Linux进程调度(3):进程切换分析
3、调度函数schedule()分析
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu)))
该函数通过向上加偏移的方式得到rq,这里可以看出runqueues为一个rq结构的数组,cpu为数组下标。
(2)删除切换出去的进程:调用deactivate_task从运行队列中删除prev进程。根据调度类的不同实现不同,对CFS,deactivate_task调用dequeue_task_fair完成进程删除。deactive_task()如下:
(3)将切换出去进程插到队尾:调用put_prev_task(),将当前进程,也就是被切换出去的进程重新插入到各自的运行队列中,对于CFS算法插入到红黑树的合适位置上,对于实时调度插入到同一个优先级队列的链表尾部。
(4)选择下一个要运行的进程:调用pick_next_task(),从运行队列中选择下一个要运行的进程。对CFS,执行的是pick_next_task_fair。它会选择红黑树最左叶子节点的进程(在所有进程中它的vruntime值最小)。pick_next_task()如下:
(5)调度信息更新:调用kernel/sched_stats.h中的sched_info_switch(),以更新切换出去和进来进程以及对应rq的相关变量。该函数最终是调用__sched_info_switch()完成工作。如下:
switch_to()用于切换进程的寄存器状态和栈,实现也与体系结构有关,对x86,在arch/x86/include/asm/system.h中。该函数被定义为一个宏,如下:
回到context_switch(),在完成mm、寄存器和栈的切换之后,context_swith最后调用kernel/sched.c中的finish_task_switch()完成进程切换后的一些清理工作。例如,如果是因为进程退出(成为TASK_DEAD状态)而导致进程调度,则需要释放退出进程的PCB,由finish_task_switch()调用put_task_struct()完成这项工作。put_task_struct()在include/linux/sched.h中,它直接调用kernel/fork.c中的__put_task_struct(),清理工作的调用链为__put_task_struct()--->free_task()--->free_task_struct()。在fork.c中,free_task_struct()工作直接由kmem_cache_free()函数完成,如下:
# define free_task_struct(tsk) kmem_cache_free(task_struct_cachep, (tsk))
context_switch执行完后,schedule()的工作基本就完成了。至此,进程调度完成,新的进程被调入CPU运行。
从以上讨论看出,CFS对以前的调度器进行了很大改动。用红黑树代替优先级数组;用完全公平的策略代替动态优先级策略;引入了模块管理器;它修改了原来Linux2.6.0调度器模块70%的代码。结构更简单灵活,算法适应性更高。相比于RSDL,虽然都基于完全公平的原理,但是它们的实现完全不同。相比之下,CFS更加清晰简单,有更好的扩展性。
CFS还有一个重要特点,即调度粒度小。CFS之前的调度器中,除了进程调用了某些阻塞函数而主动参与调度之外,每个进程都只有在用完了时间片或者属于自己的时间配额之后才被抢占。而CFS则在每次tick都进行检查,如果当前进程不再处于红黑树的左边,就被抢占。在高负载的服务器上,通过调整调度粒度能够获得更好的调度性能。
进程调度的完整流程(使用CFS算法)总结如下:
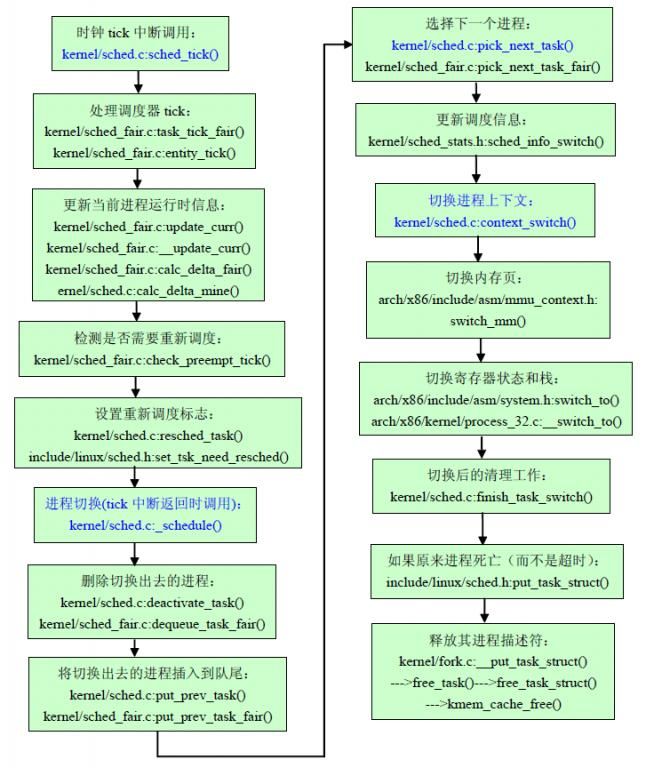
图1 Linux进程调度执行流程
当kernel/sched.c:sched_tick()执行完,并且时钟中断返回时,就会调用kernel/sched.c:schedule()完成进程切换。我们也可以显示调用schedule(),例如在前面“Linux进程管理“的介绍中,进程销毁的do_exit()最后就直接调用schedule(),以切换到下一个进程。
