scrapy爬取博客园粉丝关系

scrapy爬取博客园粉丝关系
作者:金良([email protected]) csdn博客:http://blog.csdn.net/u012176591
- scrapy爬取博客园粉丝关系
- 创建抽取的item类
- spider主程序
- 博客园网页特征
- 爬取到的数据展示
- 网页解析测试
- 断点续爬暂停和恢复
- cookies获取
- 缩进要一致
1.创建抽取的item类
文件名 items.py
其中 url 博客主页,name 为用户名, followers 为其粉丝列表。
from scrapy.item import Item, Field
class cnblogItem(Item): url = Field() name = Field() followers = Field() 2.spider主程序
文件名 cnblog_spider.py
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.selector import Selector
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.http import Request, FormRequest
from scrapy import Request
from cnblog.items import cnblogItem
#本爬虫执行方式
# scrapy crawl cnblog -o filename.json
class cnblogSipder(CrawlSpider) :
name = "cnblog" #爬虫名字
allowed_domains = ["home.cnblogs.com"]
start_urls = [
#"http://www.cnblogs.com/"
]
#rules = (
# #当前网页中符合allow要求的字段会加到allowed_domains后面组成一个网址,之后将对该网址进行分析
# Rule(SgmlLinkExtractor(allow = ('/u/[A-Za-z0-9_]+/$', )), callback = 'parse_page', follow = True),
#)
#经验证,在调用Request时如果不加入cookies参数,则不能以已登录用户身份登录页面,也就爬取不到只有已登录用户才能看到的数据
mycookies = {'__gads':r'***', '__utma':r'***',
'__utmz':r'***', 'lzstat_uv':r'***',
'_gat':r'***', '.DottextCookie':r'***',
'_ga':r'***',
'SERVERID':r'***',
'.CNBlogsCookie':r'***'
}
#重写了start_requests(self)方法, 首次爬取的网页是`http://home.cnblogs.com/u/jinliangjiuzhuang/`,解析函数是 `parse_home_page`。
def start_requests(self):
yield Request("http://home.cnblogs.com/u/jinliangjiuzhuang/", cookies = self.mycookies,callback=self.parse_home_page)
def parse_home_page(self,response):
#主页界面示例:http://home.cnblogs.com/u/LeftNotEasy/followees/
hostname = response.url.split('/')[-2]
host_followers_page_url = 'http://home.cnblogs.com/u/' + hostname + '/followers/'
host_followees_page_url = 'http://home.cnblogs.com/u/' + hostname + '/followees/'
r_host_followers_page_url = Request(host_followers_page_url, cookies = self.mycookies,callback=self.parse_followers_page)
item = cnblogItem()
item['url'] = response.url
item['name'] = hostname
item['followers'] = []
r_host_followers_page_url.meta['item'] = item
r_host_followees_page_url = Request(host_followees_page_url, cookies = self.mycookies,callback=self.parse_followees_page)
r = [r_host_followers_page_url,r_host_followees_page_url]
for i in range(2):
yield r[i]
def parse_followees_page(self,response): #我的关注
#关注界面示例:http://home.cnblogs.com/u/LeftNotEasy/followees/
sel = Selector(response)
find_avatar_list = sel.xpath(u'//div[@id="main"]/div[@class="avatar_list"]/ul/li/div[@class="avatar_name"]/a')
names = [i.extract().split('/')[2] for i in find_avatar_list]
home_page_urls = ['http://home.cnblogs.com/u/'+ name +'/' for name in names]
for url in home_page_urls:
yield Request(url, cookies = self.mycookies,callback = self.parse_home_page)
#进入下一页
next_href_list = sel.xpath(u'//div[@class="pager"]/a').extract()
href_list = [href for href in next_href_list if href.find('Next >')>0]
if len(href_list) > 0:
next_href = u'http://home.cnblogs.com' + href_list[0].split('"')[1] #下一页的网址
print 'The next followees page of the current host: \n ',next_href
yield Request(next_href, cookies = self.mycookies,callback = self.parse_followees_page)
def parse_followers_page(self,response): #我的粉丝
#粉丝界面网址示例:http://home.cnblogs.com/u/LeftNotEasy/followers/
sel = Selector(response)
item = response.meta['item']
find_avatar_list = sel.xpath(u'//div[@id="main"]/div[@class="avatar_list"]/ul/li/div[@class="avatar_name"]/a')
names = [i.extract().split('/')[2] for i in find_avatar_list]
item['followers'].extend(names)
home_page_urls = ['http://home.cnblogs.com/u/'+ name +'/' for name in names]
for url in home_page_urls:
yield Request(url, cookies = self.mycookies,callback = self.parse_home_page)
next_href_list = sel.xpath(u'//div[@class="pager"]/a').extract()
href_list = [href for href in next_href_list if href.find('Next >')>0]
if len(href_list) <= 0: #如果粉丝页面读取完毕,则返回item
yield item
else:#如果仍有粉丝页面未读,则携带当前item内容进入下一粉丝界面
next_href = u'http://home.cnblogs.com' + href_list[0].split('"')[1] #下一页的网址
print 'The next followees page of the current host: \n ',next_href
r = Request(next_href, cookies = self.mycookies,callback = self.parse_followers_page)
r.meta['item'] = item
yield r3.博客园网页特征
- 下一页的按钮
<div class="pager"><span class="current">1</span><a href="/u/gaizai/followers/2/">2</a><a href="/u/gaizai/followers/3/">3</a><a href="/u/gaizai/followers/4/">4</a><a href="/u/gaizai/followers/5/">5</a><a href="/u/gaizai/followers/6/">6</a><a href="/u/gaizai/followers/7/">7</a><a href="/u/gaizai/followers/8/">8</a><a href="/u/gaizai/followers/9/">9</a><a href="/u/gaizai/followers/10/">10</a><a href="/u/gaizai/followers/11/">11</a>···<a href="/u/gaizai/followers/23/">23</a><a href="/u/gaizai/followers/2/">Next ></a></div>
</div>- 最后一页没有下一页的按钮
<div class="pager"><a href="/u/gaizai/followers/22/">< Prev</a><a href="/u/gaizai/followers/1/">1</a>···<a href="/u/gaizai/followers/18/">18</a><a href="/u/gaizai/followers/19/">19</a><a href="/u/gaizai/followers/20/">20</a><a href="/u/gaizai/followers/21/">21</a><a href="/u/gaizai/followers/22/">22</a><span class="current">23</span></div>- 一个粉丝也没有,则没有
<div class="pager">内容
4.爬取到的数据展示

