Impala1.1.1 安装使用
一、介绍
Impala 号称在性能上比Hive高出3~30倍,甚至预言说在将来的某一天可能会超过Hive的使用率而成为Hadoop上最流行的实时计算平台。
Impala的三个组件说明:
- impalad :Implala的后台进程,需要安装在每一台数据节点上
- statestored:用于协调各个运行impalad的实例之间的信息关系。选择集群中一个节点安装.
- impala-shell : Impala的命令行接口,可以安装在非集群节点,使用远程方式连接到Impala服务器。
二、安装
我们在集群中安装impala
- 安装cdh4(略)详细可以参看Cloudera CDH4的安装笔记
- 安装配置Hive metastore(略)详细可以参考文章Hive相关安装详解
- 执行下面命令,安装impala包
sudo yum install impala # Binaries for daemons
sudo yum install impala-server # Service start/stop script
sudo yum install impala-state-store # Service start/stop script
安装包有100M以上,所以如果网络不行,可以先下载相应的安装包。地址:http://www.cloudera.com/content/cloudera/en/products/cdh/impala.html
三、配置
拷贝core-site.xml hdfs-site.xml hive-site.xml这三个文件到/etc/impala/conf目录下。
1)配置hive-site.xml
Impala依赖与hive metadata来提供impala需要的元数据库的信息,因此必须配置hive.metastore.uris,启动hive-metadata服务。
2)配置hdfs-site.xml文件
3)Short-Circuit Reads(必须)
开启short-circuit reads可以允许Impala直接读取文件系统额数据,免去了与Datanodes通信的必要。因此可以提升Impala的性能。Short-circuit reads依赖libhadoop.so,服务端和客户端都会使用到它。
The text _PORT appears just as shown; you do not need to substitute a number.
修改impala的core-site.xml
修改hdfs-site.xml
注意:这个官网上说要配成true,但是实际上配成false才成功
4)Block Location Tracking(可选)
Enabling block location metadata allows Impala to know which disk data blocks are located on, allowing better utilization of the underlying disks.
修改hdfs-site.xml
5.配置impala启动参数
Impala启动的时候需要知道master的 state store的地址,还需要设置一些自身的端口和内存参数。配置文件是/etc/default/impala。
IMPALA_STATE_STORE_HOST=192.168.1.57
IMPALA_STATE_STORE_PORT=24000
IMPALA_BACKEND_PORT=22000
IMPALA_LOG_DIR=/var/log/impala
IMPALA_STATE_STORE_ARGS=" -log_dir=${IMPALA_LOG_DIR} -state_store_port=${IMPALA_STATE_STORE_PORT}"
IMPALA_SERVER_ARGS=" \
-log_dir=${IMPALA_LOG_DIR} \
-state_store_port=${IMPALA_STATE_STORE_PORT} \
-use_statestore \
-state_store_host=${IMPALA_STATE_STORE_HOST} \
-be_port=${IMPALA_BACKEND_PORT}"
ENABLE_CORE_DUMPS=false
现解释下各参数:
1.IMPALA_STATE_STORE_HOSTImpala starte store的地址,需要配置让每台Impalad服务连接到state store
2.内存限制
由于Impalad运行时占用大量内存,因此为了安全我们需要限制Impala内存的使用。这里我们限制内存使用不超过系统的70%
export IMPALA_SERVER_ARGS=${IMPALA_SERVER_ARGS:- \
-log_dir=${IMPALA_LOG_DIR} \
-state_store_port=${IMPALA_STATE_STORE_PORT} \
-use_statestore -state_store_host=${IMPALA_STATE_STORE_HOST} \
-be_port=${IMPALA_BACKEND_PORT}}
增加mem_limit参数,修改成下面代码
export IMPALA_SERVER_ARGS=${IMPALA_SERVER_ARGS:- \
-log_dir=${IMPALA_LOG_DIR} -state_store_port=${IMPALA_STATE_STORE_PORT} \
-use_statestore -state_store_host=${IMPALA_STATE_STORE_HOST} \
-be_port=${IMPALA_BACKEND_PORT} -mem_limit=70%}
内存限制还可以写绝对的内存大小如:2000M或2G
3.允许核心转储(Core dump enablement)
核心文件,核心转储的解释见百科
export ENABLE_CORE_DUMPS=${ENABLE_COREDUMPS:-false}
修改成:
