Centos6.5 64位Hadoop伪分布安装教程
64位Centos6.5 Hadoop伪分布安装教程
本教程配置说明
- 目的:给Hadoop初学者一个直观认识,为后续的完全分布打下基础
本教程的环境搭建准备:
- 实体机Win7 64位
- VMware Workstation 10.0.0 版本
- Centos 6.5 版本
- Hadoop 2.2.0 版本(编译后64位)
- JDK1.7 版本
注意事项(用户根据实际情况进行调整)
- 在root用户权限下安装下完成
- IP地址设置为192.168.1.123
- 本机DNS设置为 8.8.8.8
- 主机名设置为hadoop
- hadoop-2.2.0软件安装在 /opt 目录下
1. 先获取管理员权限!
su root 2. IP的配置(以配置静态ip为例)
1.新机器的IP配置(通过镜像安装机器)
vim /etc/sysconfig/network-scripts/ifcfg-eth0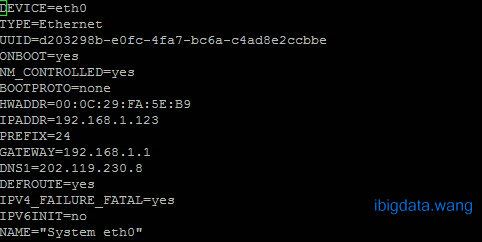
* IPADDR 为你索要指定的静态IP地址
2.克隆机器的IP配置(通过clone来安装机器)
vim /etc/udev/rules.d/70-persistent-net.rules 将其中的eth0注释掉,将eth1改成eth0
注意:此步骤当机子为虚拟机克隆时有效
3. 配置DNS
1.修改/etc/resolv.conf文件
vim /etc/resolv.conf2.在resolv.conf文件最后添加如下代码:
nameserver 202.119.230.8
nameserver 8.8.8.84. HOST的修改
vim /etc/hosts添加:
192.168.1.123 hadoop 5. 关闭防火墙和SElinux
1.关闭防火墙
service iptables stop2.永久关闭防火墙
chkconfig iptables off 3.关闭SElinux
vim /etc/sysconfig/selinux修改
SELINUX=disabled重启网卡
service network restart6. 安装配置JDK
查看JDK版本:
java –version显示如下(java版本1.70以上即可):

自带openJDK安装后的目录位于:/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.55.x86_64
修改环境变量文件
vim /etc/profile添加:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin令环境变量生效
source /etc/profile7. CentOS配置SSH使得无密码登陆
1. 查看SSH:如出现下图则跳过步骤2
rpm –qa | grep ssh
2. 安装SSH:
yum install ssh3. 启动SSH并设置开机运行:
service sshd start chkconfig sshd on4. 修改SSH配置文件,修改如下图:
vim /etc/ssh/sshd_config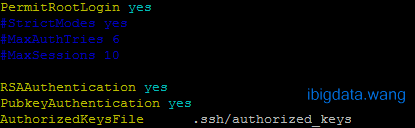
5. 重启SSH
service sshd restart6. 进入当前用户下,生成密钥
cd /root/
ssh-keygen -t rsa
chmod 700 -R .ssh一路回车,并进入.ssh 目录下
cd .ssh/
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys7. 检验能否无密码ssh登陆本ssh
ssh hadoop出现以下登录界面即可:

8. 解压hadoop-2.2.0
1. 将编译成功后的hadoop-2.2.0拷到 /opt 目录下:
友情提示:在Window下,可通过SSH Secure Shell Client 或 WinScp进行文件互传,不懂百度下
2. 解压安装包到当前目录下
tar –zxvf hadoop-2.2.0.tar.gz -C /opt/9. 添加hadoop-2.2.0环境变量
1. 编辑系统环境变量
sudo vim /etc/profile添加如下代码:
export HADOOP_PREFIX=/opt/hadoop-2.2.0
export CLASSPATH=".:$JAVA_HOME/lib:$CLASSPATH"
export PATH="$JAVA_HOME/:$HADOOP_PREFIX/bin:$PATH"
export HADOOP_PREFIX PATH CLASSPATH
export LD_LIBRARY_PATH=$HADOOP_PREFIX/lib/native/2. 环境变量生效
sudo source /etc/profile10. 修改hadoop-2.2.0配置文件
1. 进入配置文件目录下
cd /opt/hadoop-2.2.0/etc/hadoop 2. 配置hadoop-env.sh:
vim hadoop-env.sh添加如下代码:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib:$HADOOP_PREFIX/lib/native"注意:接下来的配置均在两个 configuration 之间添加完成的,如下图所示:

3. 配置core-site.xml:
vim core-site.xml在添加如下代码:
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.123:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.2.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value> file:/opt/hadoop-2.2.0/dfs/data</value>
</property>4. 配置hdfs-site.xml:
vim hdfs-site.xml添加如下代码:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.2.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.2.0/dfs/data</value>
</property>5. 配置mapred-site.xml.template:
vim mapred-site.xml.template添加如下代码:
<property>
<name>mapreduce.jobtracker.address </name>
<value>192.168.1.123:9001</value>
</property>6. 配置yarn-site.xml:
vim yarn-site.xml添加如下代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>7. 修改yarn-env.sh
vim yarn-env.sh 添加JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.45.x86_64
11. 启动Hadoop
1. 格式化hdfs
cd /opt/Hadoop-2.2.0/bin
./hadoop namenode -format出现下面则格式化成功:

2. 启动hadoop
cd /opt/hadoop-2.2.0/sbin
./start-dfs.sh ./start-yarn.sh- (注:若关闭Hadoop各个服务 则 ./ stop-all.sh )
此时键入jps,若出现以下界面,则祝贺你,安装成功!!!
