Hadoop-2.5.0-cdh5.3.2 启动过程详解
- 一 Hadoop 启动过程详解
- 1 启动ZooKeeper集群
- 2 格式化 ZooKeeper 集群目的是在 ZooKeeper 集群上建立 HA 的相应节点
- 3 启动JournalNode集群
- 4 格式化集群的 NameNode
- 5 启动刚格式化的 NameNode
- 6 同步 NameNode1 元数据到 NameNode2 上
- 7 启动 NameNode2
- 8 启动集群中所有的DataNode
- 9 在 RM1 启动Yarn
- 10 在 RM2 单独启动 YARN
- 11 启动 ZKFC
- 12 开启历史日志服务
- 13 总结
- 二 常见问题
一. Hadoop 启动过程详解
注意:在启动之前务必将配置文件都检查清楚,包括环境变量设置且生效,最后要严格按照以下的步骤启动。
1.1 启动ZooKeeper集群
在集群中安装 ZooKeeper 的主机上启动 ZooKeeper 服务。在本教程中也就是在 slave51、slave52、slave53 的主机上启动相应进程。分别登陆到三台机子上执行:
zkServer.sh start以 slave52 为例:

- 读取了 $ZOOKEEPER_HOME/conf/zoo.cfg 这个配置文件并成功启动了
- 当前 slave52 是选举出来的 leader ,剩下的 slave51 和 slave53 自然就是 follower
- 最重要的就是启动了 Zookeeper 的主进程 QuorumPeerMain
在 slave51、slave52、slave53 的任意一台机子上执行 ZooKeeper 客户端连接命令以验证:
zkCli.sh
ls /
- 可以看到 ZK 集群 中只有一个节点 zookeeper
1.2 格式化 ZooKeeper 集群,目的是在 ZooKeeper 集群上建立 HA 的相应节点
在任意的 namenode 上都可以执行,笔者还是选择了 master5 主机执行格式化命令,此操作仅仅表示和 zk集群发生关联
hdfs zkfc –formatZK截取了部分的控制台输出信息:

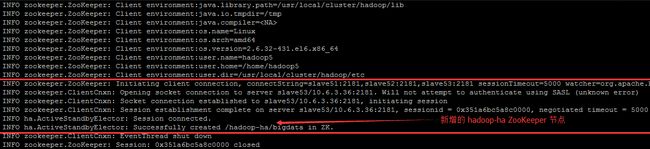
随便挑一台 ZooKeeper 的主机进行验证,如直接在 slave51 上执行:
zkCli.sh
ls /
ls /hadoop-ha
ls /hadoop-ha/bigdata出现如下即可(其中 bigdata 是你在 hdfs-site.xml 文件中设置的集群名称):

