A High-Performance Nehalem iDataPlex Cluster and DDN S2A9990 Storage for Texas A&M University
本文转载自:http://sc.tamu.edu/systems/eos/
A High-Performance Nehalem
iDataPlex Cluster
and
DDN S2A9990 Storage
for Texas A&M University
by Michael E. Thomadakis, Ph.D., 2009−2011 (C)
Supercomputing Facility
miket(at)tamu(dot)edu
A technical discussion about Nehalem multi-core chips, SMP platform
and their memory performance is available as PDF.
Follow on article on the recent expansion of EOS with
Westmere-EP dx360-M3 nodes and GPU Tesla T20 capability.
- Introduction
- The Nehalem Processor and Intel64 ISA
- Simultaneous Multi-Threading
- Memory Organization in Nehalem Processors and Platforms
- dx360-M2 SMP Node Architecture
- High-Performance IB QDR Switch Cluster Interconnect
- IB Communication Stack and MPI
Fig. 1 A photograph of EOS iDataPlex Cluster at Texas A&M University while it was being installed
Abbreviation Key
We will be using different quantities to measure capacities and speeds. To avoid confusion we will be using the following notation.
Table 1 Abbreviations of Quantities
Powers of 2
Powers of 10
KiB := 210 ("Kilo-binary-Byte")
KB := 103 ("Kilo-Byte")
MiB := 220 ("Mega-binary-Byte")
MB := 106 ("Mega-Byte")
GiB := 230 ("Giga-binary-Byte")
GB := 109 ("Giga-Byte")
TiB := 240 ("Tera-binary-Byte")
TB := 1012 ("Tera-Byte")
PiB := 250 ("Peta-binary-Byte")
PB := 1015 ("Peta-Byte")
Usually, rates, such as data transfer or floating point operations per second, are expressed in powers of 10, while storage sizes in powers of 2. See this reference for a discussion on international units.
Introduction to the EOS Cluster
This article is an in-depth technical discussion of EOS's cluster and underlying h/w and s/w technologies. Most of these technologies came out of research labs in the 2007−2009 time-frame. They render EOS one of the top high-performance platforms in the 2010 time-frame. The EOS cluster has overall a more balanced design, where no resource becomes a significant bottleneck. This is a departure from conventional x86 clusters where the bandwidth of the interconnect or of the memory are limiting factors. EOS like other state-of-the-art clusters, is a collection of complex subsystems all amenable to tuning and different configuration options. Intimate knowledge of the underlying mechanisms and their inter-dependence is a pre-requisite for putting together a cluster which is tuned and configured to perform efficiently in a demanding research and production environment. The current job mix demands access to all resources of the cluster simultaneously. We have taken into careful consideration the resource demands of the job mixes and we have configured and tuned the cluster and its subsystems so the entire system can operate as efficiently as possible. Developers of scalar or parallel applications should also have a more intimate knowledge of the underlying technologies in order to be able to make the best use of all the available resources and tools.
The discussion presented here relies on information from a large number of different sources, all scattered in many places. We hope that a coherent presentation of the constituent technologies and their interaction will save the considerable amount of effort necessary to bring all important aspects into a single place.
This article is dedicated to all those interested in producing code that runs quite well on high-performance clusters based on the Intel64 architecture. It should also be a great reference to all those who study computer architecture and parallel technologies in order to improve them or just to learn important aspects of them.
Quick Overview of EOS Cluster Configuration
Fig. 2 below presents a pictorial illustration of the main EOS cluster components. We will use it to explain at a high level how users can access the cluster.
Fig. 2 A graphical overview of the important EOS infrastructure components at Texas A&M University.
Of the 324 iDataPlex EOS's nodes, 314 are designated as Compute Nodes (CNs) while five and four nodes are set aside to provide interactive logins (LNs) and storage I/O service (SNs), respectively. The Login and I/O nodes are IBM "x3650-M2" model and the Compute Nodes are "dx360-M2". Both models are very similar in internal capabilities and architecture and they differ in packaging and I/O capabilities.
Each EOS iDataPlex node is an 8-way, native 64-bit Shared-memory Multi-Processor, consisting of two quad-core Nehalem chips and 24GiB1 of DDR3 DRAM. The Nehalem chips are designated as "XEON X5560" and run at a frequency of 2.8GHz. The two processor Nehalem chips communicate together with Intel's "QuickPath" Interconnect (QPI). QPI is a rather significant technological innovation Intel introduced with systems based on the Nehalem processor. QPI is a full-duplex point-to-point communication link which in the case of EOS can exchange data in both directions with a bandwidth of 12.8GB/sec per direction.
EOS users are expected to use the LNs to develop, compile, troubleshoot and optimize their applications. The CNs are made available through a batch scheduler to execute user code to generate results relevant to their work. In general, CNs will not be accessible to a user for interactive work.
All 324 nodes have access to high-performance distributed file systems via the QDR fabric. The file systems are provided by IBM's latest high-performance GPFS V3.3.0-4. The disk storage is provided by a DataDirect Networks S2A9900 high-performance RAID array, with a raw capacity of 120 Tera-Bytes.
All cluster nodes run a recent 64-bit version of the RedHat or the CentOS Linux operating systems. OFED V1.4.2 is the IB software communication stack for the entire cluster. The cluster employs the latest GPFS V3.3.0-4 for parallel file system.
The normal mode of problem-solving on EOS is running distributed or shared-memory (OMP) computations under the control of a batch scheduler.
Quick Overview of Technologies Incorporated into EOS Cluster
Even though it is a commodity cluster, EOS combines a number of cutting-edge technologies most suitable for a high-performance production and research environment. These technologies include the Nehalem micro-processor, DDR3 main memory (DRAM), Intel's Quick-Path Interconnect (QPI), a 4x Quadruple-Data-Rate Infiniband fabric, a high-end disk subsystem, high performance distributed file system and a comprehensive program development and execution environment supporting the "Intel64" architecture specification.
Nehalem Architecture Nehalem implements a modern multi-core technology, representing the state-of-the art in commodity, complex instruction set computer (CISC) micro-architectures. This platform relies on Intel's 45nm, high-k, metal gate silicon technology. Each processor chip has its own dedicated memory that it accesses directly through an on-chip Integrated Memory Controller.
Nehalem SIMD Processing Nehalem directly supports SIMD computation where the same operation can be applied simultaneously on multiple data operands. Applications which rely on vector type of floating-point or integer arithmetic can greatly benefit from the SIMD infrastructure in Nehalem. Nehalem can produce up to 4 double-precision simple arithmetic results per clock cycle.
Simultaneous Multi-Threading (Hyper-Threading) Technology Simultaneous Multi-Threading (SMT) allows up to 2 threads to execute within each processor core, up to eight threads per quad-core chip or 16 SMT threads per Nehalem-EP node. SMT reduces computational latency, by maximizing the utilization of the idle core functional units, thus increasing the machine instruction throughput per clock cycle. Applications with matching resource needs can be accommodated without impacting each other negatively.
QuickPath Technology Intel QuickPath Interconnect (QPI) is a platform architecture that provides high-speed (currently up to 25.6 GB/s), point-to-point connections between processor chips, and between processors and the I/O hub (IOH). A processor may access the dedicated memory of another processor, through a QPI link.
Nehalem-EP Architecture The Nehalem EP architecture supports 8-way parallel processing, enabled by two processor chips connected together by Intel QuickPath interconnect. Nehalem EP is a cc-NUMA platform where the the QPI is the coherent transport link between the two processors. Processor sockets connect to the I/O system section, each by a separate QPI link, enabling sustained high I/O throughput.
Quad-Data Rate 4x Infiniband IB is a high-speed interconnect technology which supports low-latency and high-bandwidth connection of N end-points. At TAMU, the IB fabric is configures to support NXN communication at "full-bisection bandwidth" where all N/2 disjoint communicating pairs can simultaneously send and receive message at the nominal speed of 4GB/s per direction.
High-Speed Back-End RAID Storage TAMU has configured a DDN S2A9900 RAID storage array for the GPFS file systems of the cluster. The raw disk capacity is 120 TeraBytes, which offers a 96 TeraBytes formatted capacity for GPFS.
High-Speed Parallel File System EOS cluster provides high-speed access to a high-performance parallel file system from IBM called GPFS. GPFS is a solid parallel file system designed and proven to support high-bandwidth parallel access of applications to a common file store.
Comprehensive Program Development Environment, Libraries and Tuning Tools EOS supports a comprehensive development environment for scalar, SMP, distributed and hybrid applications. These include the latest compilers, tools and libraries available from Intel or other sources to support high-performance user applications.
In subsequent Sections we analyze technical details of these technologies and we discuss how they can affect the performance of user code.
The Nehalem Processor and "Intel� 64" Architecture
"Nehalem" is the nickname for the "Intel� Microarchitecture", where the latter is a specific implementation of the "Intel64" Instruction Set Architecture (ISA) specification. For this report, "Nehalem" refers to the particular implementation where a processor chip contains four cores, the fabrication process is 45nm with high-k + metal gate transistor technology. We further focus on platforms with two processor sockets per system (node) and where the interconnection between sockets themselves and between processors and I/O is through Intel's Quick-Path Interconnect. Nehalem is the foundation of Intel Core i7 and Xeon processor 5500 series. EOS nodes use the "Xeon 5560" processor chips. Even though "Intel64" is a classic Complex-Instruction Set Computer ("CISC") type, its "Intel Micro-architecture" implementation shares many mechanisms in common with modern Reduced-Instruction Set Computer ("RISC") implementations.
The "Intel� 64" Architecture
The 64-bit "Intel64" ISA, historically derives from the 64-bit extensions AMD applied on Intel's popular 32-bit IA-32 ISA for its "K8" processor family. Later on AMD used the name "AMD64" and Intel the names "IE-32e" and "EM64T". Finally, Intel settled on "Intel64" as their "official" 64-bit ISA deriving from the IA-32. The Intel64 architecture supports IA-32 ISA and extends it to fully support natively 64-bit OS and 64-bit applications. The physical address space in the "Intel64" platform can reach up to 48 bits which implies that 256 Tera-binary-Bytes (TiB) can by directly addressed by the hardware. The logical address size of "Intel64" is 64-bit which supports a 64-bit flat linear address space. However, currently the hardware effectively uses only the last 48-bits.
Fig. 3 presents the logical (or "architected") view of the Intel64 ISA. The architected view of an ISA is the collection of objects which are visible at the machine language code level and can be directly manipulated by machine instructions.
Fig. 3 "Intel64" : 64-bit Mode Execution Environment on Nehalem processor.
In the 64-bit mode of Intel64 architecture, software may access
- a 64-bit flat linear logical address space
- 64-bit-wide General Purpose Registers (GPRs) and instruction pointers
- 16 64-bit GPRs
- 16 128-bit "XMM" registers for streaming SIMD extensions (SSE, SSE2, SSE3 and SSSE3, SSE4), in addition to 8 64-bit XMM registers or the 8 80-bit x87 registers, supporting floating-point or integer operations
- uniform byte-register addressing
- fast interrupt-prioritization mechanism
- a new instruction-pointer relative-addressing mode.
64-bit applications can use a set of prefixes to access the new registers or 64-bit register operands, and 64-bit address pointers. Intel compilers can produce code which takes full advantage of all the features in Intel64 ISA. Application optimization guidelines will be published on a separate write up.
Non 64-bit Code Intel64 architecture provides a new operating mode, referred to as IA-32e mode, which consists of two sub-modes: (1) compatibility mode which enables a 64-bit operating system to run most legacy 32-bit software unmodified, and (2) 64-bit mode which enables a 64-bit operating system to run applications written to access 64-bit linear address space. On EOS, all nodes operate at the full 64-bit mode. 32-bit applications can run, likely unchanged, but there is no good reason to produce or run 32-bit code on a native 64-bit platform. This report focuses exclusively on the full 64-bit "Intel64" ISA and will not discuss other modes of execution.
Nehalem Processor
Nehalem builds upon and expands the new features introduced by the previous micro-architecture, namely the 45nm "Enhanced Intel Core Micro-architecture" or "Core-2" for short.
Features in the Intel Core Micro-Architecture
The "Core-2" micro-architecture introduced a number of interesting features, including the following
- "Wide Dynamic Execution" which enabled each processor core to fetch, dispatch, execute and retire up to four instructions per clock cycle. This architecture had
- 14-stage core pipeline
- 4 decoders to decode up to 5 instructions per cycle
- 3 clusters of arithmetic logical units
- macro-fusion and micro-fusion to improve front-end throughput
- peak dispatching rate of up to 6 micro-ops per cycle
- peak retirement rate of up to 4 micro-ops per cycle
- advanced branch prediction algorithms
- stack pointer tracker to improve efficiency of procedure entries and exits
- "Advanced Smart Cache" which improved bandwidth from the second level cache to the core, and improved support for single- and multi-threaded applications computation
- 2-nd level cache up to 4 MB with 16-way associativity
- 256 bit internal data path from L2 to L1 data caches
- "Smart Memory Access" which pre-fetches data from memory responding to data access patterns, reducing cache-miss exposure of out-of-order execution
- hardware pre-fetchers to reduce effective latency of 2nd level cache misses
- hardware pre-fetchers to reduce effective latency of 1st level data cache misses
- "memory disambiguation" to improve efficiency of speculative instruction execution
- "Advanced Digital Media Boost" for improved execution efficiency of most 128-bit SIMD instruction with single-cycle throughput and floating-point operations
- single-cycle inter-completion latency ("throughput") of most 128-bit SIMD instructions
- up to eight SP floating-point operation per cycle
- 3 issue ports available to dispatching SIMD instructions for execution
New Features in the Intel Micro-Architecture
"Intel Micro-architecture" (Nehalem) provides a number of distinct feature enhancements over those of "Enhanced Intel Core Micro-architecture", shown above, including:
- Enhanced processor core:
- improved branch prediction and recovery cost from mis-prediction;
- enhanced loop streaming to improve front-end performance and reduce power consumption;
- deeper buffering in out-of-order engine to extract parallelism;
- enhanced execution units with accelerated processing of CRC, string/text and data shuffling.
- Hyper-threading technology (SMT):
- support for two hardware threads (logical processors) per core;
- a 4-wide execution engine, larger L3, and large memory bandwidth.
- "Smarter" Memory Access:
- integrated (on-chip) memory controller supporting low-latency access to local system memory and overall scalable memory bandwidth; previously the memory controller was hosted on a separate chip and it was common to all dual or quad socket systems;
- new cache hierarchy organization with shared, inclusive L3 to reduce snoop traffic
- two level TLBs and increased TLB sizes;
- fast unaligned memory access.
- Dedicated Power management:
- integrated micro-controller with embedded firmware which manages power consumption;
- embedded real-time sensors for temperature, current, and power;
- integrated power gate to turn off/on per-core power consumption;
- Versatility to reduce power consumption of memory and QPI link subsystems.
The Nehalem Processor Chip
A Nehalem processor chip is a "Chip-Multi Processor" (CMP), consisting of several functional parts within a single silicon die. Fig. 4 illustrates a Nehalem CMP chip and its major parts.
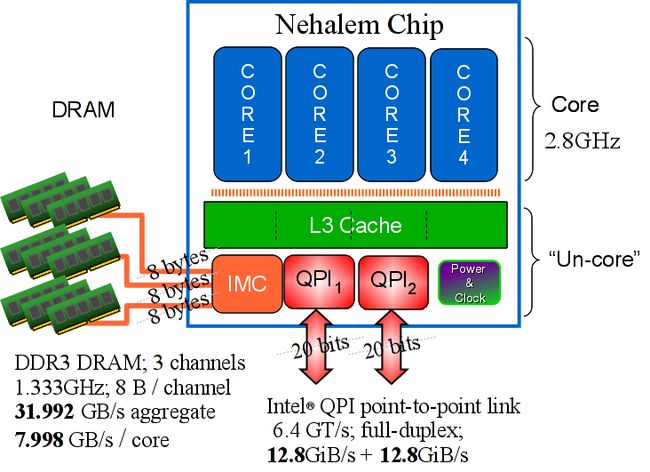
Fig. 4 (a) A Nehalem Processor and Memory module. The processor chip contains four cores, a shared L3 cache and DRAM controllers, and Quickpath Interconnect ports.

Fig. 4 (b) A Nehalem Processor Chip micro-photograph.
Referring to Fig. 4, a Nehalem chip consists of the following components
- four identical compute cores,
- CIU: Cache Interface Unit (switch connecting the 4 cores to the 4 L3 cache segments),
- L3: level-3 cache controller and data block memory,
- IMC: 1 integrated memory controller with 3 DDR3 memory channels,
- QPI: 2 Quick Path Interconnect ports, and
- auxiliary circuitry for cache-coherence, power control, system management and performance monitoring logic.
A Nehalem chip is divided into two broad domains, namely, the core and the un-core. Components in the "core domain" operate with the same clock frequency as that of the actual computation core. In EOS's case this is 2.8GHz. The "un-core" domain operates under a different clock frequency. This modular organization reflects one of Nehalem's objectives of being able to consistently implement chips with different levels of computation abilities and power consumption profiles. For instance, a Nehalem chip may have from two to eight cores, one or more high-speed QPI interconnects, different sizes for L3 caches, as well as, memory sub-systems with different DRAM bandwidths. Similar partitioning of CMP chip into different clock domains can be found in other processors, such as, in IBM's Power5, 6 and 7, in AMDs multi-core chips and serves very similar purposes.
Outside the Nehalem chip, but at close physical proximity, we find the DRAM which is accessible by means of three 8-byte DDR3 channels, each capable to operate at up to 1.333 GHz. The aggregate nominal main memory bandwidth is 31.992 GB/s per chip, or 7.998 GB/s per core. This is a significant improvement over all previous Intel micro-architectures. The maximum operating frequency of the DDR3 buses is determined by the number of DIMMs in the slots.
In essence the "un-core" domain contains the memory controller and cache coherence logic which in earlier Intel architectures used to be implemented by the separate "North-bridge" chip.
The high performance of the Nehalem architecture relies, among other things, on the fact that the DRAM controller, the L3 and the QPI ports are all housed within the same silicon die as the four cores. This saves a significant amount of off-chip communications and makes possible a tightly coupled, low-latency, high bandwidth CMP system. This particular processor to memory implementation is a significant departure from all previous ones by Intel. Prior to Nehalem, the memory controller was housed on a separate "Northbridge" chip and it was shared by all processor chips. The Northbridge has been one of the often cited bottlenecks in previous Intel architectures. Nehalem has substantially increased the main memory bandwidth and shortened the latency to access main memory. However, now that a separate DRAM is associated with every IMC and chip, platforms with more than one chips are Non-Uniform Memory Access ("NUMA"). NUMA organizations have distinct performance advantages and disadvantages and with proper care multi-threaded computation can make efficient use of the available memory bandwidth. In general data and thread placement becomes an important part of the application design and tuning process.
Nehalem Core Instruction Pipeline
Instruction and Data Flow in Modern Processors
Nehalem implements a number of techniques to process efficiently the stream of Intel64 ISA CISC "macro-instructions" in the user code. A core internally consists of a large number of functional units (FUs) each capable of carrying out an elementary "micro-operation" (micro-op). An example of a FU is an ALU (arithmetic and logic unit) which can carry out an operation against input operands. Micro-ops would specify the operation type and its operands. Micro-ops are RISC-like type of instructions and they require similar effort and resources to process.
Micro-operations having no dependencies on the results of each other could proceed in parallel if separate FUs are available. The CISC type of Intel64 macro-instructions are translated by the early stages of the core into one or more micro-ops. The micro-operations eventually reach the execution FUs where they are dispatched to FUs and "retire", that is, have their results saved back to visible ("architected") state (i.e., data registers or memory). When all micro-ops of a macro-instruction retire, the macro-instruction itself retires. It is clear that the basic objective of the processor is to maximize the macro-instruction retirement rate.
The fundamental approach Nehalem (and other modern processors) take to maximize instruction completion rates is to allow the micro-ops of as many instructions as feasible, proceed in parallel with micro-op occupying independent FUs at each clock cycle. We can summarize the Intel64 instruction flow through the core as follows.
- The early stages of the processor fetch-in several macro-instructions at a time (say in a cache block) and
- decode them (break them down) into sequences of micro-ops.
- The micro-ops are buffered at various places where they can be
- picked up and scheduled to use the FUs in parallel if data dependencies are not violated. In Nehalem, micro-ops are issued to stations were they reserve their position for subsequent
- dispatching as soon as their input operands become available.
- Finally, completed micro-ops retire and post their results to permanent storage.
The entire process proceeds in stages, in a "pipelined" fashion. Pipelining is used to break down a lengthy task into sub-tasks where intermediate results flow downstream the pipeline stages. In microprocessors, sub-tasks handled within each stage take one clock cycle. The amount of hardware logic which goes into each stage has been carefully selected so that there is approximately an equal amount of work which takes place in every stage. Since adding a pipeline stage includes some additional fixed overhead for buffering intermediate results, pipeline designs carefully balance the total number of stages and the duration per stage.
Complex FUs are usually themselves pipelined. A floating-point ALU may require several clock cycles to produce the results of complex FP operations, such as, FP division or square root. The advantage of pipelining here is that with proper intermediate result buffering, we could supply a new set of input operands to the pipelined FU in each clock cycle and then correspondingly expect a new result to be produced at each clock cycle at the output of the FU.
A pipeline bubble takes place when the input operands of a downstream stage are not available. Bubbles flow downstream at each clock cycle. When the entire pipeline has no input to work with it can stall, that is, it can suspend operation completely. Bubbles and stalls are detrimental to the efficiency of pipelined execution if they take place with a "high" frequency. Common reasons for a bubble is when say data has to be retrieved from slower memory or from a FU which takes multiple cycles to produce them. Compilers and processor designers invest heavily in minimizing the occurrence and the impact of stalls. A common way to alleviate the frequency of stalls is to allow micro-ops proceed out of chronological order and use any available FUs. Dynamic instruction scheduling logic in the processor determines which micro-ops can proceed in parallel while the program execution remains semantically correct. Dynamic scheduling utilizes the "Instruction Level Parallelism" (ILP) which is possible within the instruction stream of a program. Another mechanism to avoid pipeline stalling is called speculative execution. A processor may speculatively start fetching and executing instructions from a code path before the outcome of a conditional branch is determined. Branch prediction is commonly used to "predict" the outcome and the target of a branch instruction. However, when the path is determined not to be the correct one, the processor has to cancel all intermediate results and start fetching instructions from the right path. Another mechanism relies on data pre-fetching when it is determined that the code is retrieving data with a certain pattern. There are many other mechanisms which are however beyond the scope of this report to describe.
Nehalem, as other modern processors, invests heavily into pre-fetching as many instructions, from a predicted path and translating them into micro-ops, as possible. A dynamic scheduler then attempts to maximize the number of concurrent micro-ops which can be in progress ("in-flight") at a time, thus increasing the completion instruction rates. Another interesting feature of Intel64 is the direct support for SIMD instructions which increase the effective ALU throughput for FP or integer operations.
Instruction and Data Flow in Nehalem Cores
Nehalem cores are modern micro-processors with in-order instruction issue, super-scalar, out-of-order execution data-paths, which are coupled with a multilevel storage hierarchy. Nehalem cores have extensive support for branch prediction, speculative instruction execution, data pre-fetching and multiple pipelined FUs. An interesting feature is the direct support for integer and floating point SIMD instructions by the hardware.
Nehalem's pipeline is designed to maximize the macro-instruction flow through the multiple FUs. It continues the four-wide micro-architecture pipeline pioneered by the 65nm "Intel Core Microarchitecture" ("Merom") and the 45nm "Enhanced Core Microarchitecture" ("Penryn"). Fig. 5 illustrates a functional level overview of a Nehalem instruction pipeline. The total length of the pipeline, measured by branch mis-prediction delay, is 16 cycles, which is two cycles longer than that of its predecessor.

Fig. 5 High-level diagram of a Nehalem core pipeline.
Referring to Fig. 5, the core consists of
- an in-order Front-End Pipeline (FEP) which retrieves Intel64 instructions from memory, uses four decoders to decode them into micro-ops and buffers them for the downstream stages;
- an out-of-order super-scalar Execution Engine (EE) that can dynamically schedule and dispatch up to six micro-ops per cycle to the execution units, as soon as source operands and resources are ready,
- an in-order Retirement Unit (RU) which ensures the results of execution of micro-ops are processed and the "architected" state is updated according to the original program order, and
- multi-level cache hierarchy and address translation resources.
We describe in the next two Sub-sections in detail the front-end and back-end pf the core. Nehalem Core: Front-End Pipeline
Fig. 6 illustrates in more detail key components of Nehalem's Front-End Pipeline (FEP). The FEP is responsible for retrieving blocks of macro-instructions from memory and translating them into micro-ops and buffering them for handling at the execution back-end. FEP handles the code instructions "in-order". It can decode up to 4 macro-instructions in a single cycle. It is designed to support up to two hardware SMT threads by decoding the instruction streams of the two threads in alternate cycles. When SMT is not enabled, the FEP handles the instruction stream of only one thread.
