Centos6.5 64位Hadoop完全分布安装教程
64位Centos6.5 Hadoop2.2.0 完全分布安装教程
本教程的环境搭建准备:
- 实体机Win7 64位
- putty 或 VNC 或 SSH Secure Shell Client
- Centos 6.5 版本
- Hadoop 2.2.0 版本(编译后64位)
- OpenJdk1.7.0
本教程配置说明
- 目的: 利用两台Linux服务器(实体机)搭建完全分布式hadoop
- 在window上通过putty(或其他)工具连接上Linux服务器,进行配置
- 在每台linux服务器上如无特殊说明,均默认在hadoop用户下操作
在hadoop用户下新建下面目录,代码如下
makdir ~/softwares
| 目录 | 用途说明 |
|---|---|
| softwares | 用于存放软件安装包 |
| hadoop2.2.0 | 用于存放Hadoop2.2.0解压目录 |
| dfs | 用于存放hadoop的数据目录 |
| tmp | 用于存放hadoop的管理目录 |
* 两台Linux服务器的分布及其配置说明
| 集群关系 | 主机名 | IP地址 | JDK版本 | 免密SSH |
|---|---|---|---|---|
| namenode | name | 10.10.108.160 | OpenJDK.7.0 | 能 |
| datanode | data2 | 10.10.108.180 | OpenJDK.7.0 | 能 |
具体配置可参考: 网络配置 , SSH 配置 , JAVA配置 , 创建用户
特别说明:以下步骤1~10,除了步骤2的hadoop环境变量配置,其余的只在name主机上完成!
1. 解压安装包
将已下载好的hadoop-2.2.0.tar.gz 存放在softwares目录下, 并解压至当前主用户目录下
Apache Hadoop 各个版本的下载地址:http://archive.apache.org/dist/hadoop/common/
mv hadoop-2.2.0.tar.gz ~/softwares/
tar zxvf ~/ softwares /hadoop-2.2.0.tar.gz -C ~/ 2. 配置Hadoop的环境变量
sudo vim /etc/profile在末尾加上以下配置,保存退出
export HADOOP_HOME=/home/hadoop/hadoop-2.2.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin3. 环境变量生效
sudo source /etc/profile4. 配置文件说明
| 配置名称 | 类型 | 说明 |
|---|---|---|
| hadoop-env.sh | Bash脚本 | Hadoop运行环境变量设置 |
| core-site.xml | xml | 配置Hadoop core,如IO |
| hdfs-site.xml | xml | 配置HDFS守护进程:NameNode、JournalNode、DataNode |
| yarn-env.sh | Bash脚本 | Yarn运行环境变量设置 |
| yarn-site.xml | xml | Yarn框架配置环境 |
| mapred-site.xml | xml | MR属性设置 |
| capacity-scheduler.xml | xml | Yarn调度属性设置 |
| container-executor.cfg | cfg | Yarn Container配置 |
| mapred-queues.xml | xml | MR队列设置 |
| hadoop-metrics.properties | Java属性 | Hadoop Metrics配置 |
| hadoop-metrics2.properties | Java属性 | Hadoop Metrics配置 |
| slaves | Plain Text | DataNode 节点配置 |
| log4j.properties | 系统日志设置 | |
| configuration.xsl |
5. 修改hadoop-env.sh
vim ~/ hadoop-2.2.0/etc/hadoop/hadoop-env.sh在里面找到JAVA_HOME一行,添加如下代码:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"注意:接下来的配置均在两个 configuration 之间添加完成的,如下图所示:

6. 修改core-site.xml
sudo vim ~/hadoop-2.2.0/etc/hadoop/core-site.xml添加如下代码:
<property>
<name>fs.default.name</name>
<value>hdfs://name:8020</value>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>Note: <value>hdfs://name:8020</value> 中的 name 为 NameNode 的主机名!