export ENABLE_CORE_DUMPS=${ENABLE_COREDUMPS:-true}
其他的见Modifying Impala Startup Options
四、测试
重启服务
使用命令重启服务:
sudo service impala-state-store restart
sudo service impala-server restart
Impala的web端口是:
http:// impala-state-store-server:25010/
http:// impala-server:25000/
测试
打开impala-shell连接到Impala-server服务器, 执行查询。
Impala-shell
> connect Slave02.Hadoop:21000; > select count(1) from pokes;
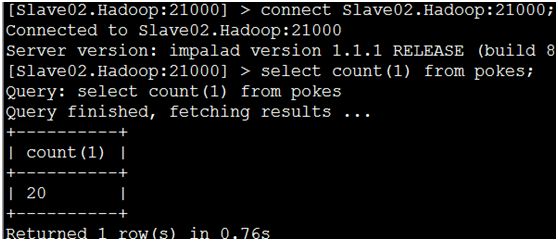
同样的查询在hive里面执行,时间大概是17s左右。
单从这简单的数字看,Impala确实很实时。当然这测试还不够。
五、问题
Insert …. Values现在只支持TEXT和Parquet格式
最好不要使用Insert来插入大数据,因为Insert并不能并行执行。
Parquet创建的Impala表,能够使用impala执行Insert和select操作。而在hive里面会有异常。通过这篇文章能够解决一些问题,但是还是无法使用hive来操作Impala的Parquet数据格式的表。
六、语句
建表语句:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT 'col_comment'], …)]
[COMMENT 'table_comment']
[PARTITIONED BY (col_name data_type [COMMENT 'col_comment'], …)]
[
[ROW FORMAT row_format] [STORED AS file_format]
]
[LOCATION 'hdfs_path']
data_type
: primitive_type
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| STRING
| TIMESTAMP
row_format
: DELIMITED [FIELDS TERMINATED BY 'char' [ESCAPED BY 'char']]
[LINES TERMINATED BY 'char']
file_format:
: PARQUETFILE
| SEQUENCEFILE
| TEXTFILE
| RCFILE
ALTER TABLE old_name RENAME TO new_name; 修改表名
ALTER TABLE table_name SET LOCATION ‘hdfs_path_of_directory’;修改数据位置
ALTER TABLE table_name ADD COLUMNS (column_defs); 增加列
ALTER TABLE table_name REPLACE COLUMNS (column_defs);
ALTER TABLE table_name CHANGE column_name new_name new_spec; 修改列名
ALTER TABLE table_name DROP column_name; 删除列
ALTER TABLE table_name SET FILEFORMAT { PARQUETFILE | RCFILE | SEQUENCEFILE | TEXTFILE } 修改表的数据存储格式
describe formatted v1; 参看表的信息
explain select count(*) from customer_address; 参看语句执行计划
一、Impala简介
Cloudera Impala对你存储在Apache Hadoop在HDFS,HBase的数据提供直接查询互动的SQL。除了像Hive使用相同的统一存储平台,Impala也使用相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(Hue Beeswax)。Impala还提供了一个熟悉的面向批量或实时查询和统一平台。
二、安装要求
1、软件要求
- Red Hat Enterprise Linux (RHEL)/CentOS 6.2 (64-bit)
- CDH 4.1.0 or later
- Hive
- MySQL
注意:Impala不支持在Debian/Ubuntu, SuSE, RHEL/CentOS 5.7系统中安装。
2、硬件要求
在Join查询过程中需要将数据集加载内存中进行计算,因此对安装Impalad的内存要求较高。
三、安装准备
1、操作系统版本查看
>more /etc/issue
CentOS release 6.2 (Final)
Kernel \r on an \m
2、机器准备
10.28.169.112 mr5
10.28.169.113 mr6
10.28.169.114 mr7
10.28.169.115 mr8
各机器安装角色
mr5:NameNode、ResourceManager、SecondaryNameNode、Hive、impala-state-store
mr6、mr7、mr8:DataNode、NodeManager、impalad
3、用户准备
在各个机器上新建用户hadoop,并打通ssh
4、软件准备
到cloudera官网下载:
Hadoop:
hadoop-2.0.0-cdh4.1.2.tar.gz
Hive:
hive-0.9.0-cdh4.1.2.tar.gz
Impala:
impala-0.3-1.p0.366.el6.x86_64.rpm
impala-debuginfo-0.3-1.p0.366.el6.x86_64.rpm
impala-server-0.3-1.p0.366.el6.x86_64.rpm