Fig. 6 High-level diagram of the In-Order Front-End Nehalem Pipeline (FEP).
The Instruction Fetch Unit (IFU) consists of the Instruction Translation Lookaside Buffer (ITLB), an instruction pre-fetcher, the L1 instruction cache and the pre-decode logic of the Instruction Queue (IQ). The IFU always fetches 16 bytes (128 bits) of aligned instruction bytes on each clock cycle from the Level 1 instruction cache into the Instruction Length Decoder. There is a 128-bit wide direct path from L1 to the IFU. The IFU always brings in 16 byte blocks.
The IFU uses the ITLB to locate the 16-byte block in the L1 instruction cache and instruction pre-fetch buffers. Instructions are referenced by virtual address and translated to physical address with the help of a 128 entry instruction translation look-aside buffer (ITLB). A hit in the instruction cache causes 16 bytes to be delivered to the instruction pre-decoder. Programs average slightly less than 4 bytes per instruction, and since most instructions can be decoded by all decoders, an entire fetch can often be consumed by the decoders in one cycle. Instruction fetches are always 16-byte aligned. A non-16 byte aligned target reduces the number of instruction bytes by the amount of offset into the 16 byte fetch quantity. A taken branch reduces the number of instruction bytes delivered to the decoders since the bytes after the taken branch are not decoded.
The Branch-Prediction Unit (BPU) allows the processor to begin fetching and processing instructions before the outcome of a branch instruction is determined. For microprocessors with lengthy pipelines successful branch prediction allows the processor to fetch and execute speculatively instructions over the "predicted" path without "stalling" the pipeline. When a prediction is not successful, Nehalem simply cancels all work already done by the micro-ops already in the pipeline on behalf of instructions along the wrong path. This may get costly in terms of resources and execution cycles already spent. Modern processors invest heavily in silicon estate and algorithms for the BPU in order to minimize the frequency and impact of wrong branch predictions.
On Nehalem the BPU makes predictions for the following types of branch instructions
- direct calls and jumps: targets are read as a target array, without regarding the taken or not-taken prediction,
- indirect calls and jumps: these may either be predicted as having a fixed behavior, or as having targets that vary according to recent program behavior,
- conditional branches: BPU predicts the branch target and whether the branch will be taken or not.
Nehalem improves branch handling in several ways. The Branch Target Buffer (BTB) has been increased in size to improve the accuracy of branch predictions. Furthermore, hardware enhancements improve the handling of branch mis-prediction by expediting resource reclamation so that the front-end would not be waiting to decode instructions in an "architected" code path (the path in which instructions will reach retirement) while resources were allocated to executing mispredicted code path. Instead, new micro-ops stream can start forward progress as soon as the front end decodes the instructions in the architected code path. The BPU includes the following mechanisms
- Return Stack Buffer (RSB) A 16-entry RSB enables the BPU to accurately predict RET instructions. Renaming is supported with return stack buffer to reduce mis-predictions of return instructions in the code.
- Front-End Queuing of BPU look-ups. The BPU makes branch predictions for 32 bytes at a time, twice the width of the IFU. Even though this enables taken branches to be predicted with no penalty, software should regard taken branches as consuming more resources than do not-taken branches.
Instruction Length Decoder (ILD or "Pre-Decoder") accepts 16 bytes from the L1 instruction cache or pre-fetch buffers and it prepares the Intel64 instructions found there for instruction decoding downstream. Specifically the ILD
- determines the length of the instructions,
- decodes all prefix modifiers associated with instructions and
- notes properties of the instructions for the decoders, as for example, the fact that an instruction is a branch.
The ILD can write up to 6 instructions per cycle, maximum, into the downstream Instruction Queue (IQ). A 16-byte buffer containing more than 6 instructions will take 2 clock cycles. Intel64 allows modifier prefixes which dynamically modify the instruction length. These length changing prefixes (LCPs) prolong the ILD process to up to 6 cycles instead of 1. The Instruction Queue (IQ) buffers the ILD-processed instructions and can deliver up to five instructions in one cycle to the downstream instruction decoder. The IQ can buffer up to 18 instructions.
The Instruction Decoding Unit (IDU) translates the pre-processed Intel64 macro-instructions into a stream of micro-operations. It can handle several instructions in parallel for expediency.
The IDU has a total of four decoding units. Three units can decode one simple instruction each, per cycle. The other decoder unit can decode one instruction every cycle, either a simple instruction or complex instruction, that is one which translates into several micro-ops. Instructions made up of more than four micro-ops are delivered from the micro-sequencer ROM (MSROM). All decoders support the common cases of single micro-op flows, including, micro-fusion, stack pointer tracking and macro-fusion. Thus, the three simple decoders are not limited to decoding single micro-op instructions. Up to four micro-ops can be delivered each cycle to the downstream instruction decoder queue (IDQ).
The IDU also parses the micro-op stream and applies a number of transformations to facilitate a more efficient handling of groups of micro-ops downstream. It supports the following.
- Loop Stream Detection (LSD). For small iterative segments of code whose micro-ops fit within the 28-slot Instruction Decoder Queue (IDQ), the system only needs to decode the instruction stream once. The LSD detects these loops (backward branches) which could be streamed directly from the IDQ. When such a loop is detected, the micro-ops are locked down and the loop is allowed to stream from the IDQ until a mis-prediction ends it. When the loop plays back from the IDQ, it provides higher bandwidth at reduced power, (since much of the rest of the front end pipeline is shut off. In the previous micro-architecture the loop detector was working with the instructions within the IQ upstream. The LSD provides a number of benefits, including,
- no loss of bandwidth due to taken-branches,
- no loss of bandwidth due to misaligned instructions,
- no LCP penalties, as the pre-decode stage are used once for the instruction stream within the loop,
- reduced front-end power consumption, because the instruction cache, BPU and pre-decode unit can go to idle mode.
However, note that loop unrolling and other code optimizations may make the loop too big to fit into the LSD. For high performance code, loop unrolling is generally considered superior for performance even when it overflows the loop cache capability.
- Stack Pointer Tracking (SPT) implements the Stack Pointer Register (RSP) update logic of instructions which manipulate the program stack (PUSH, POP, CALL, LEAVE and RET) within the IDU. These macro-instructions were implemented by several micro-ops in previous architectures. The benefits with SPT include
- using a single micro-op for these instructions improves decoder bandwidth,
- execution resources are conserved since RSP updates do not compete for them,
- parallelism in the execution engine is improved since the implicit serial dependencies have already been taken care of,
- power efficiency improves since RSP updates are carried out by a small hardware unit.
- Micro-Fusion The instruction decoder supports micro-fusion to improve pipeline front-end throughput and increase the effective size of queues in the scheduler and re-order buffer (ROB). Micro-fusion fuses multiple micro-ops from the same instruction into a single complex micro-op. The complex micro-op is dispatched in the out-of-order execution core. This reduces power consumption as the complex micro-op represents more work in a smaller format (in terms of bit density), and reduces overall "bit-toggling" in the machine for a given amount of work. It virtually increases the amount of storage in the out-of-order execution engine. Many instructions provide register and memory flavors. The flavor involving a memory operand will decodes into a longer flow of micro-ops than the register version. Micro-fusion enables software to use memory to register operations to express the actual program behavior without worrying about a loss of decoder bandwidth.
- Macro-Fusion The IDU supports macro-fusion which translates adjacent macro-instructions into a single micro-op if possible. Macro-fusion allows logical compare or test instructions to be combined with adjacent conditional jump instructions into one micro-operation.
Nehalem Core: Out-of-Order Execution Engine
The execution engine (EE) in a Nehalem core selects micro-ops from the upstream IDQ and dynamically schedules them for dispatching and execution by the execution units downstream. The EE is a dynamically scheduled "out-of-order", super-scalar pipeline which allows micro-ops to use available execution units in parallel when correctness and code semantics are not violated. The EE scheduler can dispatch up to 6 micro-ops in one clock cycle through the six dispatch ports to the execution units. There are several FUs, arranged in three clusters, for integer, FP and SIMD operations. Finally, four micro-ops can retire in one cycle, which is the same as in Nehalem's predecessor cores. Results can be written-back at the maximum rate of one register per per port per cycle. Fig. 7 presents a high-level diagram of the Execution Engine along with its various functional units.
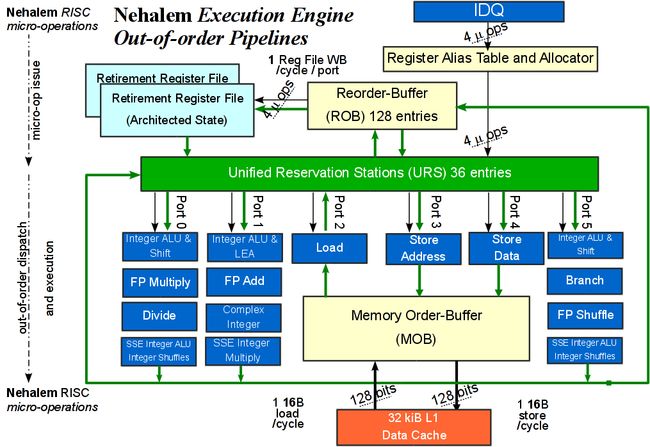
Fig. 7 High-level diagram of a the out-of-order execution engine in the Nehalem core. All units are fully pipelined and can operate independently.
The execution engine includes the following major components:
- Register Rename and Allocation Unit (RRAU) − Allocates EE resources to micro-ops in the IDQ and moves them to the EE.
- Reorder Buffer (ROB) − Tracks all micro-ops in-flight,
- Unified Reservation Station (URS) − Queues up to 36 micro-ops until all source operands are ready, schedules and dispatches ready micro-ops to the available execution units.
- Memory Order Buffer (MOB) − Supports speculative and out of order loads and stores and ensures that writes to memory take place in the right order and with the right data.
- Execution Units and Operand Forwarding Network The execution units are fully pipelined and can produce a result for most micro-ops with latency 1 cycle.
The IDQ unit (see Fig. 6) delivers a stream of micro-ops to the allocation/renaming stage of the EE pipeline. The execution engine of Nehalem supports up to 128 micro-ops in flight. The input data associated with a micro-op are generally either read from the ROB or from the retired register file. When a "dependency chain" across micro-ops causes the machine to wait for a "slow" resource (such as a data read from L2 data cache), the EE allows other micro-ops to proceed. The primary objective of the execution engine is to increase the flow of micro-ops, maximizing the overall rate of instructions reaching completion per cycle (IPC), without compromising program correctness.
Resource Allocation and Register Renaming for micro-ops The initial stages of the out of order core advance the micro-ops from the front end to the ROB and RS. This process is called micro-op issue. The RRAU in the out of order core carries out the following steps.
- It allocates resources to micro-ops, such as,
- an entry in the re-order buffer (ROB),
- an entry in the reservation station (RS),
- and a load/store buffer if a memory access is required.
- It binds the micro-op to an appropriate "dispatch" (or "issue") port.
- It "renames" source and destination operands of micro-ops in-flight, enabling out of order execution. Operands are registers or memory in general. "Architectural" (program visible) registers are renamed onto a larger set of "micro-architectural" (or "non-architectural") registers. Modern processors contain a large pool of non-architectural registers, that is, registers which are not accessible from the code. These registers are used to capture results which are produced by independent computations but which happen to refer to the same architected register as destination. Register renaming eliminates these false dependencies which are known as "write-after-write" and "write-after-read" hazards. A "hazard" is any condition which could force a pipeline to stall to avoid erroneous results.
- It provides data to the micro-op when the data is either an immediate value (a constant) or a register value that has already been calculated.
Unified Reservation Station (URS) queues micro-ops until all source operands are ready, then it schedules and dispatches ready micro-ops to the available execution units. The RS has 36 entries, that is, at any moment there is a window of up to 36 micro-ops waiting in the EE to receive input. A single scheduler in the Unified-Reservation Station (URS) dynamically selects micro-ops for dispatching to the execution units, for all operation types, integer, FP, SIMD, branch, etc. In each cycle, the URS can dispatch up to six micro-ops, which are ready to execute. A micro-op is ready to execute as soon as its input operands become available. The URS dispatches micro-ops through the 6 issue ports to the execution units clusters. Fig. 7 shows the 6 issue ports in the execution engine. Each cluster may contain a collection of integer, FP and SIMD execution units.
The result produced by an execution unit computing a micro-op are eventually written back permanent storage. Each clock cycle, up to 4 results may be either written back to the RS or to the ROB. New results can be forwarded immediately through a bypass network to a micro-op in-flight that requires it as input. Results in the RS can be used as early as in the next clock cycle.
The EE schedules and executes next common micro-operations, as follows.
- Micro-ops with single-cycle latency can be executed by multiple execution units, enabling multiple streams of dependent operations to be executed quickly.
- Frequently-used micro-ops with longer latency have pipelined execution units so that multiple micro-ops of these types may be executing in different parts of the pipeline simultaneously.
- Operations with data-dependent latencies, such as division, have data dependent latencies. Integer division parses the operands to perform the calculation only on significant portions of the operands, thereby speeding up common cases of dividing by small numbers.
- Floating point operations with fixed latency for operands that meet certain restrictions are considered exceptional cases and are executed with higher latency and reduced throughput. The lower-throughput cases do not affect latency and throughput for more common cases.
- Memory operands with variable latency, even in the case of an L1 cache hit, are not known to be safe for forwarding and may wait until a store-address is resolved before executing. The memory order buffer (MOB) accepts and processes all memory operations.
Nehalem Issue Ports and Execution Units The URS scheduler can dispatch up to six micro-ops per cycle through the six issue ports to the execution engine which can execute up to 6 operations per clock cycle, namely
- 3 memory operations (1 integer and FP load, 1 store address and 1 store data) and
- 3 arithmetic/logic operations.
The ultimate goal is to keep the execution units utilized most of the time. Nehalem contains the following components which are used to buffer micro-ops or intermediate results until the retirement stage
- 36 reservation stations
- 48 load buffers to track all allocate load operations,
- 32 store buffers to track all allocate store operations, and
- 10 fill buffers.
The execution core contains the three execution clusters, namely, SIMD integer, regular integer and SIMD floating-point/x87 units. Each blue block in Fig. 7 is a cluster of execution units (EU) in the execution engine. All EUs are fully pipelined which means they can deliver one result on each clock cycle. Latencies through the EU pipelines vary with complexity of the micro-op from 1 to 5 cycles Specifically, the EUs associated with each port are the following:
- Port 0
- Integer ALU and Shift Units
- Integer SIMD ALU and SIMD shuffle
- Single precision FP MUL, double precision FP MUL, FP MUL (x87), FP/SIMD/SSE2 Move and Logic and FP Shuffle, DIV/SQRT
- Port 1
- Integer ALU, integer LEA and integer MUL
- Integer SIMD MUL, integer SIMD shift, PSAD and string compare, and
- FP ADD
- Port 2
- Integer loads
- Port 3
- Store address
- Port 4
- Store data
- Port 5
- Integer ALU and Shift Units, jump
- Integer SIMD ALU and SIMD shuffle
- FP/SIMD/SSE2 Move and Logic
The execution core also contains connections to and from the memory cluster (see Fig. 7). <pForwarding and By-pass Operand Network Nehalem can support write back throughput of one register file write per cycle per port. The bypass network consists of three domains of integer, FP and SIMD. Forwarding the result within the same bypass domain from a producer micro-op to a consumer micro-op is done efficiently in hardware without delay. Forwarding the result across different bypass domains may be subject to additional bypass delays. The bypass delays may be visible to software in addition to the latency and throughput characteristics of individual execution units.
The Re-Order Buffer (ROB) is a key structure in the execution engine for ensuring the successful out-of-order progress-to-completion of the micro-ops. The ROB holds micro-ops in various stages of completion, it buffers completed micro-ops, updates the architectural state in macro-instruction program order, and manages ordering of the various machine exceptions. On Nehalem the ROB has 128 entries to track micro-ops in flight.
Retirement and write-back of state to architected registers is only done for instructions and micro-ops that are on the correct instruction execution path. Instructions and micro-ops of incorrectly predicted paths are flushed as soon as mis-prediction is detected and the correct paths are then processed.
Retirement of the correct execution path instructions can proceed when two conditions are satisfied:
- all micro-ops associated with the macro-instruction to be retired have completed, allowing the retirement of the entire instruction. In the case of instructions that generate very large numbers of micro-ops, enough to fill the retirement window, micro-ops may retire.
- Older instructions and their micro-ops of correctly predicted paths have retired.
These requirements ensure that the processor updates the visible state consistently with the in-order execution of the macro-instructions of the code. The advantages of this design is that older instructions which have to block waiting, for example, for the arrival of data from memory, cannot block younger, but independent, instructions and micro-ops, whose inputs are available. The micro-ops of these younger instructions can be dispatched to the execution units and warehoused in the ROB until completion.
Nehalem Core: Load and Store Operations
The memory cluster in the Nehalem core supports:
- peak issue rate of one 128-bit (16 bytes) load and one 128-bit store operation per clock cycle
- deep buffers for data load and store operations:
- 48 load buffers,
- 32 store buffers and
- 10 fill buffers;
- fast unaligned memory access and robust handling of memory alignment hazards;
- improved store-forwarding for aligned and non-aligned scenarios, and
- store-to-load data forwarding for most address alignments.
Note that the h/w for memory access and its capabilities as seen by the core are described in detail in a later subsection. Nehalem Core: Intel� Streaming SIMD Extensions Instruction Set
Single-Instruction Multiple-Data (SIMD) is a processing technique were the same operation is applied simultaneously to different sets of input operands. Vector operations, such as, vector additions, subtractions, etc. are examples of computation where SIMD processing can be applied directly. SIMD requires the presence of multiple Arithmetic and Logic Units (ALUs) and multiple source and destination operands for these operations. The multiple ALUs can produce multiple results simultaneously using input operands. Fig. 8 illustrates an example SIMD computation against four operands.
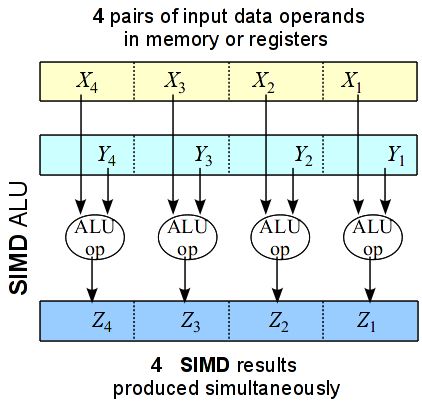
Fig. 8 SIMD instructions apply the same FP or integer operation to collections of input data pairs simultaneously.
Nehalem supports SIMD processing to integer or floating-point ALU intensive code with the Streaming SIMD Extensions (SSE) instruction set. This technology has evolved with time and now it represents a rather significant capability in Nehalem's micro-architectures. Fig. 9 illustrates the SIMD computation mode in Nehalem. On the left part of Fig. 9, two double-precision floating-point operations are applied to 2 DP input operands. On the right part of Fig. 9, four single-precision floating-point operations are applied to 4 SP input operands.
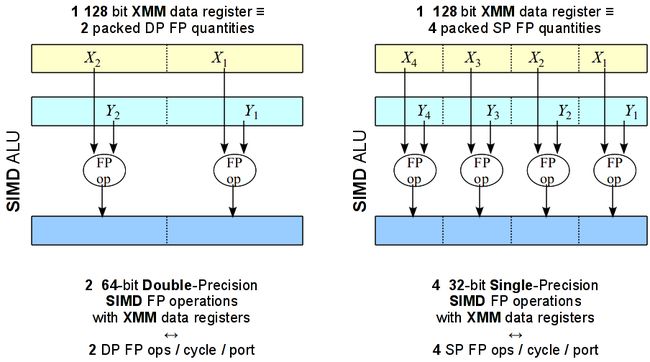
Fig. 9 Floating-Point SIMD Operations in Nehalem.
Nehalem's execution engine (see Fig. 7) contains the ALU circuitry necessary to carry out two double-precision, or four single-precision "simple" FP operations, such as addition or subtraction, in each one of the two FP units accessible through ports 0 and 1. Note that Nehalem execution engine can retire up to 4 operations per clock cycle, including the SIMD FP ones.
Ideal Floating-Point Throughput For the Xeon 5560 which operates at 2.8GHz, we can say that in the steady state and under ideal conditions each core can retire 4 double-precision or 8 single-precision floating-point operations each cycle. Therefore, the nominal, ideal throughput of a Nehalem core, a quad core and a 2-socket system are, respectively,
11.2 Giga FLOPs / sec / core = 2.8 GHz X 4 FLOPs / Hz
44.8 Giga FLOPs / sec /socket = 11.2 GigaFLOPs/sec / core X 4 cores
89.6 Giga FLOPs / sec / node = 44.8 GigaFLOPs/sec / socket X 2 sockets,
in terms of double-precision FP operations.

Fig. 10 Floating-Point Registers in a Nehalem core.
SIMD instructions use sets of separate core registers called MMX and XMM registers (shown in Fig. 10). The MMX registers are 64-bit in size and are aliased to the operand stack for the legacy x87 instructions. XMM registers are 128-bit in size and each can store either 4 SP or 2 DP floating-point operands. The load and store units can retrieve and save 128-bit operands from cache or from the main memory.
One interesting feature of Nehalem's memory subsystem is that certain memory areas can be treated as "non-temporal", that is, they can be used as buffers for vector data streaming in and out of the core, without requiring their temporary storage in a cache. This is an efficient way to retrieve a stream of sub-vector operands from memory to XMM registers, carry out SIMD computation and then stream the results out directly to memory.
Overview of the SSE Instruction Set Intel introduced and extended the support for SIMD operations in stages over time as new generations of micro-architectures and SSE instructions were released. Below we summarize the main characteristics of the SSE instructions in the order of their appearance.
MMX(TM) Technology Support for SIMD computations was introduced to the architecture with the "MMX technology". MMX allows SIMD computation on packed byte, word, and double-word integers. The integers are contained in a set of eight 64-bit MMX registers (shown in Fig. 10).
Streaming SIMD Extensions (SSE) SSE instructions can be used for 3D geometry, 3D rendering, speech recognition, and video encoding and decoding. SSE introduced 128-bit XMM registers, 128-bit data type with four packed single-precision floating-point operands, data prefetch instructions, non-temporal store instructions and other cache-ability and memory ordering instructions, extra 64-bit SIMD integer support.
Streaming SIMD Extensions 2 (SSE2) SSE2 instructions are useful for 3D graphics, video decoding/encoding, and encryption. SSE2 add 128-bit data type with two packed double-precision floating-point operands, 128-bit data types for SIMD integer operation on 16-byte, 8-word, 4-double-word, or 2-quad-word integers, support for SIMD arithmetic on 64-bit integer operands, instructions for converting between new and existing data types, extended support for data shuffling and extended support for cache-ability and memory ordering operations.
Streaming SIMD Extensions 3 (SSE3) SSE3 instructions are useful for scientific, video and multi-threaded applications. SSE3 add SIMD floating-point instructions for asymmetric and horizontal computation, a special-purpose 128-bit load instruction to avoid cache line splits, an x87 FPU instruction to convert to integer independent of the floating-point control word (FCW) and instructions to support thread synchronization.
Supplemental Streaming SIMD Extensions 3 (SSSE3) SSSE3 introduces 32 new instructions to accelerate eight types of computations on packed integers.
SSE4.1 SSE4.1 introduces 47 new instructions to accelerate video, imaging and 3D applications. SSE4.1 also improves compiler vectorization and significantly increase support for packed dword computation.
SSE4.2 Intel during 2008 introduced a new set of instructions collectively called as SSE4.2. SSE4 has been defined for Intel's 45nm products including Nehalem. A set of 7 new instructions for SSE4.2 were introduced in Nehalem architecture in 2008. The first version of SSE4.1 was present in the Penryn processor.
SSE4.2 instructions are further divided into 2 distinct sub-groups, called "STTNI" and "ATA".
- STring and Text New Instructions (STTNI) instructions operate on strings of bytes or words of 16bit size. There are four new STTNI instructions which accelerate string and text processing. For example, code can parse XML strings faster and can carry out faster search and pattern matching. Implementation supports parallel data matching and comparison operations.
- Application Targeted Accelerators (ATA) are instructions which can provide direct benefit to specific application targets. There are two ATA instructions, namely "POPCNT" and "CRC32".
- POPCNT is an ATA for fast pattern recognition while processing large data sets. It improves performance for DNA/Genome Mining and handwriting/voice recognition algorithms. It can also speed up Hamming distance or population count computation.
- CRC32 is an ATA which accelerates in hardware CRC calculation. This targets Network Attached Storage (NAS) using iSCSI. It improves power efficiency and reduces time for software I-SCSI, RDMA, and SCTP protocols by replacing complex instruction sequences with a single instruction.
Compiler Optimizations for SIMD Support in Executables User applications can leverage the SIMD capabilities of Nehalem through the Intel Compilers and various performance libraries which have been tuned up to take advantage of this feature. On EOS, use the following compiler options and flags.
