vl_feat库中的k-means聚类
最近准备好好看一下vl_feat库。
首先简单介绍一下vl_feat库(http://www.vlfeat.org/index.html)。vl_feat库是用C语言开发的一个开源的计算机视觉的库,它比opencv要小,但是实现了一些比较常见的视觉方面的算法(包括HOG,SIFT, MSER, k-means, hierarchical k-means, agglomerative information bottleneck, SLIC superpixels, and quick shift)。它不仅提供了C的API还提供了Matlab的API和toolbox,这也可能是与opencv最大的不同吧。它的主要作者是Andrea Vedaldi(http://www.robots.ox.ac.uk/~vedaldi/),他现在是牛津大学的老师,是计算机视觉方面的一个牛人。
vl_feat库中的聚类主要包括了两种:k-mean clustering和integer k-means(还有层次化的整型k-means,HIKM)。
采用vl_feat进行聚类,一般包括以下步骤:
- 创建一个k-means聚类对象,设置具体聚类使用的方法(vl_feat库实现了3种聚类方法:Lloyd、Elkan和ANN,其中,Elkan是Lloyd的加速版本,ANN (approximate nearest neighbor) 对integer k-means无效)
- 初始化种子点
- 进行聚类
首先介绍一下integer k-means clustering (ikmeans)。整型k-means内容主要来自http://www.cnblogs.com/smyb000/archive/2012/08/28/k-means_cluster_via_vlfeat.html,作者也给出了一个为什么定义整型k-means的解释“IKmeans聚类数据的类型是unsigned char型。虽然这看上去有局限性,但对于图像的特征聚类,算法有很高的准确性,因为在高维空间中(例如SIFT特征,128维),UCHAR型已经足够。”。
针对上面一般步骤,ikmeans实现时具体如下:
- 利用 vl_ikm_new(VL_IKM_ELKAN) 创建一个ikmeans聚类对象,里面定义了聚类所需的一些数据结构(例如聚类中心,数据维度,聚类中心数等)
- 利用 vl_ikm_init_rand() 随机初始化种子点
- 利用 vl_ikm_train() 进行聚类
void vlikmeans()
{
int row = 255;
int col = 255;
Mat show1 = Mat::zeros(row, col, CV_8UC3);
Mat show2 = show1.clone();
int data_num = 5000;
int data_dim = 2;
vl_uint8 * data = new vl_uint8[data_dim * data_num];
for (int i = 0; i < data_num; i++)
{
vl_uint8 x = data[i * data_dim] = rand() % col;
vl_uint8 y = data[i * data_dim + 1] = rand() % row;
circle(show1, Point(x, y), 2, Scalar(255, 255, 255));
}
namedWindow("random_points");
imshow("random_points", show1);
waitKey(0);
VlIKMFilt * kmeans = vl_ikm_new(VL_IKM_ELKAN);
vl_uint k = 3;
vl_ikm_init_rand(kmeans, data_dim, k);
vl_ikm_train(kmeans, data, data_num);
vl_uint * label = new vl_uint[data_num];
vl_ikm_push(kmeans, label, data, data_num);
for (int i = 0; i < data_num; i++)
{
vl_uint8 x = data[i * data_dim];
vl_uint8 y = data[i * data_dim + 1];
switch (label[i])
{
case 0:
circle(show2, Point(x, y), 2, Scalar(255, 0, 0));
break;
case 1:
circle(show2, Point(x, y), 2, Scalar(0, 255, 0));
break;
case 2:
circle(show2, Point(x, y), 2, Scalar(0, 0, 255));
break;
}
}
const vl_ikm_acc *centers = vl_ikm_get_centers(kmeans);
circle(show2, Point(centers[0], centers[1]), 4, Scalar(255, 255, 0), 4);
circle(show2, Point(centers[2], centers[3]), 4, Scalar(255, 255, 0), 4);