schedule()是内核和其他部分用于调用进程调度器的入口,选择哪个进程可以运行,何时将其投入运行。schedule通常都和一个具体的调度类相关联,例如对CFS会关联到调度类fair_sched_class,对实时调度会关到rt_sched_class,也就是说,它会找到一个最高优先级的调度类,后者有自己的可运行队列,然后问后者谁才是下一个该运行的进程。从kernel/sched.c:sched_init()中我们可以看到有一行为"current->sched_class = &fair_sched_class",可见它初始时使用的是CFS的调度类。schedule函数唯一重要的事情是,它会调用pick_next_task。schedule()代码如下:
asmlinkage void __sched schedule(void)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
need_resched:
preempt_disable();
cpu = smp_processor_id(); /* 获取当前cpu */
rq = cpu_rq(cpu); /* 得到指定cpu的rq */
rcu_sched_qs(cpu);
prev = rq->curr; /* 当前的运行进程 */
switch_count = &prev->nivcsw; /* 进程切换计数 */
release_kernel_lock(prev);
need_resched_nonpreemptible:
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
spin_lock_irq(&rq->lock);
update_rq_clock(rq); /* 更新rq的clock属性 */
clear_tsk_need_resched(prev); /* 清楚prev进程的调度位 */
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
if (unlikely(signal_pending_state(prev->state, prev)))
prev->state = TASK_RUNNING;
else /* 从运行队列中删除prev进程,根据调度类的不同实现不同,
对CFS,deactivate_task调用dequeue_task_fair完成进程删除 */
deactivate_task(rq, prev, 1);
switch_count = &prev->nvcsw;
}
pre_schedule(rq, prev); /* 现只对实时进程有用 */
if (unlikely(!rq->nr_running))
idle_balance(cpu, rq);
put_prev_task(rq, prev); /* 将切换出去进程插到队尾 */
next = pick_next_task(rq); /* 选择下一个要运行的进程 */
if (likely(prev != next)) {
sched_info_switch(prev, next); /* 更新进程的相关调度信息 */
perf_event_task_sched_out(prev, next, cpu);
rq->nr_switches++; /* 切换次数记录 */
rq->curr = next;
++*switch_count;
/* 进程上下文切换 */
context_switch(rq, prev, next); /* unlocks the rq */
/*
* the context switch might have flipped the stack from under
* us, hence refresh the local variables.