- -xHost (or the -xSSE4.2) compiler options to instruct the compiler to use the entire set of SSE instructions in the generated binary
- -vec This option enables "vectorization" (better term would be SIMDizations) and transformations enabled for vectorization. This effectively asks the compiler to attempt to use the SIMD SSE instructions available in Nehalem. Use the -vec-reportN option to see which lines could use SIMD and which could not and why.
- -O2 or -O3
Libraries Optimized for SIMD Support Intel provides user Libraries tuned up for SIMD computation. These include, Intel's Math-Kernel Library (MKL), Intel's standard math library (libimf) and the Integrated-Performance Primitive library (IPP). Please review the "~/README" text file on your EOS home directory with information on the available software and instructions how to access it. This document contains, among other things, a useful discussion on compiler flags used for optimization of user code, including SIMD.
Floating-Point Processing and Exception Handling
Nehalem processors implement a floating-point system compliant with the ANSI/IEEE Standard 754-1985, "IEEE Standard for Binary Floating-Point Arithmetic". IEEE 754 defines required arithmetic operations (addition, subtraction, sqrt, etc.), the binary representation of floating and fixed point quantities and conditions which render machine arithmetic valid or invalid. Before this standard, different vendors used to have their own incompatible FP arithmetic implementations making portability of FP computation virtually impossible. When the result of an arithmetic operation cannot be considered valid or when precision is lost, the h/w handles a Floating-Point Exception (FPE).
Nehalem Floating-Point Exceptions The following floating-point exceptions are detected by the processor:
- IEEE standard exception: invalid operation exception for invalid arithmetic operands and unsupported formats (#IA)
- Signaling NaN
- Infinity - Infinity
- Infinity � Infinity
- Zero � Zero
- Infinity � Zero
- Invalid Compare
- Invalid Square Root
- Invalid Integer Conversion
- Zero Divide Exception (#Z)
- Numeric Overflow Exception (#O)
- Underflow Exception (#U)
- Inexact Exception (#P)
The standard defines the exact conditions raising floating point exceptions and provides well-prescribed procedures to handle them. A user application has a set of choices in how to treat and/or respond, if necessary, to these exceptions. However, detailed treatment of FPEs is far beyond the scope of this write up. Please review the following presentation on IEEE Floating-Point Standard and Floating Point Exception handling which apply to Nehalem. Note that this presentation is under revision but it is provides useful material for FP arithmetic.
Intel� Simultaneous Multi-Threading
A Nehalem core supports "Simultaneous Multi-Threading" (SMT), or as Intel calls it Hyper-Threading. SMT is a pipeline design and implementation scheme which permits more than one hardware threads to execute simultaneously within each core and share its resources. For Nehalem, two threads can be simultaneously executing within each core. Fig. 7 shows the different execution units within a Nehalem core which the two SMT threads can share.
Basic SMT Principles
The objective of SMT is to allow the 2nd hardware thread to utilize functional units in a core which the 1st hardware thread leaves idle. In Fig. 11, the right-hand side part demonstrates the case where two threads execute simultaneously within a core with SMT enabled. The horizontal dimension shows the occupancy of the functional units of a core and the vertical one shows consecutive clock cycles. As you can see, both SMT threads may "simultaneously" (i.e., at the same clock period) utilize these units, making progress.
The alternative to SMT would be to let a thread run until it has to stall (e.g., waiting for a lengthy FP operation to finish or a cache memory miss to be handled), at which point in time the OS dispatcher would have to carry out a costly context-switching operation with processor state swapping. This is illustrated in an idealized fashion (i.e., without accounting for the resource waste due to context-switching overhead) on the right-hand side part of the figure. SMT can potentially exploit "task-level" concurrency at a very fine level and produces cost saving by avoiding context-switching.
In short, the potential advantages of SMT are several, including among others, the increased utilization of functional units that would have remained idle, the overall increased throughput in instructions completed per clock cycle and the overhead savings from the lower number of thread switching operations. It implicitly can save power consumed by the idle units.

Fig. 11 Simultaneous Multi-Treading (SMT) concept on Nehalem cores.
When SMT is ON, each Nehalem core appears to the Operating System as two logical processors. An SMT enabled dx360-M2 node appears as 16 logical processors to Linux.
On Nehalem, SMT takes advantage of the 4-wide execution engine. The units are kept busy with the two threads. SMT hides the latency experienced by a single thread. One prominent advantage is that with SMT it is more likely that an active unit will be producing some result on behalf of a thread as opposed to consuming power while it is waiting for work. Overall, SMT is much more efficient in terms of power than adding another core. One Nehalem, SMT is supported by the high memory bandwidth and the larger cache sizes.
Resources on Nehalem Cores Shared Among SMT Threads
The Nehalem core supports SMT by replicating, partitioning or sharing existing functional units in the core. Specifically the following strategies are used:
- Replication The unit is replicated for each thread.
- register state
- renamed RSB
- large page ITLB
- PartitioningThe unit is statically allocated between the two threads
- load buffer
- store buffer
- reorder buffer
- small page ITLB
- Competitive SharingThe unit is dynamically allocated between the two threads
- reservation station
- cache memories
- data TLB
- 2nd level TLB
- SMT Insensitive All execution units are SMT transparent
CISC and RISC Processors
From the discussion above, it is clear that on the Nehalem processor, the CISC nature of the Intel64 ISA exits the scene after the instruction decoding phase by the IDU. By that time all CISC macro-instructions have been converted into RISC like micro-ops which are then scheduled dynamically for parallel processing at the execution engine. The specific execution engine of the Nehalem we described above could have been be part of any RISC or CISC processor. In deed one cannot tell by examining it if it is part of a CISC or a RISC processor. Please see a companion article on Power5+ processors and systems to make comparisons and draw some preliminary conclusions.
Efficient execution of applications is the ultimate objective and this requires an efficient flow of ISA macro-instructions through the processor. This implies accurate branch prediction and efficient fetching of instructions, their efficient decoding into micro-ops and a maximal flow of micro-ops from issue to retirement through the execution engine.
This points to one of the successes of the "RISC approach" where sub-tasks are simple and can be executed in parallel in multiple FUs by dynamic dispatching. Conversely, Nehalem has invested heavily in silicon real estate and clock cycles into pre-processing the CISC macro-instructions so that can be smoothly converted into sequences of micro-ops. The varying length of the CISC instructions requires the additional overhead in the ILD. A RISC ISA would had avoided this overhead and instructions would had moved directly from fetch to decoding stage.
At the same time, it is obvious that Intel has done a great job in processing very efficiently a heavy-weight CISC ISA, using all the RISC techniques. Thus the debate of RISC vs. CISC remains a valid and open question.
- Given modern back-end engines, which ISA style is more efficient to capture at a higher-level the semantics of applications?
- Is it more efficient to use a RISC back-end engine with a CISC or a RISC ISA and front-ends?
- It would be very interesting to see how well the Nehalem back-end execution engine would perform when fitted in a RISC processor front-end, handling a classical RISC ISA. For instance, how would a classical RISC, such as a Power5+ would perform if the Nehalem execution engine were to replace its own?
- Conversely, how would the Nehalem perform if it were fitted with the back-end execution engine of a classical RISC, such as that of an IBM Power5+ processor ?
- From the core designer point of view, can I select different execution engines for the same ISA ?
The old CISC vs.RISC debate is resurfacing as a question of how more aptly and concisely RISC or a CISC ISA can express the semantics of applications, so that when the code is translated into micro-ops powerful back-end execution engines can produce results at a lower cost, i.e., in shorter amount of time and/or using less power?
Memory Organization in Nehalem Processors and Platforms
Cache-Memory and the Locality Phenomenon
The demand for increasingly larger data and instruction sections in applications requires that the size of the main memory hosting them be also sufficiently large. Experience with modern processors suggests that 2 to 4 GiB are needed per compute core to provide a comfortable size for a main memory. However, cost and power consumption for this large amounts of memory, necessitates the use of the so called, Dynamic Random Access Memory (DRAM) technology. DRAM allows the manufacturing of large amounts of memory using simpler memory elements (i.e., by a transistor and a capacitor which needs to be dynamically refreshed every a few 10s of mili-seconds). However, the bandwidth rates at which modern processors require to access memory in order to operate efficiently, far exceed the memory bandwidth that can be supported with current DRAM technologies.
Another type of memory, called "Static RAM" (SRAM) implements memory elements with more complex organization (5-6 transistors). SRAM is much faster than the DRAM and it does not require periodic refreshing of the bit contents. However, with more electronic components per bit, memory density per chip decreases dramatically while the power consumption grows. We cannot currently provide 2-4 GiB of RAM per core using just SRAM with a viable cost.
Computer architects design modern processors with multiple levels of faster, smaller and more expensive cache memories. Cache memories, mostly implemented with SRAM logic, maintain copies of recently and frequently used instruction and data blocks of the "main" (DRAM) memory. When an object is accessed for the first time, the hardware retrieves a block of memory containing it from the DRAM and stores it in the cache. Subsequent object accesses go directly to the faster cache and avoid the lengthy access to DRAM.
This is a viable approach due to the phenomenon of "temporal" and "spatial locality" in the memory access patterns which executable code exhibit. Simply speaking, temporal locality means that objects (data or instructions) accessed recently, have a higher probability to get accessed in the near future than other memory objects. Spatial locality means that objects physically adjacent in memory to those accessed recently have a higher probability of getting accessed "soon". Temporal locality stems from the fact that within in a short span of time instructions in iterations (loops) are executed repeatedly likely accessing common data. Spatial locality is the result of code accessing dense array locations in linear order or simply accessing the next in sequence instruction. Hardware and compiler designers invest heavily in mechanisms which can leverage the locality phenomenon. Compilers strive to co-locate items which are likely to be accessed together within short time spans. Hardware logic detects sequential memory access and attempts to pre-fetch subsequent blocks ahead of time. The cache memories eventually have to evict least used contents to make room for incoming new ones.
Cache-Memory Organization in Nehalem
Nehalem divides the physical memory into blocks 64 byte in size. These blocks, referred to as "cache blocks" or "cache lines", are the units of data the memory system transfers among the major subsystems.
The architecture supports a hierarchy of up to three levels of cache memory and DRAM memory. Fig. 12 shows the different caches in a Nehalem chip, their connectivity with the common L3, QPI and IMC, along with the TLBs translation structures.
Fig. 12 Overview of Cache Memory Hierarchy and Data Flow Paths to and from Nehalem's Core.
Referring to Fig. 12, a Nehalem core contains an instruction cache, a first-level data cache and a second-level unified cache. Each physical processor chip may contain several processor cores and a shared collection of subsystems that are referred to as "un-core". Specifically, in Intel Xeon 5560 processors, there are four cores and the un-core provides a unified third-level cache shared by all cores in the chip, Intel QuickPath Interconnect ports and auxiliary logic such as, a performance monitoring unit, control configuration registers and power management units, among others.
The processor always reads a cache line from system memory beginning on a 64-byte boundary (which has an address with its 6 least-significant bits zero). A cache line can be filled from memory with a 8-transfer burst transaction. The caches do not support partially-filled cache lines, so caching even a single double-word requires caching an entire line.
L1 Cache At Level 1 (L1), separate instruction and data caches are part of the Nehalem core (called a "Harvard" style). The instruction and the data cache are each 32 KiB in size. The L1 data-cache has a single access data port, and a block size of 64 bytes. In SMT mode, the caches are shared by the two hardware threads running in the core.
The instruction and the data caches have 4-way and 8-way set associative organization, respectively. The access latency to retrieve data already in L1 data-cache is 4 clocks and the "throughput" period is 1 clock. The write policy is write-back.
L2 Cache Each core also contains a private, 256KiB, 8-way set associative, unified level 2 (L2) cache (for both instructions and data). L2's block size is 64 bytes and access time for data already in the cache is 10 clocks. The write policy is write-back and the cache is non-inclusive.
L3 Cache The Level 3 (L3) cache is a unified, 16-way set associative, 8 MiB cache shared by all four cores on the Nehalem chip. The latency of L3 access may vary as a function of the frequency ratio between the processor and the un-core sub-system. Access latency is around 35 − 40+ cycles.
The L3 is inclusive (unlike L1 and L2), meaning that a cache line that exists in either L1 data or instruction, or the L2 unified caches, also exists in L3. The L3 is designed to use the inclusive nature to minimize "snoop" traffic between processor cores and processor sockets. A 4-bit valid vector indicates if a particular L3 block is already cached in the L2 or L1 cache of a particular core in the socket. If the associated bit is not set, it is certain that this core is not caching this block. A cache block in use by a core in a socket, is cached by its L3 cache which can respond to snoop requests by other chips, without disturbing (snooping into) L2 or L1 caches on the same chip. The write policy is write-back.
Nehalem Memory Access Enhancements
The data path from L1 data cache to the memory cluster is 16 bytes in each direction. Nehalem maintains load and store buffers between the L1 data cache and the core itself.
Store Buffers
Intel64 processors temporarily store data for each write (store operation) to memory in a store buffer (SB). SBs are associated with the execution unit in Nehalem cores. They are located between the core and the L1 data-cache. SBs improve processor performance by allowing the processor to continue executing instructions without having to wait until a write to memory and/or to a cache is complete. It also allows writes to be delayed for more efficient use of memory-access bus cycles. In general, the existence of store buffers is transparent to software, even in multi-processor systems like the Nehalem-EP. The processor ensures that write operations are always carried out in program order. It also insures that the contents of the store buffer are always drained to memory when necessary.
- when an exception or interrupt is generated;
- when a serializing instruction is executed;
- when an I/O instruction is executed;
- when a LOCK operation is performed;
- when a BINIT operation is performed;
- when using an SFENCE or MFENCE instruction to order stores.
Load and Store Enhancements
The memory cluster of Nehalem supports a number of mechanisms which speed up memory operations, including
- out of order execution of memory operations,
- peak issue rate of one 128-bit load and one 128-bit store operation per cycle from L1 cache,
- "deeper" buffers for load and store operations: 48 load buffers, 32 store buffers and 10 fill buffers,
- data pref-etching to L1 caches,
- data prefetch logic for pref-etching to the L2 cache
- fast unaligned memory access and robust handling of memory alignment hazards,
- memory disambiguation,
- store forwarding for most address alignments and
- pipelined read-for-ownership operation (RFO).
Data Load and Stores Nehalem can execute up to one 128-bit load and up to one 128-bit store per cycle, each to different memory locations. The micro-architecture enables execution of memory operations out-of-order with respect to other instructions and with respect to other memory operations.
Loads can
- issue before preceding stores when the load address and store address are known not to conflict,
- be carried out speculatively, before preceding branches are resolved
- take cache misses out of order and in an overlapped manner
- issue before preceding stores, speculating that the store is not going to be to a conflicting address.
Loads cannot
- speculatively take any sort of fault or trap
- speculatively access the uncacheable memory type
Faulting or uncacheable loads are detected and wait until retirement, when they update the programmer visible state. x87 and floating point SIMD loads add 1 additional clock latency. Stores to memory are executed in two phases:
- Execution Phase Prepares the store buffers with address and data for store forwarding (see below). Consumes dispatch ports 3 and 4.
- Completion Phase The store is retired to programmer-visible memory. This may compete for cache banks with executing loads. Store retirement is maintained as a background task by the Memory Order Buffer, moving the data from the store buffers to the L1 cache.
Data Pre-fetching to L1 Caches Nehalem supports hardware logic (DPL1) for two data pre-fetchers in the L1 cache. Namely
- Data Cache Unit (DCU) Prefetcher (also known as the "streaming prefetcher"), is triggered by an ascending access to recently loaded data. The logic assumes that this access is part of a streaming algorithm and automatically fetches the next line.
- Instruction Pointer-based Strided Prefetcher keeps track of individual load instructions. When load instructions have a regular stride, a prefetch is sent to the next address which is the sum of the current address and the stride. This can prefetch forward or backward and can detect strides of up to half of a 4KB-page, or 2 KBytes.
Data pre-fetching works on loads only when loads is from write-back memory type, the request is within the page boundary of 4 KiB, no fence or lock is in progress in the pipeline, the number of outstanding load misses in progress are below a threshold, the memory is not very busy and there is no continuous stream of stores waiting to get processed. L1 pre-fetching usually improves the performance of the memory subsystem, but in rare occasions it may degrade it. The key to success is to issue the pre-fetch to data that the code will use in the near future when the path from memory to L1 cache is not congested, thus effectively spreading out the memory operations over time. Under these circumstances pre-fetching improves performance by anticipating the retrieval of data in large sequential structures in the program. However, it may cause some performance degradation due to bandwidth issues if access patterns are sparse instead of having spatial locality.�
On certain occasions, if the algorithm's working set is tuned to occupy most of the cache and unneeded pre-fetches evict lines required by the program, hardware prefetcher may cause severe performance degradation due to cache capacity of L1.
In contrast to hardware prefetchers, software prefetch instructions relies on the programmer or the compiler to anticipate data cache miss traffic. Software prefetch act as hints to bring a cache line of data into the desired levels of the cache hierarchy.
Data Pre-fetching to L2 Caches DPL2 pre-fetch logic brings data to the L2 cache based on past request patterns of the L1 to the L2 data cache. DPL2 maintains two independent arrays to store addresses from the L1 cache, one for upstreams (12 entries) and one for down streams (4 entries). Each entry tracks accesses to one 4K byte page. DPL2 pre-fetches the next data block in a stream. It can also detect more complicated data accesses when intermediate data blocks are skipped. DPL2 adjusts its pre-fetching effort based on the utilization of the memory to cache paths. Separate state is maintained for each core.
Memory Disambiguation A load instruction micro-op may depend on a preceding store. Many micro-architectures block loads until all preceding store address are known. The memory disambiguator predicts which loads will not depend on any previous stores. When the disambiguator predicts that a load does not have such a dependency, the load takes its data from the L1 data cache. Eventually, the prediction is verified. If an actual conflict is detected, the load and all succeeding instructions are re-executed.
Store Forwarding When a load data follows a store which reloads the data the store just wrote to memory, the microarchitecture can forward the data directly from the store to the load in many cases. This is called "store-to-load" forwarding, and it saves several cycles by allowing a data requester receive data already available on the processor instead of waiting for a cache to respond. However several conditions must be met for store to load forwarding to proceed without delays:
- the store must be the last store to that address prior to the load,
- the store must be equal or greater in size than the size of data being loaded and
- the load data must be completely contained in the preceding store.
In previous micro-architectures specific address alignments and data sizes between the store and load operations would determine whether a store-to-load forwarding might proceed directly or get delayed going through the cache/memory sub-system. Intel microarchitecture (Nehalem) allows store-to-load forwarding to proceed regardless of store address alignment. Efficient Access to Unaligned Data The cache and memory subsystems handle a significant amount of instructions and data with different address alignment scenarios. Different address alignments have varying performance impact on memory and cache operations based on the implementation of these subsystems. On Nehalem the data path to the L1 caches are 16 bytes wide. The L1 data cache can deliver 16 bytes of data in every cycle, regardless how their addresses are aligned. However, if a 16-byte load spans across a cache line boundary, the data transfer will suffer a mild delay in the order of 4 to 5 clock cycles. Prior mircro-architectures imposed much heavier delays.
Nehalem EP Main Memory Organization
Integrated Memory Controller
The integrated memory controller (IMC) for Nehalem supports three 8-byte channels of DDR3 memory operating at up to 1.333 GigaTransfer/sec (GT/s). Fig. 13 shows the IMC in a Nehalem chip. Total theoretical bandwidth between DRAM and the IMC in the un-core domain of the chip is 31.992 GB/s. The memory controller supports both registered and un-registered DDR3 DRAM. Each channel of memory can operate independently and the controller services requests out-of-order to minimize latency. Each core supports up to 10 data cache misses and 16 total outstanding misses. This places a strict upper bound on the memory bandwidth per core.
Fig. 13 Nehalem On-Chip Memory Hierarchy and Data Traffic through the Chip
Cache-Coherence Protocol for Multi-Processors
The conveniences of the cache memories come with some extra cost when the system has multiple processors. Copies of data which have been retrieved and modified by a processor in its local cache are inconsistent with the original copy in main memory. When another processor accesses the same data item it should receive the latest up-to-date copy and not an older stale version of it. This problem of Memory Consistency is addressed with Cache Coherence (CC) mechanisms. CC ensures that the value of an item retrieved by any processor in the system is the most up-to-date one. CC may add considerable overhead in accessing memory in multi-processors. CC logic is in the critical path of accessing memory and can easily become the main bottleneck, exacerbating the processor and memory speed gap. Recent processors provide increasingly tuned and adaptive CC protocols which try to stay to any extend feasible out of the way in accessing memory. Ideally, accesses to disjoint data by separate processors should proceed without any additional overhead. Conflicting access to the same data item (reads and writes) by different processors should extend the latency as minimally as possible, maintain fairness and avoid indefinite postponement. Cache coherence mechanism have been studied extensively in the literature and still are hot topics as there is always an increasing demand for larger multi-processors and more efficient concurrent access to shared memory.
Cache-Coherence Protocol (MESI+F)
Practical reasons require that CC protocols maintain memory consistency in terms of 64-byte memory blocks and not in individual bytes or words. Memory blocks are the units of physical memory transfer. Each block has a unique identification, and belongs to a unique Nehalem socket ("home location") and is managed by the local IMC. Based on the way and time they propagate modifications of the blocks, CC protocols are divided into 2 categories, namely write-update and write-invalidate. Based on the way they locate multiple copies of the same block, are divided into "snoopy" and the directory based protocols. For the discussion which follows please refer to Fig. 13.
Nehalem processors use the MESIF (Modified, Exclusive, Shared, Invalid and Forwarding) cache protocol to maintain cache coherence with caches on the same chip and on other chips via the QPI. MESIF belongs to the write-invalidate, snoopy (with a small directory part) category, and it is a variation of the well known MESI protocol. The designations used in the its acronym are the possible states that cache memory blocks can be in as they are transferred among cores, caches, I/O and DRAM. When a core reads or modifies memory objects causes the their corresponding block to transition from one of these states to another. The current state of a block and the requested operation against it prescribes the h/w to follow a different sequence of tasks which provably maintain memory consistency.

Fig. 14 The State Transitions of Cache Blocks in the Basic MESI Cache-Coherence Protocol.
Initially all blocks in a cache do not store actual data and they are in the "Invalid" state. When a core reads a data object, it always checks first the L1 memory to see if the block is already there. The first time a block is accessed results in a cache read miss and it is in the Invalid state. If the block is not in L1 but is found in the L2 cache (L1 miss and L2 hit), it is transferred to the L1 data cache and the data access instruction proceeds. If the block is neither in the L2, then it must be retrieved from the "un-core". In general, a read-miss causes the core to retrieve the entire 64-byte cache block containing the object into the appropriate cache (L1, L2, L3, or all). This operation is called a cache-line fill. A block retrieved for the first time by any core transitions to the "Exclusive" state.
The next time a core needs to access the same or nearby memory locations, if the block is still in the cache the data object is retrieved directly from the cache instead of going back to memory. This is called a cache hit.
When a core has already retrieved a block in the Exclusive state and another core requires to read the same block, the h/w retrieves and stores a copy of this block in the cache of the latest core. The state of that block transitions to the "Shared" state.
When a core wants to write an operand to memory, it first checks if the corresponding block is already in the cache. If a valid cache line does exist, the processor can write the operand into the cache instead of writing it out to system memory. This operation is called a write hit.
A write which refers to a memory location not currently in the cache causes a write-miss. In this case the core performs a cache line-fill, write allocation and proceeds to modify the value of the operand in the cache line without writing directly to memory.
When a core attempts to modify data in a Shared state block, the h/w issues a "Request-for-Ownership" (RfO) transaction which invalidates all copies in other caches and transitions its own (unique now) copy to Exclusive state. The owning core can read and write to this block without having to notify the other cores. If any of the cores previously sharing this block attempts to read this block, it will receive a cache-miss since the block is Invalid in that core's cache. Note that when a core attempts to modify data in a Exclusive state block, NO "Request-for-Ownership" transaction is necessary since it is certain that no other processor is caching copies of this block.
For Nehalem which is a multi-processor platform, the processors have the ability to "snoop" (eavesdrop) the address bus for other processor's accesses to system memory and to their internal caches. They use this snooping ability to keep their internal caches consistent both with system memory and with the caches in other interconnected processors.
If through snooping one processor detects that another processor intends to write to a memory location that it currently has cached in Shared state, the snooping processor will invalidate its cache block forcing it to perform a cache line fill the next time it accesses the same memory location.
If a core detects that another core is trying to access a memory location that it has modified in its cache, but has not yet written back to system memory, the owning core signals the requesting core (by means of the "HITM#" signal) that the cache block is held in Modified state and will perform an implicit write-back of the modified data. The implicit write-back is transferred directly to the requesting core and snooped by the memory controller to assure that system memory has been updated. Here, the processor with the valid data can transfer the block directly to the other core without actually writing it to system memory; however, it is the responsibility of the memory controller to snoop this operation and update memory.
