scsi块设备驱动层处理
1.6.3 scsi块设备驱动层处理
好了,了解完必要的scsi设备驱动知识以后,我们就可以安心分析scsi_request_fn函数了。大家回忆一下对,这个函数指针通过几次传递并最终在blk_init_queue_node()中被赋予了q->request_fn。所以这一层的重点就是这个scsi_request_fn函数。
在看scsi_request_fn之前,注意回忆一下scsi_alloc_queue函数的1598行至1560行还赋了三个函数指针:
| 1590 struct request_queue *scsi_alloc_queue(struct scsi_device *sdev) 1591 { 1592 struct request_queue *q; 1593 1594 q = __scsi_alloc_queue(sdev->host, scsi_request_fn); 1595 if (!q) 1596 return NULL; 1597 1598 blk_queue_prep_rq(q, scsi_prep_fn); 1599 blk_queue_issue_flush_fn(q, scsi_issue_flush_fn); 1600 blk_queue_softirq_done(q, scsi_softirq_done); 1601 return q; 1602 }
143 void blk_queue_prep_rq(request_queue_t *q, prep_rq_fn *pfn) 144 { 145 q->prep_rq_fn = pfn; 146 }
313 void blk_queue_issue_flush_fn(request_queue_t *q, issue_flush_fn *iff) 314 { 315 q->issue_flush_fn = iff; 316 } 173 void blk_queue_softirq_done(request_queue_t *q, softirq_done_fn *fn) 174 { 175 q->softirq_done_fn = fn; 176 } |
分别是把scsi_prep_fn赋给了q->prep_rq_fn,把scsi_issue_flush_fn赋给了q->issue_flush_fn,把scsi_softirq_done赋给了q->softirq_done_fn。尤其是scsi_prep_fn我们马上就会用到。
好,让我们继续前面的话题,重点关注scsi_request_fn():
| 1422 static void scsi_request_fn(struct request_queue *q) 1423 { 1424 struct scsi_device *sdev = q->queuedata; 1425 struct scsi_Host *shost; 1426 struct scsi_cmnd *cmd; 1427 struct request *req; 1428 1429 if (!sdev) { 1430 printk("scsi: killing requests for dead queue/n"); 1431 while ((req = elv_next_request(q)) != NULL) 1432 scsi_kill_request(req, q); 1433 return; 1434 } 1435 1436 if(!get_device(&sdev->sdev_gendev)) 1437 /* We must be tearing the block queue down already */ 1438 return; 1439 1440 /* 1441 * To start with, we keep looping until the queue is empty, or until 1442 * the host is no longer able to accept any more requests. 1443 */ 1444 shost = sdev->host; 1445 while (!blk_queue_plugged(q)) { 1446 int rtn; 1447 /* 1448 * get next queueable request. We do this early to make sure 1449 * that the request is fully prepared even if we cannot 1450 * accept it. 1451 */ 1452 req = elv_next_request(q); 1453 if (!req || !scsi_dev_queue_ready(q, sdev)) 1454 break; 1455 1456 if (unlikely(!scsi_device_online(sdev))) { 1457 sdev_printk(KERN_ERR, sdev, 1458 "rejecting I/O to offline device/n"); 1459 scsi_kill_request(req, q); 1460 continue; 1461 } 1462 1463 1464 /* 1465 * Remove the request from the request list. 1466 */ 1467 if (!(blk_queue_tagged(q) && !blk_queue_start_tag(q, req))) 1468 blkdev_dequeue_request(req); 1469 sdev->device_busy++; /* 说明命令正在执行中 */ 1470 1471 spin_unlock(q->queue_lock); 1472 cmd = req->special; 1473 if (unlikely(cmd == NULL)) { 1474 printk(KERN_CRIT "impossible request in %s./n" 1475 "please mail a stack trace to " 1476 "[email protected]/n", 1477 __FUNCTION__); 1478 blk_dump_rq_flags(req, "foo"); 1479 BUG(); 1480 } 1481 spin_lock(shost->host_lock); 1482 1483 if (!scsi_host_queue_ready(q, shost, sdev)) 1484 goto not_ready; 1485 if (sdev->single_lun) { 1486 if (scsi_target(sdev)->starget_sdev_user && 1487 scsi_target(sdev)->starget_sdev_user != sdev) 1488 goto not_ready; 1489 scsi_target(sdev)->starget_sdev_user = sdev; 1490 } 1491 shost->host_busy++; 1492 1493 /* 1494 * XXX(hch): This is rather suboptimal, scsi_dispatch_cmd will 1495 * take the lock again. 1496 */ 1497 spin_unlock_irq(shost->host_lock); 1498 1499 /* 1500 * Finally, initialize any error handling parameters, and set up 1501 * the timers for timeouts. 