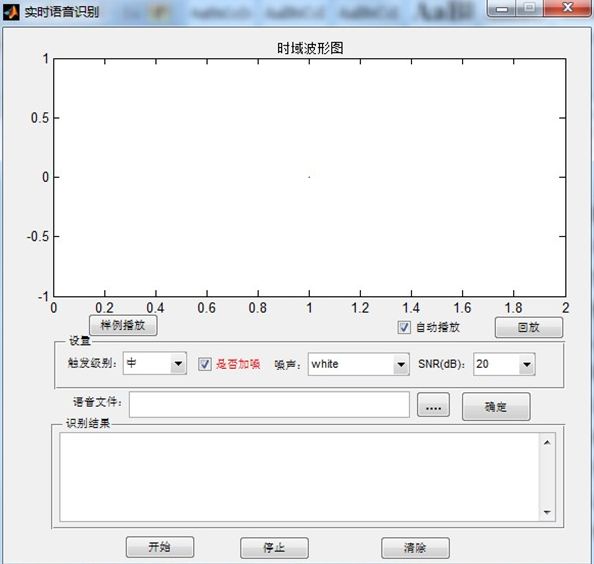
图3-5 实时语音识别界面
在图3-5中,开始按钮用于实时声音采集,然后将识别结果显示在输出框,单击停止按钮,中断信号的采集。除此之外,也可以采用单文件语音识别,选择要识别的语音文件,然后单击确定按钮就可以将识别结果输出在下面。实时语音识别和单文件语音识别都可以选择是否加噪,并且可以选择不同信噪比的多种噪声类型。由于实时声音采集识别速度比较慢并且不好控制环境噪声,这里实验采用事先录制好的单文件语音识别,然后加入各种不同的噪声。
系统的流程图如图3-6所示:
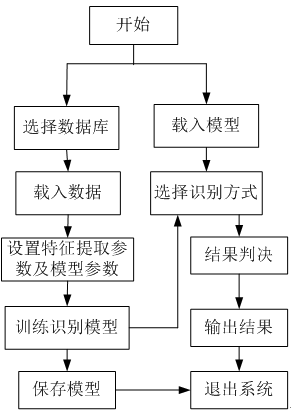
图3-6 系统流程图
从图3-6可以看到,本系统的流程大致分为两部分:第一部分是直接利用现有数据库进行训练识别模型进行实验,然后保存识别模型;第二部分是载入已经保存的模型来进行实验。通过该系统可以很方便地进行鲁棒性的语音识别实验。
系统实验演示见:http://pan.baidu.com/s/1o61Kaa2