impala-shell-0.3-1.p0.366.el6.x86_64.rpm
impala依赖包下载:
bigtop-utils-0.4(http://beta.cloudera.com/impala/redhat/6/x86_64/impala/0/RPMS/noarch/)
其他依赖包下载地址:http://mirror.bit.edu.cn/centos/6.3/os/x86_64/Packages/
四、hadoop-2.0.0-cdh4.1.2安装
1、安装包准备
hadoop用户登录到mr5机器,将hadoop-2.0.0-cdh4.1.2.tar.gz上传到/home/hadoop/目录下并解压:
tar zxvf hadoop-2.0.0-cdh4.1.2.tar.gz
2、配置环境变量
修改mr5机器hadoop用户主目录/home/hadoop/下的.bash_profile环境变量:
export JAVA_HOME=/usr/jdk1.6.0_30
export JAVA_BIN=${JAVA_HOME}/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_OPTS=”-Djava.library.path=/usr/local/lib -server -Xms1024m -Xmx2048m -XX:MaxPermSize=256m -Djava.awt.headless=true -Dsun.net.client.defaultReadTimeout=600
00 -Djmagick.systemclassloader=no -Dnetworkaddress.cache.ttl=300 -Dsun.net.inetaddr.ttl=300″
export HADOOP_HOME=/home/hadoop/hadoop-2.0.0-cdh4.1.2
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export PATH=$PATH:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export JAVA_HOME JAVA_BIN PATH CLASSPATH JAVA_OPTS
export HADOOP_LIB=${HADOOP_HOME}/lib
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
3、修改配置文件
在机器mr5上hadoop用户登录修改hadoop的配置文件(配置文件目录:hadoop-2.0.0-cdh4.1.2/etc/hadoop)
(1)、slaves :
添加以下节点
mr6
mr7
mr8
(2)、hadoop-env.sh :
增加以下环境变量
export JAVA_HOME=/usr/jdk1.6.0_30
export HADOOP_HOME=/home/hadoop/hadoop-2.0.0-cdh4.1.2
export HADOOP_PREFIX=${HADOOP_HOME}
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export PATH=$PATH:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export JAVA_HOME JAVA_BIN PATH CLASSPATH JAVA_OPTS
export HADOOP_LIB=${HADOOP_HOME}/lib
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
(3)、core-site.xml :
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://mr5:9000</value>
<description>The name of the default file system.Either the literal string “local” or a host:port for NDFS.</description>
<final>true</final>
</property>
<property>
<name>io.native.lib.available</name>
<value>true</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
(4)、hdfs-site.xml :
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfsdata/name</value>
<description>Determines where on the local filesystem the DFS name node should store the name table.If this is a comma-delimited list of directories,then name table is replicated in all of the directories,for redundancy.</description>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfsdata/data</value>
<description>Determines where on the local filesystem an DFS data node should store its blocks.If this is a comma-delimited list of directories,then data will be stored in all named directories,typically on different devices.Directories that do not exist are ignored.