1.3 启动JournalNode集群
分别在 slave51、slave52、slave53 上执行,这些机器之前已经在 hdfs-site.xml 的 dfs.namenode.shared.edits.dir 属性中设置过的
hadoop-daemon.sh start journalnode
这三台机器一定都要出现 JournalNode 进程,且在 /usr/local/cluster/data 本地磁盘路径下生成一个 journal 目录,作用是给用户保存 NameNode 的 edits 文件的数据(该路径在 hdfs-site.xml 中自定义设置)。接着可以查看相应的 log 文件
vim /usr/local/cluster/hadoop/logs/hadoop-hadoop5-journalnode-slave51.log
- 绑定了 Web-server 8040 端口和 ipc.Server 的监听端口 8045 ( 在 hdfs-site.xml 中设置 )
1.4 格式化集群的 NameNode
在 master5 的主机上执行以下命令,以格式化 namenode:
hdfs namenode -format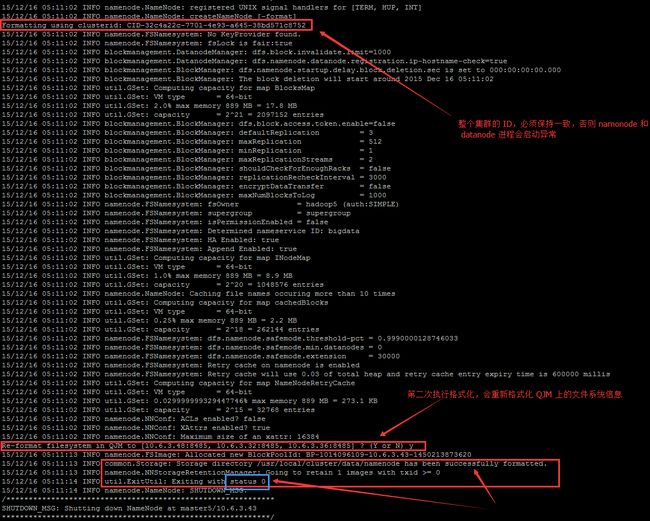
- /usr/local/cluster/data/namenode/current/VERSION 文件中的 clusterID 就是在图中 CID-6d9c34e0-9d84-45be-8442-be73a03ddea8 ,整个集群(namenode 和 datanode ) 的 clusterID 一定要确保一致!
- 格式化 NameNode 会在磁盘 /usr/local/cluster/data/ 目录下会出现产生 namenode、edit_files 目录(该这两个路径在 hdfs-site.xml 中设置)
- namenode目录用于保存 NameNode 的 fsimage 、fsimage.md5 、seen_txid 、VERSION 文件
- edit_files 目录用于保存 NameNode 的 edits 、
seen_txid、VERSION 文件 - 以上两个目录一般来说在同一目录下,但是为了区分管理,笔者将其分开在不同目录下喽~
- 在 hdfs-site.xml 文件中设置 namenode 和 datanode 的文件存储位置时,网上大部分教程是直接写
/usr/local/...,这样会出现如下警告信息,正确的配置笔者已经在 hdfs-site.xml 中指出了
Path /usr/local/cluster/data/namenode should be specified as a URI in configuration files. Please update hdfs configuration- 但是日志中出现这 Warning ,笔者仍旧百思不得其解啊,明明已经配置 dfs.namenode.name.dir 和 dfs.namenode.edits.dir 了呀….(相关资料:https://issues.apache.org/jira/browse/HDFS-3612)
WARN org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Only one image storage directory (dfs.namenode.name.dir) configured. Beware of data loss due to lack of redundant storage directories!1.5 启动刚格式化的 NameNode
刚在 master5 上格式化了 namenode ,故就在 master5 上执行
hadoop-daemon.sh start namenode出现如下 namenode 进程 :

此时在 $HADOOP_HOME/logs 下产生 3 个文件

查看其中的 log 文件,可以看到

- web 服务已经开启,通过网页即可查看 namenode 的状态:
http://master5:50070(http://10.6.3.43:50070)
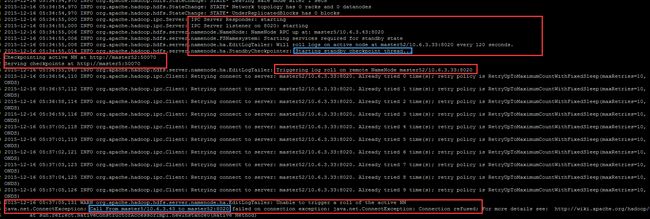
- 因为设置为 HA 自动选举,所以一开始在 mster5 上启动的这个 namenode 是 Standby 模式
- 每隔 120 秒循环登陆到 master52/10.6.3.33:8020 上的 active node ,但是因为 master52 还没有启动 namenode ,所以肯定
failed on connection
1.6 同步 NameNode1 元数据到 NameNode2 上
复制你的NameNode 上的元数据目录到另一个 NameNode,也就是此处的 master5 复制元数据到 master52 上。在 master52 上执行以下命令:
hdfs namenode -bootstrapStandby
- 在 /usr/local/cluster 下生成了 data 目录,且该 data 目录下的含有与 master5 相同的 namenode 目录,甚至里面的文件都一样(除了 in_use.lock 这个文件)
- in_use.lock文件里面此时内容为 “29082@master5” ,含义是 “master5” 主机上 “29082” 的 namenode 进程是当前用户锁 (lock) 信息
1.7 启动 NameNode2
master52 主机拷贝了元数据之后,就接着启动 namenode 进程了,执行
hadoop-daemon.sh start namenode在 master52 上出现 namenode进程

