Mahout 模糊kmeans
Mahout 模糊KMeans
一、算法流程
模糊 C 均值聚类(FCM),即众所周知的模糊 ISODATA,是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。1973 年,Bezdek 提出了该算法,作为早期硬 C 均值聚类(HCM)方法的一种改进。 FCM 把 n 个向量 xi(i=1,2,...,n)分为 c 个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。FCM 使得每个给定数据点用值在 0,1 间的隶属度来确定其属于各个组的程度。与引入模糊划分相适应,隶属矩阵 U 允许有取值在 0,1 间的元素。不过,加上归一化规定,一个数据集的隶属度的和总等于 1:

那么,FCM 的价值函数(或目标函数)就是下式一般化形式:

这里 uij 介于 0,1 间;ci 为模糊组 i 的聚类中心,dij=||ci-xj||为第 i 个聚类中心与第 j 个数据点间的欧几里德距离;且 m (属于1到无穷)是一个加权指数。
构造如下新的目标函数,可求得使下式达到最小值的必要条件:其实就是拉格朗日乘子法
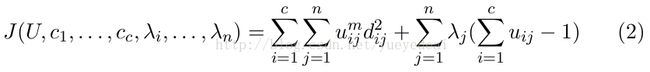
对上式所有输入参量求导,使上式达到最小的必要条件为:

和

由上述两个必要条件,模糊 C 均值聚类算法是一个简单的迭代过程。在批处理方式运行时,FCM 用下面步骤确定聚类中心 ci 和隶属矩阵 U:
步骤 1:用值在 0,1 间的随机数初始化隶属矩阵 U。
步骤 2:用式(3)计算 c 个聚类中心ci,i=1,...,c。
步骤 3:根据式(1)计算价值函数。如果它小于某个确定的阀值,或它相对上次价
值函数值的改变量小于某个阀值,则算法停止。
步骤 4:用(4)计算新的 U 矩阵和。返回步骤 2。
上述算法也可以先初始化聚类中心,然后再执行迭代过程。由于不能确保 FCM 收敛于一个最优解。算法的性能依赖于初始聚类中心。因此,我们要么用另外的快速算法确定初始聚类中心,要么每次用不同的初始聚类中心启动该算法,多次运行 FCM。
二、MapReduce实现
(一)初始化中心
RandomSeedGenerator 将输入的向量随机选择K个输出到HDFS作为Fuzzy Kmeans 聚类的初始中心点。
(二) 簇定义
簇Cluster是一个实体,保存该簇的关键信息。
private int id; 簇编号
核心参数:计算完数据后最终的簇属性
private long numPoints; 簇中点的个数
private Vector center; 中心向量 center=
private Vector radius; 半径向量 radius =
调整参数:簇中加入一个点后调整的参数
private double s0; s0= 权重和。对该算法
private Vector s1; s1= x 为point,w为权重,对该算法。
private Vector s2 ; s2= x 为point,w为权重,对该算法。
(三)寻找中心点
FCM算法用一个Job寻找cluster的中心点。在map的初始化节点,加载初始化(或上一轮迭代的结果)中心点。在map中计算point 和每一个簇的亲和度。在combiner计算同一个cluster的参数,该过程只能计算同一cluster的局部信息。在reduce中首先计算同一个cluster的全局参数,然后计算该cluster是否收敛,输出cluster。
在HDFS中读取所有cluster,只要有一个cluster没有收敛,或者没有达到设定的迭代次数,则继续执行Job。直到符合以上两个条件。
Map:
List<SoftCluster>clusters = new ArrayList<SoftCluster>()
setUp(){
加载初始化cluster中心或者上一轮cluster中心点,填充clusters。
}
Map(WritableComparable<?>key, VectorWritable point){
For(cluster :clusters){
计算point和每一个cluster的亲和度。
S0=
S1=point
S2=
}
}
Combier:
合并同一簇局部参数,其中。s0= , s1=,s2=。
Reduce:
1. 合并同一簇的全局参数,其中。s0= , s1=,s2=。计算中心点等参数。
2.计算簇是否收敛。当前的中心点和之前cluster的中心点的距离<=收敛值,则收敛,否则为不收敛。
3.计算参数,点个数,中心向量,半径等。计算公式参看上文。
(四)划分数据
上面的Job收敛之后,得到了k个cluster的中心,划分数据就是把向量划分到cluster中。过程相对简单。
1. 计算point和所有cluster的距离,计算亲和向量。
2. 将点归属到cluster中,这里面有两个策略,一个是划分到亲和度最大的簇中,另外一个是划分到大于阈值的所有簇中。
3. 输出key: 簇id ,value :WeightedVectorWritable(pdf,point) 。Pdf为亲和度。
三、API说明
API
| KMeansDriver.main(args); |
|
|||
| --input(-i) |
输入路径 |
|
||
| --outpu(-o) |
输出路径 |
|
||
| --distanceMeasure(-dm) |
距离类权限命名,如“org.apache.mahout.common.distance.Cosine DistanceMeasure” |
|
||
| --clusters(-c) |
中心点存储路径,如果该路径下没有中心点,则随机生成并写入该目录 |
|
||
| --numClusters(-k) |
簇个数 |
|
||
| --convergenceDelta(-cd) |
收敛值 |
|
||
| --maxIter(-x) |
最大迭代次数 |
|
||
| --m(-m) |
>1的值 |
|
||
| --emitMostLikely (-e) |
是否提交最大似然 |
|
|
|
| --overwrite(-ow) |
是否覆盖上次操作 |
|
||
| --clustering(-cl) |
是否执行聚类 |
|
||
| --method(-xm) |
默认”mapreduce”,或”sequential” |
|
||
示例
| String [] args ={"--input","vector/tfidf-vectors", "--output","fkmeans", "--distanceMeasure","org.apache.mahout.common.distance. CosineDistanceMeasure", "--clusters","fkmeans", "--numClusters","3", "--convergenceDelta","0.1", "--maxIter","5", "--overwrite", "-m","3", "--clustering", "--emitMostLikely" };
FuzzyKMeansDriver.main(args); |
输出
| 结果文件 |
Key类型 |
Value类型 |
说明 |
| clusters-* |
类id (org.apache.hadoop.io.Text) |
类中心 (org.apache.mahout. clustering.kmeans.Cluster) |
每条记录以类id和类中心表示一个类别 |
| clusteredPoints |
类id (org.apache.hadoop.io.IntWritable) |
文档向量 (org.apache. mahout.clustering.WeightedVectorWritable) |
每条记录中,文档向量代表文档,类id代表该文档所属类别 |
注:clusters-*中*代表数字,第i次迭代产生的类信息即为clusters-i
四、参考文献
1.《web 数据挖掘》
2.《模式分类》
3.博客 http://home.deib.polimi.it/matteucc/Clustering/tutorial_html/cmeans.html
4.博客http://www.cs.princeton.edu/courses/archive/fall08/cos436/Duda/C/fk_means.htm