Each memory block can be stored in a unique set of cache locations, based on a subset of their memory block identification. A cache memory with associativity K can store each memory block to up to K alternative locations. If all K cache slots are occupied by memory blocks, the K+1 request will not have room to store this latest memory block. This requires that one of the existing K blocks has to be written out to memory (or the inclusive L3 cache) if this block is in Modified state. Cache memories commonly use a Least Recently Used (LRU) cache replacement strategy where they evict the block which has not been accessed recently.
As we mentioned, before written out to memory, data operands are first saved in a store buffer. They are then written from the store buffer to memory when the system path to memory is available.
Note that when all 10 of the line-fill buffers in a core become occupied, outstanding data access operations queue up in the load and store buffers and cannot proceed. When this happens the core's front end is suspends issuing micro-ops to the RS and OOO engine to maintain pipeline consistency.
The Un-Core Domain and Multi-Socket Cache Coherence
In the Nehalem processor the "un-core" domain essentially is a shared last level L3 cache ("LLC"), a memory access chip-set ("Northbridge"), and a QPI socket interconnection interface. Cache line access requests (such as, L2 cache misses, "un-cache-able" loads and stores) from the cores are serviced and the multi socket cache line coherency is maintained with the other sockets and the I/O Hub.
Memory consistency in a multi-core, multi-socket system like the Nehalem-PE, is maintained across sockets. With the introduction of the Intel Quick-Path Interconnect protocol the, 4 MESI states are supplemented with a fifth, Forward (F) state, for lines forwarded from one Nehalem socket to another.
Cache line requests from the on-chip four cores, from a remote chip or the I/O hub are handled by the Global Queue (GQ) (see Fig. 13). The GQ buffers, schedules and manages the flow of data traffic through the un-core. The GQ contains 3 request queues for the different request types:
- Write Queue (WQ): is a 16-entry queue for store (write) memory access operations from the local cores.
- Load Queue (LQ): is a 32-entry queue for load (read) memory requests by the local cores.
- QPI Queue (QQ): is a 12-entry queue for off-chip requests delivered by the QPI links.
When the GQ receives a cache line request from one of the cores, it first checks the on-chip Last Level Cache (L3) to see if the line is already cached there. As the L3 is inclusive, the answer can be quickly determined. If the line is in the L3 and was owned by the requesting core it can be returned to the core from the L3 cache directly. If the line is being used by multiple cores, the GQ snoops the other cores to see if there is a modified copy. If so the L3 cache is updated and the line is sent to the requesting core. In the event of an L3 cache miss, the GQ sends out requests for the line. Since the cache line could be cached in the other Nehalem chip, a request through the QPI to the remote L3 cache is made. As each Nehalem processor chip has its own local integrated memory controller, the GQ must identify the "home" location of the requested cache line from the physical address. If the address identifies home as being on the local chip, then the GQ makes a simultaneous request to the local IMC. If home belongs to the remote chip, the request sent by the QPI will also be used to access the remote IMC.
This process can be viewed in the terms of the QPI protocol as follows. Each socket has a "Caching Agent" (CA) which might be thought of as the GQ plus the L3 cache and a "Home agent" (HA) which is the IMC. An L3 cache miss results in simultaneous queries for the line from all the CAs and the HA (wherever home is). In a Nehalem-EP system there are 3 caching agents, namely the 2 sockets and an I/O hub. If none of the CAs has the cache line, the home agent ultimately delivers it to the caching agent that requested it. Clearly, the IMC has queues for handling local and remote, read and write requests.
Local vs. Remote Memory Access
In Nehalem, the integrated memory controller substantially improved memory latency and bandwidth, compared to predecessor micro-architectures. For the two socket implementations of Nehalem EP (see Fig. 15 ), the remote latency is higher, since the memory request and response must go through a QPI link. This shared memory organization is called "cache-coherent Non-Uniform Memory Access" (cc-NUMA) and it is very common in modern SMP platforms.
The latency to access the local memory is, approximately, 65 nano-seconds. The latency to access the remote memory is, approximately, 105 nano-seconds. That is, remote accesses are 1.6 to 1.7 times the latency of local memory access.
The available bandwidth through the QPI link is 12.8 GB/s which is approximately %40 of the theoretical bandwidth of the three local DDR3 channels.

Fig. 15 Nehalem-EP 8-way cc-NUMA SMP, Memory Hierarchies and Local vs. Remote Memory Organization.
Fig. 16 demonstrates access to memory which is directly (locally) attached to a Nehalem chip. The sequence of steps which take place are the following:
- Step1: CPU0 requests a cache line which is not in CPU0's cache
- CPU0 requests data from its DRAM ;
- CPU0 snoops CPU1 to check if data is present there.
- Step 2: Response
- DRAM returns data
- CPU1 returns snoop response
The local memory access latency is the maximum of the above two steps

Fig. 16 Nehalem Local Memory Access Event Sequence.
Fig. 17 demonstrates access to remote memory (directly attached to the other Nehalem chip). The sequence of steps which take place are the following:
- Step1: CPU0 requests a cache line which is not in CPU0's cache nor in directly attached DRAM
- Step 2: Request sent over Intel� QuickPath Interconnect to CPU1
- Step 3: CPU1's probe for cache line
- CPU1's IMC makes requests to its DRAM;
- CPU1 snoops internal caches;
- Step 4: Response
- Data returns to CPU0 via the QPI;
- CPU0 installs cache block
The remote memory access latency is the sum of steps 1, 2, 3 and 4 and clearly is a function of QPI latencies.
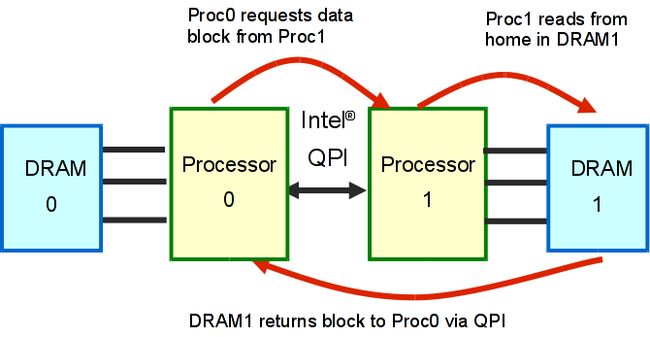
Fig. 17Nehalem Remote Memory Access Event Sequence.
The cache coherency protocol messages, among the multiple sockets, are exchanged over the Intel QPI. The inclusive L3 cache mode allows this protocol to operate rather fast, with the latency to the L3 cache of the adjacent socket being even less than the latency to the local memory.
One of the main virtues of the integrated memory controller is the separation of the cache coherency traffic and the memory access traffic. This enables a tangible increase in memory access bandwidth, compared to previous architectures, but it results in a non-uniform memory access (NUMA). The latency to the memory DIMMs attached to a remote socket is considerably longer than to the local DIMMs. A second advantage is that the memory control logic can run at processor frequencies and thereby reduce the latency.
Virtual Memory in Nehalem Processors
Virtual Memory
In modern processors, an executable is logically divided into "sections", or "segments" which have distinct function. For instance, an executable consists, among others, of a "code", a "stack" and a "heap" segment. For reasons of effective space management and efficient utilization, each segment is divided into logical units, called pages. A page in different varies from a few KiBytes in size, (e.g., 4 KiB) to several MiBytes or even GiBytes.
Each page can actually be stored anywhere in the physical memory, in any of the available main memory slots known as page frames. We can consider the main memory as an array of pages frames. As an example, a physical memory with 4GiBytes capacity has available exactly 1 Mi page frames for pages having 4KiB size. Applications can define vast amounts of memory, but they usually refer or access a very small subset of it. When a program references for the first time a memory location (for instance a new subroutine call or a reference to a data item in an array) the system selects a free page frame and "pages in" the corresponding page. Application pages already in page slots which have not been recently used become candidates for eviction to make room for new pages.
The mechanism which dynamically manages the page frames and keeps track of the mapping between pages and page frames is called the Virtual Memory (VM) management system.
While applications execute refer to memory using "Effective Addresses" (EA) which are virtual memory addresses. "Physical Addresses" (PA) are actual addresses the memory hardware uses to identify specific memory locations. The VM system dynamically translates EAs into PAs, in process called "Virtual Address Translation". VM systems keeps track of the various program segments and corresponding pages with in memory in data structures called VM segment and page tables. These structures end up taking plenty of memory space. Multiple levels of page tables are used to cut down on the actual space used. This multi-level indirection requires the traversal of multiple tables for each address an application uses and it is in the critical path of the tasks the processor has to carry out in order to retire each macro-instruction. For this reason, special hardware called "Translation Look-aside Buffers" (TLBs) is used to speed up this process.
Nehalem Address Translation Process
Address Sizes Intel64 architecture defines translation from a "flat", linear 64-bit "Effective Address" (EA) into a "Physical Address" (PA) with a width to up to 52 bits. Note that even though this mode produces 64-bit linear addresses, the processor ensures that bits 63:47 of such an address are identical. This implies that the Virtual Address (VA) the paging system uses has an effective width of 48 bits. Although 52 bits corresponds to 4 PiBytes, since linear addresses are limited to 48 bits, at most 256 TiBytes of linear-address space may be accessed at any given time by a single process.
VM Page Sizes Supported Nehalem support virtual memory page sizes of 4 KiB, and 2 MiB and 1GiB "large" pages. Please refer to Fig. 13 which shows in detail the hardware components involved in the EA to PA translation process and the various levels of cache memories.
TLBs The processor architecture specifies two-levels of translation look-aside buffers, TLB0 and TLB1 to speed-up the EA to PA translation process. The TLB is a cache of recently accessed page table entries (PTE). A PTE maps the address of a page referenced by the program to its actual page slot location in memory. The first level TLB0 consists of separate TLBs for data DTLB0 and instructions ITLB0. DTLB0 handles address translation for data accesses, it provides 64 entries to support 4KiB pages and 32 entries for large pages. The ITLB0 provides 64 entries (per thread) for 4KiB pages and 7 entries (per thread) for large pages. The second level unified UTLB1 handles both code and data accesses for 4KiB pages. It support 4KiB page translation operation that missed DTLB0 or ITLB0.
Here is a list of entries in each TLB
- ITLB0 for 4-KiB pages: 64 entries / SMT thread, 4-way associative;
- ITLB0 for 2-MiB pages: 7 entries / SMT thread, fully associative;
- DTLB0 for 4-KiBe pages: 64 entries, 4-way associative;
- DTLB0 for 2-MiB pages : 32 entries, 4-way associative;
- UTLB1 for 4-KiB pages: 512 entries for both data and instruction look-ups.
An DTLB0 miss and UTLB1 hit causes a penalty of 7 cycles. Software only pays this penalty if the DTLB0 is used in some dispatch cases. The delays associated with a miss to the TLB1 and Page-Miss Handler are largely non-blocking.
Intel Turbo Boost Technology
"Turbo Boost Technology" dynamically turns off unused processor cores and increases the clock speed of the cores in use. It will increase the frequency in steps of 133 MHz (to a maximum of three steps or 400 MHz) as long as the processors' predetermined thermal and electrical requirements are still met. For example, with three cores active, a 2.26 GHz processor can run the cores at 2.4 GHz. With only one or two cores active, the same processor can run those cores at 2.53 GHz. Similarly, a 2.93 GHz processor can run at 3.06 GHz or even 3.33 GHz. When the cores are needed again, they are dynamically turned back on and the processor frequency is adjusted accordingly. This feature can be enabled or disabled in the UEFI BIOS of each node.
EOS Node Architecture
Each of the 314 dx360-M2 compute nodes and the 6 x3650-M2 login nodes are Shared-memory Multi-Processors (SMP). The underlying architecture for both dx360-M2 and x3650-M2 is the "Nehalem EP", discussed previously. Fig. 18 shows a dx360-M2 node without the cover. It basically consists of two quad-core Nehalem chips, DDR3 DRAM memory and I/O capability. All basic parts of the nodes use Intel's QPI which supports substantial point-to-point bandwidth and low latencies.
dx360 M2 SMP Nodes Architecture

Fig. 18 An Internal View of a Typical dx360-M2 EOS Compute Node.
In Nehalem EP, two Nehalem chips connect together to form a 8-Way SMP by a Quick-Path Interconnect (QPI) link. See Fig. 19 for the architecture of iDataPlex nodes. QPI is a recent , high-speed, point-to-point interconnection technology designed for intra and inter-chip level communication. Since memory DIMMs are partitioned by Nehalem socket, the system is a cache-coherent non-uniform memory access (cc-NUMA) system.

Fig. 19 An 8-way dx360 M2 node with 2 quad-core Nehalem chips.
High-Performance Switch Cluster Interconnect
The powerful Nehalem dx360-M2 nodes form high-performance cluster with an equally high-performance InfiniBand interconnect fabric. At TAMU, all 324 nodes of the EOS connect together through a Voltaire's Grid Director GD4700 (see Fig. 20) IB switch.
Fig. 19 An overview of the EOS iDataPlex Cluster at Texas A&M University
HCA the Host Adapter to IB Fabric
Each dx360-m2 node connects to the IB fabric through a host-side switch adapter, called the Host-Channel Adapter (HCA). The HCAs are using the ConnectX�-2 Single or Dual-Port Adapter Silicon from Mellanox. Each HCA has one (and for some nodes two) full-duplex IB transmission link and connects to a port on the GD4700. On the dx360-M2 side, each HCA attaches directly to the 16-lane PCI-express gen2 channel. A 16-lane PCIe-gen2 is a full-duplex I/O bus with 2 data bytes per direction, and it is capable of delivering 8GB/s per direction. Since this PCIe port is on the Intel 5520 I/O Hub chip (IOH) it is one hop away to each one of the two Nehalem chips though a QPI link. In this configuration the PCIe_gen2-QPI-Nehalem path supports very low latency for short IB messages and full bandwidth for the IB links.
Intel's 5520 IOH chip supports fully all the RDMA features of the IB HCA and facilitates efficient access to node's main memory. HCAs are based on communications processors which support several main-processor off-load capabilities to facilitate high-speed, low-latency, concurrent access to local and remote memories. One of the interesting design feature of IB is that it can directly map into user (application memory) for direct access. This avoids expensive user to system memory intermediate data copies whenever possible and user to kernel code switching.
Voltaire's Grid Director GD4700 IB Switch
The GD4700 is a 4x Quadruple-Data Rate (QDR) "non-blocking" InfiniBand switch. At TAMU the GD4700 currently is half-way populated with 324 4x QDR ports connected to cluster nodes. This switch has a modular architecture and it has been configured with the internal fabric infrastructure to be expandable to up to 648 4x QDR ports. Fig. 21 illustrates the major functional components and the internal connectivity of this switch.
Fig. 21 The Voltaire's Grid-Director GD4700 4x QDR IB switch providing Full-Bisection bandwidth to all 324 attached hots for the EOS Cluster at Texas A&M University
The GD4700 is built around 4-th Generation Mellanox InfiniScale IV ASIC. InfiniScale IV is a 36X36, non-blocking switching element which can sustain the full bi-section bandwidth over all 36 bi-directional ports at QDR speeds, namely at 40Gb/sec per port per direction for a total of 2.88 Tib/s switching capacity. This ASIC implements a packet switching and scheduling engine for Congestion control and Quality of Service enforcement. It also supports adaptive routing in addition to the static routing capability commonly available. Now InfiniBand supports moving traffic via multiple parallel paths. Adaptive routing dynamically and automatically re-routes traffic to alleviate congested ports. However, in networks where traffic patterns are more predictable, static routing has been shown to produce superior results. The InfiniScale IV can use both static and adaptive routing.
In cases where resource contention is unavoidable, as for instance when multiple sources are trying to reach a single destination, Congestion control, using InfiniBand 1.2 standard mechanisms, is used to alleviate the hot-spot problem. The InfiniScale IV ASIC works in conjunction with ConnectX HCAs to restrict process traffic causing congestion, ensuring high-bandwidth and low-latency to all other flows. For converged traffic, the combination of high-bandwidth, adaptive routing, and congestion control provide a balanced traffic carrying capacity. End-to-end Quality of Service makes sure that traffic classes can be protected, guaranteeing the delivery of critical traffic.
Referring to Fig. 21, the Voltaire GD4700
- is a fully Non-Blocking Architecture based on a CLOS 3-stage multi-stage interconnection network;
- port-to-port small message latency is ~100 nano-seconds per SE hop, that is
- 100 nano-seconds when the two ports are on the same "line-card", or
- 300 nanoseconds maximum port-to-port (3 SEs are traversed).
As can be seen in Fig. 21, the GD4700 is not a "monolithic" switch but a 2 level "Fat-Tree", or "Folded-Closs" network. This fabric has constant and full bisection bandwidth. In practical terms this means that any N/2 disjoint pairs of communicating hosts can send and receive data at the line rate (nominally at 4GB/s), simultaneously, without creating any congestion or blocking anywhere in the entire fabric.
However, a common misconception is that FBB allows non-blocking and un-congested communication at full BW for all possible communicating pairs or groups. The keyword is "disjoint" which implies that each destination has exactly one source. When several sources are trying to reach the same destination, as for instance when there is an MPI Gather operation, it is common sense that the slowest part will be the bottleneck and it will determine the rate at which the communication will be carried out. In our case here the slowest part will be the links behind which packets from the various sources queue up to reach the common destination.
Routes and Routing Cost in IB Fabric
Referring to Fig. 22, there is only one possible minimum-hop route between any two hosts which are attached to the same IB line-card of the GD4770 switch. For example, packets traveling from A to host B, require traversing only one SE ASIC ("1 hop") with a nominal latency of ~100 nano-seconds.
On the other hand, when two hosts, say C and host Dminimum-hop routes for the communication. Each one of the possible routes has ~300 nano-second nominal latency. Once a pair of hosts establishes a communication path for a particular application the system will keep the same route until the application terminates.
Fig. 22 Possible routing cases with associated hop count and number of possible routes over infiniband fabric within the GD4700.
InfiniBand Communication Stack and MPI Code
Linux commodity clusters with IB fabric, employ a complex, yet standardized communications protocol stack. One of the big advantages of IB is that it supports direct access to IB communication h/w by user applications, bypassing the system kernel. This applies to data transfers and control logic.
InfiniBand Protocol Stack
User-Level Protocols Initially the application contacts the kernel to establish the necessary system data structures for the inter-process communication. When this registration step is completed, the application can directly request the IB h/w to transfer data with only a minimal kernel intervention. When actual data transfer takes place, the IB stack avoids to copy it from user space to system space and vice-versa.
Hardware Off-loading Another advantage of IB is that communications logic which is normally implemented by system software, is off-loaded to IB HCA hardware. A common technique used is called Remote-Direct Memory Access (RDMA). RDMA allows the actual transfer of data from system memory to I/O adapters (HCAs) without executing any code in the processor. The application via IB libraries, submits the parameters of the data transfer and it launches the I/O. The actual byte transfer takes place under the control of hardware or firmware. Application or system code is minimally involved.
Advantages of IB Communication Stacks The above dual performance boost allows MPI or other communicating code to achieve the lowest latencies for small messages and high transfer rates, close to "wire-speed", for larger messages, All these advantages along with the supported high-speed h/w communication bandwidths have made IB the preferred communications infrastructure for high-performance computing centers. Note that currently IB links support Quad-Data Rates ("QDR") but soon are slated to get an increase to Octo-Data Rates by the IB community. This will support up to 8GB/s per direction per IB link and double this later in the future.
The IB communications stack is a multi-layer communications s/w which is illustrated in Fig. 23. As with any complex collection of h/w and s/w protocols, discussion of the stack can take place by explaining the functions of each one of the layers. MPI applications can directly use the hardware capabilities of the high-speed IB HCAs and the IB switch by invoking APIs at the upper layer of this stack.

Fig. 23 The IB/MPI software protocol stack for EOS.
At TAMU the InfiniBand fabric h/w uses the OFED V1.4.2 IB s/w stack to provide the lower level messaging capabilities to applications as well as to provide the IB management functions, such as IB initialization, route determination, node state change updates and so on. OFED is an implementation of the standard IB protocol stack which is made possible with the contributions by research labs in academia and by commercial vendors.
The OFED provides the "lower level" IB transport layer to "application" layers such as MPI. At TAMU, the primary MPI stacks are those by Intel and the OpenMPI project. In the near future other MPI stacks, including the MVAPICH2 will be deployed.
MPI Software Stack
The Message-Passing Interface (MPI) is the predominant Message Passing Programming (MPP) API for distributed memory multi-processor systems. MPI has evolved into a very mature, widely used and highly efficient MPP layer. MPI can leverage efficiently the low-latency and high-bandwidth performance of the underlying IB transport. On-going research and development effort has been continuously improving MPI's performance as perceived by the application.
On EOS, three of the most prevalent MPI implementations have been installed and are ready to be used to develop and run high-performance message passing code. Namely,
- Intel MPI versions 4 (4.0.3.8, 4.0.0.028 default, 4.0.0.025, 4.0.0.027) and 3 (3.2.2.006). Unless you have a specific reason not to, please use v4.0.0.028.
- Open MPI version 1.4.3,
- MVAPICH2 version 1.8 (and also 1.5, 1.6 and 1.7) and
- mpich2 version 1.3.1 which is not supported at the moment.
Each MPI stack has advantages in certain areas (such as, performance or programmability). Unfortunately, the environment to build, troubleshoot, tune up, and execute code varies among these stacks. In general, when we build code under MPI stack X, we should run it under the run-time environment of the same stack X.
In our performance evaluations for the MPI stacks, MVAPICH2 and Intel MPI stacks rank at the top (lowest latencies, highest bandwidths). However, OpenMPI is the best when it comes to programmability and available options controlling rank to node mapping and task / thread to core mapping and binding. When building your own MPI code, consider the stack which may provide you highest benefit for the type of application at hand. If you care most about performance consider IntelMPI or MVAPICH2. If having better control in how the ranks will map to nodes and cores is more important to you, then use OpenMPI.Note that all stacks are actively evolving and in the future the pros and cons of each stack could change.
One word of advise is that you will have to understand how each one of the MPI stacks binds by default the threads in multi-threaded (i.e., "hybrid") MPI code to cores at run-time. Multi-threaded MPI code is used when, for instance, each MPI task is also an OpemMP program or when it involves multi-threaded MKL library routines to solve a numerical problem. IntelMPI usually does "the right thing" when it binds OMP/MKL threads to cores in a hybrid MPI program. Specifically, it binds each OMP/MKL thread to a different core without over-subscribing the cores.
However, non-Intel MPI libraries used with OMP or Intel MKL threads, may bind at run-time, for each MPI task running on a node all threads numi to the same core in that node. This will result it a slowdown vs. a speedup as we increase the number of OMP/MKL threads per MPI task. As each MPI stack uses different syntax and options to specify and different mechanisms to implement task and thread to node and core mapping and binding the matter quickly becomes unwieldy when the behavior of one stack has to be replicated with another.
DDN S2A9900 Cluster Storage and GPFS File Systems
EOS is directly attached to 120 Tera-byte (un-formatted capacity) disk space on a top of the line Data-Direct Network's DDN S2A 9900 RAID array (see Fig. 20). The connection to the DDN RAID is through eight 2-GByte/sec 4x DDR IB links, with two IB links hosted by each of four I/O x3650-M2 server nodes. On the RAID side (see Fig. 24), each logical disk (LUN) is protected with two parity disks for increased recovery capabilities, in a configuration referred to as "RAID 6". The error-check and correction capability is beyond the standard N+1 RAID configuration (RAID 5).
Fig. 24 Details of the 120 Tera-Byte DDN S2A9900 RAID array.
With DDN storage, disks are arranged into logical groups of 10 disks each, called "tiers". For maximum performance the tiers are split equally for ownership across the two 9900 array controllers (called "singlets"). In our case, each tier consists of 4 Tera Bytes of data and 1 Tera Byte of Parity information in 8 plus 2 disks, respectively. This is illustrated in Fig. 24. Each singlet attaches with 4 3 Gb/s SAS channels to all the disks in the back-end. The maximum raw I/O bandwidth for the 2 S2A 9900 Singlets operating together is close to 6 GBytes/sec. The I/O bandwidth observed at the parallel file system level is above 5 GBytes/sec and it depends on the application access patterns.
The EOS cluster deploys the latest version of GPFS which is IBM's high-performing, highly-scalable clustered file system. Currently, /g/home and /g/software are hosted on one GPFS file system. /scratch is hosted on another GPFS file system. The different file systems on EOS are configured with respect to different performance objectives. /scratch consists of twenty 4 Tera-byte LUNs, whereas, /g/home and /g/software are hosted on four 4 Tera-byte LUNs for a total of 80 and 16 TeraBytes, respectively. This is illustrated in Fig. 24.
Fig. 25 Details of the 120 Tera-Byte DDN S2A9900 RAID array.
Each one of the four I/O servers is responsible for 1/4th of the total DDNS2A9900 LUNs. The paths from each GPFS client (compute or login) node to each one of th LUNs is perfectly balanced.
