通过Nginx访问FastDFS文件系统并进行图片文件裁剪的性能测试和分析
前段时间公司的分布式图片文件系统(FastDFS)做了图片裁剪和缩放功能,并把缩放计算和FastDFS做了解耦分离,前端用虚拟机作为图片文件缩放的访问代理层(Nginx Proxy),后端使用nginx直接访问FastDFS的文件系统。以下是测试和分析过程。
1测试场景
为了测试解耦后的图片读取并发和分析系统瓶颈,我们在内网中搭建了一个测试环境。以下是测试环境的网络的物理架构图:
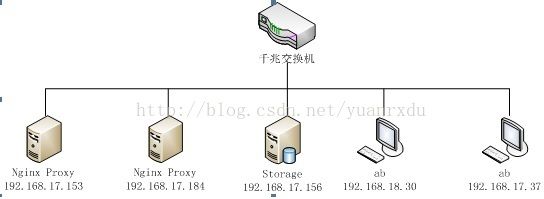
上图中:
NginxProxy:CPU解耦后的图片裁剪代理服务器
Storage:图片的存储服务器
ab:图片访问的模拟压力测试客户端
访问的原图大小:75KB,分辨率640 * 480
裁剪后的图片大小:23KB
Nginx Proxy的CPU:4核 2.5G
Nginx Proxy的内存:4G
2测试用例
所有测试的样本请求总数都是100000个
2.1 ab直接对storage获取原图

| Ab连接并发 |
TPS |
Storage CPU(%) |
请求失败数 |
响应延迟(ms) |
Storage带宽(KB/S) |
浏览器访问图片 |
| 32 |
1496 |
15% |
0 |
21 |
119313 |
无延迟感 |
| 64 |
1495 |
20% |
0 |
42 |
119728 |
无延迟感 |
| 128 |
1490 |
20% |
0 |
85 |
120299 |
无延迟感 |
| 512 |
1492 |
18% |
0 |
343 |
120157 |
稍微延迟,不明显 |
| 1024 |
1491 |
25% |
167 |
670 |
124660 |
稍微延迟,不明显 |
小结:
从上面的数据可以看出,这种方式的测试主要瓶颈是在网络带宽上,TPS的能力直接是受限于网络的带宽。CPU和内存不会是瓶颈。这里要注意的是我们采用的是访问同一种图片,所以无法分析磁盘IO的并发,关于Storage的磁盘IO并发我们在后面做详细的分析总结。
2.2 ab通过Nginx proxy访问图片
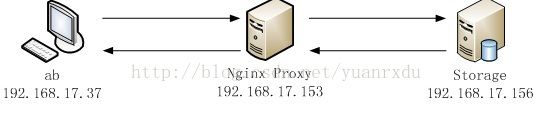
2.2.1原图访问
| Ab并发 |
TPS |
Proxy cpu(%) |
失败数 |
响应延迟(ms) |
Storage带宽(KB/S) |
浏览器访问图片 |
| 32 |
1213 |
30% |
0 |
26 |
102020 |
无延迟感 |
| 64 |
1254 |
30% |
0 |
51 |
102553 |
无延迟感 |
| 128 |
1287 |
40% |
0 |
99 |
104841 |
无延迟感 |
| 256 |
1321 |
42% |
0 |
193 |
110028.2 |
无延迟感 |
| 512 |
1337 |
45% |
0 |
381 |
108868.8 |
稍微延迟 |
| 1024 |
1354 |
48% |
0 |
755 |
115988 |
稍微延迟 |
小结:
这个case和2.1情况差不多,TPS稍有下降,proxy的CPU虽然比较高(没过50%),但是并发数是受storage带宽的限制。带宽是这种case最大的瓶颈.这里CPU高的原因是因为HTTP是短连接请求,nginx不停的受理来之ab的TCP请求和发起对storage的upstream的TCP请求导致的。
2.2.2裁剪图访问
| Ab并发 |
TPS |
Proxy cpu(%) |
失败数 |
响应延迟(ms) |
Storage带宽(KB/S) |
浏览器访问图片 |
| 32 |
264 |
89% |
0 |
121 |
21563 |
稍有延迟 |
| 64 |
273 |
97% |
0 |
234 |
23472 |
稍有延迟 |
| 128 |
279 |
100% |
0 |
458 |
24270 |
稍有延迟 |
| 256 |
278 |
100% |
0 |
917 |
27656 |
稍有延迟 |
| 512 |
277 |
100% |
0 |
1844 |
24646 |
稍有延迟 |
| 1024 |
274 |
100% |
0 |
3723 |
18408 |
明显延迟 |
小结:
这个case的测试数据可以看出,NginxProxy的CPU成为整个系统的瓶颈,TPS只有280左右。Storage的带宽还有近100M的富余。在这种情况测试后,我们增加一个PROXY来进行测试。
2.3 通过两台Nginx Proxy访问裁剪图片
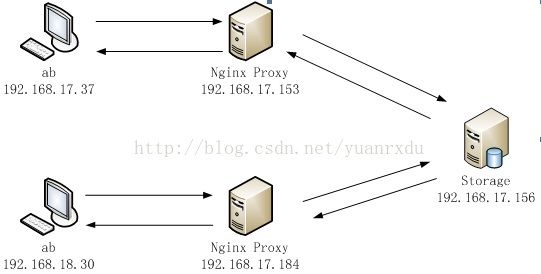
有两个ab客户端同时发起测试请求,例如64个并发,那么每个ab 发起32个并发
| Ab并发 |
TPS |
Proxy cpu(%) |
失败数 |
响应延迟(ms) |
Storage带宽(KB/S) |
浏览器访问图片 |
| 64 |
497 |
86% |
0 |
127 |
40133 |
稍有延迟 |
| 128 |
529 |
95% |
0 |
242 |
44907 |