*/
cpu = smp_processor_id();
rq = cpu_rq(cpu);
} else
spin_unlock_irq(&rq->lock);
post_schedule(rq); /* 对于实时进程有用到 */
if (unlikely(reacquire_kernel_lock(current) < 0))
goto need_resched_nonpreemptible;
preempt_enable_no_resched();
if (need_resched())
goto need_resched;
}
EXPORT_SYMBOL(schedule); (1)清除调度位:如果之前设置了need_resched标志,则需要重新调度进程。先获取cpu和rq,当前进程成为prev进程,清除它的调度位。cpu_rq()函数在sched.c中定义为一个宏:
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu)))
该函数通过向上加偏移的方式得到rq,这里可以看出runqueues为一个rq结构的数组,cpu为数组下标。
(2)删除切换出去的进程:调用deactivate_task从运行队列中删除prev进程。根据调度类的不同实现不同,对CFS,deactivate_task调用dequeue_task_fair完成进程删除。deactive_task()如下:
static void deactivate_task(struct rq *rq, struct task_struct *p, int sleep)
{
if (task_contributes_to_load(p))
rq->nr_uninterruptible++;
dequeue_task(rq, p, sleep); /* 具体操作 */
dec_nr_running(rq); /* rq中当前进程的运行数减一 */
}
static void dequeue_task(struct rq *rq, struct task_struct *p, int sleep)
{
if (sleep) { /* 如果sleep不为0,更新调度实体se中的相关变量 */
if (p->se.last_wakeup) {
update_avg(&p->se.avg_overlap,
p->se.sum_exec_runtime - p->se.last_wakeup);
p->se.last_wakeup = 0;
} else {
update_avg(&p->se.avg_wakeup,
sysctl_sched_wakeup_granularity);
}
}
/* 更新进程的sched_info数据结构中相关属性 */
sched_info_dequeued(p);
/* 调用具体调度类的函数从它的运行队列中删除 */
p->sched_class->dequeue_task(rq, p, sleep);
p->se.on_rq = 0;
} 对CFS,sched_class会关联到kernel/sched_fair.c中的fair_sched_class,因此最终是调用dequeue_task_fair从运行队列中删除切换出去的进程。dequeue_task_fair在前面已分析过。
(3)将切换出去进程插到队尾:调用put_prev_task(),将当前进程,也就是被切换出去的进程重新插入到各自的运行队列中,对于CFS算法插入到红黑树的合适位置上,对于实时调度插入到同一个优先级队列的链表尾部。
(4)选择下一个要运行的进程:调用pick_next_task(),从运行队列中选择下一个要运行的进程。对CFS,执行的是pick_next_task_fair。它会选择红黑树最左叶子节点的进程(在所有进程中它的vruntime值最小)。pick_next_task()如下:
static inline struct task_struct *
pick_next_task(struct rq *rq)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
if (likely(rq->nr_running == rq->cfs.nr_running)) {
p = fair_sched_class.pick_next_task(rq);
if (likely(p))
return p;
}
class = sched_class_highest;
for ( ; ; ) { /* 对每一个调度类 */
/* 调用该调度类中的函数,找出下一个task */
p = class->pick_next_task(rq);
if (p)
return p;
/*
* Will never be NULL as the idle class always
* returns a non-NULL p:
*/
class = class->next; /* 访问下一个调度类 */
}
} 该函数以优先级为序,从高到低,依次检查每个调度类并且从高优先级的调度类中,选择最高优先级的进程。前面的优化是说如果所有的进程都在CFS调度类中,则可以直接调用fair_sched_class中的pick_next_task_fair函数找出下一个要运行的进程。这个函数前面分析过。
(5)调度信息更新:调用kernel/sched_stats.h中的sched_info_switch(),以更新切换出去和进来进程以及对应rq的相关变量。该函数最终是调用__sched_info_switch()完成工作。如下:
static inline void
__sched_info_switch(struct task_struct *prev, struct task_struct *next)
{
struct rq *rq = task_rq(prev);
/*
* prev now departs the cpu. It's not interesting to record
* stats about how efficient we were at scheduling the idle
* process, however.
