Solr的Facet学习笔记与个人总结
1. Facet简介
Facet是solr的高级搜索功能之一,可以给用户提供更友好的搜索体验。
在搜索关键字的同时,能够按照Facet的字段进行分组并统计。
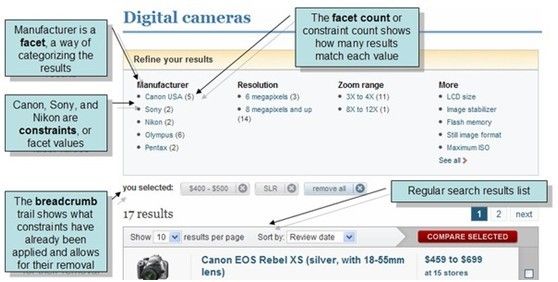
2. Facet字段
2.1. 适宜被Facet的字段
一般代表了实体的某种公共属性。如商品的分类,商品的制造厂家,书籍的出版商等等。
2.2. Facet字段的要求
Facet的字段必须被索引。一般来说该字段无需分词、无需存储。
无需分词是因为该字段的值代表了一个整体概念,如电脑的品牌”联想”代表了一个整体概念。
如果拆成”联”,”想”两个字都不具有实际意义。
另外该字段的值无需进行大小写转换等处理,保持其原貌即可。
无需存储是因为一般而言用户所关心的并不是该字段的具体值,
而是作为对查询结果进行分组的一种手段,
用户一般会沿着这个分组进一步深入搜索。
2.3. 特殊情况
对于一般查询而言,分词和存储都是必要的.
比如CPU类型”Intel 酷睿2双核 P7570”,拆分成”Intel”,”酷睿”,”P7570”这样一些关键字并分别索引,可能提供更好的搜索体验。
但是如果将CPU作为Facet字段,最好不进行分词,这样就造成了矛盾。
解决方法为,将CPU字段设置为不分词不存储,然后建立另外一个字段为它的COPY,对这个COPY的字段进行分词和存储。
schema.xml配置如下:
<types> <fieldType name="string" class="solr.StrField" omitNorms="true"/> <fieldType name="tokened" class="solr.TextField" > <analyzer> …… </analyzer> </fieldType> …… </types> <fields> <field name=”cpu” type=”string” indexed=”true” stored=”false”/> <field name=”cpuCopy” type=” tokened” indexed=”true” stored=”true”/> …… </fields> <copyField source="cpu" dest="cpuCopy"/>
3. Facet组件
Solr的默认requestHandler(org.apache.solr.handler.component.SearchHandler)已经包含了Facet组件(org.apache.solr.handler.component.FacetComponent)。
如果自定义requestHandler或者对默认的requestHandler自定义组件列表,那么需要将Facet加入到组件列表中去。
solrconfig.xml配置:
<requestHandler name="standard" class="solr.SearchHandler" default="true"> …… <arr name="components"> <str>自定义组件名</str> <str>facet</str> …… </arr> </requestHandler>
4. Facet查询
进行Facet查询需要在请求参数中加入”facet=on”或者”facet=true”,只有这样Facet组件才起作用。
4.1. Field Facet【可快速应用】
Facet字段通过在请求中加入”facet.field”参数加以声明,如果需要对多个字段进行Facet查询,那么将该参数声明多次。比如:
/select?q=联想 &facet=on &facet.field=cpu &facet.field=videoCard
返回结果为:
<lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name="cpu"> <int name="Intel 酷睿2双核 T6600">48</int> <int name="Intel 奔腾双核 T4300">28</int> <int name="Intel 酷睿2双核 P8700">18</int> <int name="Intel 酷睿2双核 T6570">11</int> <int name="Intel 酷睿2双核 T6670">11</int> <int name="Intel 奔腾双核 T4400">9</int> <int name="Intel 酷睿2双核 P7450">9</int> <int name="Intel 酷睿2双核 T5870">8</int> <int name="Intel 赛扬双核 T3000">7</int> <int name="Intel 奔腾双核 SU4100">6</int> <int name="Intel 酷睿2双核 P8400">6</int> <int name="Intel 酷睿2双核 SU7300">5</int> <int name="Intel 酷睿 i3 330M">4</int> </lst> <lst name="videoCard"> <int name="ATI Mobility Radeon HD 4">63</int> <int name="NVIDIA GeForce G 105M">24</int> <int name="NVIDIA GeForce GT 240M">21</int> <int name="NVIDIA GeForce G 103M">8</int> <int name="NVIDIA GeForce GT 220M">8</int> <int name="NVIDIA GeForce 9400M G">7</int> <int name="NVIDIA GeForce G 210M">6</int> </lst> </lst> <lst name="facet_dates"/> </lst>