7. 修改yarn-site.xml
sudo vim ~/hadoop-2.2.0/etc/hadoop/yarn-site.xml添加如下代码:
<property>
<name>yarn.resourcemanager.address</name>
<value>name:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>name:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>name:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>name:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>name:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>Note: <value>name:8032</value> 中的 name 为 NameNode 的主机名,其他类似!
8. 修改mapred-site.xml
将mapred-site.xml.template复制mapred-site.xml
cp mapred-site.xml.template mapred-site.xml编辑mapred-site.xml文件
sudo vim ~/hadoop-2.2.0/etc/hadoop/mapred-site.xml添加如下代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>file:/home/hadoop/mapred/system/</value>
<final>true</final>
</property>
<property>
<name>mapred.local.dir</name>
<value>file:/home/hadoop/mapred/local/</value>
<final>true</final>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>name:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>name:19888</value>
</property>Note: <value>name:10020</value> 中的 name 为 NameNode 的主机名,其他类似!
9. 修改hdfs-site.xml
编辑mapred-site.xml文件
sudo vim ~/hadoop-2.2.0/etc/hadoop/hdfs-site.xml添加如下代码:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>10. 修改yarn-env.sh
添加JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64
11. 修改slaves
sudo vim ~/hadoop-2.2.0/etc/hadoop/slaves在slave文件里面添加所有的data节点的IP地址(或者主机名,前提是/etc/hosts 内已经增添了对应的关系表,本教程中在slaves文件中添加如下
data2
12. 拷贝hadoop-2.2.0到各个从节点上
配置好Hadoop的相关东西之后,请将hadoop-2.2.0整个文件夹拷贝到data2主机上面去
scp -r hadoop-2.2.0 hadoop@data2:/home/hadoop/13. 验证 hadoop
注意:以下步骤均在name主机上操作
A. 格式化HDFS
首先在master上面格式化一下HDFS,如下命令
hdfs namenode -format 大致出现如下界面就算格式化成功(图片仅供参考)

若格式化成功,在当前用户目录下会新增一个目录:dfs
B. 启动HDFS
start-dfs.sh启动成功之后,在name节点上运行
jps可以看到如下:
此时,在data2节点上运行 jps 能看到如下信息:
C. 启动YARN
start-yarn.sh启动成功之后,在name节点上运行 jps 可以看到如下:

此时,在data2节点上运行 jps 应该能看到如下信息:
此时hadoop集群已全部配置完成!!!
14. 运行hadoop自带wordcount程序