*/
if (prev != rq->idle) /* 如果被切换出去的进程不是idle进程 */
sched_info_depart(prev); /* 更新prev进程和他对应rq的相关变量 */
if (next != rq->idle) /* 如果切换进来的进程不是idle进程 */
sched_info_arrive(next); /* 更新next进程和对应队列的相关变量 */
}
static inline void sched_info_depart(struct task_struct *t)
{
/* 计算进程在rq中运行的时间长度 */
unsigned long long delta = task_rq(t)->clock -
t->sched_info.last_arrival;
/* 更新RunQueue中的Task所得到CPU执行时间的累加值 */
rq_sched_info_depart(task_rq(t), delta);
/* 如果被切换出去进程的状态是运行状态
那么将进程sched_info.last_queued设置为rq的clock
last_queued为最后一次排队等待运行的时间 */
if (t->state == TASK_RUNNING)
sched_info_queued(t);
}
static void sched_info_arrive(struct task_struct *t)
{
unsigned long long now = task_rq(t)->clock, delta = 0;
if (t->sched_info.last_queued) /* 如果被切换进来前在运行进程中排队 */
delta = now - t->sched_info.last_queued; /* 计算排队等待的时间长度 */
sched_info_reset_dequeued(t); /* 因为进程将被切换进来运行,设定last_queued为0 */
t->sched_info.run_delay += delta; /* 更新进程在运行队列里面等待的时间 */
t->sched_info.last_arrival = now; /* 更新最后一次运行的时间 */
t->sched_info.pcount++; /* cpu上运行的次数加一 */
/* 更新rq中rq_sched_info中的对应的变量 */
rq_sched_info_arrive(task_rq(t), delta);
} (6)上下文切换:调用kernel/sched.c中的context_switch()来完成进程上下文的切换,包括切换到新的内存页、寄存器状态和栈,以及切换后的清理工作(例如如果是因为进程退出而导致进程调度,则需要释放退出进程的进程描述符PCB)。schedule()的大部分核心工作都在这个函数中完成。如下:
static inline void
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
trace_sched_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
if (unlikely(!mm)) { /* 如果被切换进来的进程的mm为空 */
next->active_mm = oldmm; /* 将共享切换出去进程的active_mm */
atomic_inc(&oldmm->mm_count); /* 有一个进程共享,所有引用计数加一 */
/* 将per cpu变量cpu_tlbstate状态设为LAZY */
enter_lazy_tlb(oldmm, next);
} else /* 如果mm不为空,那么进行mm切换 */
switch_mm(oldmm, mm, next);
if (unlikely(!prev->mm)) { /* 如果切换出去的mm为空,从上面
可以看出本进程的active_mm为共享先前切换出去的进程
的active_mm,所有需要在这里置空 */
prev->active_mm = NULL;
rq->prev_mm = oldmm; /* 更新rq的前一个mm结构 */
}
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
#ifndef __ARCH_WANT_UNLOCKED_CTXSW
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
#endif
/* 这里切换寄存器状态和栈 */
switch_to(prev, next, prev);
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the 'rq' on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
} 该函数调用switch_mm()切换进程的mm,调用switch_to()切换进程的寄存器状态和栈,调用finish_task_switch()完成切换后的清理工作。
switch_mm()的实现与体系结构相关,对x86,在arch/x86/include/asm/mmu_context.h中,如下:
static inline void switch_mm(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
unsigned cpu = smp_processor_id();
if (likely(prev != next)) {
#ifdef CONFIG_SMP
/* 设置per cpu变量tlb */
percpu_write(cpu_tlbstate.state, TLBSTATE_OK);
percpu_write(cpu_tlbstate.active_mm, next);
#endif
/* 将要被调度运行进程拥有的内存描述结构
的CPU掩码中当前处理器号对应的位码设置为1 */
cpumask_set_cpu(cpu, mm_cpumask(next));
/* Re-load page tables */
load_cr3(next->pgd); /* 将切换进来进程的pgd load到cr3寄存器 */
/* 将被替换进程使用的内存描述结构的CPU
掩码中当前处理器号对应的位码清0 */
cpumask_clear_cpu(cpu, mm_cpumask(prev));
/*
* load the LDT, if the LDT is different:
*/
if (unlikely(prev->context.ldt != next->context.ldt))
load_LDT_nolock(&next->context);
}
#ifdef CONFIG_SMP
else { /* 如果切换的两个进程相同 */
percpu_write(cpu_tlbstate.state, TLBSTATE_OK);
BUG_ON(percpu_read(cpu_tlbstate.active_mm) != next);
if (!cpumask_test_and_set_cpu(cpu, mm_cpumask(next))) {
/* We were in lazy tlb mode and leave_mm disabled
* tlb flush IPI delivery. We must reload CR3
* to make sure to use no freed page tables.