1502 */ 1503 scsi_init_cmd_errh(cmd); 1504 1505 /* 1506 * Dispatch the command to the low-level driver. 1507 */ 1508 rtn = scsi_dispatch_cmd(cmd); 1509 spin_lock_irq(q->queue_lock); 1510 if(rtn) { 1511 /* we're refusing the command; because of 1512 * the way locks get dropped, we need to 1513 * check here if plugging is required */ 1514 if(sdev->device_busy == 0) 1515 blk_plug_device(q); 1516 1517 break; 1518 } 1519 } 1520 1521 goto out; 1522 1523 not_ready: 1524 spin_unlock_irq(shost->host_lock); 1525 1526 /* 1527 * lock q, handle tag, requeue req, and decrement device_busy. We 1528 * must return with queue_lock held. 1529 * 1530 * Decrementing device_busy without checking it is OK, as all such 1531 * cases (host limits or settings) should run the queue at some 1532 * later time. 1533 */ 1534 spin_lock_irq(q->queue_lock); 1535 blk_requeue_request(q, req); 1536 sdev->device_busy--; 1537 if(sdev->device_busy == 0) 1538 blk_plug_device(q); 1539 out: 1540 /* must be careful here...if we trigger the ->remove() function 1541 * we cannot be holding the q lock */ 1542 spin_unlock_irq(q->queue_lock); 1543 put_device(&sdev->sdev_gendev); 1544 spin_lock_irq(q->queue_lock); 1545 } |
scsi_request_fn函数为scsi设备请求队列处理函数,前面看到该函数被注册到了request_queue->request_fn上。块设备请求的bio最终会merge到request queue中,然后通过unplug_fn函数调用request_queue->request_fn,实现scsi_reuqest_fn函数的调用。
scsi_request_fn函数实现了请求队列的处理,首先1452-1468行按照电梯算法从请求队列中摘取一个request,所以我们首先关注1452行的elv_next_request(),来自block/elevator.c:
| 712 struct request *elv_next_request(request_queue_t *q) 713 { 714 struct request *rq; 715 int ret; 716 717 while ((rq = __elv_next_request(q)) != NULL) { 718 if (!(rq->cmd_flags & REQ_STARTED)) { 719 /* 720 * This is the first time the device driver 721 * sees this request (possibly after 722 * requeueing). Notify IO scheduler. 723 */ 724 if (blk_sorted_rq(rq)) 725 elv_activate_rq(q, rq); 726 727 /* 728 * just mark as started even if we don't start 729 * it, a request that has been delayed should 730 * not be passed by new incoming requests 731 */ 732 rq->cmd_flags |= REQ_STARTED; 733 blk_add_trace_rq(q, rq, BLK_TA_ISSUE); 734 } 735 736 if (!q->boundary_rq || q->boundary_rq == rq) { 737 q->end_sector = rq_end_sector(rq); 738 q->boundary_rq = NULL; 739 } 740 741 if ((rq->cmd_flags & REQ_DONTPREP) || !q->prep_rq_fn) 742 break; 743 744 ret = q->prep_rq_fn(q, rq); 745 if (ret == BLKPREP_OK) { 746 break; 747 } else if (ret == BLKPREP_DEFER) { 748 /* 749 * the request may have been (partially) prepped. 750 * we need to keep this request in the front to 751 * avoid resource deadlock. REQ_STARTED will 752 * prevent other fs requests from passing this one. 753 */ 754 rq = NULL; 755 break; 756 } else if (ret == BLKPREP_KILL) { 757 int nr_bytes = rq->hard_nr_sectors << 9; 758 759 if (!nr_bytes) 760 nr_bytes = rq->data_len; 761 762 blkdev_dequeue_request(rq); 763 rq->cmd_flags |= REQ_QUIET; 764 end_that_request_chunk(rq, 0, nr_bytes); 765 end_that_request_last(rq, 0); 766 } else { 767 printk(KERN_ERR "%s: bad return=%d/n", __FUNCTION__, 768 ret); 769 break; 770 } 771 } 772 773 return rq; 774 } |
它调用的__elv_next_request()仍然来自block/elevator.c:
| 696 static inline struct request *__elv_next_request(request_queue_t *q) 697 { 698 struct request *rq; 699 700 while (1) { 701 while (!list_empty(&q->queue_head)) { 702 rq = list_entry_rq(q->queue_head.next); 703 if (blk_do_ordered(q, &rq)) 704 return rq; 705 } 706 707 if (!q->elevator->ops->elevator_dispatch_fn(q, 0)) 708 return NULL; 709 } 710 } |
由于我们在I/O调度层中插入了一个request,所以这里q->queue_head不可能为空。所以702行从中取出一个request来。然后是blk_do_ordered(),来自block/ll_rw_blk.c:
| 478 int blk_do_ordered(request_queue_t *q, struct request **rqp) 479 { 480 struct request *rq = *rqp; 481 int is_barrier = blk_fs_request(rq) && blk_barrier_rq(rq); 482 483 if (!q->ordseq) { 484 if (!is_barrier) 485 return 1; 486 487 if (q->next_ordered != QUEUE_ORDERED_NONE) { 488 *rqp = start_ordered(q, rq); 489 return 1; 490 } else { 491 /* 492 * This can happen when the queue switches to 493 * ORDERED_NONE while this request is on it. 494 */ 495 blkdev_dequeue_request(rq); 496 end_that_request_first(rq, -EOPNOTSUPP, 497 rq->hard_nr_sectors); 498 end_that_request_last(rq, -EOPNOTSUPP); 499 *rqp = NULL; 500 return 0; 501 } 502 } 503 504 /* 505 * Ordered sequence in progress 506 */ 507 508 /* Special requests are not subject to ordering rules. */ 509 if (!blk_fs_request(rq) && 510 rq != &q->pre_flush_rq && rq != &q->post_flush_rq) 511 return 1; 512 513 if (q->ordered & QUEUE_ORDERED_TAG) { 514 /* Ordered by tag. Blocking the next barrier is enough. */ 515 if (is_barrier && rq != &q->bar_rq) 516 *rqp = NULL; 517 } else { 518 /* Ordered by draining. Wait for turn. */ 519 WARN_ON(blk_ordered_req_seq(rq) < blk_ordered_cur_seq(q)); 520 if (blk_ordered_req_seq(rq) > blk_ordered_cur_seq(q)) 521 *rqp = NULL 522 } 523 524 return 1; 525 } |
首先看一下blk_fs_request,
528 #define blk_fs_request(rq) ((rq)->cmd_type == REQ_TYPE_FS)
很显然,咱们从来没有设置这个标识,所以不去管它。
所以在咱们这个上下文里,is_barrier一定是0。所以,blk_do_ordered二话不说,直接返回1。那么回到__elv_next_request以后,703行这个if条件是满足的,所以也就是返回rq,下面的那个elevator_dispatch_fn根本不会执行的。另一方面,我们从__elv_next_request返回,回到elv_next_request()的时候,只要request queue不是空的,那么返回值就是队列中最前边的那个request。
继续在elv_next_request中往下走,request得到了,cmd_flags其实整个故事中设置REQ_STARTED的也就是这里,732行。所以在我们执行732行之前,这个flag是没有设置的。因此,if条件是满足的。
而blk_sorted_rq又是一个宏,来自include/linux/blkdev.h:
543 #define blk_sorted_rq(rq) ((rq)->cmd_flags & REQ_SORTED)
很显然,咱们也从来没有设置过这个flag,所以这里不关我们的事。
当然了,对于noop,即便执行下一个函数也没有意义,因为这个elv_activate_rq()来自block/elevator.c:
| 272 static void elv_activate_rq(request_queue_t *q, struct request *rq) 273 { 274 elevator_t *e = q->elevator; 275 276 if (e->ops->elevator_activate_req_fn) 277 e->ops->elevator_activate_req_fn(q, rq); 278 } |
我们假设使用最简单的noop电梯算法,即根本就没有这个指针,所以不去管他。
这时候,我们设置REQ_STARTED这个flag,最开始我们在elevator_init()中,有这么一句:
230 q->boundary_rq = NULL;
于是rq_end_sector会被执行,这其实也只是一个很简单的宏:
172 #define rq_end_sector(rq) ((rq)->sector + (rq)->nr_sectors)
同时,boundary_rq还是被置为NULL。
回到elv_next_request中,接下来744行,由于我们把prep_rq_fn赋上了scsi_prep_fn,所以我们要看一下这个scsi_prep_fn(),这个来自drivers/scsi/scsi_lib.c的函数:
| 1093static int scsi_prep_fn(struct request_queue *q, struct request *req) 1094{ 1095 struct scsi_device *sdev = q->queuedata; 1096 struct scsi_cmnd *cmd; 1097 int specials_only = 0; 1098 1099 /* 1100 * Just check to see if the device is online. If it isn't, we 1101 * refuse to process any commands. The device must be brought 1102 * online before trying any recovery commands 1103 */ 1104 if (unlikely(!scsi_device_online(sdev))) { 1105 sdev_printk(KERN_ERR, sdev, 1106 "rejecting I/O to offline device/n"); 1107 goto kill; 1108 } 1109 if (unlikely(sdev->sdev_state != SDEV_RUNNING)) { 1110 /* OK, we're not in a running state don't prep 1111 * user commands */ 1112 if (sdev->sdev_state == SDEV_DEL) { 1113 /* Device is fully deleted, no commands 1114 * at all allowed down */ 1115 sdev_printk(KERN_ERR, sdev, 1116 "rejecting I/O to dead device/n"); 1117 goto kill; 1118 } 1119 /* OK, we only allow special commands (i.e. not 1120 * user initiated ones */ 1121 specials_only = sdev->sdev_state; 1122 } 1123 1124 /* 1125 * Find the actual device driver associated with this command. 1126 * The SPECIAL requests are things like character device or 1127 * ioctls, which did not originate from ll_rw_blk. Note that 1128 * the special field is also used to indicate the cmd for 1129 * the remainder of a partially fulfilled request that can 1130 * come up when there is a medium error. We have to treat 1131 * these two cases differently. We differentiate by looking 1132 * at request->cmd, as this tells us the real story. 1133 */ 1134 if (req->flags & REQ_SPECIAL && req->special) { 1135 cmd = req->special; 1136 } else if (req->flags & (REQ_CMD | REQ_BLOCK_PC)) { 1137 1138 if(unlikely(specials_only) && !(req->flags & REQ_SPECIAL)) { 1139 if(specials_only == SDEV_QUIESCE || 1140 specials_only == SDEV_BLOCK) 1141 goto defer; 1142 1143 sdev_printk(KERN_ERR, sdev, 1144 "rejecting I/O to device being removed/n"); 1145 goto kill; 1146 } 1147 1148 1149 /* 1150 * Now try and find a command block that we can use. 1151 */ 1152 if (!req->special) { 1153 cmd = scsi_get_command(sdev, GFP_ATOMIC); 1154 if (unlikely(!cmd)) 1155 goto defer; 1156 } else 1157 cmd = req->special; 1158 1159 /* pull a tag out of the request if we have one */ 1160 cmd->tag = req->tag; 1161 } else { 1162 blk_dump_rq_flags(req, "SCSI bad req"); 1163 goto kill; 1164 } 1165 1166 /* note the overloading of req->special. When the tag 1167 * is active it always means cmd. If the tag goes 1168 * back for re-queueing, it may be reset */ 1169 req->special = cmd; 1170 cmd->request = req; 1171 1172 /* 1173 * FIXME: drop the lock here because the functions below 1174 * expect to be called without the queue lock held. Also, 1175 * previously, we dequeued the request before dropping the 1176 * lock. We hope REQ_STARTED prevents anything untoward from 1177 * happening now. 1178 */ 1179 if (req->flags & (REQ_CMD | REQ_BLOCK_PC)) { 1180 int ret; 1181 1182 /* 1183 * This will do a couple of things: 1184 * 1) Fill in the actual SCSI command. 1185 * 2) Fill in any other upper-level specific fields 1186 * (timeout). 1187 * 1188 * If this returns 0, it means that the request failed 1189 * (reading past end of disk, reading offline device, 1190 * etc). This won't actually talk to the device, but 1191 * some kinds of consistency checking may cause the 1192 * request to be rejected immediately. 1193 */ 1194 1195 /* 1196 * This sets up the scatter-gather table (allocating if 1197 * required). 1198 */ 1199 ret = scsi_init_io(cmd); 1200 switch(ret) { 1201 /* For BLKPREP_KILL/DEFER the cmd was released */ 1202 case BLKPREP_KILL: 1203 goto kill; 1204 case BLKPREP_DEFER: 1205 goto defer; 1206 } 1207 1208 /* 1209 * Initialize the actual SCSI command for this request. 