A. 找到examples例子
ls ~/hadoop-2.2.0/share/hadoop/mapreduce/B. 离开安全模式
hadoop dfsadmin -safemode leaveC. 先在HDFS创建几个数据目录
hadoop fs -mkdir -p /data/wordcount
hadoop fs -mkdir -p /output/D. 首先新建文件inputWord
vim ~/inputWord内容如下:
E. 将本地文件上传到HDFS中
hadoop fs -put ~/inputWord /data/wordcount/F. 可以查看上传后的文件情况,执行如下命令
hadoop fs -ls /data/wordcount
hadoop fs -text /data/wordcount/inputWordG. 运行WordCount例子,执行如下命令
hadoop jar ~/hadoop-2.2.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordcount /output/wordcountH. 查看结果,执行如下命令或登录到Web控制台,访问链接http://name:8088/ 可以看到任务记录情况
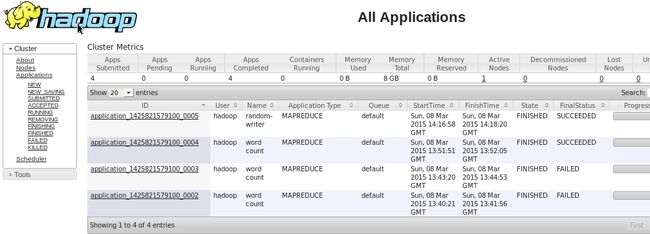
hadoop fs -text /output/wordcount/part-r-00000如果出现以下结果,则恭喜你,安装成功!不谢~
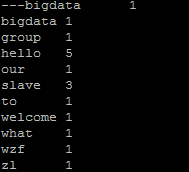
15. 一个陷阱
如果你执行的程序,出现以下关键字眼:
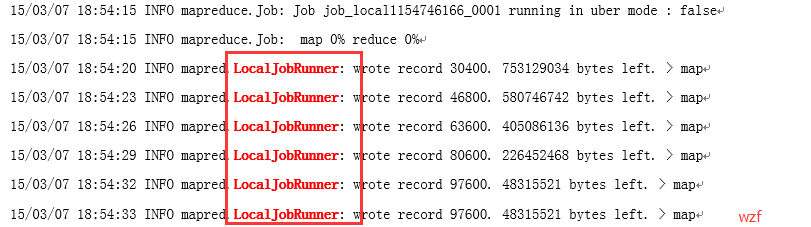
说明,你的 wordcount 还是运行在本地上,本质是伪分布安装。也就是说不管你执行哪个示例程序,启动的job都只是在master这个节点本地运行的job。
实际上,成功时输出的 INFO 为:

16. 安装过程中常见的错误及解决
Q1:namenode/datanode 没能全部同时启动(或启动后又瞬间挂了)
A: 观察两者之间的clusterID是否一致,一般是不一致才导致错误
cat ~/hadoop-2.2.0/dfs/name/current/VERSION
cat ~/hadoop-2.2.0/dfs/data/current/VERSIONR:删除原有的dfs目录,检查各项配置文件无误后,重新执行格式化 hadoop 步骤
Q2:hadoop伪分布式运行mapreduce命令,报连接拒绝错误
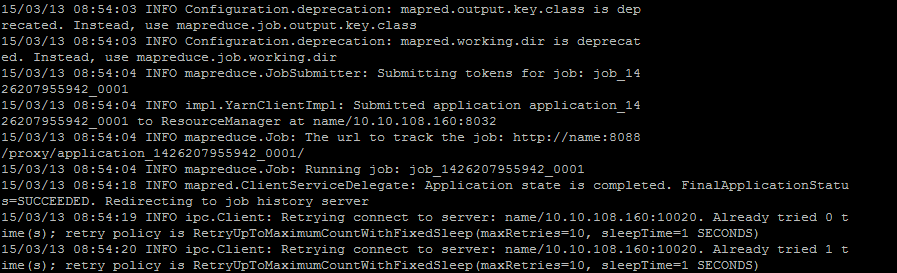
INFO mapred.ClientServiceDelegate: Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
A:需要启动 jobhistoryserver,配置historyserver,然后启动就可以了
R: 执行以下命令:
sbin/mr-jobhistory-daemon.sh start historyserverQ3:nodemanager启动后失败
问题描述:检查日志信息发现一直报本机与一个0.0.0.0的连接失败,然后继续与进行通信尝试一段时间后nodemanager失败。
A:nodemanager启动一段时间后会自动失败,检查日志,终于发现原来是与master节点通信失败造成的。通过检查配置文件知道8031端口出现 在yarn-site.xml配置文件的yarn.resourcemanager.scheduler.address配置项中。 yarn.resourcemanager.scheduler.address 是resourcemanager暴漏给nodemanager的地址和端口。nodermanager利用这个地址通过心跳机制与RM通信。正 常情况下我的NM应该与RM通信,但是NM却一直与0.0.0.0通信.因此查阅官方默认的yarn-site.xml配置文件,发现其中 yarn.resourcemanager.hostname的默认值被设置成:0.0.0.0了(怪不得一直与0.0.0.0通信)。发现原来是我设置 的主机ip在这里没有生效。
R:在yarn-site.xml中添加一项新的项,将yarn.resourcemanager.hostname的值修改为master机器的ip地址。