circle(show2, Point(centers[4], centers[5]), 4, Scalar(255, 255, 0), 4);
namedWindow("vlikmeans_result");
imshow("vlikmeans_result", show2);
waitKey(0);
centers = NULL;
vl_ikm_delete(kmeans);
delete[] label;
label = NULL;
delete []data;
data = NULL;
}
在函数退出之前,要养成将创建的数据结构进行释放的习惯,vl_feat也定义了释放的函数。

- 利用 vl_kmeans_new() 创建一个聚类的对象,它包含了两个参数:数据类型和具体比较的相似度计算方法(距离函数)
- 利用 vl_kmeans_set_algorithm() 设定需要使用的聚类方法(Lloyd、Elkan还是ANN)
- 利用 vl_kmeans_init_centers_plus_plus() 或者 vl_kmeans_set_centers() 或者 vl_kmeans_init_centers_with_rand_data() 初始化聚类中心 (由于要与matlab的聚类结果进行对比,实现时采用的是 vl_kmeans_set_centers())
- 利用 vl_kmeans_cluster() 进行聚类
void vlkmeans()
{
int data_num = 10;
int data_dim = 2;
int k = 2;
float *data = new float[data_dim * data_num];
cout << "Points to clustering: " << endl;
for (int i = 0; i < data_num; i++)
{
data[i * data_dim] = (float)rand()/3.0;
data[i * data_dim + 1] = (float)rand()/3.0;
cout << data[i * data_dim] << "\t" << data[i * data_dim + 1] << endl;
}
float * init_centers = new float[data_dim * k];
cout << "Initial centers: " << endl;
for (int i = 0; i < k; i++)
{
init_centers[i * data_dim] = (float)rand()/3.0;
init_centers[i * data_dim + 1] = (float)rand()/3.0;
cout << init_centers[i * data_dim] << "\t" << init_centers[i * data_dim + 1] << endl;
}
VlKMeans * fkmeans = vl_kmeans_new(VL_TYPE_FLOAT, VlDistanceL2);
vl_kmeans_set_algorithm(fkmeans, VlKMeansElkan);
// vl_kmeans_init_centers_plus_plus(fkmeans, data, data_dim, data_num, k);
vl_kmeans_set_centers(fkmeans, (void *)init_centers, data_dim, k);
vl_kmeans_cluster(fkmeans, data, data_dim, data_num, k);
// vl_kmeans_set_max_num_iterations(fkmeans, 100);
// vl_kmeans_refine_centers(fkmeans, data, data_num);
// vl_kmeans_cluster(fkmeans, data, data_dim, data_num, k);
const float * centers = (float *)vl_kmeans_get_centers(fkmeans);
cout << "Clustering Centers: " << endl;
for (int i = 0; i < k; i++)
{
cout << centers[i * data_dim] << "\t" << centers[i * data_dim + 1] << endl;
}
}
聚类结果如下:
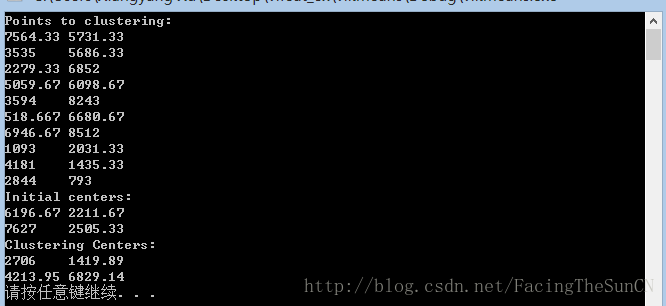
4213.95242857143 6829.14285714286
#include <ikmeans.h>
#include <kmeans.h>
#include <opencv/cv.h>
#include <opencv/cxcore.h>
#include <opencv/highgui.h>
using namespace std;
using namespace cv;
void vlikmeans();
void vlkmeans();
int main()
{
rand();
vlikmeans();
vlkmeans();
system("pause");
return 0;
}