1210 */ 1211 if (req->flags & REQ_BLOCK_PC) { 1212 scsi_setup_blk_pc_cmnd(cmd); 1213 } else if (req->rq_disk) { 1214 struct scsi_driver *drv; 1215 1216 drv = *(struct scsi_driver **)req->rq_disk->private_data; 1217 if (unlikely(!drv->init_command(cmd))) { 1218 scsi_release_buffers(cmd); 1219 scsi_put_command(cmd); 1220 goto kill; 1221 } 1222 } 1223 } 1224 1225 /* 1226 * The request is now prepped, no need to come back here 1227 */ 1228 req->flags |= REQ_DONTPREP; 1229 return BLKPREP_OK; 1230 1231 defer: 1232 /* If we defer, the elv_next_request() returns NULL, but the 1233 * queue must be restarted, so we plug here if no returning 1234 * command will automatically do that. */ 1235 if (sdev->device_busy == 0) 1236 blk_plug_device(q); 1237 return BLKPREP_DEFER; 1238 kill: 1239 req->errors = DID_NO_CONNECT << 16; 1240 return BLKPREP_KILL; 1241} |
大家还记得我们前面使用__make_request函数创建一个request的时候,曾经通过init_request_from_bio(req, bio)初始化请求描述符中的字段。其中把request的设置flags字段中的REQ_CMD标识,说明这次request是一个标准的读或写操作。注意,前面我们并没有设置REQ_BLOCK_PC标识。
所以scsi_prep_fn函数首先会进入1136那个条件分支。1138-1146的代码是对该块设备状态的一个检查,一般不会出什么问题。随后1153行调用scsi_get_command函数给我们这个request对应的scsi_device分配一个scsi_cmnd结构,其地址赋给函数内部变量cmd指针:
| struct scsi_cmnd *scsi_get_command(struct scsi_device *dev, gfp_t gfp_mask) { struct scsi_cmnd *cmd;
/* Bail if we can't get a reference to the device */ if (!get_device(&dev->sdev_gendev)) return NULL;
cmd = __scsi_get_command(dev->host, gfp_mask);
if (likely(cmd != NULL)) { unsigned long flags;
memset(cmd, 0, sizeof(*cmd)); cmd->device = dev; init_timer(&cmd->eh_timeout); INIT_LIST_HEAD(&cmd->list); spin_lock_irqsave(&dev->list_lock, flags); list_add_tail(&cmd->list, &dev->cmd_list); spin_unlock_irqrestore(&dev->list_lock, flags); cmd->jiffies_at_alloc = jiffies; } else put_device(&dev->sdev_gendev);
return cmd; }
static struct scsi_cmnd *__scsi_get_command(struct Scsi_Host *shost, gfp_t gfp_mask) { struct scsi_cmnd *cmd;
cmd = kmem_cache_alloc(shost->cmd_pool->slab, gfp_mask | shost->cmd_pool->gfp_mask);
if (unlikely(!cmd)) { unsigned long flags;
spin_lock_irqsave(&shost->free_list_lock, flags); if (likely(!list_empty(&shost->free_list))) { cmd = list_entry(shost->free_list.next, struct scsi_cmnd, list); list_del_init(&cmd->list); } spin_unlock_irqrestore(&shost->free_list_lock, flags); }
return cmd; } |
看不懂这个分配函数的回去好好看一下“scsi设备驱动体系架构”最后那个图,我就不多费口舌了。回到scsi_prep_fn中,1160行把reqest的tag赋给这个全新的scsi_cmnd结构;然后1169、1170行把这个reqest和scsi_cmnd联系起来。随后又进入1179行条件判断,1199行,调用scsi_init_io函数初始化这个scsi_cmnd结构:
| static int scsi_init_io(struct scsi_cmnd *cmd) { struct request *req = cmd->request; struct scatterlist *sgpnt; int count;
/* * if this is a rq->data based REQ_BLOCK_PC, setup for a non-sg xfer */ if ((req->flags & REQ_BLOCK_PC) && !req->bio) { cmd->request_bufflen = req->data_len; cmd->request_buffer = req->data; req->buffer = req->data; cmd->use_sg = 0; return 0; }
/* * we used to not use scatter-gather for single segment request, * but now we do (it makes highmem I/O easier to support without * kmapping pages) */ cmd->use_sg = req->nr_phys_segments;
/* * if sg table allocation fails, requeue request later. */ sgpnt = scsi_alloc_sgtable(cmd, GFP_ATOMIC); if (unlikely(!sgpnt)) { scsi_unprep_request(req); return BLKPREP_DEFER; }
cmd->request_buffer = (char *) sgpnt; cmd->request_bufflen = req->nr_sectors << 9; if (blk_pc_request(req)) cmd->request_bufflen = req->data_len; req->buffer = NULL;
/* * Next, walk the list, and fill in the addresses and sizes of * each segment. */ count = blk_rq_map_sg(req->q, req, cmd->request_buffer);