*/
load_cr3(next->pgd);
load_LDT_nolock(&next->context);
}
}
#endif
} 该函数主要工作包括设置per cpu变量tlb、设置新进程的mm的CPU掩码位、重新加载页表、清除原来进程的mm的CPU掩码位。
switch_to()用于切换进程的寄存器状态和栈,实现也与体系结构有关,对x86,在arch/x86/include/asm/system.h中。该函数被定义为一个宏,如下:
#define switch_to(prev, next, last) \
do { \
/* \
* Context-switching clobbers all registers, so we clobber \
* them explicitly, via unused output variables. \
* (EAX and EBP is not listed because EBP is saved/restored \
* explicitly for wchan access and EAX is the return value of \
* __switch_to()) \
*/ \
unsigned long ebx, ecx, edx, esi, edi; \
\
asm volatile("pushfl\n\t" /* save flags */ \
"pushl %%ebp\n\t" /* save EBP */ \
"movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
"movl %[next_sp],%%esp\n\t" /* restore ESP */ \
"movl $1f,%[prev_ip]\n\t" /* save EIP */ \
/* 将next_ip入栈,下面用jmp跳转,这样
返回到标号1时就切换过来了 */
"pushl %[next_ip]\n\t" /* restore EIP */ \
__switch_canary \
"jmp __switch_to\n" /* 跳转到C函数__switch_to,执行完后返回到下面的标号1处 */ \
"1:\t" \
"popl %%ebp\n\t" /* restore EBP */ \
"popfl\n" /* restore flags */ \
\
/* output parameters */ \
: [prev_sp] "=m" (prev->thread.sp), \
[prev_ip] "=m" (prev->thread.ip), \
"=a" (last), \
\
/* clobbered output registers: */ \
"=b" (ebx), "=c" (ecx), "=d" (edx), \
"=S" (esi), "=D" (edi) \
\
__switch_canary_oparam \
\
/* input parameters: */ \
: [next_sp] "m" (next->thread.sp), \
[next_ip] "m" (next->thread.ip), \
\
/* regparm parameters for __switch_to(): */ \
[prev] "a" (prev), \
[next] "d" (next) \
\
__switch_canary_iparam \
\
: /* reloaded segment registers */ \
"memory"); \
} while (0) 该函数用汇编代码保持各种寄存器的值,然后通过jmp调用C函数__switch_to,完成寄存器状态和栈的切换。对32位系统,__switch_to()函数在arch/x86/kernel/process_32.c中,如下:
__notrace_funcgraph struct task_struct *
__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread,
*next = &next_p->thread;
int cpu = smp_processor_id();
/* init_tss为一个per cpu变量 */
struct tss_struct *tss = &per_cpu(init_tss, cpu);
bool preload_fpu;
/* never put a printk in __switch_to... printk() calls wake_up*() indirectly */
/*
* If the task has used fpu the last 5 timeslices, just do a full
* restore of the math state immediately to avoid the trap; the
* chances of needing FPU soon are obviously high now
*/
preload_fpu = tsk_used_math(next_p) && next_p->fpu_counter > 5;
__unlazy_fpu(prev_p); /* 保存FPU寄存器 */
/* we're going to use this soon, after a few expensive things */
if (preload_fpu)
prefetch(next->xstate);
/*
* 重新载入esp0:把next_p->thread.esp0装入对应于本地cpu的tss的esp0
* 字段;任何由sysenter汇编指令产生的从用户态
* 到内核态的特权级转换将把这个地址拷贝到esp寄存器中
*/
load_sp0(tss, next);
/*
* Save away %gs. No need to save %fs, as it was saved on the
* stack on entry. No need to save %es and %ds, as those are
* always kernel segments while inside the kernel. Doing this
* before setting the new TLS descriptors avoids the situation
* where we temporarily have non-reloadable segments in %fs
* and %gs. This could be an issue if the NMI handler ever
* used %fs or %gs (it does not today), or if the kernel is
* running inside of a hypervisor layer.
*/
lazy_save_gs(prev->gs);
/*
* 装载每个线程的线程局部存储描述符:把next进程使用的线程局部存储(TLS)段
* 装入本地CPU的全局描述符表;三个段选择符保存在进程描述符
* 内的tls_array数组中
*/
load_TLS(next, cpu);
/*
* Restore IOPL if needed. In normal use, the flags restore
* in the switch assembly will handle this. But if the kernel
* is running virtualized at a non-zero CPL, the popf will
* not restore flags, so it must be done in a separate step.
*/
if (get_kernel_rpl() && unlikely(prev->iopl != next->iopl))
set_iopl_mask(next->iopl);
/*
* Now maybe handle debug registers and/or IO bitmaps
*/
if (unlikely(task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV ||
task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT))
__switch_to_xtra(prev_p, next_p, tss);
/* If we're going to preload the fpu context, make sure clts
is run while we're batching the cpu state updates. */
if (preload_fpu)
clts();
/*
* Leave lazy mode, flushing any hypercalls made here.