References
Published Literature and Presentations for Intel Nehalem Micro-Processor
- Patrick P. Gelsinger, "Intel Architecture Press Briefing," Intel Developer Forum, 17 March, 2008.
- Steve Gunther and Ronak Singhal, "Next Generation Intel� Microarchitecture (Nehalem) Family: Architectural Insights and Power Management", Intel Developer Forum, San Francisco, 2008.
- Ronak Singhal, "Inside Intel Next Generation Nehalem Microarchitecture, " Intel Developer Forum, April 1, 2008.
- Eric Delano, "Intel� Itanium� Processor (Tukwila): Quad-Core IA-64 Architecture for the Enterprise," Intel Developer Forum, San Francisco, 2008.
- Antonio Valles, Pallavi Mehrotra and Zia Ansari, "Tuning Your Software for the Next Generation Intel� Microarchitecture (Nehalem) Family", Intel Developer Forum, San Francisco, 2008.
- Stephen Thomas, "High End Desktop Platform Design Overview for the Next Generation Intel� Microarchitecture (Nehalem) Processor", Intel Developer Forum, San Francisco, 2008.
- Tom Trill and Carlos Weissenberg, "DDR3 Moving to Mainstream," Intel Developer Forum, San Francisco, 2008.
- Eric Moore and Claire Cates, "Threads : The Good, Bad, and Ugly: Improving Parallel Application Performance and Quality," Intel Developer Forum, San Francisco, 2008.
- Bob Maddox, "Overview of the Intel� QuickPath Interconnect," Intel Developer Forum, San Francisco, 2008.
- Robert Safranek, Gurbir Singh and Robert Maddox, "Intel� QuickPath Interconnect Overview," HotChips 21 − IEEE Symposium on High Performance Chips, Stanford University, Palo-Alto, CA, Aug. 2009.
- "An Introduction to the Intel� QuickPath Interconnect," Intel Corporation Whitepaper, January 2009.
- Ofri Wechsler, "Inside Intel Core Micro-Architecture," Intel Corporation Whitepaper, January 2006.
- B. Stackhouse, et al., "A 65nm 2-Billion-Transistor Quad-Core Itanium Processor," ISSCC Digest of Technical Papers, pp. 92--93, February 2008.
- Intel Xeon Processor 5500 Series Product Brief, "Intel� Xeon� Processor 5500 Series An Intelligent Approach to IT Challenges," Intel Corporation Whitepaper, March 2009.
- Intel Xeon Processor 5500 Series Product Brief, "Intel� 64 Architecture Processor Topology Enumeration," Intel Corporation Whitepaper, June 2008.
- Intel Corporation, Intel� 5520 Chipset and Intel� 5500 Chipset Datasheet, Intel Corporation Document, March 2009.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 1:Basic Architecture , Intel Corporation Document, June 2010.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 2A: Instruction Set Reference, A-M , Intel Corporation Document, June 2010.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 2B: Instruction Set Reference, N-Z , Intel Corporation Document, June 2010.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 3A: System Programming Guide, Part 1, Intel Corporation Document, June 2010.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 3B: System Programming Guide, Part 2, Intel Corporation Document, June 2010.
- Intel Corporation, "Intel� Turbo Boost Technology in Intel� Core(TM) Microarchitecture (Nehalem) Based Processors ," Intel Corporation Whitepaper, November 2008.
- M. Papamarcos and J. Patel, "A Low-Overhead Coherence Solution for Multiprocessors with Private Cache Memories," in Proc. 11th ISCA, pp. 348--354, 1984.
Fig. 1 A photograph of EOS iDataPlex Cluster at Texas A&M University while it was being installed
Abbreviation Key
We will be using different quantities to measure capacities and speeds. To avoid confusion we will be using the following notation.
Table 1 Abbreviations of Quantities
| Powers of 2 | Powers of 10 |
|---|---|
| KiB := 210 ("Kilo-binary-Byte") | KB := 103 ("Kilo-Byte") |
| MiB := 220 ("Mega-binary-Byte") | MB := 106 ("Mega-Byte") |
| GiB := 230 ("Giga-binary-Byte") | GB := 109 ("Giga-Byte") |
| TiB := 240 ("Tera-binary-Byte") | TB := 1012 ("Tera-Byte") |
| PiB := 250 ("Peta-binary-Byte") | PB := 1015 ("Peta-Byte") |
Usually, rates, such as data transfer or floating point operations per second, are expressed in powers of 10, while storage sizes in powers of 2. See this reference for a discussion on international units.
Introduction to the EOS Cluster
This article is an in-depth technical discussion of EOS's cluster and underlying h/w and s/w technologies. Most of these technologies came out of research labs in the 2007−2009 time-frame. They render EOS one of the top high-performance platforms in the 2010 time-frame. The EOS cluster has overall a more balanced design, where no resource becomes a significant bottleneck. This is a departure from conventional x86 clusters where the bandwidth of the interconnect or of the memory are limiting factors. EOS like other state-of-the-art clusters, is a collection of complex subsystems all amenable to tuning and different configuration options. Intimate knowledge of the underlying mechanisms and their inter-dependence is a pre-requisite for putting together a cluster which is tuned and configured to perform efficiently in a demanding research and production environment. The current job mix demands access to all resources of the cluster simultaneously. We have taken into careful consideration the resource demands of the job mixes and we have configured and tuned the cluster and its subsystems so the entire system can operate as efficiently as possible. Developers of scalar or parallel applications should also have a more intimate knowledge of the underlying technologies in order to be able to make the best use of all the available resources and tools.
The discussion presented here relies on information from a large number of different sources, all scattered in many places. We hope that a coherent presentation of the constituent technologies and their interaction will save the considerable amount of effort necessary to bring all important aspects into a single place.
This article is dedicated to all those interested in producing code that runs quite well on high-performance clusters based on the Intel64 architecture. It should also be a great reference to all those who study computer architecture and parallel technologies in order to improve them or just to learn important aspects of them.
Quick Overview of EOS Cluster Configuration
Fig. 2 below presents a pictorial illustration of the main EOS cluster components. We will use it to explain at a high level how users can access the cluster.Fig. 2 A graphical overview of the important EOS infrastructure components at Texas A&M University.
Of the 324 iDataPlex EOS's nodes, 314 are designated as Compute Nodes (CNs) while five and four nodes are set aside to provide interactive logins (LNs) and storage I/O service (SNs), respectively. The Login and I/O nodes are IBM "x3650-M2" model and the Compute Nodes are "dx360-M2". Both models are very similar in internal capabilities and architecture and they differ in packaging and I/O capabilities.
Each EOS iDataPlex node is an 8-way, native 64-bit Shared-memory Multi-Processor, consisting of two quad-core Nehalem chips and 24GiB1 of DDR3 DRAM. The Nehalem chips are designated as "XEON X5560" and run at a frequency of 2.8GHz. The two processor Nehalem chips communicate together with Intel's "QuickPath" Interconnect (QPI). QPI is a rather significant technological innovation Intel introduced with systems based on the Nehalem processor. QPI is a full-duplex point-to-point communication link which in the case of EOS can exchange data in both directions with a bandwidth of 12.8GB/sec per direction.
EOS users are expected to use the LNs to develop, compile, troubleshoot and optimize their applications. The CNs are made available through a batch scheduler to execute user code to generate results relevant to their work. In general, CNs will not be accessible to a user for interactive work.
All 324 nodes have access to high-performance distributed file systems via the QDR fabric. The file systems are provided by IBM's latest high-performance GPFS V3.3.0-4. The disk storage is provided by a DataDirect Networks S2A9900 high-performance RAID array, with a raw capacity of 120 Tera-Bytes.
All cluster nodes run a recent 64-bit version of the RedHat or the CentOS Linux operating systems. OFED V1.4.2 is the IB software communication stack for the entire cluster. The cluster employs the latest GPFS V3.3.0-4 for parallel file system.
The normal mode of problem-solving on EOS is running distributed or shared-memory (OMP) computations under the control of a batch scheduler.
Quick Overview of Technologies Incorporated into EOS Cluster
Even though it is a commodity cluster, EOS combines a number of cutting-edge technologies most suitable for a high-performance production and research environment. These technologies include the Nehalem micro-processor, DDR3 main memory (DRAM), Intel's Quick-Path Interconnect (QPI), a 4x Quadruple-Data-Rate Infiniband fabric, a high-end disk subsystem, high performance distributed file system and a comprehensive program development and execution environment supporting the "Intel64" architecture specification.
Nehalem Architecture Nehalem implements a modern multi-core technology, representing the state-of-the art in commodity, complex instruction set computer (CISC) micro-architectures. This platform relies on Intel's 45nm, high-k, metal gate silicon technology. Each processor chip has its own dedicated memory that it accesses directly through an on-chip Integrated Memory Controller.
Nehalem SIMD Processing Nehalem directly supports SIMD computation where the same operation can be applied simultaneously on multiple data operands. Applications which rely on vector type of floating-point or integer arithmetic can greatly benefit from the SIMD infrastructure in Nehalem. Nehalem can produce up to 4 double-precision simple arithmetic results per clock cycle.
Simultaneous Multi-Threading (Hyper-Threading) Technology Simultaneous Multi-Threading (SMT) allows up to 2 threads to execute within each processor core, up to eight threads per quad-core chip or 16 SMT threads per Nehalem-EP node. SMT reduces computational latency, by maximizing the utilization of the idle core functional units, thus increasing the machine instruction throughput per clock cycle. Applications with matching resource needs can be accommodated without impacting each other negatively.
QuickPath Technology Intel QuickPath Interconnect (QPI) is a platform architecture that provides high-speed (currently up to 25.6 GB/s), point-to-point connections between processor chips, and between processors and the I/O hub (IOH). A processor may access the dedicated memory of another processor, through a QPI link.
Nehalem-EP Architecture The Nehalem EP architecture supports 8-way parallel processing, enabled by two processor chips connected together by Intel QuickPath interconnect. Nehalem EP is a cc-NUMA platform where the the QPI is the coherent transport link between the two processors. Processor sockets connect to the I/O system section, each by a separate QPI link, enabling sustained high I/O throughput.
Quad-Data Rate 4x Infiniband IB is a high-speed interconnect technology which supports low-latency and high-bandwidth connection of N end-points. At TAMU, the IB fabric is configures to support NXN communication at "full-bisection bandwidth" where all N/2 disjoint communicating pairs can simultaneously send and receive message at the nominal speed of 4GB/s per direction.
High-Speed Back-End RAID Storage TAMU has configured a DDN S2A9900 RAID storage array for the GPFS file systems of the cluster. The raw disk capacity is 120 TeraBytes, which offers a 96 TeraBytes formatted capacity for GPFS.
High-Speed Parallel File System EOS cluster provides high-speed access to a high-performance parallel file system from IBM called GPFS. GPFS is a solid parallel file system designed and proven to support high-bandwidth parallel access of applications to a common file store.
Comprehensive Program Development Environment, Libraries and Tuning Tools EOS supports a comprehensive development environment for scalar, SMP, distributed and hybrid applications. These include the latest compilers, tools and libraries available from Intel or other sources to support high-performance user applications.
In subsequent Sections we analyze technical details of these technologies and we discuss how they can affect the performance of user code.
The Nehalem Processor and "Intel� 64" Architecture
"Nehalem" is the nickname for the "Intel� Microarchitecture", where the latter is a specific implementation of the "Intel64" Instruction Set Architecture (ISA) specification. For this report, "Nehalem" refers to the particular implementation where a processor chip contains four cores, the fabrication process is 45nm with high-k + metal gate transistor technology. We further focus on platforms with two processor sockets per system (node) and where the interconnection between sockets themselves and between processors and I/O is through Intel's Quick-Path Interconnect. Nehalem is the foundation of Intel Core i7 and Xeon processor 5500 series. EOS nodes use the "Xeon 5560" processor chips. Even though "Intel64" is a classic Complex-Instruction Set Computer ("CISC") type, its "Intel Micro-architecture" implementation shares many mechanisms in common with modern Reduced-Instruction Set Computer ("RISC") implementations.
The "Intel� 64" Architecture
The 64-bit "Intel64" ISA, historically derives from the 64-bit extensions AMD applied on Intel's popular 32-bit IA-32 ISA for its "K8" processor family. Later on AMD used the name "AMD64" and Intel the names "IE-32e" and "EM64T". Finally, Intel settled on "Intel64" as their "official" 64-bit ISA deriving from the IA-32. The Intel64 architecture supports IA-32 ISA and extends it to fully support natively 64-bit OS and 64-bit applications. The physical address space in the "Intel64" platform can reach up to 48 bits which implies that 256 Tera-binary-Bytes (TiB) can by directly addressed by the hardware. The logical address size of "Intel64" is 64-bit which supports a 64-bit flat linear address space. However, currently the hardware effectively uses only the last 48-bits.
Fig. 3 presents the logical (or "architected") view of the Intel64 ISA. The architected view of an ISA is the collection of objects which are visible at the machine language code level and can be directly manipulated by machine instructions.
Fig. 3 "Intel64" : 64-bit Mode Execution Environment on Nehalem processor.
In the 64-bit mode of Intel64 architecture, software may access
- a 64-bit flat linear logical address space
- 64-bit-wide General Purpose Registers (GPRs) and instruction pointers
- 16 64-bit GPRs
- 16 128-bit "XMM" registers for streaming SIMD extensions (SSE, SSE2, SSE3 and SSSE3, SSE4), in addition to 8 64-bit XMM registers or the 8 80-bit x87 registers, supporting floating-point or integer operations
- uniform byte-register addressing
- fast interrupt-prioritization mechanism
- a new instruction-pointer relative-addressing mode.
64-bit applications can use a set of prefixes to access the new registers or 64-bit register operands, and 64-bit address pointers. Intel compilers can produce code which takes full advantage of all the features in Intel64 ISA. Application optimization guidelines will be published on a separate write up.
Non 64-bit Code Intel64 architecture provides a new operating mode, referred to as IA-32e mode, which consists of two sub-modes: (1) compatibility mode which enables a 64-bit operating system to run most legacy 32-bit software unmodified, and (2) 64-bit mode which enables a 64-bit operating system to run applications written to access 64-bit linear address space. On EOS, all nodes operate at the full 64-bit mode. 32-bit applications can run, likely unchanged, but there is no good reason to produce or run 32-bit code on a native 64-bit platform. This report focuses exclusively on the full 64-bit "Intel64" ISA and will not discuss other modes of execution.
Nehalem Processor
Nehalem builds upon and expands the new features introduced by the previous micro-architecture, namely the 45nm "Enhanced Intel Core Micro-architecture" or "Core-2" for short.
Features in the Intel Core Micro-Architecture
The "Core-2" micro-architecture introduced a number of interesting features, including the following
- "Wide Dynamic Execution" which enabled each processor core to fetch, dispatch, execute and retire up to four instructions per clock cycle. This architecture had
- 14-stage core pipeline
- 4 decoders to decode up to 5 instructions per cycle
- 3 clusters of arithmetic logical units
- macro-fusion and micro-fusion to improve front-end throughput
- peak dispatching rate of up to 6 micro-ops per cycle
- peak retirement rate of up to 4 micro-ops per cycle
- advanced branch prediction algorithms
- stack pointer tracker to improve efficiency of procedure entries and exits
- "Advanced Smart Cache" which improved bandwidth from the second level cache to the core, and improved support for single- and multi-threaded applications computation
- 2-nd level cache up to 4 MB with 16-way associativity
- 256 bit internal data path from L2 to L1 data caches
- "Smart Memory Access" which pre-fetches data from memory responding to data access patterns, reducing cache-miss exposure of out-of-order execution
- hardware pre-fetchers to reduce effective latency of 2nd level cache misses
- hardware pre-fetchers to reduce effective latency of 1st level data cache misses
- "memory disambiguation" to improve efficiency of speculative instruction execution
- "Advanced Digital Media Boost" for improved execution efficiency of most 128-bit SIMD instruction with single-cycle throughput and floating-point operations
- single-cycle inter-completion latency ("throughput") of most 128-bit SIMD instructions
- up to eight SP floating-point operation per cycle
- 3 issue ports available to dispatching SIMD instructions for execution
New Features in the Intel Micro-Architecture
"Intel Micro-architecture" (Nehalem) provides a number of distinct feature enhancements over those of "Enhanced Intel Core Micro-architecture", shown above, including:
- Enhanced processor core:
- improved branch prediction and recovery cost from mis-prediction;
- enhanced loop streaming to improve front-end performance and reduce power consumption;
- deeper buffering in out-of-order engine to extract parallelism;
- enhanced execution units with accelerated processing of CRC, string/text and data shuffling.
- Hyper-threading technology (SMT):
- support for two hardware threads (logical processors) per core;
- a 4-wide execution engine, larger L3, and large memory bandwidth.
- "Smarter" Memory Access:
- integrated (on-chip) memory controller supporting low-latency access to local system memory and overall scalable memory bandwidth; previously the memory controller was hosted on a separate chip and it was common to all dual or quad socket systems;
- new cache hierarchy organization with shared, inclusive L3 to reduce snoop traffic
- two level TLBs and increased TLB sizes;
- fast unaligned memory access.
- Dedicated Power management:
- integrated micro-controller with embedded firmware which manages power consumption;
- embedded real-time sensors for temperature, current, and power;
- integrated power gate to turn off/on per-core power consumption;
- Versatility to reduce power consumption of memory and QPI link subsystems.
The Nehalem Processor Chip
A Nehalem processor chip is a "Chip-Multi Processor" (CMP), consisting of several functional parts within a single silicon die. Fig. 4 illustrates a Nehalem CMP chip and its major parts.
Fig. 4 (a) A Nehalem Processor and Memory module. The processor chip contains four cores, a shared L3 cache and DRAM controllers, and Quickpath Interconnect ports.
Fig. 4 (b) A Nehalem Processor Chip micro-photograph.
Referring to Fig. 4, a Nehalem chip consists of the following components
- four identical compute cores,
- CIU: Cache Interface Unit (switch connecting the 4 cores to the 4 L3 cache segments),
- L3: level-3 cache controller and data block memory,
- IMC: 1 integrated memory controller with 3 DDR3 memory channels,
- QPI: 2 Quick Path Interconnect ports, and
- auxiliary circuitry for cache-coherence, power control, system management and performance monitoring logic.
A Nehalem chip is divided into two broad domains, namely, the core and the un-core. Components in the "core domain" operate with the same clock frequency as that of the actual computation core. In EOS's case this is 2.8GHz. The "un-core" domain operates under a different clock frequency. This modular organization reflects one of Nehalem's objectives of being able to consistently implement chips with different levels of computation abilities and power consumption profiles. For instance, a Nehalem chip may have from two to eight cores, one or more high-speed QPI interconnects, different sizes for L3 caches, as well as, memory sub-systems with different DRAM bandwidths. Similar partitioning of CMP chip into different clock domains can be found in other processors, such as, in IBM's Power5, 6 and 7, in AMDs multi-core chips and serves very similar purposes.
Outside the Nehalem chip, but at close physical proximity, we find the DRAM which is accessible by means of three 8-byte DDR3 channels, each capable to operate at up to 1.333 GHz. The aggregate nominal main memory bandwidth is 31.992 GB/s per chip, or 7.998 GB/s per core. This is a significant improvement over all previous Intel micro-architectures. The maximum operating frequency of the DDR3 buses is determined by the number of DIMMs in the slots.
In essence the "un-core" domain contains the memory controller and cache coherence logic which in earlier Intel architectures used to be implemented by the separate "North-bridge" chip.
The high performance of the Nehalem architecture relies, among other things, on the fact that the DRAM controller, the L3 and the QPI ports are all housed within the same silicon die as the four cores. This saves a significant amount of off-chip communications and makes possible a tightly coupled, low-latency, high bandwidth CMP system. This particular processor to memory implementation is a significant departure from all previous ones by Intel. Prior to Nehalem, the memory controller was housed on a separate "Northbridge" chip and it was shared by all processor chips. The Northbridge has been one of the often cited bottlenecks in previous Intel architectures. Nehalem has substantially increased the main memory bandwidth and shortened the latency to access main memory. However, now that a separate DRAM is associated with every IMC and chip, platforms with more than one chips are Non-Uniform Memory Access ("NUMA"). NUMA organizations have distinct performance advantages and disadvantages and with proper care multi-threaded computation can make efficient use of the available memory bandwidth. In general data and thread placement becomes an important part of the application design and tuning process.
Nehalem Core Instruction Pipeline
Instruction and Data Flow in Modern Processors
Nehalem implements a number of techniques to process efficiently the stream of Intel64 ISA CISC "macro-instructions" in the user code. A core internally consists of a large number of functional units (FUs) each capable of carrying out an elementary "micro-operation" (micro-op). An example of a FU is an ALU (arithmetic and logic unit) which can carry out an operation against input operands. Micro-ops would specify the operation type and its operands. Micro-ops are RISC-like type of instructions and they require similar effort and resources to process.
Micro-operations having no dependencies on the results of each other could proceed in parallel if separate FUs are available. The CISC type of Intel64 macro-instructions are translated by the early stages of the core into one or more micro-ops. The micro-operations eventually reach the execution FUs where they are dispatched to FUs and "retire", that is, have their results saved back to visible ("architected") state (i.e., data registers or memory). When all micro-ops of a macro-instruction retire, the macro-instruction itself retires. It is clear that the basic objective of the processor is to maximize the macro-instruction retirement rate.
The fundamental approach Nehalem (and other modern processors) take to maximize instruction completion rates is to allow the micro-ops of as many instructions as feasible, proceed in parallel with micro-op occupying independent FUs at each clock cycle. We can summarize the Intel64 instruction flow through the core as follows.
- The early stages of the processor fetch-in several macro-instructions at a time (say in a cache block) and
- decode them (break them down) into sequences of micro-ops.
- The micro-ops are buffered at various places where they can be
- picked up and scheduled to use the FUs in parallel if data dependencies are not violated. In Nehalem, micro-ops are issued to stations were they reserve their position for subsequent
- dispatching as soon as their input operands become available.
- Finally, completed micro-ops retire and post their results to permanent storage.
The entire process proceeds in stages, in a "pipelined" fashion. Pipelining is used to break down a lengthy task into sub-tasks where intermediate results flow downstream the pipeline stages. In microprocessors, sub-tasks handled within each stage take one clock cycle. The amount of hardware logic which goes into each stage has been carefully selected so that there is approximately an equal amount of work which takes place in every stage. Since adding a pipeline stage includes some additional fixed overhead for buffering intermediate results, pipeline designs carefully balance the total number of stages and the duration per stage.
Complex FUs are usually themselves pipelined. A floating-point ALU may require several clock cycles to produce the results of complex FP operations, such as, FP division or square root. The advantage of pipelining here is that with proper intermediate result buffering, we could supply a new set of input operands to the pipelined FU in each clock cycle and then correspondingly expect a new result to be produced at each clock cycle at the output of the FU.
A pipeline bubble takes place when the input operands of a downstream stage are not available. Bubbles flow downstream at each clock cycle. When the entire pipeline has no input to work with it can stall, that is, it can suspend operation completely. Bubbles and stalls are detrimental to the efficiency of pipelined execution if they take place with a "high" frequency. Common reasons for a bubble is when say data has to be retrieved from slower memory or from a FU which takes multiple cycles to produce them. Compilers and processor designers invest heavily in minimizing the occurrence and the impact of stalls. A common way to alleviate the frequency of stalls is to allow micro-ops proceed out of chronological order and use any available FUs. Dynamic instruction scheduling logic in the processor determines which micro-ops can proceed in parallel while the program execution remains semantically correct. Dynamic scheduling utilizes the "Instruction Level Parallelism" (ILP) which is possible within the instruction stream of a program. Another mechanism to avoid pipeline stalling is called speculative execution. A processor may speculatively start fetching and executing instructions from a code path before the outcome of a conditional branch is determined. Branch prediction is commonly used to "predict" the outcome and the target of a branch instruction. However, when the path is determined not to be the correct one, the processor has to cancel all intermediate results and start fetching instructions from the right path. Another mechanism relies on data pre-fetching when it is determined that the code is retrieving data with a certain pattern. There are many other mechanisms which are however beyond the scope of this report to describe.
Nehalem, as other modern processors, invests heavily into pre-fetching as many instructions, from a predicted path and translating them into micro-ops, as possible. A dynamic scheduler then attempts to maximize the number of concurrent micro-ops which can be in progress ("in-flight") at a time, thus increasing the completion instruction rates. Another interesting feature of Intel64 is the direct support for SIMD instructions which increase the effective ALU throughput for FP or integer operations.
Instruction and Data Flow in Nehalem Cores
Nehalem cores are modern micro-processors with in-order instruction issue, super-scalar, out-of-order execution data-paths, which are coupled with a multilevel storage hierarchy. Nehalem cores have extensive support for branch prediction, speculative instruction execution, data pre-fetching and multiple pipelined FUs. An interesting feature is the direct support for integer and floating point SIMD instructions by the hardware.