查看相应的日志文件,发现:
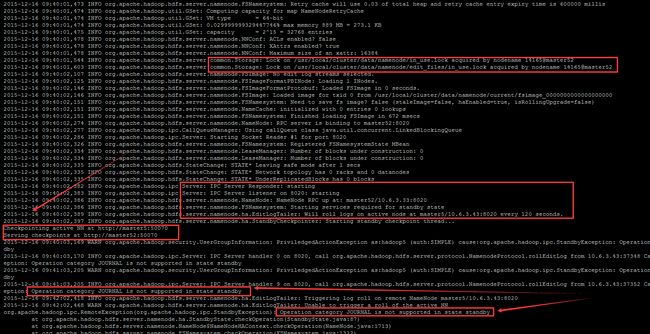
此时,在浏览器栏里分别输入
http://10.6.3.43:50070/dfshealth.html#tab-overview
http://10.6.3.33:50070/dfshealth.html#tab-overview- 在 master5 (10.6.3.43) 的 50070 端口可以看到如下界面,standby 状态:
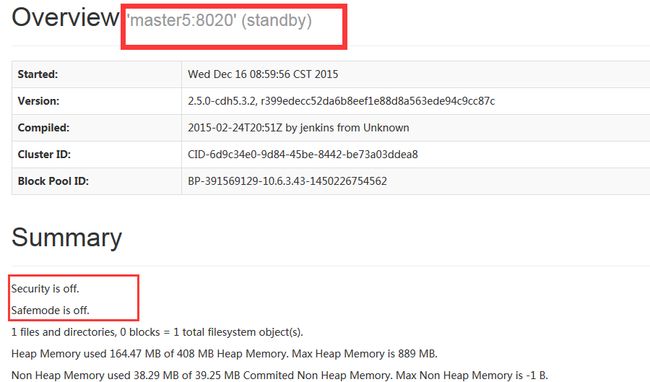
- 在 master52 (10.6.3.33) 的 50070 端口可以看到如下界面,standby 状态:
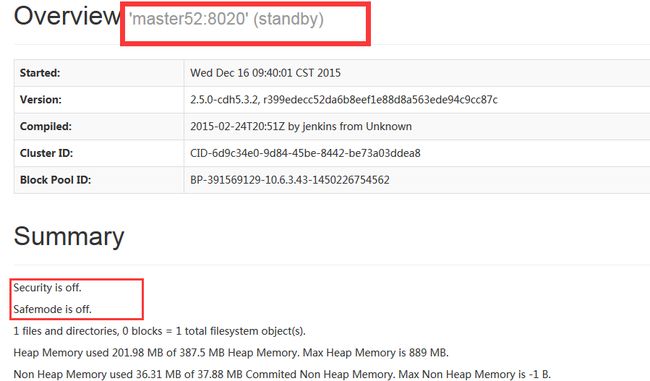
1.8 启动集群中所有的DataNode
在 master5 上执行
hadoop-daemons.sh start datanode千万别错写成 hadoop-daemon.sh 了,这个仅对本机起作用。而 hadoop-daemons.sh 是对 slaves 文件里的主机起作用
在 master5 (master52进程也一样)上显示:

- 在各个 slave 的上的进程(以 slave51 为例)

- 各个 slave 主机上 在 /usr/local/cluster/data/ 路径下生成 datanode 目录(路径在 hdfs-site.xml 设置)
- 其中 in_use.lock 文件里面此时内容为 ” 32016@slave51”,含义是 “slave51” 主机上 “32016” 的 datanode 进程是当前用户锁 (lock) 信息
- 同时在 slave51、slave52、slave53 的 /usr/local/cluster/data/journal 路径下,出现了 “bigdata” 以集群名称为命名的目录,里面自然就存放着平时由 Active NameNode 所记录的 edits 文件的数据
1.9 在 RM1 启动Yarn
在 master5 的主机上执行以下命令:
start-yarn.sh在 master5 的主机上查看进程多了 ResourceManager:

在 slave51、slave52、slave53 上查看到进程多了 NodeManager

此时在浏览器输入 10.6.3.43:8088 ,可以看到
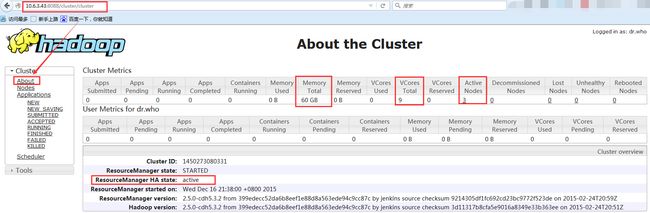
- 在 RM2 还没启动 ResourceManager 进程时,已经是 Active 状态了(因为 ActiveStandbyElector 已经在内部用于选择活动的 RM)
- Active Nodes 总共 3 个 (slave51、slave52、slave53)
- VCores Total 总共 3*3=9 个 (在 yarn-site.xml 中的 yarn.nodemanager.resource.cpu-vcores 属性中设置的)
- Memory Total 总共 3*20=60G (在 yarn-site.xml 中的 yarn.nodemanager.resource.memory-mb 属性中设置的)
查看相应的日志,可以看到正常启动流程
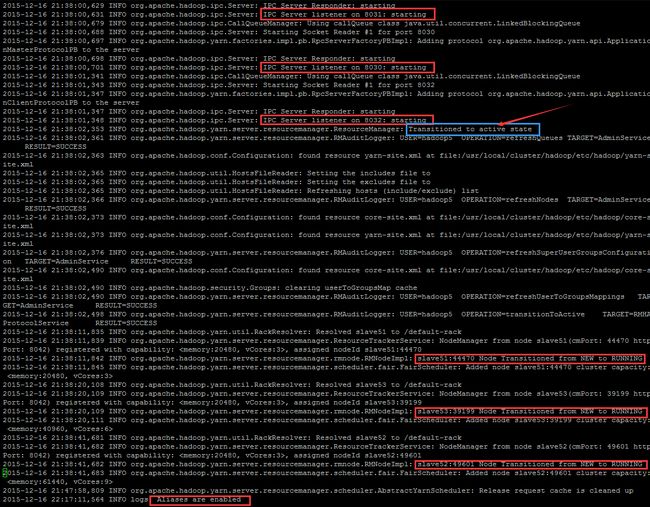
但是发现了如下的 INFO 和 WARN
INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Using Scheduler: org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
WARN org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.AllocationFileLoaderService: fair-scheduler.xml not found on the classpath
原因是该版本的 Hadoop 使用的是 Fair Scheduler 的多用户公平调度器。出现 WARN 的原因是未自定义配置文件 fair-scheduler.xml(原先不存在)。解决办法
- 配置 yarn-site.xml 文件中的 yarn.scheduler.fair.allocation.file属性,指定自定义 XML 配置文件所在位置
- 在
$HADOOP_HOME/etc/hadoop路径下创建一个 fair-scheduler.xml 文件 - 上述的 yarn-site.xml 主要配置调度器级别的参数
- 上述的 fair-scheduler.xml 文件中主要配置各个队列的资源量、权重等信息
1.10 在 RM2 单独启动 YARN
虽然上一步启动了 YARN ,但是在 master52 上是没有相应的 ResourceManager 进程,故需要在 master52 主机上单独启动:
yarn-daemon.sh start resourcemanager在 master52 上多出了 ResourceManager 进程:

同时在浏览器输入 10.6.3.33:8080 ,可以看到
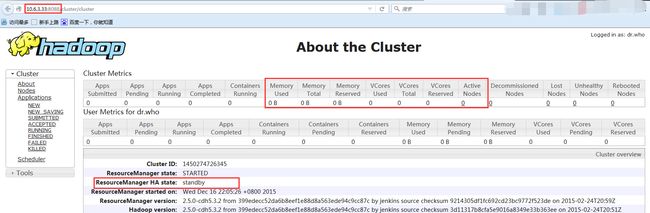
点击左边其他的 Nodes 等栏目时弹出
![]()
- 启动时已经是 standby 状态了
- 不提供 RM 功能了,将所有的网页请求重定向到当前 active RM: http://master5:8088/cluster/
查看相应的日志,可以看到正常启动流程

1.11 启动 ZKFC
在 master5 和 master52 的主机上分别执行如下命令:
hadoop-daemon.sh start zkfc在 master5 和 master52 上都可以看到多出了 DFSZKFailoverController 进程

在 master5 打开相应的日志文件可以看到 (截取):
vim /usr/local/cluster/hadoop/logs/hadoop-hadoop5-zkfc-master5.log // 该 log 是上图中出现的那个 log
- 初始化客户端与 ZooKeeper 服务器,与 slave51、slave52、slave53 伺机连接,会话超时设置为 5000,同时设置 watcher 为 ActiveStandbyElector$WatcherWithClientRef@146044d7
- 最终与 ZooKeeper server 中的 slave51/10.6.3.48:2181 成功完成会话建立
- 检查有没有旧的 active namenode 需要被隔离 (fence),因为是刚建立,所以肯定是 no old active node
- 在 ZooKeeper 的 /hadoop-ha/bigdata 的路径下创建了 ActiveBreadCrumb,该路径下还有 ActiveStandbyElectorLock
- 最后就是成功将 master5 转化为 Active 状态(若希望 master52 为 Active 可以先开启 master52 上 ZKFC 服务)
在 master52 打开相应的日志文件可以看到 (截取):
vim /usr/local/cluster/hadoop/logs/hadoop-hadoop5-zkfc-master52.log
此时在浏览器上输入:
http://10.6.3.43:50070/dfshealth.html#tab-overview
http://10.6.3.33:50070/dfshealth.html#tab-overview

