openfire + spark 搭建聊天系统
openfire是服务器,spark是客户端
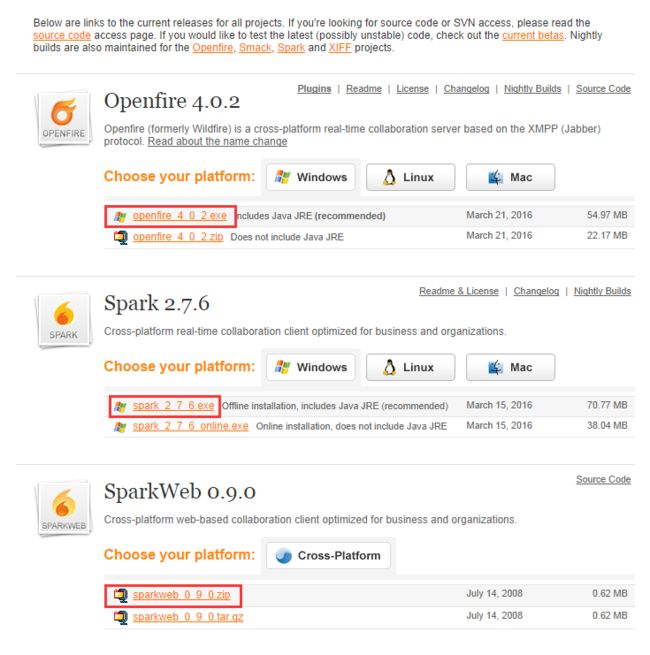
下载地址:http://www.igniterealtime.org/downloads/index.jsp
下载红框内的文件,Openfire如果你的机器为64位的话不要下载zip,因为zip默认是32位的,会启动失败
全部下载完后先安装openfire服务端,可参考此教程:http://www.cnblogs.com/hoojo/archive/2012/05/17/2506769.html
接着安装spark桌面客户端,正常安装即可
最后安装sparkWeb,这部分有点麻烦,需要把他部署在tomcat服务器上,解压sparkweb_0_9_0.zip到tomcat的webapp下,启动tomcat即可
访问地址为http://localhost:8080/sparkbweb/SparkWeb.html
全部安装完成后,接下来是添加用户,可以注册,也可以后台添加
后台添加用户方式如下:
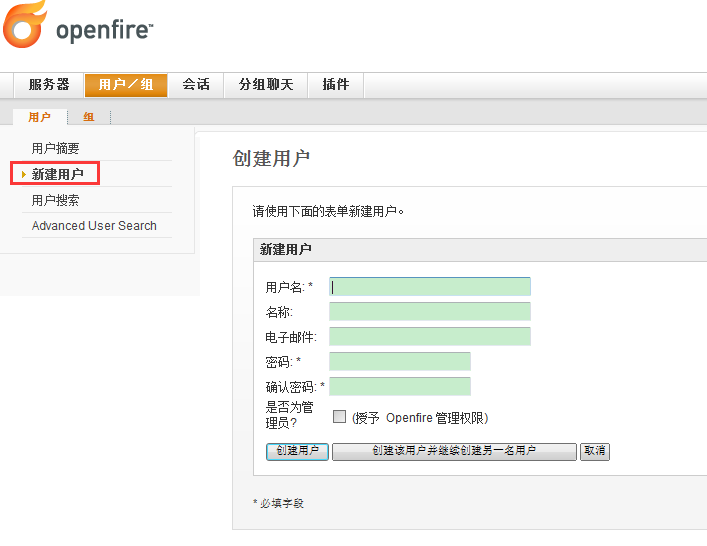
浏览器输入http://127.0.0.1:9090/ 登录到Openfire后台,点击用户/组,新建用户,如图
创建完成运行spark桌面客户端,使用用户名密码登录即可
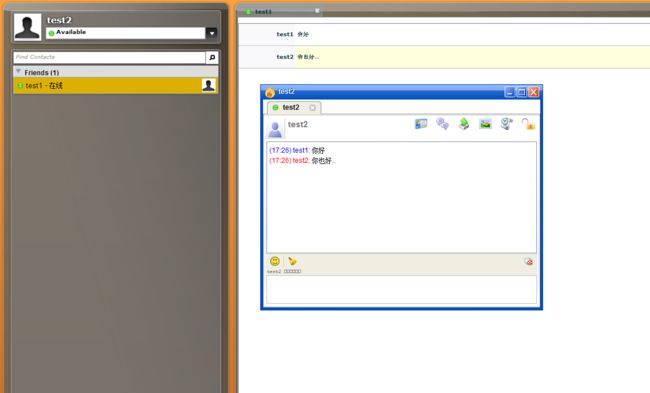
最后效果图:
参考文章:
http://www.cnblogs.com/luxiaofeng54/archive/2011/03/14/1984026.html 基于XMPP协议的手机多方多端即时通讯方案
http://www.cnblogs.com/hoojo/archive/2012/05/17/2506769.html Openfire 的安装和配置