* This must be done before restoring TLS segments so
* the GDT and LDT are properly updated, and must be
* done before math_state_restore, so the TS bit is up
* to date.
*/
arch_end_context_switch(next_p);
if (preload_fpu)
__math_state_restore(); /* 恢复FPU寄存器 */
/*
* Restore %gs if needed (which is common)
*/
if (prev->gs | next->gs)
lazy_load_gs(next->gs);
percpu_write(current_task, next_p);
return prev_p;
}
主要工作包括保存FPU寄存器、重新装载esp0、装载每个线程的TLS段、恢复FPU寄存器等。__unlazy_fpu()函数在arch/x86/include/asm/i387.h中,如下:
static inline void __unlazy_fpu(struct task_struct *tsk)
{
/* 如果进程使用了FPU/MMX/SSE或SSE2指令 */
if (task_thread_info(tsk)->status & TS_USEDFPU) {
__save_init_fpu(tsk); /* 保存相关的硬件上下文 */
stts();
} else
tsk->fpu_counter = 0;
}
/*
* These must be called with preempt disabled
*/
static inline void __save_init_fpu(struct task_struct *tsk)
{
/* 如果CPU使用SSE/SSE2扩展 */
if (task_thread_info(tsk)->status & TS_XSAVE) {
struct xsave_struct *xstate = &tsk->thread.xstate->xsave;
struct i387_fxsave_struct *fx = &tsk->thread.xstate->fxsave;
xsave(tsk);
/*
* xsave header may indicate the init state of the FP.
*/
if (!(xstate->xsave_hdr.xstate_bv & XSTATE_FP))
goto end;
if (unlikely(fx->swd & X87_FSW_ES))
asm volatile("fnclex");
/*
* we can do a simple return here or be paranoid :)
*/
goto clear_state;
}
/* Use more nops than strictly needed in case the compiler
varies code */
alternative_input(
"fnsave %[fx] ;fwait;" GENERIC_NOP8 GENERIC_NOP4,
"fxsave %[fx]\n"
"bt $7,%[fsw] ; jnc 1f ; fnclex\n1:",
X86_FEATURE_FXSR,
[fx] "m" (tsk->thread.xstate->fxsave),
[fsw] "m" (tsk->thread.xstate->fxsave.swd) : "memory");
clear_state:
/* AMD K7/K8 CPUs don't save/restore FDP/FIP/FOP unless an exception
is pending. Clear the x87 state here by setting it to fixed
values. safe_address is a random variable that should be in L1 */
alternative_input(
GENERIC_NOP8 GENERIC_NOP2,
"emms\n\t" /* clear stack tags */
"fildl %[addr]", /* set F?P to defined value */
X86_FEATURE_FXSAVE_LEAK,
[addr] "m" (safe_address));
end:
task_thread_info(tsk)->status &= ~TS_USEDFPU; /* 重置TS_USEDFPU标志 */
} 包含在thread_info描述符的status字段中的TS_USEDFPU标志,表示进程在当前执行的过程中是否使用过FPU/MMU/XMM寄存器。在__unlazy_fpu中可以看到,如果进程执行过程中使用了FPU/MMX/SSE或SSE2指令,则内核必须保存相关的硬件上下文,这由__save_init_fpu()完成,它会调用xsave()保存硬件相关的状态信息,注意保存完之后要重置TS_USEDFPU标志。
回到context_switch(),在完成mm、寄存器和栈的切换之后,context_swith最后调用kernel/sched.c中的finish_task_switch()完成进程切换后的一些清理工作。例如,如果是因为进程退出(成为TASK_DEAD状态)而导致进程调度,则需要释放退出进程的PCB,由finish_task_switch()调用put_task_struct()完成这项工作。put_task_struct()在include/linux/sched.h中,它直接调用kernel/fork.c中的__put_task_struct(),清理工作的调用链为__put_task_struct()--->free_task()--->free_task_struct()。在fork.c中,free_task_struct()工作直接由kmem_cache_free()函数完成,如下:
# define free_task_struct(tsk) kmem_cache_free(task_struct_cachep, (tsk))
context_switch执行完后,schedule()的工作基本就完成了。至此,进程调度完成,新的进程被调入CPU运行。
从以上讨论看出,CFS对以前的调度器进行了很大改动。用红黑树代替优先级数组;用完全公平的策略代替动态优先级策略;引入了模块管理器;它修改了原来Linux2.6.0调度器模块70%的代码。结构更简单灵活,算法适应性更高。相比于RSDL,虽然都基于完全公平的原理,但是它们的实现完全不同。相比之下,CFS更加清晰简单,有更好的扩展性。
CFS还有一个重要特点,即调度粒度小。CFS之前的调度器中,除了进程调用了某些阻塞函数而主动参与调度之外,每个进程都只有在用完了时间片或者属于自己的时间配额之后才被抢占。而CFS则在每次tick都进行检查,如果当前进程不再处于红黑树的左边,就被抢占。在高负载的服务器上,通过调整调度粒度能够获得更好的调度性能。
进程调度的完整流程(使用CFS算法)总结如下:
fork() --->kernel/sched_fair.c:enqueue_task_fair() 新进程最后进入红黑树队列 kernel/sched.c:sched_tick() 被时钟tick中断直接调用 --->sched_class->task_tick()==>kernel/sched_fair.c:task_tick_fair() --->kernel/sched_fair.c:entity_tick() 处理tick中断 --->update_curr() 更新当前进程的运行时统计信息 --->__update_curr() 更新进程的vruntime --->calc_delta_fair() 计算负载权重值 --->kernel/sched.c:calc_delta_mine() 修正delta值 --->check_preempt_tick() 检测是否需要重新调度 --->kernel/sched.c:resched_task() 设置need_resched标志 --->include/linux/sched.h:set_tsk_need_resched(p) 完成设置工作 kernel/sched.c:schedule() 中断返回时调用,完成进程切换 --->include/linux/sched.h:clear_tsk_need_resched() 清除调度位 --->kernel/sched.c:deactivate_task() 删除切换出去的进程(pre进程) --->dequeue_task() --->kernel/sched_fair.c:dequeue_task_fair() 从红黑树中删除pre进程 --->dequeue_entity() --->__dequeue_entity() --->lib/rbtree.c:rb_erase() 删除pre进程 --->dec_nr_running() 递减nr_running --->kernel/sched.c:put_prev_task() 将切换出去的进程插入到队尾 --->kernel/sched_fair.c:put_prev_task_fair() --->put_prev_entity() --->__enqueue_entity() --->搜索红黑树,找到插入位置并插入 --->缓存最左边的节点进程 --->kernel/sched.c:pick_next_task() 选择下一个要运行的进程 --->kernel/sched_fair.c:pick_next_task_fair() --->pick_next_entity() --->__pick_next_entity() --->include/linux/rbtree.h:rb_entry(left,...) 返回红黑树最左边的节点进程 --->include/linux/kernel.h:container_of() --->kernel/sched_stats.h:sched_info_switch() 更新调度信息(rq相关变量) --->sched_info_depart() --->sched_info_arrive() --->kernel/sched.c:context_switch() 切换进程上下文 --->arch/x86/include/asm/mmu_context.h:switch_mm() 切换内存页 --->设置新进程的CPU掩码位,重新加载页表等 --->arch/x86/include/asm/system.h:switch_to() 切换寄存器状态和栈 --->arch/x86/kernel/process_32.c:__switch_to() --->arch/x86/include/asm/i387.h:__unlazy_fpu() 保存FPU寄存器 --->__save_init_fpu() 若使用了FPU/MMX/SSE或SSE2指令则保存相关硬件上下文 --->xsave() --->arch/x86/include/asm/paravirt.h:load_sp0() 重新载入esp0 --->arch/x86/include/asm/paravirt.h:load_TLS() 加载线程的TLS段 --->__math_state_restore() 恢复FPU寄存器 --->kernel/sched.c:finish_task_switch() 完成切换后的清理工作 --->include/linux/sched.h:put_task_struct() 如果原来进程死亡(而不是运行超时) 需要释放它的PCB --->kernel/fork.c:__put_task_struct() --->free_task() -->free_task_struct() --->kmem_cache_free() 释放原来进程的PCB
下面是基本的执行流程图:
图1 Linux进程调度执行流程