</description>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permission</name>
<value>false</value>
</property>
</configuration>
(5)、mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://mr5:9001</value>
<final>true</final>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
</property>
<property>
<name>mapreduce.cluster.temp.dir</name>
<value>file:/home/hadoop/mapreddata/system</value>
<final>true</final>
</property>
<property>
<name>mapreduce.cluster.local.dir</name>
<value>file:/home/hadoop/mapreddata/local</value>
<final>true</final>
</property>
</configuration>
(6)、yarn-env.sh :
增加以下环境变量
export JAVA_HOME=/usr/jdk1.6.0_30
export HADOOP_HOME=/home/hadoop/hadoop-2.0.0-cdh4.1.2
export HADOOP_PREFIX=${HADOOP_HOME}
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export PATH=$PATH:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export JAVA_HOME JAVA_BIN PATH CLASSPATH JAVA_OPTS
export HADOOP_LIB=${HADOOP_HOME}/lib
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
(7)、yarn-site.xml:
<configuration>
<!– Site specific YARN configuration properties –>
<property>
<name>yarn.resourcemanager.address</name>
<value>mr5:8080</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>mr5:8081</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>mr5:8082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:/home/hadoop/nmdata/local</value>
<description>the local directories used by the nodemanager</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:/home/hadoop/nmdata/log</value>
<description>the directories used by Nodemanagers as log directories</description>
</property>
</configuration>
4、拷贝到其他节点
(1)、在mr5上配置完第2步和第3步后,压缩hadoop-2.0.0-cdh4.1.2
rm hadoop-2.0.0-cdh4.1.2.tar.gz
tar zcvf hadoop-2.0.0-cdh4.1.2.tar.gz hadoop-2.0.0-cdh4.1.2
然后将hadoop-2.0.0-cdh4.1.2.tar.gz远程拷贝到mr6、mr7、mr8机器上
scp /home/hadoop/hadoop-2.0.0-cdh4.1.2.tar.gz hadoop@mr6:/home/hadoop/
scp /home/hadoop/hadoop-2.0.0-cdh4.1.2.tar.gz hadoop@mr7:/home/hadoop/
scp /home/hadoop/hadoop-2.0.0-cdh4.1.2.tar.gz hadoop@mr8:/home/hadoop/
(2)、将mr5机器上hadoop用户的配置环境的文件.bash_profile远程拷贝到mr6、mr7、mr8机器上
scp /home/hadoop/.bash_profile hadoop@mr6:/home/hadoop/
scp /home/hadoop/.bash_profile hadoop@mr7:/home/hadoop/
scp /home/hadoop/.bash_profile hadoop@mr8:/home/hadoop/
拷贝完成后,在mr5、mr6、mr7、mr8机器的/home/hadoop/目录下执行
source .bash_profile
使得环境变量生效
5、启动hdfs和yarn
以上步骤都执行完成后,用hadoop用户登录到mr5机器依次执行:
hdfs namenode -format
start-dfs.sh
start-yarn.sh
通过jps命令查看:
mr5成功启动了NameNode、ResourceManager、SecondaryNameNode进程;
mr6、mr7、mr8成功启动了DataNode、NodeManager进程。
6、验证成功状态
通过以下方式查看节点的健康状态和作业的执行情况:
浏览器访问(本地需要配置hosts)
http://mr5:50070/dfshealth.jsp
http://mr5:8088/cluster
五、hive-0.9.0-cdh4.1.2安装
1、安装包准备
使用hadoop用户上传hive-0.9.0-cdh4.1.2到mr5机器的/home/hadoop/目录下并解压:
tar zxvf hive-0.9.0-cdh4.1.2
2、配置环境变量
在.bash_profile添加环境变量:
export HIVE_HOME=/home/hadoop/hive-0.9.0-cdh4.1.2
export PATH=$PATH:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${HIVE_HOME}/bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export HIVE_LIB=$HIVE_HOME/lib
添加完后执行以下命令使得环境变量生效:
. .bash_profile
3、修改配置文件
修改hive配置文件(配置文件目录:hive-0.9.0-cdh4.1.2/conf/)