/* * mapped well, send it off */ if (likely(count <= cmd->use_sg)) { cmd->use_sg = count; return 0; }
printk(KERN_ERR "Incorrect number of segments after building list/n"); printk(KERN_ERR "counted %d, received %d/n", count, cmd->use_sg); printk(KERN_ERR "req nr_sec %lu, cur_nr_sec %u/n", req->nr_sectors, req->current_nr_sectors);
/* release the command and kill it */ scsi_release_buffers(cmd); scsi_put_command(cmd); return BLKPREP_KILL; } |
一般情况下,scsi_init_io返回0,否则致命错误,导致scsi_prep_fn退出。继续走,由于我们并没有设置REQ_BLOCK_PC标识,而且req的rq_disk是存在的,gendisk,忘了?那你完了。所以scsi_prep_fn函数来到1217行,执行本函数中最重要的过程,drv->init_command。这个drv是啥?来自gendisk的private_data字段。还记得sd_probe吗?我们在其中把它赋值给了对应scsi_disk结构的driver字段,就是前面那个sd_template常量,别告诉我你又忘了。如果真忘了,那就好好从头开始,从scsi磁盘驱动的初始化函数init_sd开始。
我们知道sd_template常量的init_command指针指向sd_init_command函数地址,所以下面就来看看sd_init_command这个函数,十分重要,来自drivers/scsi/sd.c:
| 366static int sd_init_command(struct scsi_cmnd * SCpnt) 367{ 368 struct scsi_device *sdp = SCpnt->device; 369 struct request *rq = SCpnt->request; 370 struct gendisk *disk = rq->rq_disk; 371 sector_t block = rq->sector; 372 unsigned int this_count = SCpnt->request_bufflen >> 9; 373 unsigned int timeout = sdp->timeout; 374 375 SCSI_LOG_HLQUEUE(1, printk("sd_init_command: disk=%s, block=%llu, " 376 "count=%d/n", disk->disk_name, 377 (unsigned long long)block, this_count)); 378 379 if (!sdp || !scsi_device_online(sdp) || 380 block + rq->nr_sectors > get_capacity(disk)) { 381 SCSI_LOG_HLQUEUE(2, printk("Finishing %ld sectors/n", 382 rq->nr_sectors)); 383 SCSI_LOG_HLQUEUE(2, printk("Retry with 0x%p/n", SCpnt)); 384 return 0; 385 } 386 387 if (sdp->changed) { 388 /* 389 * quietly refuse to do anything to a changed disc until 390 * the changed bit has been reset 391 */ 392 /* printk("SCSI disk has been changed. Prohibiting further I/O./n"); */ 393 return 0; 394 } 395 SCSI_LOG_HLQUEUE(2, printk("%s : block=%llu/n", 396 disk->disk_name, (unsigned long long)block)); 397 398 /* 399 * If we have a 1K hardware sectorsize, prevent access to single 400 * 512 byte sectors. In theory we could handle this - in fact 401 * the scsi cdrom driver must be able to handle this because 402 * we typically use 1K blocksizes, and cdroms typically have 403 * 2K hardware sectorsizes. Of course, things are simpler 404 * with the cdrom, since it is read-only. For performance 405 * reasons, the filesystems should be able to handle this 406 * and not force the scsi disk driver to use bounce buffers 407 * for this. 408 */ 409 if (sdp->sector_size == 1024) { 410 if ((block & 1) || (rq->nr_sectors & 1)) { 411 printk(KERN_ERR "sd: Bad block number requested"); 412 return 0; 413 } else { 414 block = block >> 1; 415 this_count = this_count >> 1; 416 } 417 } 418 if (sdp->sector_size == 2048) { 419 if ((block & 3) || (rq->nr_sectors & 3)) { 420 printk(KERN_ERR "sd: Bad block number requested"); 421 return 0; 422 } else { 423 block = block >> 2; 424 this_count = this_count >> 2; 425 } 426 } 427 if (sdp->sector_size == 4096) { 428 if ((block & 7) || (rq->nr_sectors & 7)) { 429 printk(KERN_ERR "sd: Bad block number requested"); 430 return 0; 431 } else { 432 block = block >> 3; 433 this_count = this_count >> 3; 434 } 435 } 436 if (rq_data_dir(rq) == WRITE) { 437 if (!sdp->writeable) { 438 return 0; 439 } 440 SCpnt->cmnd[0] = WRITE_6; 441 SCpnt->sc_data_direction = DMA_TO_DEVICE; 442 } else if (rq_data_dir(rq) == READ) { 443 SCpnt->cmnd[0] = READ_6; 444 SCpnt->sc_data_direction = DMA_FROM_DEVICE; 445 } else { 446 printk(KERN_ERR "sd: Unknown command %lx/n", rq->flags); 447/* overkill panic("Unknown sd command %lx/n", rq->flags); */ 448 return 0; 449 } 450 451 SCSI_LOG_HLQUEUE(2, printk("%s : %s %d/%ld 512 byte blocks./n", 452 disk->disk_name, (rq_data_dir(rq) == WRITE) ? 