Nehalem's pipeline is designed to maximize the macro-instruction flow through the multiple FUs. It continues the four-wide micro-architecture pipeline pioneered by the 65nm "Intel Core Microarchitecture" ("Merom") and the 45nm "Enhanced Core Microarchitecture" ("Penryn"). Fig. 5 illustrates a functional level overview of a Nehalem instruction pipeline. The total length of the pipeline, measured by branch mis-prediction delay, is 16 cycles, which is two cycles longer than that of its predecessor.
Fig. 5 High-level diagram of a Nehalem core pipeline.
Referring to Fig. 5, the core consists of
- an in-order Front-End Pipeline (FEP) which retrieves Intel64 instructions from memory, uses four decoders to decode them into micro-ops and buffers them for the downstream stages;
- an out-of-order super-scalar Execution Engine (EE) that can dynamically schedule and dispatch up to six micro-ops per cycle to the execution units, as soon as source operands and resources are ready,
- an in-order Retirement Unit (RU) which ensures the results of execution of micro-ops are processed and the "architected" state is updated according to the original program order, and
- multi-level cache hierarchy and address translation resources.
Nehalem Core: Front-End Pipeline
Fig. 6 illustrates in more detail key components of Nehalem's Front-End Pipeline (FEP). The FEP is responsible for retrieving blocks of macro-instructions from memory and translating them into micro-ops and buffering them for handling at the execution back-end. FEP handles the code instructions "in-order". It can decode up to 4 macro-instructions in a single cycle. It is designed to support up to two hardware SMT threads by decoding the instruction streams of the two threads in alternate cycles. When SMT is not enabled, the FEP handles the instruction stream of only one thread.Fig. 6 High-level diagram of the In-Order Front-End Nehalem Pipeline (FEP).
The Instruction Fetch Unit (IFU) consists of the Instruction Translation Lookaside Buffer (ITLB), an instruction pre-fetcher, the L1 instruction cache and the pre-decode logic of the Instruction Queue (IQ). The IFU always fetches 16 bytes (128 bits) of aligned instruction bytes on each clock cycle from the Level 1 instruction cache into the Instruction Length Decoder. There is a 128-bit wide direct path from L1 to the IFU. The IFU always brings in 16 byte blocks.
The IFU uses the ITLB to locate the 16-byte block in the L1 instruction cache and instruction pre-fetch buffers. Instructions are referenced by virtual address and translated to physical address with the help of a 128 entry instruction translation look-aside buffer (ITLB). A hit in the instruction cache causes 16 bytes to be delivered to the instruction pre-decoder. Programs average slightly less than 4 bytes per instruction, and since most instructions can be decoded by all decoders, an entire fetch can often be consumed by the decoders in one cycle. Instruction fetches are always 16-byte aligned. A non-16 byte aligned target reduces the number of instruction bytes by the amount of offset into the 16 byte fetch quantity. A taken branch reduces the number of instruction bytes delivered to the decoders since the bytes after the taken branch are not decoded.
The Branch-Prediction Unit (BPU) allows the processor to begin fetching and processing instructions before the outcome of a branch instruction is determined. For microprocessors with lengthy pipelines successful branch prediction allows the processor to fetch and execute speculatively instructions over the "predicted" path without "stalling" the pipeline. When a prediction is not successful, Nehalem simply cancels all work already done by the micro-ops already in the pipeline on behalf of instructions along the wrong path. This may get costly in terms of resources and execution cycles already spent. Modern processors invest heavily in silicon estate and algorithms for the BPU in order to minimize the frequency and impact of wrong branch predictions.
On Nehalem the BPU makes predictions for the following types of branch instructions
- direct calls and jumps: targets are read as a target array, without regarding the taken or not-taken prediction,
- indirect calls and jumps: these may either be predicted as having a fixed behavior, or as having targets that vary according to recent program behavior,
- conditional branches: BPU predicts the branch target and whether the branch will be taken or not.
Nehalem improves branch handling in several ways. The Branch Target Buffer (BTB) has been increased in size to improve the accuracy of branch predictions. Furthermore, hardware enhancements improve the handling of branch mis-prediction by expediting resource reclamation so that the front-end would not be waiting to decode instructions in an "architected" code path (the path in which instructions will reach retirement) while resources were allocated to executing mispredicted code path. Instead, new micro-ops stream can start forward progress as soon as the front end decodes the instructions in the architected code path. The BPU includes the following mechanisms
- Return Stack Buffer (RSB) A 16-entry RSB enables the BPU to accurately predict RET instructions. Renaming is supported with return stack buffer to reduce mis-predictions of return instructions in the code.
- Front-End Queuing of BPU look-ups. The BPU makes branch predictions for 32 bytes at a time, twice the width of the IFU. Even though this enables taken branches to be predicted with no penalty, software should regard taken branches as consuming more resources than do not-taken branches.
Instruction Length Decoder (ILD or "Pre-Decoder") accepts 16 bytes from the L1 instruction cache or pre-fetch buffers and it prepares the Intel64 instructions found there for instruction decoding downstream. Specifically the ILD
- determines the length of the instructions,
- decodes all prefix modifiers associated with instructions and
- notes properties of the instructions for the decoders, as for example, the fact that an instruction is a branch.
The Instruction Queue (IQ) buffers the ILD-processed instructions and can deliver up to five instructions in one cycle to the downstream instruction decoder. The IQ can buffer up to 18 instructions.
The Instruction Decoding Unit (IDU) translates the pre-processed Intel64 macro-instructions into a stream of micro-operations. It can handle several instructions in parallel for expediency.
The IDU has a total of four decoding units. Three units can decode one simple instruction each, per cycle. The other decoder unit can decode one instruction every cycle, either a simple instruction or complex instruction, that is one which translates into several micro-ops. Instructions made up of more than four micro-ops are delivered from the micro-sequencer ROM (MSROM). All decoders support the common cases of single micro-op flows, including, micro-fusion, stack pointer tracking and macro-fusion. Thus, the three simple decoders are not limited to decoding single micro-op instructions. Up to four micro-ops can be delivered each cycle to the downstream instruction decoder queue (IDQ).
The IDU also parses the micro-op stream and applies a number of transformations to facilitate a more efficient handling of groups of micro-ops downstream. It supports the following.
- Loop Stream Detection (LSD). For small iterative segments of code whose micro-ops fit within the 28-slot Instruction Decoder Queue (IDQ), the system only needs to decode the instruction stream once. The LSD detects these loops (backward branches) which could be streamed directly from the IDQ. When such a loop is detected, the micro-ops are locked down and the loop is allowed to stream from the IDQ until a mis-prediction ends it. When the loop plays back from the IDQ, it provides higher bandwidth at reduced power, (since much of the rest of the front end pipeline is shut off. In the previous micro-architecture the loop detector was working with the instructions within the IQ upstream. The LSD provides a number of benefits, including,
- no loss of bandwidth due to taken-branches,
- no loss of bandwidth due to misaligned instructions,
- no LCP penalties, as the pre-decode stage are used once for the instruction stream within the loop,
- reduced front-end power consumption, because the instruction cache, BPU and pre-decode unit can go to idle mode.
- Stack Pointer Tracking (SPT) implements the Stack Pointer Register (RSP) update logic of instructions which manipulate the program stack (PUSH, POP, CALL, LEAVE and RET) within the IDU. These macro-instructions were implemented by several micro-ops in previous architectures. The benefits with SPT include
- using a single micro-op for these instructions improves decoder bandwidth,
- execution resources are conserved since RSP updates do not compete for them,
- parallelism in the execution engine is improved since the implicit serial dependencies have already been taken care of,
- power efficiency improves since RSP updates are carried out by a small hardware unit.
- Micro-Fusion The instruction decoder supports micro-fusion to improve pipeline front-end throughput and increase the effective size of queues in the scheduler and re-order buffer (ROB). Micro-fusion fuses multiple micro-ops from the same instruction into a single complex micro-op. The complex micro-op is dispatched in the out-of-order execution core. This reduces power consumption as the complex micro-op represents more work in a smaller format (in terms of bit density), and reduces overall "bit-toggling" in the machine for a given amount of work. It virtually increases the amount of storage in the out-of-order execution engine. Many instructions provide register and memory flavors. The flavor involving a memory operand will decodes into a longer flow of micro-ops than the register version. Micro-fusion enables software to use memory to register operations to express the actual program behavior without worrying about a loss of decoder bandwidth.
- Macro-Fusion The IDU supports macro-fusion which translates adjacent macro-instructions into a single micro-op if possible. Macro-fusion allows logical compare or test instructions to be combined with adjacent conditional jump instructions into one micro-operation.
Nehalem Core: Out-of-Order Execution Engine
The execution engine (EE) in a Nehalem core selects micro-ops from the upstream IDQ and dynamically schedules them for dispatching and execution by the execution units downstream. The EE is a dynamically scheduled "out-of-order", super-scalar pipeline which allows micro-ops to use available execution units in parallel when correctness and code semantics are not violated. The EE scheduler can dispatch up to 6 micro-ops in one clock cycle through the six dispatch ports to the execution units. There are several FUs, arranged in three clusters, for integer, FP and SIMD operations. Finally, four micro-ops can retire in one cycle, which is the same as in Nehalem's predecessor cores. Results can be written-back at the maximum rate of one register per per port per cycle. Fig. 7 presents a high-level diagram of the Execution Engine along with its various functional units.
Fig. 7 High-level diagram of a the out-of-order execution engine in the Nehalem core. All units are fully pipelined and can operate independently.
The execution engine includes the following major components:
- Register Rename and Allocation Unit (RRAU) − Allocates EE resources to micro-ops in the IDQ and moves them to the EE.
- Reorder Buffer (ROB) − Tracks all micro-ops in-flight,
- Unified Reservation Station (URS) − Queues up to 36 micro-ops until all source operands are ready, schedules and dispatches ready micro-ops to the available execution units.
- Memory Order Buffer (MOB) − Supports speculative and out of order loads and stores and ensures that writes to memory take place in the right order and with the right data.
- Execution Units and Operand Forwarding Network The execution units are fully pipelined and can produce a result for most micro-ops with latency 1 cycle.
The IDQ unit (see Fig. 6) delivers a stream of micro-ops to the allocation/renaming stage of the EE pipeline. The execution engine of Nehalem supports up to 128 micro-ops in flight. The input data associated with a micro-op are generally either read from the ROB or from the retired register file. When a "dependency chain" across micro-ops causes the machine to wait for a "slow" resource (such as a data read from L2 data cache), the EE allows other micro-ops to proceed. The primary objective of the execution engine is to increase the flow of micro-ops, maximizing the overall rate of instructions reaching completion per cycle (IPC), without compromising program correctness.
Resource Allocation and Register Renaming for micro-ops The initial stages of the out of order core advance the micro-ops from the front end to the ROB and RS. This process is called micro-op issue. The RRAU in the out of order core carries out the following steps.
- It allocates resources to micro-ops, such as,
- an entry in the re-order buffer (ROB),
- an entry in the reservation station (RS),
- and a load/store buffer if a memory access is required.
- It binds the micro-op to an appropriate "dispatch" (or "issue") port.
- It "renames" source and destination operands of micro-ops in-flight, enabling out of order execution. Operands are registers or memory in general. "Architectural" (program visible) registers are renamed onto a larger set of "micro-architectural" (or "non-architectural") registers. Modern processors contain a large pool of non-architectural registers, that is, registers which are not accessible from the code. These registers are used to capture results which are produced by independent computations but which happen to refer to the same architected register as destination. Register renaming eliminates these false dependencies which are known as "write-after-write" and "write-after-read" hazards. A "hazard" is any condition which could force a pipeline to stall to avoid erroneous results.
- It provides data to the micro-op when the data is either an immediate value (a constant) or a register value that has already been calculated.
Unified Reservation Station (URS) queues micro-ops until all source operands are ready, then it schedules and dispatches ready micro-ops to the available execution units. The RS has 36 entries, that is, at any moment there is a window of up to 36 micro-ops waiting in the EE to receive input. A single scheduler in the Unified-Reservation Station (URS) dynamically selects micro-ops for dispatching to the execution units, for all operation types, integer, FP, SIMD, branch, etc. In each cycle, the URS can dispatch up to six micro-ops, which are ready to execute. A micro-op is ready to execute as soon as its input operands become available. The URS dispatches micro-ops through the 6 issue ports to the execution units clusters. Fig. 7 shows the 6 issue ports in the execution engine. Each cluster may contain a collection of integer, FP and SIMD execution units.
The result produced by an execution unit computing a micro-op are eventually written back permanent storage. Each clock cycle, up to 4 results may be either written back to the RS or to the ROB. New results can be forwarded immediately through a bypass network to a micro-op in-flight that requires it as input. Results in the RS can be used as early as in the next clock cycle.
The EE schedules and executes next common micro-operations, as follows.
- Micro-ops with single-cycle latency can be executed by multiple execution units, enabling multiple streams of dependent operations to be executed quickly.
- Frequently-used micro-ops with longer latency have pipelined execution units so that multiple micro-ops of these types may be executing in different parts of the pipeline simultaneously.
- Operations with data-dependent latencies, such as division, have data dependent latencies. Integer division parses the operands to perform the calculation only on significant portions of the operands, thereby speeding up common cases of dividing by small numbers.
- Floating point operations with fixed latency for operands that meet certain restrictions are considered exceptional cases and are executed with higher latency and reduced throughput. The lower-throughput cases do not affect latency and throughput for more common cases.
- Memory operands with variable latency, even in the case of an L1 cache hit, are not known to be safe for forwarding and may wait until a store-address is resolved before executing. The memory order buffer (MOB) accepts and processes all memory operations.
Nehalem Issue Ports and Execution Units The URS scheduler can dispatch up to six micro-ops per cycle through the six issue ports to the execution engine which can execute up to 6 operations per clock cycle, namely
- 3 memory operations (1 integer and FP load, 1 store address and 1 store data) and
- 3 arithmetic/logic operations.
The ultimate goal is to keep the execution units utilized most of the time. Nehalem contains the following components which are used to buffer micro-ops or intermediate results until the retirement stage
- 36 reservation stations
- 48 load buffers to track all allocate load operations,
- 32 store buffers to track all allocate store operations, and
- 10 fill buffers.
The execution core contains the three execution clusters, namely, SIMD integer, regular integer and SIMD floating-point/x87 units. Each blue block in Fig. 7 is a cluster of execution units (EU) in the execution engine. All EUs are fully pipelined which means they can deliver one result on each clock cycle. Latencies through the EU pipelines vary with complexity of the micro-op from 1 to 5 cycles Specifically, the EUs associated with each port are the following:
- Port 0
- Integer ALU and Shift Units
- Integer SIMD ALU and SIMD shuffle
- Single precision FP MUL, double precision FP MUL, FP MUL (x87), FP/SIMD/SSE2 Move and Logic and FP Shuffle, DIV/SQRT
- Port 1
- Integer ALU, integer LEA and integer MUL
- Integer SIMD MUL, integer SIMD shift, PSAD and string compare, and
- FP ADD
- Port 2
- Integer loads
- Port 3
- Store address
- Port 4
- Store data
- Port 5
- Integer ALU and Shift Units, jump
- Integer SIMD ALU and SIMD shuffle
- FP/SIMD/SSE2 Move and Logic
The execution core also contains connections to and from the memory cluster (see Fig. 7). <pForwarding and By-pass Operand Network Nehalem can support write back throughput of one register file write per cycle per port. The bypass network consists of three domains of integer, FP and SIMD. Forwarding the result within the same bypass domain from a producer micro-op to a consumer micro-op is done efficiently in hardware without delay. Forwarding the result across different bypass domains may be subject to additional bypass delays. The bypass delays may be visible to software in addition to the latency and throughput characteristics of individual execution units.
The Re-Order Buffer (ROB) is a key structure in the execution engine for ensuring the successful out-of-order progress-to-completion of the micro-ops. The ROB holds micro-ops in various stages of completion, it buffers completed micro-ops, updates the architectural state in macro-instruction program order, and manages ordering of the various machine exceptions. On Nehalem the ROB has 128 entries to track micro-ops in flight.
Retirement and write-back of state to architected registers is only done for instructions and micro-ops that are on the correct instruction execution path. Instructions and micro-ops of incorrectly predicted paths are flushed as soon as mis-prediction is detected and the correct paths are then processed.
Retirement of the correct execution path instructions can proceed when two conditions are satisfied:
- all micro-ops associated with the macro-instruction to be retired have completed, allowing the retirement of the entire instruction. In the case of instructions that generate very large numbers of micro-ops, enough to fill the retirement window, micro-ops may retire.
- Older instructions and their micro-ops of correctly predicted paths have retired.
The advantages of this design is that older instructions which have to block waiting, for example, for the arrival of data from memory, cannot block younger, but independent, instructions and micro-ops, whose inputs are available. The micro-ops of these younger instructions can be dispatched to the execution units and warehoused in the ROB until completion.
Nehalem Core: Load and Store Operations
The memory cluster in the Nehalem core supports:- peak issue rate of one 128-bit (16 bytes) load and one 128-bit store operation per clock cycle
- deep buffers for data load and store operations:
- 48 load buffers,
- 32 store buffers and
- 10 fill buffers;
- fast unaligned memory access and robust handling of memory alignment hazards;
- improved store-forwarding for aligned and non-aligned scenarios, and
- store-to-load data forwarding for most address alignments.
Nehalem Core: Intel� Streaming SIMD Extensions Instruction Set
Single-Instruction Multiple-Data (SIMD) is a processing technique were the same operation is applied simultaneously to different sets of input operands. Vector operations, such as, vector additions, subtractions, etc. are examples of computation where SIMD processing can be applied directly. SIMD requires the presence of multiple Arithmetic and Logic Units (ALUs) and multiple source and destination operands for these operations. The multiple ALUs can produce multiple results simultaneously using input operands. Fig. 8 illustrates an example SIMD computation against four operands.
Fig. 8 SIMD instructions apply the same FP or integer operation to collections of input data pairs simultaneously.
Nehalem supports SIMD processing to integer or floating-point ALU intensive code with the Streaming SIMD Extensions (SSE) instruction set. This technology has evolved with time and now it represents a rather significant capability in Nehalem's micro-architectures. Fig. 9 illustrates the SIMD computation mode in Nehalem. On the left part of Fig. 9, two double-precision floating-point operations are applied to 2 DP input operands. On the right part of Fig. 9, four single-precision floating-point operations are applied to 4 SP input operands.
Fig. 9 Floating-Point SIMD Operations in Nehalem.
Nehalem's execution engine (see Fig. 7) contains the ALU circuitry necessary to carry out two double-precision, or four single-precision "simple" FP operations, such as addition or subtraction, in each one of the two FP units accessible through ports 0 and 1. Note that Nehalem execution engine can retire up to 4 operations per clock cycle, including the SIMD FP ones.
Ideal Floating-Point Throughput For the Xeon 5560 which operates at 2.8GHz, we can say that in the steady state and under ideal conditions each core can retire 4 double-precision or 8 single-precision floating-point operations each cycle. Therefore, the nominal, ideal throughput of a Nehalem core, a quad core and a 2-socket system are, respectively,
11.2 Giga FLOPs / sec / core = 2.8 GHz X 4 FLOPs / Hz44.8 Giga FLOPs / sec /socket = 11.2 GigaFLOPs/sec / core X 4 cores
89.6 Giga FLOPs / sec / node = 44.8 GigaFLOPs/sec / socket X 2 sockets,
in terms of double-precision FP operations.
Fig. 10 Floating-Point Registers in a Nehalem core.
SIMD instructions use sets of separate core registers called MMX and XMM registers (shown in Fig. 10). The MMX registers are 64-bit in size and are aliased to the operand stack for the legacy x87 instructions. XMM registers are 128-bit in size and each can store either 4 SP or 2 DP floating-point operands. The load and store units can retrieve and save 128-bit operands from cache or from the main memory.
One interesting feature of Nehalem's memory subsystem is that certain memory areas can be treated as "non-temporal", that is, they can be used as buffers for vector data streaming in and out of the core, without requiring their temporary storage in a cache. This is an efficient way to retrieve a stream of sub-vector operands from memory to XMM registers, carry out SIMD computation and then stream the results out directly to memory.
Overview of the SSE Instruction Set Intel introduced and extended the support for SIMD operations in stages over time as new generations of micro-architectures and SSE instructions were released. Below we summarize the main characteristics of the SSE instructions in the order of their appearance.
MMX(TM) Technology Support for SIMD computations was introduced to the architecture with the "MMX technology". MMX allows SIMD computation on packed byte, word, and double-word integers. The integers are contained in a set of eight 64-bit MMX registers (shown in Fig. 10).
Streaming SIMD Extensions (SSE) SSE instructions can be used for 3D geometry, 3D rendering, speech recognition, and video encoding and decoding. SSE introduced 128-bit XMM registers, 128-bit data type with four packed single-precision floating-point operands, data prefetch instructions, non-temporal store instructions and other cache-ability and memory ordering instructions, extra 64-bit SIMD integer support.
Streaming SIMD Extensions 2 (SSE2) SSE2 instructions are useful for 3D graphics, video decoding/encoding, and encryption. SSE2 add 128-bit data type with two packed double-precision floating-point operands, 128-bit data types for SIMD integer operation on 16-byte, 8-word, 4-double-word, or 2-quad-word integers, support for SIMD arithmetic on 64-bit integer operands, instructions for converting between new and existing data types, extended support for data shuffling and extended support for cache-ability and memory ordering operations.
Streaming SIMD Extensions 3 (SSE3) SSE3 instructions are useful for scientific, video and multi-threaded applications. SSE3 add SIMD floating-point instructions for asymmetric and horizontal computation, a special-purpose 128-bit load instruction to avoid cache line splits, an x87 FPU instruction to convert to integer independent of the floating-point control word (FCW) and instructions to support thread synchronization.
Supplemental Streaming SIMD Extensions 3 (SSSE3) SSSE3 introduces 32 new instructions to accelerate eight types of computations on packed integers.
SSE4.1 SSE4.1 introduces 47 new instructions to accelerate video, imaging and 3D applications. SSE4.1 also improves compiler vectorization and significantly increase support for packed dword computation.
SSE4.2 Intel during 2008 introduced a new set of instructions collectively called as SSE4.2. SSE4 has been defined for Intel's 45nm products including Nehalem. A set of 7 new instructions for SSE4.2 were introduced in Nehalem architecture in 2008. The first version of SSE4.1 was present in the Penryn processor.
SSE4.2 instructions are further divided into 2 distinct sub-groups, called "STTNI" and "ATA".
- STring and Text New Instructions (STTNI) instructions operate on strings of bytes or words of 16bit size. There are four new STTNI instructions which accelerate string and text processing. For example, code can parse XML strings faster and can carry out faster search and pattern matching. Implementation supports parallel data matching and comparison operations.
- Application Targeted Accelerators (ATA) are instructions which can provide direct benefit to specific application targets. There are two ATA instructions, namely "POPCNT" and "CRC32".
- POPCNT is an ATA for fast pattern recognition while processing large data sets. It improves performance for DNA/Genome Mining and handwriting/voice recognition algorithms. It can also speed up Hamming distance or population count computation.
- CRC32 is an ATA which accelerates in hardware CRC calculation. This targets Network Attached Storage (NAS) using iSCSI. It improves power efficiency and reduces time for software I-SCSI, RDMA, and SCTP protocols by replacing complex instruction sequences with a single instruction.
Compiler Optimizations for SIMD Support in Executables User applications can leverage the SIMD capabilities of Nehalem through the Intel Compilers and various performance libraries which have been tuned up to take advantage of this feature. On EOS, use the following compiler options and flags.
- -xHost (or the -xSSE4.2) compiler options to instruct the compiler to use the entire set of SSE instructions in the generated binary
- -vec This option enables "vectorization" (better term would be SIMDizations) and transformations enabled for vectorization. This effectively asks the compiler to attempt to use the SIMD SSE instructions available in Nehalem. Use the -vec-reportN option to see which lines could use SIMD and which could not and why.
- -O2 or -O3
Libraries Optimized for SIMD Support Intel provides user Libraries tuned up for SIMD computation. These include, Intel's Math-Kernel Library (MKL), Intel's standard math library (libimf) and the Integrated-Performance Primitive library (IPP). Please review the "~/README" text file on your EOS home directory with information on the available software and instructions how to access it. This document contains, among other things, a useful discussion on compiler flags used for optimization of user code, including SIMD.
Floating-Point Processing and Exception Handling
Nehalem processors implement a floating-point system compliant with the ANSI/IEEE Standard 754-1985, "IEEE Standard for Binary Floating-Point Arithmetic". IEEE 754 defines required arithmetic operations (addition, subtraction, sqrt, etc.), the binary representation of floating and fixed point quantities and conditions which render machine arithmetic valid or invalid. Before this standard, different vendors used to have their own incompatible FP arithmetic implementations making portability of FP computation virtually impossible. When the result of an arithmetic operation cannot be considered valid or when precision is lost, the h/w handles a Floating-Point Exception (FPE).