稍有延迟 |
| 256 |
548 |
98% |
0 |
464 |
45048 |
稍有延迟 |
| 512 |
551 |
100% |
0 |
920 |
47411 |
稍有延迟 |
| 1024 |
553 |
100% |
0 |
1821 |
47745 |
稍有延迟 |
| 2048 |
552 |
100% |
0 |
3725 |
50552 |
明显延迟 |
小结:
这个case和2.2.2的case比较可以得出,增加NginxProxy的数量在Storage有富余带宽的情况下是基本成线性增长的关系。在Storage 磁盘IO无线和1G带宽的情况下,一个Storage可以挂在4核 2.5GHZ CPU运算能力的proxy最多4个。
3测试结果分析
3.1 CPU
从以上4个测试case的结果看,耗CPU的主要是在图片的裁剪上。根据2.2.2的测试数据,我们可以得出一个基本的CPU与裁剪图片的数据之间的关系,如下:
在CPU100%的时候,Storage上的带宽是24270KB。那么1GHZ运能能力能裁剪大概的带宽数据:
1GHZ每秒裁剪的带宽数据 = 24270KB / (4 * 2.5G) = 2427KB =2.4MB
1GHZ每秒裁剪的图片数 = 279 / (4 * 2.5G) = 28张。(分辨率640 x 480 成 300 x 300)
因为线上生产环境是原图套图和裁剪图混合访问,1GHZCPU的实际运算能力应该在40 ~ 50左右。这个具体要看各种图片的分布比例。
3.2内存
在整个测试过程中,Nginx Proxy的每个进程的内存始终保持在50M左右。如果在Storage和Proxy之间带宽不足或者网络不稳定的情况下,Proxy的内存将会大大增加(在10月21日的测试中,4个nginx总共占用了1.7G的内存),这是由于图片分片从storage发送过来时,Proxy需要在内存中拼接图片导致的。
3.3磁盘IO
这个测试过程中,我们始终都是访问同一张图片,所以不存在磁盘IO的测试。我们可以根据SATA硬盘(7200转速)的一些特性做随机文件访问的分析。基于LevelDB和innoDB引擎对SATA硬盘的两个基本参数我们可以做具体的分析。这两个参数是:
1、 磁盘在seek一次需要耗费10ms左右的时间
2、 磁盘顺序读取1M数据到内存需要10ms左右的时间。
基于我们的Storage上都是随机访问小文件(大部分100KB~ 200KB以内),那么Storage在读取一个小文件的时候必须seek一次,在进行顺序读取。我们线上环境有各种图片格式,大小不一,我们暂且以图片大小平均100KB来分析。
从上面两个参数我们很容易知道随机读取一张100KB的图片大概需要的时间:
Readdelay = seek + read time = 10ms + 10ms / 10 = 11ms;
那么一秒钟我们单个SATA盘最大可以读取的图片数:
Percount = 1000 / 11 = 90张。
线上环境一般是单个Storage配置12个SATA盘。那么一个Storage最大可以的图片数:
Maxread count = 90 * 12 = 1080张。
如果考虑文件的PageCache的话,Max Read count可能会略大于这个数字。
这个计算仅仅是12个磁盘全部用于读,没有 写的情况。在实际情况是有写的,因为商家会不定时增加或者修改图片,Max read count在实际系统中是会小于1080张的。尤其是在遇到类似图片搬家之类操作时,磁盘的IO能力会大大打折扣。
从这个分析结果再对比我们2.1中的TPS = 1495可以看出,Max readcount < TPS,也就是说如果Storage的带宽是千兆,那么带宽是大于磁盘IO的,所以在带宽达到极限之前,磁盘IO首先会成为瓶颈。从上面分析的结果我们可以得出,一个Storage磁盘IO读的TPS 在600 ~ 700左右就应该是瓶颈了。
3.4网络带宽
通过上面4个CASE,我们基本知道Storage和Nginx Proxy之间的带宽是一个很重要的因素。因为做了CPU解耦,无疑增加了一次原图拉取的开销。我们线上环境可能是采用如下的物理网络拓扑:

如果Nginx Proxy集群的CPU运算能力和右边的Storage集群的磁盘IO都能力超过交换机之间的网络传输能力的话,那么瓶颈就会在交换机之间的带宽上。我们还是以原图平均大小为100KB来计算,如果交换机之间是千兆网络,那么转换成字节带宽为:
Bandwidth=1024 mb / 8 = 128MB
proxy集群每秒能同时获得的原图数:
PerPic count = 128M / 0.1 = 1280张。
这里的计算并没有除去TCP本身的净核,一般用到120M就是比较高效的。也就是说最多不超过1200张图片。
4结论
我们可以初步按照2.2.2的case和3.3的磁盘IO分析得出基本的proxy/storage和带宽之间的对应关系。我们可以得出一个基本的结论:
50GHZ的CPU运算能力每秒可以裁剪近1200~1500张图片,带宽在120MB/S.
3台storage除去磁盘IO写负载,大概每秒能读取1000 ~ 1100张图片。
配上1GB的传输带宽。