5.网页解析测试
程序中解析网页的工具是scrapy 自带的Selector,可以脱离scrapy项目直接用其进行解析网页语句的测试,待测试成功后再在scrapy项目中使用该语句。

6.断点续爬—暂停和恢复
爬取大的站点,我们希望能暂停爬取,之后再恢复运行,我们只需要在启动命令时添加-s参数,如下
scrapy crawl cnblog -o data.json -s JOBDIR=crawls/somespider-1启动后项目下多了如下所示的一个文件夹,项目运行时里面的文件内容是动态增减的
crawls
└─somespider-1
│ requests.seen
│ spider.state
│
└─requests.queue
active.json
p0
要暂停爬取过程,只需要点击一次(注:一定要仅点击一次,否则恢复时会出错)组合键Ctrl+C ,稍等一会,程序保存好相关数据就停止了。
要恢复状态继续运行,只需要再执行启动命令(如下)即可。
scrapy crawl cnblog -o data.json -s JOBDIR=crawls/somespider-1暂停和恢复过程的截图

7.cookies获取
博客园的粉丝数据需要用cookie才能获取到,所以有必要介绍一下cookie的获取过程。
- 首先用账号和密码登录博客园。
- 快捷键
Ctrl+shift+I打开开发者工具。 - 然后点击你的粉丝或关注
你会看到开发者工具里出现了好多内容,点击发送给服务器端的网页,Network->Headers,可以看到cookies数据。
将cookies数据整理成Python中的字典数据类型如下
mycookies = {'__gads':r'***', '__utma':r'***',
'__utmz':r'***', 'lzstat_uv':r'***',
'_gat':r'***', '.DottextCookie':r'***',
'_ga':r'***',
'SERVERID':r'***',
'.CNBlogsCookie':r'***'
}scrapy中cookies数据的用法:
Request(URL, cookies = self.mycookies,callback = self.parse)下面这张图帮助你寻找cookie的所在
上一张图的cookies数据比较乱,这张图将帮你看清cookie的条理,cookie的键和值整理好了,对应着cookies字典。
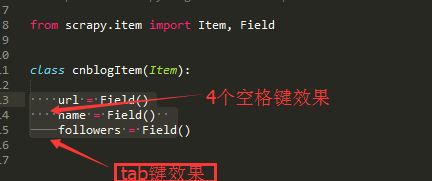
8.缩进要一致
Python缩进可以用 Tab 键和4个空格键达到同样的视觉效果,但是实际上Tab 键的缩进并不等于四个空格键,混用二者会导致程序运行出错。
在sublime中选定文本可以使Tab 键和 空格键 显出原形,如下
- Jobs: 暂停,恢复爬虫
http://scrapy-chs.readthedocs.org/zh_CN/latest/topics/jobs.html - a