453 "writing" : "reading", this_count, rq->nr_sectors)); 454 455 SCpnt->cmnd[1] = 0; 456 457 if (block > 0xffffffff) { 458 SCpnt->cmnd[0] += READ_16 - READ_6; 459 SCpnt->cmnd[1] |= blk_fua_rq(rq) ? 0x8 : 0; 460 SCpnt->cmnd[2] = sizeof(block) > 4 ? (unsigned char) (block >> 56) & 0xff : 0; 461 SCpnt->cmnd[3] = sizeof(block) > 4 ? (unsigned char) (block >> 48) & 0xff : 0; 462 SCpnt->cmnd[4] = sizeof(block) > 4 ? (unsigned char) (block >> 40) & 0xff : 0; 463 SCpnt->cmnd[5] = sizeof(block) > 4 ? (unsigned char) (block >> 32) & 0xff : 0; 464 SCpnt->cmnd[6] = (unsigned char) (block >> 24) & 0xff; 465 SCpnt->cmnd[7] = (unsigned char) (block >> 16) & 0xff; 466 SCpnt->cmnd[8] = (unsigned char) (block >> 8) & 0xff; 467 SCpnt->cmnd[9] = (unsigned char) block & 0xff; 468 SCpnt->cmnd[10] = (unsigned char) (this_count >> 24) & 0xff; 469 SCpnt->cmnd[11] = (unsigned char) (this_count >> 16) & 0xff; 470 SCpnt->cmnd[12] = (unsigned char) (this_count >> 8) & 0xff; 471 SCpnt->cmnd[13] = (unsigned char) this_count & 0xff; 472 SCpnt->cmnd[14] = SCpnt->cmnd[15] = 0; 473 } else if ((this_count > 0xff) || (block > 0x1fffff) || 474 SCpnt->device->use_10_for_rw) { 475 if (this_count > 0xffff) 476 this_count = 0xffff; 477 478 SCpnt->cmnd[0] += READ_10 - READ_6; 479 SCpnt->cmnd[1] |= blk_fua_rq(rq) ? 0x8 : 0; 480 SCpnt->cmnd[2] = (unsigned char) (block >> 24) & 0xff; 481 SCpnt->cmnd[3] = (unsigned char) (block >> 16) & 0xff; 482 SCpnt->cmnd[4] = (unsigned char) (block >> 8) & 0xff; 483 SCpnt->cmnd[5] = (unsigned char) block & 0xff; 484 SCpnt->cmnd[6] = SCpnt->cmnd[9] = 0; 485 SCpnt->cmnd[7] = (unsigned char) (this_count >> 8) & 0xff; 486 SCpnt->cmnd[8] = (unsigned char) this_count & 0xff; 487 } else { 488 if (unlikely(blk_fua_rq(rq))) { 489 /* 490 * This happens only if this drive failed 491 * 10byte rw command with ILLEGAL_REQUEST 492 * during operation and thus turned off 493 * use_10_for_rw. 494 */ 495 printk(KERN_ERR "sd: FUA write on READ/WRITE(6) drive/n"); 496 return 0; 497 } 498 499 SCpnt->cmnd[1] |= (unsigned char) ((block >> 16) & 0x1f); 500 SCpnt->cmnd[2] = (unsigned char) ((block >> 8) & 0xff); 501 SCpnt->cmnd[3] = (unsigned char) block & 0xff; 502 SCpnt->cmnd[4] = (unsigned char) this_count; 503 SCpnt->cmnd[5] = 0; 504 } 505 SCpnt->request_bufflen = this_count * sdp->sector_size; 506 507 /* 508 * We shouldn't disconnect in the middle of a sector, so with a dumb 509 * host adapter, it's safe to assume that we can at least transfer 510 * this many bytes between each connect / disconnect. 511 */ 512 SCpnt->transfersize = sdp->sector_size; 513 SCpnt->underflow = this_count << 9; 514 SCpnt->allowed = SD_MAX_RETRIES; 515 SCpnt->timeout_per_command = timeout; 516 517 /* 518 * This is the completion routine we use. This is matched in terms 519 * of capability to this function. 520 */ 521 SCpnt->done = sd_rw_intr; 522 523 /* 524 * This indicates that the command is ready from our end to be 525 * queued. 526 */ 527 return 1; 528} |