1.12 开启历史日志服务
在 master5 和 master52 的主机上执行
mr-jobhistory-daemon.sh start historyserver在 master5 和 master52 上可以看到多出的 JobHistoryServer 进程

其中在 master5 查看相应日志:
vim /usr/local/cluster/hadoop/logs/mapred-hadoop5-historyserver-master5.log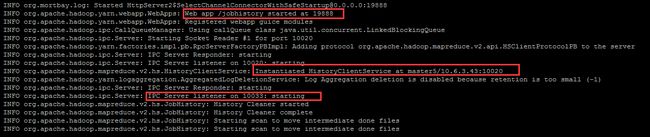
在浏览器上输入 http://10.6.3.43:19888/jobhistory 可以看到如下
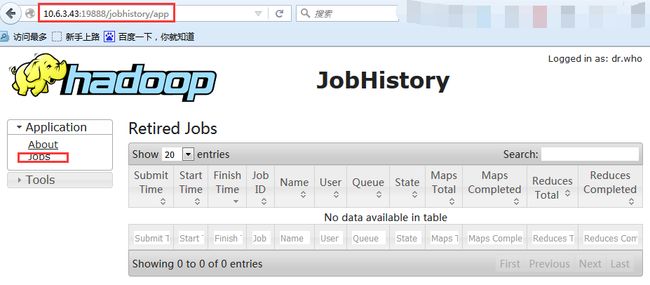
master52 也是分析过程和浏览器查看过程也是一样的,仅是输入的浏览器地址不同:http://10.6.3.33:19888/jobhistory
1.13 总结
安装完成后各节点上的进程:主机规划
二. 常见问题
1. 我启动 ZKFC 和 NameNode 守护进程的顺序重要么?
不重要,在任何给定的节点上,你可以任意顺序启动 ZKFC 和 NameNode 进程
2. 我应该在此增加什么样的监控?
你应该在每一台运行 NameNode 的机器上增加监控以确保 ZKFC 保持运行。在某些类型的 Zookeeper 失效时,例如,ZKFC 意料之外的结束,应该被重新启动以确保,系统准备自动故障转移。
除此之外,你应该监控 Zookeeper 集群中的每一个 Server。如 Zookeeper 宕机,自动故障转移将不起作用。
3. 如果Zookeeper宕机会怎样?
如果 Zookeeper 集群宕机,没有自动故障转移将会被触发。但是,HDFS 将继续没有任何影响的运行。当Zookeeper 被重新启动,HDFS 将重新连接,不会出现问题。
4. 我可以指定两个 NameNode 中的一个作为主要的 NameNode 么?
当然不可以。目前,这是不支持的。先启动的 NameNode 将会先变成 Active 状态。你可以指定的顺序,先启动你希望成为 Active 的节点,来完成这个目的。
5. 自动故障转移被配置时,如何发起一次手工故障转移?
即使自动故障转移被卑职,你也可以用 hdfs haadmin 发起一次手工故障转移。这个命令将执行一次协调的故障转移。
6. 当NameNode发生故障时,他们的数据如何保持一致哪?
2 个 NameNode 的数据其实是实时共享的。新 HDFS 采用了一种共享机制,JournalNode 集群或者 NFS 进行共享。NFS 是操作系统层面的,JournalNode 是 hadoop 层面的,我们这里使用 JournalNode 集群进行数据共享。
7. HDFS Federation(HDFS联盟)是怎么回事?
联盟的出现是有原因的。我们知道 NameNode 是核心节点,维护着整个 HDFS 中的元数据信息,那么其容量是有限的,受制于服务器的内存空间。当 NameNode 服务器的内存装不下数据后,那么 HDFS 集群就装不下数据了,寿命也就到头了。因此其扩展性是受限的。HDFS 联盟指的是有多个 HDFS 集群同时工作,那么其容量理论上就不受限了,夸张点说就是无限扩展。
8. 为什么 namenode 和 datanode 没能全部同时启动?
检查配置文件无误后,看看是否是因为 namenode 和 datanode 之间的 clusterID 不一致造成的,而这个 clusterID 可以在 hdfs-site.xml 中所设置的 dfs.namenode.edits.dir 和 dfs.datanode.data.dir 路径下的 Version 文件中查看到。
参考资料
- HDFS High Availability Using the Quorum Journal Manager
- Hadoop-2.3.0-cdh5.0.1完全分布式环境搭建(NameNode,ResourceManager HA)
- hadoop2 搭建自动切换的ha集群 yarn集群
- 详细讲解hadoop2的automatic HA+Federation+Yarn配置的教程