用实例讲解Spark Sreaming
用实例讲解Spark Sreaming
本篇文章用Spark Streaming +Hbase为列,Spark Streaming专为流式数据处理,对Spark核心API进行了相应的扩展。
什么是Spark Streaming?
首先,什么是流式处理呢?数据流是一个数据持续不断到达的无边界序列集。流式处理是把连续不断的数据输入分割成单元数据块来处理。流式处理是一个低延迟的处理和流式数据分析。Spark Streaming对Spark核心API进行了相应的扩展,支持高吞吐、低延迟、可扩展的流式数据处理。实时数据处理应用的场景有下面几个:
- 网站监控和网络监控;
- 异常监测;
- 网页点击;
- 广告数据;
物联网(IOT)

图1
Spark Streaming支持的数据源包括HDFS文件,TCP socket,Kafka,Flume,Twitter等,数据流可以通过Spark核心API、DataFrame SQL或者机器学习API处理,并可以持久化到本地文件、HDFS、数据库或者其它任意支持Hadoop输出格式的形式。
Spark Streaming如何工作?
Spark Streaming以X秒(batch size)为时间间隔把数据流分割成Dstream,组成一个RDD序列。你的Spark应用处理RDD,并把处理的结果批量返回。

图2
Spark Streaming例子的架构图
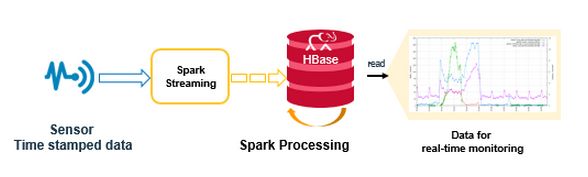
图3
Spark Streaming例子代码分下面几部分:
- 读取流式数据;
- 处理流式数据;
- 写处理结果倒Hbase表。
Spark处理部分的代码涉及到如下内容:
- 读取Hbase表的数据;
- 按天计算数据统计;
- 写统计结果到Hbase表,列簇:stats。
数据集
数据集来自油泵信号数据,以CSV格式存储在指定目录下。Spark Streaming监控此目录,CSV文件的格式如图3。