这个函数很重要,看似也很长,但是对照着前面scsi块设备驱动体系架构仔细看看,就会发现其实代码虽多,但很好理解。379~394检查一下磁盘状态,正常的话就不进入相应的条件分支。409~435行,根据扇区大小对内部变量block和this_count进行调整,其中block表示将要对磁盘读写的起始扇区号,this_count表示将要读入scsi_cmnd对应的那个缓冲区的字节数。这个缓冲区是通过前面scsi_init_io函数调用scsi_alloc_sgtable获得的,感兴趣的同学可以深入研究一下。
继续走,436行,通过rq_data_dir宏获得request的传输方向:
#define rq_data_dir(rq) ((rq)->flags & 1)
如果是WRITE就把scsi命令设置成WRITE_6,否则设置成READ_6。457-478是针对有些磁盘的大扇区的处理,我们略过,然后499-503初始化CDB的其他字段,大家可以对照“scsi设备驱动体系架构”中CDB的格式来分析这些代码的意思。最后,sd_init_command函数初始化scsi_cmnd的其他字段,并返回到scsi_prep_fn函数中。由于sd_init_command返回的是1,最终,正常的话,scsi_prep_fn函数返回BLKPREP_OK。prep表示prepare的意思,用我们的母语说就是准备的意思,最后BLKPREP_OK就说明准备好了,或者说准备就绪。而scsi_prep_fn()也将返回这个值,返回之前还设置了cmd_flags中的REQ_DONTPREP。(注意elv_next_request()函数741行判断的就是设这个flag。)
回到elv_next_request()中,由于返回值是BLKPREP_OK,所以746行我们就break了。换言之,我们取到了一个request,我们为之准备好了scsi命令,我们下一步就该是执行这个命令了。所以我们不需要再在elv_next_request()中滞留。我们终于回到了scsi_request_fn(),结束了elv_next_request,又要看下一个,不只是一个,而是两个,1467行,一个宏加一个函数,宏是blk_queue_tagged,来自include/linux/blkdev.h:
#define blk_queue_tagged(q) test_bit(QUEUE_FLAG_QUEUED, &(q)->queue_flags)
而函数是blk_queue_start_tag,来自block/ll_rw_blk.c:
| 1122 int blk_queue_start_tag(request_queue_t *q, struct request *rq) 1123 { 1124 struct blk_queue_tag *bqt = q->queue_tags; 1125 int tag; 1126 1127 if (unlikely((rq->cmd_flags & REQ_QUEUED))) { 1128 printk(KERN_ERR 1129 "%s: request %p for device [%s] already tagged %d", 1130 __FUNCTION__, rq, 1131 rq->rq_disk ? rq->rq_disk->disk_name : "?", rq->tag); 1132 BUG(); 1133 } 1134 1135 /* 1136 * Protect against shared tag maps, as we may not have exclusive 1137 * access to the tag map. 1138 */ 1139 do { 1140 tag = find_first_zero_bit(bqt->tag_map, bqt->max_depth); 1141 if (tag >= bqt->max_depth) 1142 return 1; 1143 1144 } while (test_and_set_bit(tag, bqt->tag_map)); 1145 1146 rq->cmd_flags |= REQ_QUEUED; 1147 rq->tag = tag; 1148 bqt->tag_index[tag] = rq; 1149 blkdev_dequeue_request(rq); 1150 list_add(&rq->queuelist, &bqt->busy_list); 1151 bqt->busy++; 1152 return 0; 1153 } |
对于我们大多数人来说,这两个函数的返回值都是0。
也因此,下一个函数blkdev_dequeue_request()就会被执行。来自include/linux/blkdev.h:
| 725 static inline void blkdev_dequeue_request(struct request *req) 726 { 727 elv_dequeue_request(req->q, req); 728 } |
而elv_dequeue_request来自block/elevator.c:
| 778 void elv_dequeue_request(request_queue_t *q, struct request *rq) 779 { 780 BUG_ON(list_empty(&rq->queuelist)); 781 BUG_ON(ELV_ON_HASH(rq)); 782 783 list_del_init(&rq->queuelist); 784 785 /* 786 * the time frame between a request being removed from the lists 787 * and to it is freed is accounted as io that is in progress at 788 * the driver side. 789 */ 790 if (blk_account_rq(rq)) 791 q->in_flight++; 792 } |
现在这个社会就是利用与被利用的关系,既然这个request已经没有了利用价值,我们已经从它身上得到了我们想要的scsi命令,那么我们完全可以过河拆桥卸磨杀驴了。list_del_init把这个request从request queue队列里删除掉。
而下面这个blk_account_rq也是一个来自include/linux/blkdev.h的宏:
536 #define blk_account_rq(rq) (blk_rq_started(rq) && blk_fs_request(rq))
很显然,至少第二个条件我们是不满足的。所以不用多说,结束这个elv_dequeue_request。
现在是时候去执行scsi命令了,回到scsi_request_fn函数中elv_next_request执行完毕之后,req的special就存放对scsi硬件设备发出“特殊”命令的请求所使用的数据的指针,1472行,把它赋给内部 scsi_cmnd型变量cmd。然后1508行调用scsi_dispatch_cmd函数执行这个cmd。
整个块设备驱动层的处理就结束了,我还是在网上找到一个图,正好可以总结上面的过程:
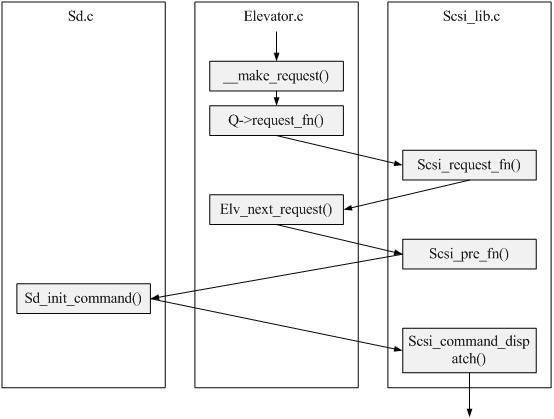
从前面分析可以看出,请求队列queue是top level与middle level之间的纽带。上层请求会在请求队列中维护,处理函数的方法由上下各层提供。在请求队列的处理过程中,将普通的块设备请求转换成标准的scsi命令,然后再通过middle level与low level之间的接口将请求递交给scsi host。