Nehalem Floating-Point Exceptions The following floating-point exceptions are detected by the processor:
- IEEE standard exception: invalid operation exception for invalid arithmetic operands and unsupported formats (#IA)
- Signaling NaN
- Infinity - Infinity
- Infinity � Infinity
- Zero � Zero
- Infinity � Zero
- Invalid Compare
- Invalid Square Root
- Invalid Integer Conversion
- Zero Divide Exception (#Z)
- Numeric Overflow Exception (#O)
- Underflow Exception (#U)
- Inexact Exception (#P)
Please review the following presentation on IEEE Floating-Point Standard and Floating Point Exception handling which apply to Nehalem. Note that this presentation is under revision but it is provides useful material for FP arithmetic.
Intel� Simultaneous Multi-Threading
A Nehalem core supports "Simultaneous Multi-Threading" (SMT), or as Intel calls it Hyper-Threading. SMT is a pipeline design and implementation scheme which permits more than one hardware threads to execute simultaneously within each core and share its resources. For Nehalem, two threads can be simultaneously executing within each core. Fig. 7 shows the different execution units within a Nehalem core which the two SMT threads can share.
Basic SMT Principles
The objective of SMT is to allow the 2nd hardware thread to utilize functional units in a core which the 1st hardware thread leaves idle. In Fig. 11, the right-hand side part demonstrates the case where two threads execute simultaneously within a core with SMT enabled. The horizontal dimension shows the occupancy of the functional units of a core and the vertical one shows consecutive clock cycles. As you can see, both SMT threads may "simultaneously" (i.e., at the same clock period) utilize these units, making progress.
The alternative to SMT would be to let a thread run until it has to stall (e.g., waiting for a lengthy FP operation to finish or a cache memory miss to be handled), at which point in time the OS dispatcher would have to carry out a costly context-switching operation with processor state swapping. This is illustrated in an idealized fashion (i.e., without accounting for the resource waste due to context-switching overhead) on the right-hand side part of the figure. SMT can potentially exploit "task-level" concurrency at a very fine level and produces cost saving by avoiding context-switching.
In short, the potential advantages of SMT are several, including among others, the increased utilization of functional units that would have remained idle, the overall increased throughput in instructions completed per clock cycle and the overhead savings from the lower number of thread switching operations. It implicitly can save power consumed by the idle units.
Fig. 11 Simultaneous Multi-Treading (SMT) concept on Nehalem cores.
When SMT is ON, each Nehalem core appears to the Operating System as two logical processors. An SMT enabled dx360-M2 node appears as 16 logical processors to Linux.
On Nehalem, SMT takes advantage of the 4-wide execution engine. The units are kept busy with the two threads. SMT hides the latency experienced by a single thread. One prominent advantage is that with SMT it is more likely that an active unit will be producing some result on behalf of a thread as opposed to consuming power while it is waiting for work. Overall, SMT is much more efficient in terms of power than adding another core. One Nehalem, SMT is supported by the high memory bandwidth and the larger cache sizes.
Resources on Nehalem Cores Shared Among SMT Threads
The Nehalem core supports SMT by replicating, partitioning or sharing existing functional units in the core. Specifically the following strategies are used:
- Replication The unit is replicated for each thread.
- register state
- renamed RSB
- large page ITLB
- PartitioningThe unit is statically allocated between the two threads
- load buffer
- store buffer
- reorder buffer
- small page ITLB
- Competitive SharingThe unit is dynamically allocated between the two threads
- reservation station
- cache memories
- data TLB
- 2nd level TLB
- SMT Insensitive All execution units are SMT transparent
CISC and RISC Processors
From the discussion above, it is clear that on the Nehalem processor, the CISC nature of the Intel64 ISA exits the scene after the instruction decoding phase by the IDU. By that time all CISC macro-instructions have been converted into RISC like micro-ops which are then scheduled dynamically for parallel processing at the execution engine. The specific execution engine of the Nehalem we described above could have been be part of any RISC or CISC processor. In deed one cannot tell by examining it if it is part of a CISC or a RISC processor. Please see a companion article on Power5+ processors and systems to make comparisons and draw some preliminary conclusions.
Efficient execution of applications is the ultimate objective and this requires an efficient flow of ISA macro-instructions through the processor. This implies accurate branch prediction and efficient fetching of instructions, their efficient decoding into micro-ops and a maximal flow of micro-ops from issue to retirement through the execution engine.
This points to one of the successes of the "RISC approach" where sub-tasks are simple and can be executed in parallel in multiple FUs by dynamic dispatching. Conversely, Nehalem has invested heavily in silicon real estate and clock cycles into pre-processing the CISC macro-instructions so that can be smoothly converted into sequences of micro-ops. The varying length of the CISC instructions requires the additional overhead in the ILD. A RISC ISA would had avoided this overhead and instructions would had moved directly from fetch to decoding stage.
At the same time, it is obvious that Intel has done a great job in processing very efficiently a heavy-weight CISC ISA, using all the RISC techniques. Thus the debate of RISC vs. CISC remains a valid and open question.
- Given modern back-end engines, which ISA style is more efficient to capture at a higher-level the semantics of applications?
- Is it more efficient to use a RISC back-end engine with a CISC or a RISC ISA and front-ends?
- It would be very interesting to see how well the Nehalem back-end execution engine would perform when fitted in a RISC processor front-end, handling a classical RISC ISA. For instance, how would a classical RISC, such as a Power5+ would perform if the Nehalem execution engine were to replace its own?
- Conversely, how would the Nehalem perform if it were fitted with the back-end execution engine of a classical RISC, such as that of an IBM Power5+ processor ?
- From the core designer point of view, can I select different execution engines for the same ISA ?
The old CISC vs.RISC debate is resurfacing as a question of how more aptly and concisely RISC or a CISC ISA can express the semantics of applications, so that when the code is translated into micro-ops powerful back-end execution engines can produce results at a lower cost, i.e., in shorter amount of time and/or using less power?
Memory Organization in Nehalem Processors and Platforms
Cache-Memory and the Locality Phenomenon
The demand for increasingly larger data and instruction sections in applications requires that the size of the main memory hosting them be also sufficiently large. Experience with modern processors suggests that 2 to 4 GiB are needed per compute core to provide a comfortable size for a main memory. However, cost and power consumption for this large amounts of memory, necessitates the use of the so called, Dynamic Random Access Memory (DRAM) technology. DRAM allows the manufacturing of large amounts of memory using simpler memory elements (i.e., by a transistor and a capacitor which needs to be dynamically refreshed every a few 10s of mili-seconds). However, the bandwidth rates at which modern processors require to access memory in order to operate efficiently, far exceed the memory bandwidth that can be supported with current DRAM technologies.
Another type of memory, called "Static RAM" (SRAM) implements memory elements with more complex organization (5-6 transistors). SRAM is much faster than the DRAM and it does not require periodic refreshing of the bit contents. However, with more electronic components per bit, memory density per chip decreases dramatically while the power consumption grows. We cannot currently provide 2-4 GiB of RAM per core using just SRAM with a viable cost.
Computer architects design modern processors with multiple levels of faster, smaller and more expensive cache memories. Cache memories, mostly implemented with SRAM logic, maintain copies of recently and frequently used instruction and data blocks of the "main" (DRAM) memory. When an object is accessed for the first time, the hardware retrieves a block of memory containing it from the DRAM and stores it in the cache. Subsequent object accesses go directly to the faster cache and avoid the lengthy access to DRAM.
This is a viable approach due to the phenomenon of "temporal" and "spatial locality" in the memory access patterns which executable code exhibit. Simply speaking, temporal locality means that objects (data or instructions) accessed recently, have a higher probability to get accessed in the near future than other memory objects. Spatial locality means that objects physically adjacent in memory to those accessed recently have a higher probability of getting accessed "soon". Temporal locality stems from the fact that within in a short span of time instructions in iterations (loops) are executed repeatedly likely accessing common data. Spatial locality is the result of code accessing dense array locations in linear order or simply accessing the next in sequence instruction. Hardware and compiler designers invest heavily in mechanisms which can leverage the locality phenomenon. Compilers strive to co-locate items which are likely to be accessed together within short time spans. Hardware logic detects sequential memory access and attempts to pre-fetch subsequent blocks ahead of time. The cache memories eventually have to evict least used contents to make room for incoming new ones.
Cache-Memory Organization in Nehalem
Nehalem divides the physical memory into blocks 64 byte in size. These blocks, referred to as "cache blocks" or "cache lines", are the units of data the memory system transfers among the major subsystems.
The architecture supports a hierarchy of up to three levels of cache memory and DRAM memory. Fig. 12 shows the different caches in a Nehalem chip, their connectivity with the common L3, QPI and IMC, along with the TLBs translation structures.
Fig. 12 Overview of Cache Memory Hierarchy and Data Flow Paths to and from Nehalem's Core.
Referring to Fig. 12, a Nehalem core contains an instruction cache, a first-level data cache and a second-level unified cache. Each physical processor chip may contain several processor cores and a shared collection of subsystems that are referred to as "un-core". Specifically, in Intel Xeon 5560 processors, there are four cores and the un-core provides a unified third-level cache shared by all cores in the chip, Intel QuickPath Interconnect ports and auxiliary logic such as, a performance monitoring unit, control configuration registers and power management units, among others.
The processor always reads a cache line from system memory beginning on a 64-byte boundary (which has an address with its 6 least-significant bits zero). A cache line can be filled from memory with a 8-transfer burst transaction. The caches do not support partially-filled cache lines, so caching even a single double-word requires caching an entire line.
L1 Cache At Level 1 (L1), separate instruction and data caches are part of the Nehalem core (called a "Harvard" style). The instruction and the data cache are each 32 KiB in size. The L1 data-cache has a single access data port, and a block size of 64 bytes. In SMT mode, the caches are shared by the two hardware threads running in the core.
The instruction and the data caches have 4-way and 8-way set associative organization, respectively. The access latency to retrieve data already in L1 data-cache is 4 clocks and the "throughput" period is 1 clock. The write policy is write-back.
L2 Cache Each core also contains a private, 256KiB, 8-way set associative, unified level 2 (L2) cache (for both instructions and data). L2's block size is 64 bytes and access time for data already in the cache is 10 clocks. The write policy is write-back and the cache is non-inclusive.
L3 Cache The Level 3 (L3) cache is a unified, 16-way set associative, 8 MiB cache shared by all four cores on the Nehalem chip. The latency of L3 access may vary as a function of the frequency ratio between the processor and the un-core sub-system. Access latency is around 35 − 40+ cycles.
The L3 is inclusive (unlike L1 and L2), meaning that a cache line that exists in either L1 data or instruction, or the L2 unified caches, also exists in L3. The L3 is designed to use the inclusive nature to minimize "snoop" traffic between processor cores and processor sockets. A 4-bit valid vector indicates if a particular L3 block is already cached in the L2 or L1 cache of a particular core in the socket. If the associated bit is not set, it is certain that this core is not caching this block. A cache block in use by a core in a socket, is cached by its L3 cache which can respond to snoop requests by other chips, without disturbing (snooping into) L2 or L1 caches on the same chip. The write policy is write-back.
Nehalem Memory Access Enhancements
The data path from L1 data cache to the memory cluster is 16 bytes in each direction. Nehalem maintains load and store buffers between the L1 data cache and the core itself.
Store Buffers
Intel64 processors temporarily store data for each write (store operation) to memory in a store buffer (SB). SBs are associated with the execution unit in Nehalem cores. They are located between the core and the L1 data-cache. SBs improve processor performance by allowing the processor to continue executing instructions without having to wait until a write to memory and/or to a cache is complete. It also allows writes to be delayed for more efficient use of memory-access bus cycles.In general, the existence of store buffers is transparent to software, even in multi-processor systems like the Nehalem-EP. The processor ensures that write operations are always carried out in program order. It also insures that the contents of the store buffer are always drained to memory when necessary.
- when an exception or interrupt is generated;
- when a serializing instruction is executed;
- when an I/O instruction is executed;
- when a LOCK operation is performed;
- when a BINIT operation is performed;
- when using an SFENCE or MFENCE instruction to order stores.
Load and Store Enhancements
The memory cluster of Nehalem supports a number of mechanisms which speed up memory operations, including- out of order execution of memory operations,
- peak issue rate of one 128-bit load and one 128-bit store operation per cycle from L1 cache,
- "deeper" buffers for load and store operations: 48 load buffers, 32 store buffers and 10 fill buffers,
- data pref-etching to L1 caches,
- data prefetch logic for pref-etching to the L2 cache
- fast unaligned memory access and robust handling of memory alignment hazards,
- memory disambiguation,
- store forwarding for most address alignments and
- pipelined read-for-ownership operation (RFO).
Data Load and Stores Nehalem can execute up to one 128-bit load and up to one 128-bit store per cycle, each to different memory locations. The micro-architecture enables execution of memory operations out-of-order with respect to other instructions and with respect to other memory operations.
Loads can
- issue before preceding stores when the load address and store address are known not to conflict,
- be carried out speculatively, before preceding branches are resolved
- take cache misses out of order and in an overlapped manner
- issue before preceding stores, speculating that the store is not going to be to a conflicting address.
Loads cannot
- speculatively take any sort of fault or trap
- speculatively access the uncacheable memory type
Stores to memory are executed in two phases:
- Execution Phase Prepares the store buffers with address and data for store forwarding (see below). Consumes dispatch ports 3 and 4.
- Completion Phase The store is retired to programmer-visible memory. This may compete for cache banks with executing loads. Store retirement is maintained as a background task by the Memory Order Buffer, moving the data from the store buffers to the L1 cache.
Data Pre-fetching to L1 Caches Nehalem supports hardware logic (DPL1) for two data pre-fetchers in the L1 cache. Namely
- Data Cache Unit (DCU) Prefetcher (also known as the "streaming prefetcher"), is triggered by an ascending access to recently loaded data. The logic assumes that this access is part of a streaming algorithm and automatically fetches the next line.
- Instruction Pointer-based Strided Prefetcher keeps track of individual load instructions. When load instructions have a regular stride, a prefetch is sent to the next address which is the sum of the current address and the stride. This can prefetch forward or backward and can detect strides of up to half of a 4KB-page, or 2 KBytes.
L1 pre-fetching usually improves the performance of the memory subsystem, but in rare occasions it may degrade it. The key to success is to issue the pre-fetch to data that the code will use in the near future when the path from memory to L1 cache is not congested, thus effectively spreading out the memory operations over time. Under these circumstances pre-fetching improves performance by anticipating the retrieval of data in large sequential structures in the program. However, it may cause some performance degradation due to bandwidth issues if access patterns are sparse instead of having spatial locality.�
On certain occasions, if the algorithm's working set is tuned to occupy most of the cache and unneeded pre-fetches evict lines required by the program, hardware prefetcher may cause severe performance degradation due to cache capacity of L1.
In contrast to hardware prefetchers, software prefetch instructions relies on the programmer or the compiler to anticipate data cache miss traffic. Software prefetch act as hints to bring a cache line of data into the desired levels of the cache hierarchy.
Data Pre-fetching to L2 Caches DPL2 pre-fetch logic brings data to the L2 cache based on past request patterns of the L1 to the L2 data cache. DPL2 maintains two independent arrays to store addresses from the L1 cache, one for upstreams (12 entries) and one for down streams (4 entries). Each entry tracks accesses to one 4K byte page. DPL2 pre-fetches the next data block in a stream. It can also detect more complicated data accesses when intermediate data blocks are skipped. DPL2 adjusts its pre-fetching effort based on the utilization of the memory to cache paths. Separate state is maintained for each core.
Memory Disambiguation A load instruction micro-op may depend on a preceding store. Many micro-architectures block loads until all preceding store address are known. The memory disambiguator predicts which loads will not depend on any previous stores. When the disambiguator predicts that a load does not have such a dependency, the load takes its data from the L1 data cache. Eventually, the prediction is verified. If an actual conflict is detected, the load and all succeeding instructions are re-executed.
Store Forwarding When a load data follows a store which reloads the data the store just wrote to memory, the microarchitecture can forward the data directly from the store to the load in many cases. This is called "store-to-load" forwarding, and it saves several cycles by allowing a data requester receive data already available on the processor instead of waiting for a cache to respond. However several conditions must be met for store to load forwarding to proceed without delays:
- the store must be the last store to that address prior to the load,
- the store must be equal or greater in size than the size of data being loaded and
- the load data must be completely contained in the preceding store.
Efficient Access to Unaligned Data The cache and memory subsystems handle a significant amount of instructions and data with different address alignment scenarios. Different address alignments have varying performance impact on memory and cache operations based on the implementation of these subsystems. On Nehalem the data path to the L1 caches are 16 bytes wide. The L1 data cache can deliver 16 bytes of data in every cycle, regardless how their addresses are aligned. However, if a 16-byte load spans across a cache line boundary, the data transfer will suffer a mild delay in the order of 4 to 5 clock cycles. Prior mircro-architectures imposed much heavier delays.
Nehalem EP Main Memory Organization
Integrated Memory Controller
The integrated memory controller (IMC) for Nehalem supports three 8-byte channels of DDR3 memory operating at up to 1.333 GigaTransfer/sec (GT/s). Fig. 13 shows the IMC in a Nehalem chip. Total theoretical bandwidth between DRAM and the IMC in the un-core domain of the chip is 31.992 GB/s. The memory controller supports both registered and un-registered DDR3 DRAM. Each channel of memory can operate independently and the controller services requests out-of-order to minimize latency. Each core supports up to 10 data cache misses and 16 total outstanding misses. This places a strict upper bound on the memory bandwidth per core.
Fig. 13 Nehalem On-Chip Memory Hierarchy and Data Traffic through the Chip
Cache-Coherence Protocol for Multi-Processors
The conveniences of the cache memories come with some extra cost when the system has multiple processors. Copies of data which have been retrieved and modified by a processor in its local cache are inconsistent with the original copy in main memory. When another processor accesses the same data item it should receive the latest up-to-date copy and not an older stale version of it. This problem of Memory Consistency is addressed with Cache Coherence (CC) mechanisms. CC ensures that the value of an item retrieved by any processor in the system is the most up-to-date one. CC may add considerable overhead in accessing memory in multi-processors. CC logic is in the critical path of accessing memory and can easily become the main bottleneck, exacerbating the processor and memory speed gap. Recent processors provide increasingly tuned and adaptive CC protocols which try to stay to any extend feasible out of the way in accessing memory. Ideally, accesses to disjoint data by separate processors should proceed without any additional overhead. Conflicting access to the same data item (reads and writes) by different processors should extend the latency as minimally as possible, maintain fairness and avoid indefinite postponement. Cache coherence mechanism have been studied extensively in the literature and still are hot topics as there is always an increasing demand for larger multi-processors and more efficient concurrent access to shared memory.
Cache-Coherence Protocol (MESI+F)
Practical reasons require that CC protocols maintain memory consistency in terms of 64-byte memory blocks and not in individual bytes or words. Memory blocks are the units of physical memory transfer. Each block has a unique identification, and belongs to a unique Nehalem socket ("home location") and is managed by the local IMC. Based on the way and time they propagate modifications of the blocks, CC protocols are divided into 2 categories, namely write-update and write-invalidate. Based on the way they locate multiple copies of the same block, are divided into "snoopy" and the directory based protocols. For the discussion which follows please refer to Fig. 13.
Nehalem processors use the MESIF (Modified, Exclusive, Shared, Invalid and Forwarding) cache protocol to maintain cache coherence with caches on the same chip and on other chips via the QPI. MESIF belongs to the write-invalidate, snoopy (with a small directory part) category, and it is a variation of the well known MESI protocol. The designations used in the its acronym are the possible states that cache memory blocks can be in as they are transferred among cores, caches, I/O and DRAM. When a core reads or modifies memory objects causes the their corresponding block to transition from one of these states to another. The current state of a block and the requested operation against it prescribes the h/w to follow a different sequence of tasks which provably maintain memory consistency.
Fig. 14 The State Transitions of Cache Blocks in the Basic MESI Cache-Coherence Protocol.
Initially all blocks in a cache do not store actual data and they are in the "Invalid" state. When a core reads a data object, it always checks first the L1 memory to see if the block is already there. The first time a block is accessed results in a cache read miss and it is in the Invalid state. If the block is not in L1 but is found in the L2 cache (L1 miss and L2 hit), it is transferred to the L1 data cache and the data access instruction proceeds. If the block is neither in the L2, then it must be retrieved from the "un-core". In general, a read-miss causes the core to retrieve the entire 64-byte cache block containing the object into the appropriate cache (L1, L2, L3, or all). This operation is called a cache-line fill. A block retrieved for the first time by any core transitions to the "Exclusive" state.
The next time a core needs to access the same or nearby memory locations, if the block is still in the cache the data object is retrieved directly from the cache instead of going back to memory. This is called a cache hit.
When a core has already retrieved a block in the Exclusive state and another core requires to read the same block, the h/w retrieves and stores a copy of this block in the cache of the latest core. The state of that block transitions to the "Shared" state.
When a core wants to write an operand to memory, it first checks if the corresponding block is already in the cache. If a valid cache line does exist, the processor can write the operand into the cache instead of writing it out to system memory. This operation is called a write hit.
A write which refers to a memory location not currently in the cache causes a write-miss. In this case the core performs a cache line-fill, write allocation and proceeds to modify the value of the operand in the cache line without writing directly to memory.
When a core attempts to modify data in a Shared state block, the h/w issues a "Request-for-Ownership" (RfO) transaction which invalidates all copies in other caches and transitions its own (unique now) copy to Exclusive state. The owning core can read and write to this block without having to notify the other cores. If any of the cores previously sharing this block attempts to read this block, it will receive a cache-miss since the block is Invalid in that core's cache. Note that when a core attempts to modify data in a Exclusive state block, NO "Request-for-Ownership" transaction is necessary since it is certain that no other processor is caching copies of this block.
For Nehalem which is a multi-processor platform, the processors have the ability to "snoop" (eavesdrop) the address bus for other processor's accesses to system memory and to their internal caches. They use this snooping ability to keep their internal caches consistent both with system memory and with the caches in other interconnected processors.
If through snooping one processor detects that another processor intends to write to a memory location that it currently has cached in Shared state, the snooping processor will invalidate its cache block forcing it to perform a cache line fill the next time it accesses the same memory location.
If a core detects that another core is trying to access a memory location that it has modified in its cache, but has not yet written back to system memory, the owning core signals the requesting core (by means of the "HITM#" signal) that the cache block is held in Modified state and will perform an implicit write-back of the modified data. The implicit write-back is transferred directly to the requesting core and snooped by the memory controller to assure that system memory has been updated. Here, the processor with the valid data can transfer the block directly to the other core without actually writing it to system memory; however, it is the responsibility of the memory controller to snoop this operation and update memory.
Each memory block can be stored in a unique set of cache locations, based on a subset of their memory block identification. A cache memory with associativity K can store each memory block to up to K alternative locations. If all K cache slots are occupied by memory blocks, the K+1 request will not have room to store this latest memory block. This requires that one of the existing K blocks has to be written out to memory (or the inclusive L3 cache) if this block is in Modified state. Cache memories commonly use a Least Recently Used (LRU) cache replacement strategy where they evict the block which has not been accessed recently.
As we mentioned, before written out to memory, data operands are first saved in a store buffer. They are then written from the store buffer to memory when the system path to memory is available.
Note that when all 10 of the line-fill buffers in a core become occupied, outstanding data access operations queue up in the load and store buffers and cannot proceed. When this happens the core's front end is suspends issuing micro-ops to the RS and OOO engine to maintain pipeline consistency.
The Un-Core Domain and Multi-Socket Cache Coherence
In the Nehalem processor the "un-core" domain essentially is a shared last level L3 cache ("LLC"), a memory access chip-set ("Northbridge"), and a QPI socket interconnection interface. Cache line access requests (such as, L2 cache misses, "un-cache-able" loads and stores) from the cores are serviced and the multi socket cache line coherency is maintained with the other sockets and the I/O Hub.
Memory consistency in a multi-core, multi-socket system like the Nehalem-PE, is maintained across sockets. With the introduction of the Intel Quick-Path Interconnect protocol the, 4 MESI states are supplemented with a fifth, Forward (F) state, for lines forwarded from one Nehalem socket to another.
Cache line requests from the on-chip four cores, from a remote chip or the I/O hub are handled by the Global Queue (GQ) (see Fig. 13). The GQ buffers, schedules and manages the flow of data traffic through the un-core. The GQ contains 3 request queues for the different request types:
- Write Queue (WQ): is a 16-entry queue for store (write) memory access operations from the local cores.
- Load Queue (LQ): is a 32-entry queue for load (read) memory requests by the local cores.
- QPI Queue (QQ): is a 12-entry queue for off-chip requests delivered by the QPI links.
When the GQ receives a cache line request from one of the cores, it first checks the on-chip Last Level Cache (L3) to see if the line is already cached there. As the L3 is inclusive, the answer can be quickly determined. If the line is in the L3 and was owned by the requesting core it can be returned to the core from the L3 cache directly. If the line is being used by multiple cores, the GQ snoops the other cores to see if there is a modified copy. If so the L3 cache is updated and the line is sent to the requesting core. In the event of an L3 cache miss, the GQ sends out requests for the line. Since the cache line could be cached in the other Nehalem chip, a request through the QPI to the remote L3 cache is made. As each Nehalem processor chip has its own local integrated memory controller, the GQ must identify the "home" location of the requested cache line from the physical address. If the address identifies home as being on the local chip, then the GQ makes a simultaneous request to the local IMC. If home belongs to the remote chip, the request sent by the QPI will also be used to access the remote IMC.