图4
采用Scala的case class来定义数据表结构,parseSensor函数解析逗号分隔的数据。
Hbase表结构
流式处理的Hbase表结构如下:
- 油泵名字 + 日期 + 时间戳 组合成row key;
- 列簇是由输入数据列、报警数据列等组成,并设置过期时间。
- 每天等统计数据表结构如下:
- 油泵名和日期组成row key;
列簇为stats,包含列有最大值、最小值和平均值;
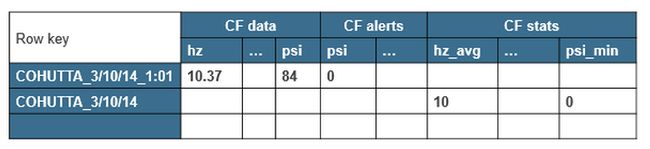
图5
Spark直接用TableOutputFormat类写数据到Hbase里,跟在MapReduce中写数据到Hbase表一样,下面就直接用TableOutputFormat类了。
Spark Streaming的基本步骤:
- 初始化Spark StreamingContext对象;
- 在DStream上进行transformation操作和输出操作;
- 开始接收数据并用streamingContext.start();
- 等待处理停止,streamingContext.awaitTermination()。
初始化Spark StreamingContext对象
创建 StreamingContext对象,StreamingContext是Spark Streaming处理的入口,这里设置2秒的时间间隔。
val sparkConf = new SparkConf().setAppName("HBaseStream")
// create a StreamingContext, the main entry point for all streaming functionality
val ssc = new StreamingContext(sparkConf, Seconds(2))接下来用StreamingContext的textFileStream(directory)创建输入流跟踪Hadoop文件系统的新文件,并处理此目录下的所有文件,这里directory指文件目录。
// create a DStream that represents streaming data from a directory source
val linesDStream = ssc.textFileStream("/user/user01/stream")linesDStream是数据流,每条记录是按行记录的text格式。
图6
对DStream进行transformation操作和输出操作
接下来进行解析,对linesDStream进行map操作,map操作是对RDD应用Sensor.parseSensor函数,返回Sensor的RDD。
// parse each line of data in linesDStream into sensor objects
val sensorDStream = linesDStream.map(Sensor.parseSensor)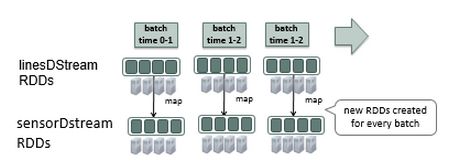
图7
对DStream的每个RDD执行foreachRDD 方法,使用filter过滤Sensor中低psi值来创建报警,使用Hbase的Put对象转换sensor和alter数据以便能写入到Hbase。然后使用PairRDDFunctions的saveAsHadoopDataset方法将最终结果写入到任何Hadoop兼容到存储系统。
// for each RDD. performs function on each RDD in DStream
sensorRDD.foreachRDD { rdd =>
// filter sensor data for low psi
val alertRDD = rdd.filter(sensor => sensor.psi < 5.0)
// convert sensor data to put object and write to HBase Table CF data
rdd.map(Sensor.convertToPut).saveAsHadoopDataset(jobConfig)
// convert alert to put object write to HBase Table CF alerts
rdd.map(Sensor.convertToPutAlert).saveAsHadoopDataset(jobConfig)
}sensorRDD经过Put对象转换,然后写入到Hbase。
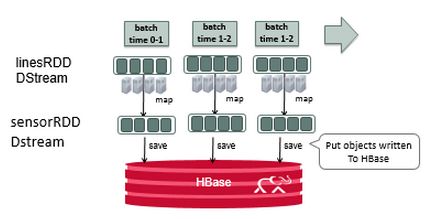
图8
开始接收数据
通过streamingContext.start()显式的启动数据接收,然后调用streamingContext.awaitTermination()来等待计算完成。
// Start the computation
ssc.start()
// Wait for the computation to terminate
ssc.awaitTermination()Spark读写Hbase
现在开始读取Hbase的sensor表,计算每条的统计指标并把对应的数据写入stats列簇。
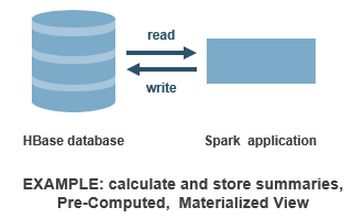
图9
下面的代码读取Hbase的sensor表psi列数据,用StatCounter计算统计数据,然后写入stats列簇。
// configure HBase for reading
val conf = HBaseConfiguration.create()
conf.set(TableInputFormat.INPUT_TABLE, HBaseSensorStream.tableName)
// scan data column family psi column
conf.set(TableInputFormat.SCAN_COLUMNS, "data:psi")
// Load an RDD of (row key, row Result) tuples from the table
val hBaseRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
// transform (row key, row Result) tuples into an RDD of Results
val resultRDD = hBaseRDD.map(tuple => tuple._2)
// transform into an RDD of (RowKey, ColumnValue)s , with Time removed from row key
val keyValueRDD = resultRDD.
map(result => (Bytes.toString(result.getRow()).
split(" ")(0), Bytes.toDouble(result.value)))
// group by rowkey , get statistics for column value
val keyStatsRDD = keyValueRDD.
groupByKey().
mapValues(list => StatCounter(list))
// convert rowkey, stats to put and write to hbase table stats column family
keyStatsRDD.map { case (k, v) => convertToPut(k, v) }.saveAsHadoopDataset(jobConfig)下面的流程图显示newAPIHadoopRDD输出,(row key,result)的键值对。PairRDDFunctions 的saveAsHadoopDataset方法把Put对象存入到Hbase。

图10
运行Spark Streaming应用
运行Spark Streaming应用跟运行Spark应用类似,比较简单,此处不赘述,参见Spark Streaming官方文档。