各个Facet字段互不影响,且可以针对每个Facet字段设置查询参数。
以下介绍的参数既可以应用于所有的Facet字段,也可以应用于每个单独的Facet字段。
应用于单独的字段时通过
f.字段名.参数名=参数值
这种方式调用,比如facet.prefix参数应用于cpu字段,可以采用如下形式:
f.cpu.facet.prefix=Intel
4.1.1. facet.prefix
表示Facet字段值的前缀。
比如”facet.field=cpu&facet.prefix=Intel”,那么对cpu字段进行Facet查询,返回的cpu都是以”Intel”开头的,”AMD”开头的cpu型号将不会被统计在内。
4.1.2. facet.sort
表示Facet字段值以哪种顺序返回,可接受的值为true(count)|false(index,lex)。
true(count)表示按照count值从大到小排列。
false(index,lex)表示按照字段值的自然顺序(字母,数字的顺序)排列。
默认情况下为true(count)。
当facet.limit值为负数时,默认facet.sort= false(index,lex)。
4.1.3. facet.limit
限制Facet字段返回的结果条数,默认值为100。
如果此值为负数,表示不限制。
4.1.4. facet.offset
返回结果集的偏移量,默认为0。
它与facet.limit配合使用可以达到分页的效果.
4.1.5. facet.mincount
限制了Facet字段值的最小count,默认为0。
合理设置该参数可以将用户的关注点集中在少数比较热门的领域。
4.1.6. facet.missing
默认为””,如果设置为true或者on,那么将统计那些Facet字段值为null的记录。
4.1.7. facet.method
取值为enum或fc,默认为fc。该字段表示了两种Facet的算法,与执行效率相关。
enum适用于字段值比较少的情况,比如字段类型为布尔型,或者字段表示中国的所有省份。
Solr会遍历该字段的所有取值,并从filterCache里为每个值分配一个filter(这里要求solrconfig.xml里对filterCache的设置足够大).然后计算每个filter与主查询的交集。
fc(表示Field Cache)适用于字段取值比较多,但在每个文档里出现次数比较少的情况。
Solr会遍历所有的文档,在每个文档内搜索Cache内的值,如果找到就将Cache内该值的count加1。
4.1.8. facet.enum.cache.minDf
当facet.method=enum时,此参数其作用,minDf表示minimum document frequency。
也就是文档内出现某个关键字的最少次数,该参数默认值为0。
设置该参数可以减少filterCache的内存消耗,但会增加总的查询时间(计算交集的时间增加了)。
如果设置该值的话,官方文档建议优先尝试25-50内的值。
4.2. Date Facet
日期类型的字段在文档中很常见,如商品上市时间,货物出仓时间,书籍上架时间等等。
某些情况下需要针对这些字段进行Facet。不过时间字段的取值有无限性,用户往往关心的不是某个时间点而是某个时间段内的查询统计结果。
Solr为日期字段提供了更为方便的查询统计方式。当然,字段的类型必须是DateField(或其子类型)。
需要注意的是,使用Date Facet时,字段名、起始时间、结束时间、时间间隔这4个参数都必须提供。
与Field Facet类似,Date Facet也可以对多个字段进行Facet,并且针对每个字段都可以单独设置参数。
4.2.1. facet.date
该参数表示需要进行Date Facet的字段名,与facet.field一样,该参数可以被设置多次,表示对多个字段进行Date Facet。
4.2.2. facet.date.start
起始时间,时间的一般格式为” 1995-12-31T23:59:59Z”,另外可以使用”NOW”、”YEAR”、”MONTH”等等,具体格式可以参考org.apache.solr.schema. DateField的java doc。
4.2.3. facet.date.end
结束时间。
4.2.4. facet.date.gap
时间间隔。如果start为2009-1-1,end为2010-1-1。
gap设置为”+1MONTH”表示间隔1个月,那么将会把这段时间划分为12个间隔段。
注意”+”因为是特殊字符所以应该用”%2B”代替。
4.2.5. facet.date.hardend
取值可以为true|false,默认为false。
它表示gap迭代到end处采用何种处理。
举例说明start为2009-1-1,end为2009-12-25,gap为”+1MONTH”。
hardend为false的话最后一个时间段为2009-12-1至2010-1-1;
hardend为true的话最后一个时间段为2009-12-1至2009-12-25。
4.2.6. facet.date.other
取值范围为before|after|between|none|all,默认为none。
before会对start之前的值做统计。
after会对end之后的值做统计。
between会对start至end之间所有值做统计。
如果hardend为true的话,那么该值就是各个时间段统计值的和。
none表示该项禁用。
all表示before,after,all都会统计。
举例:
&facet=on &facet.date=date &facet.date.start=2009-1-1T0:0:0Z &facet.date.end=2010-1-1T0:0:0Z &facet.date.gap=%2B1MONTH &facet.date.other=all