在hive-0.9.0-cdh4.1.2/conf/目录下新建hive-site.xml文件,并添加以下配置信息:
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://10.28.169.61:3306/hive_impala?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.security.authorization.enabled</name>
<value>false</value>
</property>
<property>
<name>hive.security.authorization.createtable.owner.grants</name>
<value>ALL</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>${user.home}/hive-logs/querylog</value>
</property>
</configuration>
4、验证成功状态
完成以上步骤之后,验证hive安装是否成功
在mr5命令行执行hive,并输入”show tables;”,出现以下提示,说明hive安装成功:
>hive
hive> show tables;
OK
Time taken: 18.952 seconds
hive>
六、impala安装
说明:
(1)、以下1、2、3、4步是在root用户分别在mr5、mr6、mr7、mr8下执行
(2)、以下第5步是在hadoop用户下执行
1、安装依赖包:
安装mysql-connector-java:
yum install mysql-connector-java
安装bigtop
rpm -ivh bigtop-utils-0.4+300-1.cdh4.0.1.p0.1.el6.noarch.rpm
安装libevent
rpm -ivh libevent-1.4.13-4.el6.x86_64.rpm
如存在其他需要安装的依赖包,可以到以下链接:
http://mirror.bit.edu.cn/centos/6.3/os/x86_64/Packages/进行下载。
2、安装impala的rpm,分别执行
rpm -ivh impala-0.3-1.p0.366.el6.x86_64.rpm
rpm -ivh impala-server-0.3-1.p0.366.el6.x86_64.rpm
rpm -ivh impala-debuginfo-0.3-1.p0.366.el6.x86_64.rpm
rpm -ivh impala-shell-0.3-1.p0.366.el6.x86_64.rpm
3、找到impala的安装目录
完成第1步和第2步后,通过以下命令:
find / -name impala
输出:
/usr/lib/debug/usr/lib/impala
/usr/lib/impala
/var/run/impala
/var/log/impala
/var/lib/alternatives/impala
/etc/default/impala
/etc/alternatives/impala
找到impala的安装目录:/usr/lib/impala
4、配置Impala
在Impala安装目录/usr/lib/impala下创建conf,将hadoop中的conf文件夹下的core-site.xml、hdfs-site.xml、hive中的conf文件夹下的hive-site.xml复制到其中。
在core-site.xml文件中添加如下内容:
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.client.read.shortcircuit.skip.checksum</name>
<value>false</value>
</property>
在hdfs-site.xml文件中添加如下内容:
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>755</value>
</property>
<property>
<name>dfs.block.local-path-access.user</name>
<value>hadoop</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
5、启动服务
(1)、在mr5启动Impala state store,命令如下:
>GLOG_v=1 nohup statestored -state_store_port=24000 &
如果statestore正常启动,可以在/tmp/statestored.INFO查看。如果出现异常,可以查看/tmp/statestored.ERROR定位错误信息。
(2)、在mr6、mr7、mr8启动Impalad,命令如下:
mr6:
>GLOG_v=1 nohup impalad -state_store_host=mr5 -nn=mr5 -nn_port=54310 -hostname=mr6 -ipaddress=10.28.169.113 &
mr7:
>GLOG_v=1 nohup impalad -state_store_host=mr5 -nn=mr5 -nn_port=54310 -hostname=mr7 -ipaddress=10.28.169.114 &
mr8:
>GLOG_v=1 nohup impalad -state_store_host=mr5 -nn=mr5 -nn_port=54310 -hostname=mr8 -ipaddress=10.28.169.115 &
如果impalad正常启动,可以在/tmp/ impalad.INFO查看。如果出现异常,可以查看/tmp/ impalad.ERROR定位错误信息。
6、使用shell
使用impala-shell启动Impala Shell,分别连接各Impalad主机(mr6、mr7、mr8),刷新元数据,之后就可以执行shell命令。相关的命令如下(可以在任意节点执行):
>impala-shell
[Not connected] > connect mr6:21000
[mr6:21000] >refresh
[mr6:21000]>connect mr7:21000
[mr7:21000]>refresh
[mr7:21000]>connect mr8:21000
[mr8:21000]>refresh
7、验证成功状态
使用impala-shell启动Impala Shell,分别连接各Impalad主机,刷新元数据,之后就可以执行shell命令。相关的命令如下(可以在任意节点执行):
>impala-shell
[Not connected] > connect mr6:21000
[mr6:21000] >refresh
[mr6:21000] > show databases
default
[mr6:21000] >
出现以上提示信息,说明安装成功