This process can be viewed in the terms of the QPI protocol as follows. Each socket has a "Caching Agent" (CA) which might be thought of as the GQ plus the L3 cache and a "Home agent" (HA) which is the IMC. An L3 cache miss results in simultaneous queries for the line from all the CAs and the HA (wherever home is). In a Nehalem-EP system there are 3 caching agents, namely the 2 sockets and an I/O hub. If none of the CAs has the cache line, the home agent ultimately delivers it to the caching agent that requested it. Clearly, the IMC has queues for handling local and remote, read and write requests.
Local vs. Remote Memory Access
In Nehalem, the integrated memory controller substantially improved memory latency and bandwidth, compared to predecessor micro-architectures. For the two socket implementations of Nehalem EP (see Fig. 15 ), the remote latency is higher, since the memory request and response must go through a QPI link. This shared memory organization is called "cache-coherent Non-Uniform Memory Access" (cc-NUMA) and it is very common in modern SMP platforms.
The latency to access the local memory is, approximately, 65 nano-seconds. The latency to access the remote memory is, approximately, 105 nano-seconds. That is, remote accesses are 1.6 to 1.7 times the latency of local memory access.
The available bandwidth through the QPI link is 12.8 GB/s which is approximately %40 of the theoretical bandwidth of the three local DDR3 channels.
Fig. 15 Nehalem-EP 8-way cc-NUMA SMP, Memory Hierarchies and Local vs. Remote Memory Organization.
Fig. 16 demonstrates access to memory which is directly (locally) attached to a Nehalem chip. The sequence of steps which take place are the following:
- Step1: CPU0 requests a cache line which is not in CPU0's cache
- CPU0 requests data from its DRAM ;
- CPU0 snoops CPU1 to check if data is present there.
- Step 2: Response
- DRAM returns data
- CPU1 returns snoop response
Fig. 16 Nehalem Local Memory Access Event Sequence.
Fig. 17 demonstrates access to remote memory (directly attached to the other Nehalem chip). The sequence of steps which take place are the following:
- Step1: CPU0 requests a cache line which is not in CPU0's cache nor in directly attached DRAM
- Step 2: Request sent over Intel� QuickPath Interconnect to CPU1
- Step 3: CPU1's probe for cache line
- CPU1's IMC makes requests to its DRAM;
- CPU1 snoops internal caches;
- Step 4: Response
- Data returns to CPU0 via the QPI;
- CPU0 installs cache block
Fig. 17Nehalem Remote Memory Access Event Sequence.
The cache coherency protocol messages, among the multiple sockets, are exchanged over the Intel QPI. The inclusive L3 cache mode allows this protocol to operate rather fast, with the latency to the L3 cache of the adjacent socket being even less than the latency to the local memory.
One of the main virtues of the integrated memory controller is the separation of the cache coherency traffic and the memory access traffic. This enables a tangible increase in memory access bandwidth, compared to previous architectures, but it results in a non-uniform memory access (NUMA). The latency to the memory DIMMs attached to a remote socket is considerably longer than to the local DIMMs. A second advantage is that the memory control logic can run at processor frequencies and thereby reduce the latency.
Virtual Memory in Nehalem Processors
Virtual Memory
In modern processors, an executable is logically divided into "sections", or "segments" which have distinct function. For instance, an executable consists, among others, of a "code", a "stack" and a "heap" segment. For reasons of effective space management and efficient utilization, each segment is divided into logical units, called pages. A page in different varies from a few KiBytes in size, (e.g., 4 KiB) to several MiBytes or even GiBytes.
Each page can actually be stored anywhere in the physical memory, in any of the available main memory slots known as page frames. We can consider the main memory as an array of pages frames. As an example, a physical memory with 4GiBytes capacity has available exactly 1 Mi page frames for pages having 4KiB size. Applications can define vast amounts of memory, but they usually refer or access a very small subset of it. When a program references for the first time a memory location (for instance a new subroutine call or a reference to a data item in an array) the system selects a free page frame and "pages in" the corresponding page. Application pages already in page slots which have not been recently used become candidates for eviction to make room for new pages.
The mechanism which dynamically manages the page frames and keeps track of the mapping between pages and page frames is called the Virtual Memory (VM) management system.
While applications execute refer to memory using "Effective Addresses" (EA) which are virtual memory addresses. "Physical Addresses" (PA) are actual addresses the memory hardware uses to identify specific memory locations. The VM system dynamically translates EAs into PAs, in process called "Virtual Address Translation". VM systems keeps track of the various program segments and corresponding pages with in memory in data structures called VM segment and page tables. These structures end up taking plenty of memory space. Multiple levels of page tables are used to cut down on the actual space used. This multi-level indirection requires the traversal of multiple tables for each address an application uses and it is in the critical path of the tasks the processor has to carry out in order to retire each macro-instruction. For this reason, special hardware called "Translation Look-aside Buffers" (TLBs) is used to speed up this process.
Nehalem Address Translation Process
Address Sizes Intel64 architecture defines translation from a "flat", linear 64-bit "Effective Address" (EA) into a "Physical Address" (PA) with a width to up to 52 bits. Note that even though this mode produces 64-bit linear addresses, the processor ensures that bits 63:47 of such an address are identical. This implies that the Virtual Address (VA) the paging system uses has an effective width of 48 bits. Although 52 bits corresponds to 4 PiBytes, since linear addresses are limited to 48 bits, at most 256 TiBytes of linear-address space may be accessed at any given time by a single process.
VM Page Sizes Supported Nehalem support virtual memory page sizes of 4 KiB, and 2 MiB and 1GiB "large" pages. Please refer to Fig. 13 which shows in detail the hardware components involved in the EA to PA translation process and the various levels of cache memories.
TLBs The processor architecture specifies two-levels of translation look-aside buffers, TLB0 and TLB1 to speed-up the EA to PA translation process. The TLB is a cache of recently accessed page table entries (PTE). A PTE maps the address of a page referenced by the program to its actual page slot location in memory. The first level TLB0 consists of separate TLBs for data DTLB0 and instructions ITLB0. DTLB0 handles address translation for data accesses, it provides 64 entries to support 4KiB pages and 32 entries for large pages. The ITLB0 provides 64 entries (per thread) for 4KiB pages and 7 entries (per thread) for large pages. The second level unified UTLB1 handles both code and data accesses for 4KiB pages. It support 4KiB page translation operation that missed DTLB0 or ITLB0.
Here is a list of entries in each TLB
- ITLB0 for 4-KiB pages: 64 entries / SMT thread, 4-way associative;
- ITLB0 for 2-MiB pages: 7 entries / SMT thread, fully associative;
- DTLB0 for 4-KiBe pages: 64 entries, 4-way associative;
- DTLB0 for 2-MiB pages : 32 entries, 4-way associative;
- UTLB1 for 4-KiB pages: 512 entries for both data and instruction look-ups.
An DTLB0 miss and UTLB1 hit causes a penalty of 7 cycles. Software only pays this penalty if the DTLB0 is used in some dispatch cases. The delays associated with a miss to the TLB1 and Page-Miss Handler are largely non-blocking.
Intel Turbo Boost Technology
"Turbo Boost Technology" dynamically turns off unused processor cores and increases the clock speed of the cores in use. It will increase the frequency in steps of 133 MHz (to a maximum of three steps or 400 MHz) as long as the processors' predetermined thermal and electrical requirements are still met. For example, with three cores active, a 2.26 GHz processor can run the cores at 2.4 GHz. With only one or two cores active, the same processor can run those cores at 2.53 GHz. Similarly, a 2.93 GHz processor can run at 3.06 GHz or even 3.33 GHz. When the cores are needed again, they are dynamically turned back on and the processor frequency is adjusted accordingly. This feature can be enabled or disabled in the UEFI BIOS of each node.
EOS Node Architecture
Each of the 314 dx360-M2 compute nodes and the 6 x3650-M2 login nodes are Shared-memory Multi-Processors (SMP). The underlying architecture for both dx360-M2 and x3650-M2 is the "Nehalem EP", discussed previously. Fig. 18 shows a dx360-M2 node without the cover. It basically consists of two quad-core Nehalem chips, DDR3 DRAM memory and I/O capability. All basic parts of the nodes use Intel's QPI which supports substantial point-to-point bandwidth and low latencies.
dx360 M2 SMP Nodes Architecture
Fig. 18 An Internal View of a Typical dx360-M2 EOS Compute Node.
In Nehalem EP, two Nehalem chips connect together to form a 8-Way SMP by a Quick-Path Interconnect (QPI) link. See Fig. 19 for the architecture of iDataPlex nodes. QPI is a recent , high-speed, point-to-point interconnection technology designed for intra and inter-chip level communication. Since memory DIMMs are partitioned by Nehalem socket, the system is a cache-coherent non-uniform memory access (cc-NUMA) system.
Fig. 19 An 8-way dx360 M2 node with 2 quad-core Nehalem chips.
High-Performance Switch Cluster Interconnect
The powerful Nehalem dx360-M2 nodes form high-performance cluster with an equally high-performance InfiniBand interconnect fabric. At TAMU, all 324 nodes of the EOS connect together through a Voltaire's Grid Director GD4700 (see Fig. 20) IB switch.
Fig. 19 An overview of the EOS iDataPlex Cluster at Texas A&M University
HCA the Host Adapter to IB Fabric
Each dx360-m2 node connects to the IB fabric through a host-side switch adapter, called the Host-Channel Adapter (HCA). The HCAs are using the ConnectX�-2 Single or Dual-Port Adapter Silicon from Mellanox. Each HCA has one (and for some nodes two) full-duplex IB transmission link and connects to a port on the GD4700. On the dx360-M2 side, each HCA attaches directly to the 16-lane PCI-express gen2 channel. A 16-lane PCIe-gen2 is a full-duplex I/O bus with 2 data bytes per direction, and it is capable of delivering 8GB/s per direction. Since this PCIe port is on the Intel 5520 I/O Hub chip (IOH) it is one hop away to each one of the two Nehalem chips though a QPI link. In this configuration the PCIe_gen2-QPI-Nehalem path supports very low latency for short IB messages and full bandwidth for the IB links.
Intel's 5520 IOH chip supports fully all the RDMA features of the IB HCA and facilitates efficient access to node's main memory. HCAs are based on communications processors which support several main-processor off-load capabilities to facilitate high-speed, low-latency, concurrent access to local and remote memories. One of the interesting design feature of IB is that it can directly map into user (application memory) for direct access. This avoids expensive user to system memory intermediate data copies whenever possible and user to kernel code switching.
Voltaire's Grid Director GD4700 IB Switch
The GD4700 is a 4x Quadruple-Data Rate (QDR) "non-blocking" InfiniBand switch. At TAMU the GD4700 currently is half-way populated with 324 4x QDR ports connected to cluster nodes. This switch has a modular architecture and it has been configured with the internal fabric infrastructure to be expandable to up to 648 4x QDR ports. Fig. 21 illustrates the major functional components and the internal connectivity of this switch.
Fig. 21 The Voltaire's Grid-Director GD4700 4x QDR IB switch providing Full-Bisection bandwidth to all 324 attached hots for the EOS Cluster at Texas A&M University
The GD4700 is built around 4-th Generation Mellanox InfiniScale IV ASIC. InfiniScale IV is a 36X36, non-blocking switching element which can sustain the full bi-section bandwidth over all 36 bi-directional ports at QDR speeds, namely at 40Gb/sec per port per direction for a total of 2.88 Tib/s switching capacity. This ASIC implements a packet switching and scheduling engine for Congestion control and Quality of Service enforcement. It also supports adaptive routing in addition to the static routing capability commonly available. Now InfiniBand supports moving traffic via multiple parallel paths. Adaptive routing dynamically and automatically re-routes traffic to alleviate congested ports. However, in networks where traffic patterns are more predictable, static routing has been shown to produce superior results. The InfiniScale IV can use both static and adaptive routing.
In cases where resource contention is unavoidable, as for instance when multiple sources are trying to reach a single destination, Congestion control, using InfiniBand 1.2 standard mechanisms, is used to alleviate the hot-spot problem. The InfiniScale IV ASIC works in conjunction with ConnectX HCAs to restrict process traffic causing congestion, ensuring high-bandwidth and low-latency to all other flows. For converged traffic, the combination of high-bandwidth, adaptive routing, and congestion control provide a balanced traffic carrying capacity. End-to-end Quality of Service makes sure that traffic classes can be protected, guaranteeing the delivery of critical traffic.
Referring to Fig. 21, the Voltaire GD4700
- is a fully Non-Blocking Architecture based on a CLOS 3-stage multi-stage interconnection network;
- port-to-port small message latency is ~100 nano-seconds per SE hop, that is
- 100 nano-seconds when the two ports are on the same "line-card", or
- 300 nanoseconds maximum port-to-port (3 SEs are traversed).
As can be seen in Fig. 21, the GD4700 is not a "monolithic" switch but a 2 level "Fat-Tree", or "Folded-Closs" network. This fabric has constant and full bisection bandwidth. In practical terms this means that any N/2 disjoint pairs of communicating hosts can send and receive data at the line rate (nominally at 4GB/s), simultaneously, without creating any congestion or blocking anywhere in the entire fabric.
However, a common misconception is that FBB allows non-blocking and un-congested communication at full BW for all possible communicating pairs or groups. The keyword is "disjoint" which implies that each destination has exactly one source. When several sources are trying to reach the same destination, as for instance when there is an MPI Gather operation, it is common sense that the slowest part will be the bottleneck and it will determine the rate at which the communication will be carried out. In our case here the slowest part will be the links behind which packets from the various sources queue up to reach the common destination.
Routes and Routing Cost in IB Fabric
Referring to Fig. 22, there is only one possible minimum-hop route between any two hosts which are attached to the same IB line-card of the GD4770 switch. For example, packets traveling from A to host B, require traversing only one SE ASIC ("1 hop") with a nominal latency of ~100 nano-seconds.
On the other hand, when two hosts, say C and host Dminimum-hop routes for the communication. Each one of the possible routes has ~300 nano-second nominal latency. Once a pair of hosts establishes a communication path for a particular application the system will keep the same route until the application terminates.
Fig. 22 Possible routing cases with associated hop count and number of possible routes over infiniband fabric within the GD4700.
InfiniBand Communication Stack and MPI Code
Linux commodity clusters with IB fabric, employ a complex, yet standardized communications protocol stack. One of the big advantages of IB is that it supports direct access to IB communication h/w by user applications, bypassing the system kernel. This applies to data transfers and control logic.
InfiniBand Protocol Stack
User-Level Protocols Initially the application contacts the kernel to establish the necessary system data structures for the inter-process communication. When this registration step is completed, the application can directly request the IB h/w to transfer data with only a minimal kernel intervention. When actual data transfer takes place, the IB stack avoids to copy it from user space to system space and vice-versa.
Hardware Off-loading Another advantage of IB is that communications logic which is normally implemented by system software, is off-loaded to IB HCA hardware. A common technique used is called Remote-Direct Memory Access (RDMA). RDMA allows the actual transfer of data from system memory to I/O adapters (HCAs) without executing any code in the processor. The application via IB libraries, submits the parameters of the data transfer and it launches the I/O. The actual byte transfer takes place under the control of hardware or firmware. Application or system code is minimally involved.
Advantages of IB Communication Stacks The above dual performance boost allows MPI or other communicating code to achieve the lowest latencies for small messages and high transfer rates, close to "wire-speed", for larger messages, All these advantages along with the supported high-speed h/w communication bandwidths have made IB the preferred communications infrastructure for high-performance computing centers. Note that currently IB links support Quad-Data Rates ("QDR") but soon are slated to get an increase to Octo-Data Rates by the IB community. This will support up to 8GB/s per direction per IB link and double this later in the future.
The IB communications stack is a multi-layer communications s/w which is illustrated in Fig. 23. As with any complex collection of h/w and s/w protocols, discussion of the stack can take place by explaining the functions of each one of the layers. MPI applications can directly use the hardware capabilities of the high-speed IB HCAs and the IB switch by invoking APIs at the upper layer of this stack.
Fig. 23 The IB/MPI software protocol stack for EOS.
At TAMU the InfiniBand fabric h/w uses the OFED V1.4.2 IB s/w stack to provide the lower level messaging capabilities to applications as well as to provide the IB management functions, such as IB initialization, route determination, node state change updates and so on. OFED is an implementation of the standard IB protocol stack which is made possible with the contributions by research labs in academia and by commercial vendors.
The OFED provides the "lower level" IB transport layer to "application" layers such as MPI. At TAMU, the primary MPI stacks are those by Intel and the OpenMPI project. In the near future other MPI stacks, including the MVAPICH2 will be deployed.
MPI Software Stack
The Message-Passing Interface (MPI) is the predominant Message Passing Programming (MPP) API for distributed memory multi-processor systems. MPI has evolved into a very mature, widely used and highly efficient MPP layer. MPI can leverage efficiently the low-latency and high-bandwidth performance of the underlying IB transport. On-going research and development effort has been continuously improving MPI's performance as perceived by the application.
On EOS, three of the most prevalent MPI implementations have been installed and are ready to be used to develop and run high-performance message passing code. Namely,
- Intel MPI versions 4 (4.0.3.8, 4.0.0.028 default, 4.0.0.025, 4.0.0.027) and 3 (3.2.2.006). Unless you have a specific reason not to, please use v4.0.0.028.
- Open MPI version 1.4.3,
- MVAPICH2 version 1.8 (and also 1.5, 1.6 and 1.7) and
- mpich2 version 1.3.1 which is not supported at the moment.
Each MPI stack has advantages in certain areas (such as, performance or programmability). Unfortunately, the environment to build, troubleshoot, tune up, and execute code varies among these stacks. In general, when we build code under MPI stack X, we should run it under the run-time environment of the same stack X.
In our performance evaluations for the MPI stacks, MVAPICH2 and Intel MPI stacks rank at the top (lowest latencies, highest bandwidths). However, OpenMPI is the best when it comes to programmability and available options controlling rank to node mapping and task / thread to core mapping and binding. When building your own MPI code, consider the stack which may provide you highest benefit for the type of application at hand. If you care most about performance consider IntelMPI or MVAPICH2. If having better control in how the ranks will map to nodes and cores is more important to you, then use OpenMPI.Note that all stacks are actively evolving and in the future the pros and cons of each stack could change.
One word of advise is that you will have to understand how each one of the MPI stacks binds by default the threads in multi-threaded (i.e., "hybrid") MPI code to cores at run-time. Multi-threaded MPI code is used when, for instance, each MPI task is also an OpemMP program or when it involves multi-threaded MKL library routines to solve a numerical problem. IntelMPI usually does "the right thing" when it binds OMP/MKL threads to cores in a hybrid MPI program. Specifically, it binds each OMP/MKL thread to a different core without over-subscribing the cores.
However, non-Intel MPI libraries used with OMP or Intel MKL threads, may bind at run-time, for each MPI task running on a node all threads numi to the same core in that node. This will result it a slowdown vs. a speedup as we increase the number of OMP/MKL threads per MPI task. As each MPI stack uses different syntax and options to specify and different mechanisms to implement task and thread to node and core mapping and binding the matter quickly becomes unwieldy when the behavior of one stack has to be replicated with another.
DDN S2A9900 Cluster Storage and GPFS File Systems
EOS is directly attached to 120 Tera-byte (un-formatted capacity) disk space on a top of the line Data-Direct Network's DDN S2A 9900 RAID array (see Fig. 20). The connection to the DDN RAID is through eight 2-GByte/sec 4x DDR IB links, with two IB links hosted by each of four I/O x3650-M2 server nodes. On the RAID side (see Fig. 24), each logical disk (LUN) is protected with two parity disks for increased recovery capabilities, in a configuration referred to as "RAID 6". The error-check and correction capability is beyond the standard N+1 RAID configuration (RAID 5).
Fig. 24 Details of the 120 Tera-Byte DDN S2A9900 RAID array.
With DDN storage, disks are arranged into logical groups of 10 disks each, called "tiers". For maximum performance the tiers are split equally for ownership across the two 9900 array controllers (called "singlets"). In our case, each tier consists of 4 Tera Bytes of data and 1 Tera Byte of Parity information in 8 plus 2 disks, respectively. This is illustrated in Fig. 24. Each singlet attaches with 4 3 Gb/s SAS channels to all the disks in the back-end. The maximum raw I/O bandwidth for the 2 S2A 9900 Singlets operating together is close to 6 GBytes/sec. The I/O bandwidth observed at the parallel file system level is above 5 GBytes/sec and it depends on the application access patterns.
The EOS cluster deploys the latest version of GPFS which is IBM's high-performing, highly-scalable clustered file system. Currently, /g/home and /g/software are hosted on one GPFS file system. /scratch is hosted on another GPFS file system. The different file systems on EOS are configured with respect to different performance objectives. /scratch consists of twenty 4 Tera-byte LUNs, whereas, /g/home and /g/software are hosted on four 4 Tera-byte LUNs for a total of 80 and 16 TeraBytes, respectively. This is illustrated in Fig. 24.
Fig. 25 Details of the 120 Tera-Byte DDN S2A9900 RAID array.
Each one of the four I/O servers is responsible for 1/4th of the total DDNS2A9900 LUNs. The paths from each GPFS client (compute or login) node to each one of th LUNs is perfectly balanced.
References
Published Literature and Presentations for Intel Nehalem Micro-Processor
- Patrick P. Gelsinger, "Intel Architecture Press Briefing," Intel Developer Forum, 17 March, 2008.
- Steve Gunther and Ronak Singhal, "Next Generation Intel� Microarchitecture (Nehalem) Family: Architectural Insights and Power Management", Intel Developer Forum, San Francisco, 2008.
- Ronak Singhal, "Inside Intel Next Generation Nehalem Microarchitecture, " Intel Developer Forum, April 1, 2008.
- Eric Delano, "Intel� Itanium� Processor (Tukwila): Quad-Core IA-64 Architecture for the Enterprise," Intel Developer Forum, San Francisco, 2008.
- Antonio Valles, Pallavi Mehrotra and Zia Ansari, "Tuning Your Software for the Next Generation Intel� Microarchitecture (Nehalem) Family", Intel Developer Forum, San Francisco, 2008.
- Stephen Thomas, "High End Desktop Platform Design Overview for the Next Generation Intel� Microarchitecture (Nehalem) Processor", Intel Developer Forum, San Francisco, 2008.
- Tom Trill and Carlos Weissenberg, "DDR3 Moving to Mainstream," Intel Developer Forum, San Francisco, 2008.
- Eric Moore and Claire Cates, "Threads : The Good, Bad, and Ugly: Improving Parallel Application Performance and Quality," Intel Developer Forum, San Francisco, 2008.
- Bob Maddox, "Overview of the Intel� QuickPath Interconnect," Intel Developer Forum, San Francisco, 2008.
- Robert Safranek, Gurbir Singh and Robert Maddox, "Intel� QuickPath Interconnect Overview," HotChips 21 − IEEE Symposium on High Performance Chips, Stanford University, Palo-Alto, CA, Aug. 2009.
- "An Introduction to the Intel� QuickPath Interconnect," Intel Corporation Whitepaper, January 2009.
- Ofri Wechsler, "Inside Intel Core Micro-Architecture," Intel Corporation Whitepaper, January 2006.
- B. Stackhouse, et al., "A 65nm 2-Billion-Transistor Quad-Core Itanium Processor," ISSCC Digest of Technical Papers, pp. 92--93, February 2008.
- Intel Xeon Processor 5500 Series Product Brief, "Intel� Xeon� Processor 5500 Series An Intelligent Approach to IT Challenges," Intel Corporation Whitepaper, March 2009.
- Intel Xeon Processor 5500 Series Product Brief, "Intel� 64 Architecture Processor Topology Enumeration," Intel Corporation Whitepaper, June 2008.
- Intel Corporation, Intel� 5520 Chipset and Intel� 5500 Chipset Datasheet, Intel Corporation Document, March 2009.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 1:Basic Architecture , Intel Corporation Document, June 2010.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 2A: Instruction Set Reference, A-M , Intel Corporation Document, June 2010.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 2B: Instruction Set Reference, N-Z , Intel Corporation Document, June 2010.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 3A: System Programming Guide, Part 1, Intel Corporation Document, June 2010.
- Intel Corporation, Intel� 64 and IA-32 Architectures Software Developer's Manual Volume 3B: System Programming Guide, Part 2, Intel Corporation Document, June 2010.
- Intel Corporation, "Intel� Turbo Boost Technology in Intel� Core(TM) Microarchitecture (Nehalem) Based Processors ," Intel Corporation Whitepaper, November 2008.
- M. Papamarcos and J. Patel, "A Low-Overhead Coherence Solution for Multiprocessors with Private Cache Memories," in Proc. 11th ISCA, pp. 348--354, 1984.