返回结果:
<lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"/> <lst name="facet_dates"> <int name="2009-01-01T00:00:00Z">5</int> <int name="2009-02-01T00:00:00Z">7</int> <int name="2009-03-01T00:00:00Z">4</int> <int name="2009-04-01T00:00:00Z">3</int> <int name="2009-05-01T00:00:00Z">7</int> <int name="2009-06-01T00:00:00Z">3</int> <int name="2009-07-01T00:00:00Z">6</int> <int name="2009-08-01T00:00:00Z">7</int> <int name="2009-09-01T00:00:00Z">2</int> <int name="2009-10-01T00:00:00Z">4</int> <int name="2009-11-01T00:00:00Z">1</int> <int name="2009-12-01T00:00:00Z">5</int> <str name="gap">+1MONTH</str> <date name="end">2010-01-01T00:00:00Z</date> <int name="before">180</int> <int name="after">5</int> <int name="between">54</int> </lst> </lst>
4.3. Facet Query【非常灵活,可进行各种定制】
Facet Query利用类似于filter query的语法提供了更为灵活的Facet。
通过facet.query参数,可以对任意字段进行筛选。
例1:
&facet=on &facet.query=date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z] &facet.query=date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z]
返回结果:
<lst name="facet_counts"> <lst name="facet_queries"> <int name="date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]">5</int> <int name="date:[2009-4-1T0:0:0Z TO 2009-5-1T0:0:0Z]">3</int> </lst> <lst name="facet_fields"/> <lst name="facet_dates"/> </lst>
例2:
&facet=on &facet.query=date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z] &facet.query=price:[* TO 5000]
返回结果:
<lst name="facet_counts"> <lst name="facet_queries"> <int name="date:[2009-1-1T0:0:0Z TO 2009-2-1T0:0:0Z]">5</int> <int name="price:[* TO 5000]">116</int> </lst> <lst name="facet_fields"/> <lst name="facet_dates"/> </lst>
例3:
&facet=on &facet.query=cpu:[A TO G]
返回结果:
<lst name="facet_counts"> <lst name="facet_queries"> <int name="cpu:[A TO G]">11</int> </lst> <lst name="facet_fields"/> <lst name="facet_dates"/> </lst>
4.4. key操作符
可以用key操作符为Facet字段取一个别名。
例:
&facet=on
&facet.field={!key=中央处理器}cpu
&facet.field={!key=显卡}videoCard
返回结果:
<lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name="中央处理器"> <int name="Intel 酷睿2双核 T6600">48</int> <int name="Intel 奔腾双核 T4300">28</int> <int name="Intel 酷睿2双核 P8700">18</int> <int name="Intel 酷睿2双核 T6570">11</int> <int name="Intel 酷睿2双核 T6670">11</int> <int name="Intel 奔腾双核 T4400">9</int> <int name="Intel 酷睿2双核 P7450">9</int> <int name="Intel 酷睿2双核 T5870">8</int> <int name="Intel 赛扬双核 T3000">7</int> <int name="Intel 奔腾双核 SU4100">6</int> <int name="Intel 酷睿2双核 P8400">6</int> <int name="Intel 酷睿2双核 SU7300">5</int> <int name="Intel 酷睿 i3 330M">4</int> </lst> <lst name="显卡"> <int name="ATI Mobility Radeon HD 4">63</int> <int name="NVIDIA GeForce G 105M">24</int> <int name="NVIDIA GeForce GT 240M">21</int> <int name="NVIDIA GeForce G 103M">8</int> <int name="NVIDIA GeForce GT 220M">8</int> <int name="NVIDIA GeForce 9400M G">7</int> <int name="NVIDIA GeForce G 210M">6</int> </lst> </lst> <lst name="facet_dates"/> </lst>
4.5. tag操作符和ex操作符【非常有用】
当查询使用filter query的时候,如果filter query的字段正好是Facet字段,那么查询结果往往被限制在某一个值内。
例:
&fq=screenSize:14 &facet=on &facet.field=screenSize
返回结果:
<lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name=" screenSize"> <int name="14.0">107</int> <int name="10.2">0</int> <int name="11.1">0</int> <int name="11.6">0</int> <int name="12.1">0</int> <int name="13.1">0</int> <int name="13.3">0</int> <int name="14.1">0</int> <int name="15.4">0</int> <int name="15.5">0</int> <int name="15.6">0</int> <int name="16.0">0</int> <int name="17.0">0</int> <int name="17.3">0</int> </lst> </lst> <lst name="facet_dates"/> </lst>
可以看到,屏幕尺寸(screenSize)为14寸的产品共有107件,其它尺寸的产品的数目都是0。
这是因为在filter里已经限制了screenSize:14。
这样,查询结果中,,除了screenSize=14的这一项之外,其它项目没有实际的意义。
应用场景:
有些时候,用户希望把结果限制在某一范围内,又希望查看该范围外的概况。
比如上述情况,既要把查询结果限制在14寸屏的笔记本,又想查看一下其它屏幕尺寸的笔记本有多少产品。
这个时候需要用到tag和ex操作符。
tag就是把一个filter标记起来,ex(exclude)是在Facet的时候把标记过的filter排除在外。
例:
&fq={!tag=aa}screenSize:14
&facet=on
&facet.field={!ex=aa}screenSize
返回结果:
<lst name="facet_counts"> <lst name="facet_queries"/> <lst name="facet_fields"> <lst name=" screenSize"> <int name="14.0">107</int> <int name="14.1">40</int> <int name="13.3">34</int> <int name="15.6">22</int> <int name="15.4">8</int> <int name="11.6">6</int> <int name="12.1">5</int> <int name="16.0">5</int> <int name="15.5">3</int> <int name="17.0">3</int> <int name="17.3">3</int> <int name="10.2">1</int> <int name="11.1">1</int> <int name="13.1">1</int> </lst> </lst> <lst name="facet_dates"/> </lst>
这样其它屏幕尺寸的统计信息就有意义了。
5. SolrJ对Facet的支持
SolrServer server = getSolrServer();//获取SolrServer
SolrQuery query = new SolrQuery();//建立一个新的查询
query.setQuery("*:*");
query.setFacet(true);//设置facet=on
query.addFacetField(new String[] { "cpu", "videoCard" });//设置需要facet的字段
query.setFacetLimit(10);//限制facet返回的数量
QueryResponse response = server.query(query);
List<FacetField> facets = response.getFacetFields();//返回的facet列表
for (FacetField facet : facets) {
System.out.println(facet.getName());
System.out.println("----------------");
List<Count> counts = facet.getValues();
for (Count count : counts) {
System.out.println(count.getName() + ":" + count.getCount());
}
System.out.println();
}